
數(shù)據分析面試必考的AB-Test知識點整理
 先點贊收藏一波!
先點贊收藏一波!AB測試來源
越來越多的公司重視AB測試,按照貓哥的經驗,之前會Excel就行,SQL是加分項。后來變成了必須懂SQL,AB測試是加分項。再到后來變成了,AB測試和SQL都是必會的東西。
因為從15年至今,人口紅利肉眼可見的減少,流量競爭從增量競爭變成了存量競爭。截至2020年底,互聯(lián)網用戶已經高達10億。微信,支付寶,頭條,抖音這些巨型APP基本已經瓜分了用戶的大部分時間,別的APP想要存活及增長,精細化運營就變成了必須。
精細化從技術上,又無法避免AB測試。往往產品的認知并不是用戶的認知,所以我們需要去測試,去實驗用戶的喜好。選擇一個用戶偏愛的功能上線,才會不斷提高用戶滿意度,我們的APP才能活下來,并有一定程度的增長。
AB測試是借鑒了實驗的思維,目標是為了歸因。通俗來說,就是我們想把條件分開,明確的知道,哪種條件下,用戶會買賬。這就需要三個條件:有對照組,隨機分配用戶,且用戶量足夠。
最早的AB測試本身是起源于醫(yī)學。當一個藥劑被研發(fā)后,醫(yī)學工作人員需要評估藥劑的效果。一般就會選擇兩組用戶(隨機篩選的用戶),構建實驗組和對照組。用這兩組用戶來“試藥”。也就是實驗組用戶給真的藥劑,對照組用戶給安慰劑,但是用戶本身不知道自己是什么組,只有醫(yī)生指導。之后,在后期的觀察中,通過一些統(tǒng)計方法,驗證效果的差異性是否顯著,從而去校驗藥劑是否達到我們的預期效果。
這個就是最早期的醫(yī)學“雙盲實驗”。互聯(lián)網行業(yè)其實也差不多是這么用。我們需要確認的是,當前改版,是否有效果,也就是說,我們需要驗證效果的“藥劑”變成了一個“改版”。
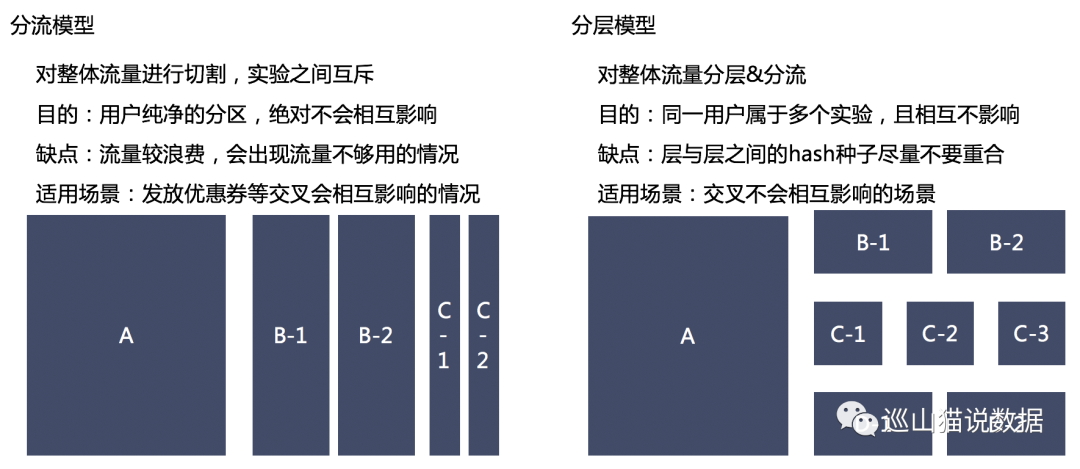
業(yè)務把將web或者app界面或者流程,拆分為多個版本。然后將流量分層(或者分流),不同的人群使用的某個功能或者觸發(fā)的策略不同。但是這里的人群一定要滿足同質化的特性。所以無論分層還是分流,我們都需要將用戶隨機分配,且同一用戶不能處在兩個組內。
通俗來說,AB測試是一種互聯(lián)網人口紅利減少的背景下,為了提高用戶滿意度,留下用戶而使用的一種利用數(shù)學原理來精細化運營的評估方法。
從本質上來說,AB-Test是對某唯一變化的有效性進行測試的實驗
AB測試適用場景
AB測試原理簡介
AB測試最核心的原理,就四個字:假設檢驗。檢驗我們提出的假設是否正確。對應到AB測試中,就是檢驗實驗組&對照組,指標是否有顯著差異。
既然是假設檢驗,那么就是先假設,再收集數(shù)據,最后根據收集的數(shù)據來做檢驗。
先來說說假設。
假設一般成對出現(xiàn),分為零假設 和 備選假設。
在AB測試中,零假設是:實驗組&對照組 指標相同,無顯著差異;備選假設則相反,實驗組&對照組 指標不同,有顯著差異。
舉個例子。我們優(yōu)化了某算法,想提高頁面的點擊率。針對這個場景的AB測試,零假設就是 新算法&老算法的頁面點擊率無明顯差異,備選假設是 新算法&老算法的頁面點擊率有顯著差異。
再來說說檢驗。
一般來說,我們是通過具體的指標屬性來找尋相應的檢驗方法。那么問題來了,指標如何分類呢?
指標可以分為兩種類別:
1、絕對值類指標。也就是我們平常直接計算就能得到的,比如DAU,點擊次數(shù)等。我們的一般都是統(tǒng)計該指標在一段時間內的均值或者匯總值,不存在兩個值之間還要相互計算。
2、相對值類指標。與絕對值類指標相反,我們不能直接計算得到。比如某頁面的CTR,我們是用 頁面點擊數(shù) / 頁面展現(xiàn)數(shù)。我們要計算點擊數(shù)和展現(xiàn)數(shù),兩者相除才能得到該指標。類似的,還有XX轉化率,XX點擊率,XX購買率一類的。我們做的AB實驗,大部分情況下都想提高這類指標。
根據指標我們可以知道,該如何計算最小樣本量,以及實驗周期,以及對應的檢驗方法。
AB測試詳細流程



AB測試案例串講
我們先來按照上節(jié)課的流程串講一個案例。
大體背景如下:
某社交APP增加了“看一看”功能,即用戶之間可以查閱到對方所填寫的一些基礎信息。現(xiàn)在要分析該功能,是否有效果。
我們得到這個問題,需要腦子里想到AB測試的整體流程圖(如下)。
從流程圖中,我們需要想到幾個問題:
1、實驗前:如何選指標,如何做假設,如何選實驗單位,根據實驗指標和單位,如何計算最小樣本量,以及實驗的周期
2、實驗中:需要驗證是否所有用戶僅處于同一個桶,還需要驗證線上實驗桶策略是否符合預期
3、實驗后:需要回收數(shù)據,通過計算P值或者置信區(qū)間Diff的方法,校驗該功能是否有效
從該功能來說,我們需要考慮的主要指標是用戶之間建立聯(lián)系的率值是否有提升。因為社交是為了讓用戶之間建立聯(lián)系,增加這種查閱資料的功能,是為了讓用戶通過資料查閱,與感興趣的用戶建立聯(lián)系。
所以該功能,我們的指標選擇為加好友率。這時候,零假設就是該功能無效果,即兩個桶的加好友率無明顯差異。備選假設則相反。實驗單位我們?yōu)榱吮苊鈹?shù)據的不置信,我們選擇以用戶為實驗單位。
假設我們的原有添加好友率如下 ,那么我們計算整體樣本量如下:
P:45%,p:47%(由于波動范圍是[44%,46%],所以至少是2.0%)
總樣本量 = 16 * (45%*(1-45%)+ 47%*(1-47%))/ (47%-45%)^2 = 19864
由于實驗桶和基線桶的比例是1:1,所以我們分配為實驗桶1w樣本,基線桶1w樣本量。但是由于我們不能一上來就全量試驗,所以我們開20%的流量為實驗桶(假設DAU的20%是2000/天,即實驗桶的DAU為2000/天),那么,我們預計要實驗5天(1w/2000)。
但是通過計算,用戶的一次活躍周期是7天,所以我們?yōu)榱俗寣嶒炐Ч尚哦雀撸媱潓嶒?天。
實驗上線后,我們對線上數(shù)據進行了驗證,確認了以下兩個問題:
1、實驗策略在實驗桶已生效,在基線桶未生效。即相關的看一看功能在實驗桶已上線,基線桶保持原樣;
2、同一個用戶僅處在同一分桶中,未出現(xiàn)一個用戶處于兩個桶的情況。
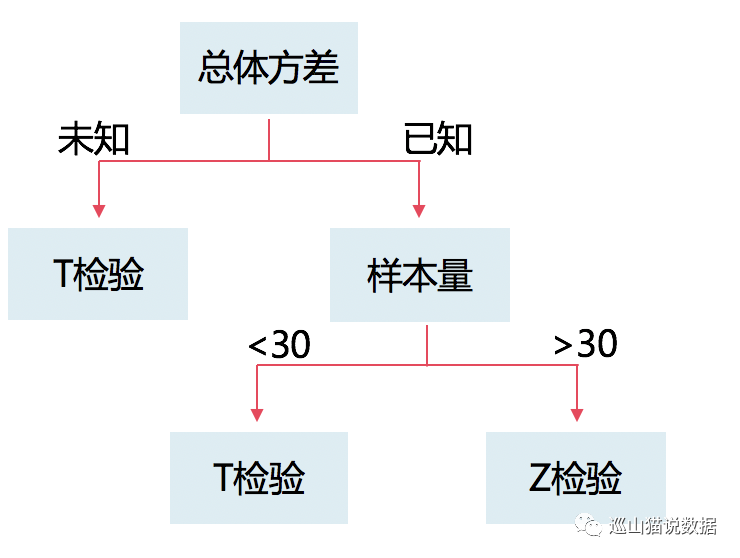
實驗到期后,我們對線上數(shù)據進行了回收。由于我們這個是相對值指標,所以我們使用Z檢驗。
檢驗方法有以下兩種:
1、算P值,P值小于5%,拒絕原假設,即產品功能有效果。這個場景中(假設)P=0.002,即我們判斷產品有效果。
2、算執(zhí)行區(qū)間的差值,如果不含0,則拒絕零假設。同樣,我們這里假設算出來期間不含0,我們認為該產品有效果。
以上,就是一個整體的AB實驗案例。我們從篩選指標,到設計實驗(選取實驗單位,計算最小樣本量,計算實驗周期),到實驗上線,再到后面的效果驗證。
但是不知道大家注意沒有,這個實驗有些地方設計的并不合理。因為社交用戶之間會有網絡效應,即一個用戶會影響另一個用戶,所以我們實驗分桶這么設計并不合理。
AB測試注意事項
下面,我們就來講講AB實驗的注意事項。
1、網絡效應:
這種情況通常出現(xiàn)在社交網絡,以及共享經濟場景(如滴滴)。舉個例子:如果微信改動了某一個功能,這個功能讓實驗組用戶更加活躍。但是相應的,實驗組的用戶的好友沒有分配到實驗組,而是對照組。但是,實驗組用戶更活躍(比如更頻繁的發(fā)朋友圈),作為對照組的我們也就會經常去刷朋友圈,那相應的,對照組用戶也受到了實驗組用戶的影響。本質上,對照組用戶也就收到了新的功能的影響,那么AB實驗就不再能很好的檢測出相應的效果。
解決辦法:從地理上區(qū)隔用戶,這種情況適合滴滴這種能夠從地理上區(qū)隔的產品,比如北京是實驗組,上海是對照組,只要兩個城市樣本量相近即可。或者從用戶上直接區(qū)隔,比如我們剛剛舉的例子,我們按照用戶的親密關系區(qū)分為不同的分層,按照用戶分層來做實驗即可。但是這種方案比較復雜,建議能夠從地理上區(qū)隔,就從地理上區(qū)隔。
2、學習效應:
這種情況就類似,產品做了一個醒目的改版,比如將某個按鈕顏色從暗色調成亮色。那相應的,很多用戶剛剛看到,會有個新奇心里,去點擊該按鈕,導致按鈕點擊率在一段時間內上漲,但是長時間來看,點擊率可能又會恢復到原有水平。反之,如果我們將亮色調成暗色,也有可能短時間內點擊率下降,長時間內又恢復到原有水平。這就是學習效應。
解決辦法:一個是拉長周期來看,我們不要一開始就去觀察該指標,而是在一段時間后再去觀察指標。通過剛剛的描述大家也知道,新奇效應會隨著時間推移而消失。另一種辦法是只看新用戶,因為新用戶不會有學習效應這個問題,畢竟新用戶并不知道老版本是什么樣子的。
3、多重檢驗問題:
這個很好理解,就是如果我們在實驗中,不斷的檢驗指標是否有差異,會造成我們的結果不可信。也就是說,多次檢驗同一實驗導致第一類錯誤概率上漲;同時檢驗多個分組導致第一類錯誤概率上漲。
舉個例子:
出現(xiàn)第一類錯誤概率:P(A)=5%
檢驗了20遍:P(至少出現(xiàn)一次第一類錯誤)
=1-P(20次完全沒有第一類錯誤)
=1- (1?5%) ^20
=64%
也就是說,當我們不斷的去檢驗實驗效果時,第一類錯誤的概率會直線上漲。所以我們在實驗結束前,不要多次去觀察指標,更不要觀察指標有差異后,直接停止實驗并下結論說該實驗有效。
AB測試面試踩坑
針對這些問題,有很多時候,面試官在問問題時,會設下一些坑,我們來舉兩個例子。
例1:滴滴準備升級司機端的一個功能,該如何校驗功能效果?
考點1:常見的AB測試流程設計
考點2:網絡效應
解法:
針對考點1:AB測試的流程是 確定目標 --> 確定實驗單位 --> 確定最小樣本量 --> 確認流量分割方案 --> 實驗上線 --> 規(guī)則校驗 --> 數(shù)據收集 --> 效果檢驗
針對考點2:實驗分桶,以兩個量級相近城市分割,避免網絡效應的相互影響
例2:某app,用戶活躍周期是14天,這時,上線了一個實驗,計劃跑20天在看效果,結果有位新同學,在10天時做了統(tǒng)計推斷,發(fā)現(xiàn)數(shù)據已經有了顯著差異,認為可以停止實驗,這樣做對嗎?
考點1:實驗周期應該跨越一個活躍周期
考點2:多重檢驗問題
解法:
由于AB測試的實驗周期盡量跨越一個用戶活躍周期,且在實驗結束時再做統(tǒng)計推斷,所以該做法不對,建議跑慢20天再看數(shù)據效果
AB測試小Tips
1、用戶屬性一定要一致
如果上線一個實驗,我們對年輕群體上線,年老群體不上線,實驗后拿著效果來對比,即使數(shù)據顯著性檢驗通過,那么,實驗也是不可信的。因為AB測試的基礎條件之一,就是實驗用戶的同質化。即實驗用戶群,和非實驗用戶群的 地域、性別、年齡等自然屬性因素分布基本一致。
2、一定要在同一時間維度下做實驗
舉例:如果某一個招聘app,年前3月份對用戶群A做了一個實驗,年中7月份對用戶群B做了同一個實驗,結果7月份的效果明顯較差,但是可能本身是由于周期性因素導致的。所以我們在實驗時,一定要排除掉季節(jié)等因素。
3、AB測試一定要從小流量逐漸放大
如果上線一個功能,直接流量開到50%去做測試,那么如果數(shù)據效果不好,或者功能意外出現(xiàn)bug,對線上用戶將會造成極大的影響。所以,建議一開始從最小樣本量開始實驗,然后再逐漸擴大用戶群體及實驗樣本量。
4、如果最小樣本量不足該怎么辦
如果我們計算出來,樣本量需要很大,我們分配的比例已經很大,仍舊存在樣本量不足的情況,那么我們只能通過拉長時間周期,通過累計樣本量來進行比較
5、是否需要上線第一天就開始看效果?
由于AB-Test,會影響到不同的用戶群體,所以,我們在做AB測試時,盡量設定一個測試生效期,這個周期一般是用戶的一個活躍間隔期。如招聘用戶活躍間隔是7天,那么生效期為7天,如果是一個機酒app,用戶活躍間隔是30天,那生效期為30天
6、用戶是否生效
用戶如果被分組后,未觸發(fā)實驗,我們需要排除這類用戶。因為這類用戶本身就不是AB該統(tǒng)計進入的用戶(這種情況較少,如果有,那在做實驗時打上生效標簽即可)
7、用戶不能同時處于多個組
如果用戶同時屬于多個組,那么,一個是會對用戶造成誤導(如每次使用,效果都不一樣),一個是會對數(shù)據造成影響,我們不能確認及校驗實驗的效果及準確性
8、如果多個實驗同時進行,一定要對用戶分層+分組
比如,在推薦算法修改的一個實驗中,我們還上線了一個UI優(yōu)化的實驗,那么我們需要將用戶劃分為4個組:A、老算法+老UI,B、老算法+新UI,C、新算法+老UI,D、新算法+新UI,因為只有這樣,我們才能同時進行的兩個實驗的參與改動的元素,做數(shù)據上的評估
9、特殊情況(實際情況)
樣本量計算這步,可能在部分公司不會使用,更多的是偏向經驗值;
假設檢驗這一步,部分公司可能也不會使用;
大部分公司,都會有自己的AB平臺,產運更偏向于平臺上直接測試,最后在一段時間后查看指標差異。
對于這兩種情況,我們需要計算不同流量分布下的指標波動數(shù)據,把相關自然波動下的閾值作為波動參考,這樣能夠大概率保證AB實驗的嚴謹及可信度。

