
2022最新「異常檢測 」綜述!中科院自動化所論文
點擊下方“AI算法與圖像處理”,一起進步!
重磅干貨,第一時間送達(dá)
中科院自動化所等《圖像異常檢測研究現(xiàn)狀》綜述論文

圖像異常檢測是計算機視覺領(lǐng)域的一個熱門研究課題, 其目標(biāo)是在不使用真實異常樣本的情況下, 利用現(xiàn)有的正 常樣本構(gòu)建模型以檢測可能出現(xiàn)的各種異常圖像, 在工業(yè)外觀缺陷檢測, 醫(yī)學(xué)圖像分析, 高光譜圖像處理等領(lǐng)域有較高的研 究意義和應(yīng)用價值. 本文首先介紹了異常的定義以及常見的異常類型. 然后, 本文根據(jù)在模型構(gòu)建過程中有無神經(jīng)網(wǎng)絡(luò)的參 與, 將圖像異常檢測方法分為基于傳統(tǒng)方法和基于深度學(xué)習(xí)兩大類型, 并分別對相應(yīng)的檢測方法的設(shè)計思路、優(yōu)點和局限性 進行了綜述與分析. 其次, 梳理了圖像異常檢測任務(wù)中面臨的主要挑戰(zhàn). 最后, 對該領(lǐng)域未來可能的研究方向進行了展望.
http://www.aas.net.cn/cn/article/doi/10.16383/j.aas.c200956
1. 引言
異常檢測是機器學(xué)習(xí)領(lǐng)域中一項重要的研究內(nèi)容. 它是一種利用無標(biāo)注樣本或者正常樣本構(gòu)建檢測模型[1], 檢測與期望模式存在差異的異常樣本的方法. 異常檢測在各種領(lǐng)域中都有廣泛的應(yīng)用, 如網(wǎng)絡(luò)入侵檢測, 信號處理, 工業(yè)大數(shù)據(jù)分析, 異常行為檢測和圖像與視頻處理等.
早期的異常檢測算法大多應(yīng)用于數(shù)據(jù)挖掘領(lǐng)域, 而近年來隨著計算機視覺和深度學(xué)習(xí)等相關(guān)技術(shù)的發(fā)展, 許多相關(guān)工作將異常檢測引入到圖像處理領(lǐng)域來解決樣本匱乏情況下的目標(biāo)檢測問題.
傳統(tǒng)的目標(biāo)檢測算法中很大一部分方法屬于監(jiān)督學(xué)習(xí)的范疇, 即需要收集足夠的目標(biāo)類別樣本并進行精確的標(biāo)注, 比如圖像的類別、圖像中目標(biāo)的位置以及每一個像素點的類別信息等[2, 3]. 然而, 在許多應(yīng)用場景下, 很難收集到足夠數(shù)量的樣本. 例如, 在表面缺陷檢測任務(wù)當(dāng)中, 實際收集到的圖像大部分屬于正常的無缺陷樣本, 僅有少部分屬于缺陷樣本, 而需要檢測的缺陷類型又十分多樣, 這就使得可供訓(xùn)練的缺陷樣本的數(shù)量十分有限[4]. 又比如在安檢任務(wù)當(dāng)中, 不斷會有新的異常物品出現(xiàn)[5]. 而對于醫(yī)學(xué)圖像中病變區(qū)域的識別任務(wù), 不僅帶有病變區(qū)域的樣本十分稀少, 對樣本進行手工標(biāo)注也十分耗時[6]. 在這些情況下, 由于目標(biāo)類別樣本的缺乏, 傳統(tǒng)的目標(biāo)檢測和圖像分割的方法已不再適用.
而異常檢測無需任何標(biāo)注樣本就能構(gòu)建檢測模型的特點, 使得其十分適用于上述幾種情況[7]. 在圖像異常檢測當(dāng)中, 收集正常圖像的難度要遠(yuǎn)低于收集異常圖像的難度, 能顯著減少檢測算法在實際應(yīng)用中的時間和人力成本. 而且, 在異常檢測中模型是通過分析與正常樣本之間的差異來檢測異常樣本, 這使得異常檢測算法對各種類型甚至是全新的異常樣本都具有檢測能力. 雖然標(biāo)注樣本的缺失給圖像異常檢測帶來了許多問題和挑戰(zhàn), 不過由于上述各種優(yōu)點, 如表1所示, 已經(jīng)有許多方法將圖像異常檢測應(yīng)用在各種領(lǐng)域中.因此, 圖像異常檢測問題具有較高的研究價值和實際應(yīng)用價值.
隨著對異常檢測研究的深入, 大量研究成果不斷涌現(xiàn), 也有許多學(xué)者開展了一些綜述性工作. 如Ehret等[20]根據(jù)不同的圖像背景, 對大量圖像異常檢測方法進行了綜述, 不過對基于深度學(xué)習(xí)的方法還缺乏一定的梳理. Pang等[21]和Chalapathy[22]等則是從更為廣闊的角度對基于深度學(xué)習(xí)的異常檢測方法進行了梳理, 不過由于數(shù)據(jù)類型的多樣性, 這些工作對異常檢測在圖像中的應(yīng)用還缺乏針對性. 陶顯等[23]對異常檢測在工業(yè)外觀缺陷檢測中的應(yīng)用進行了一些總結(jié), 不過重心落在有監(jiān)督的檢測任務(wù)上, 對無監(jiān)督的異常檢測方法欠缺一定的整理和歸納. 而本文則針對無監(jiān)督的圖像異常檢測任務(wù), 以工業(yè)、醫(yī)學(xué)和高光譜圖像作為具體應(yīng)用領(lǐng)域, 對傳統(tǒng)和基于深度學(xué)習(xí)的兩大類方法進行梳理. 上述三種應(yīng)用領(lǐng)域都有相同的特點即可使用的帶標(biāo)注異常樣本數(shù)量稀少, 因此有許多工作針對這幾個領(lǐng)域內(nèi)的異常目標(biāo)檢測問題開展了研究. 本文整體結(jié)構(gòu)安排如下: 第1節(jié)將介紹異常的定義以及常見的形態(tài). 第2節(jié)根據(jù)模型構(gòu)建過程中有無神經(jīng)網(wǎng)絡(luò)的參與, 將現(xiàn)有的圖像異常檢測算法分為傳統(tǒng)方法和基于深度學(xué)習(xí)兩大類并分別進行綜述與分析. 第3節(jié)將介紹圖像異常檢測中常用的數(shù)據(jù)集. 第4節(jié)將介紹在圖像異常檢測當(dāng)中面臨的主要挑戰(zhàn). 第5節(jié)將綜合圖像異常檢測的研究現(xiàn)狀對未來可能的發(fā)展方向進行展望. 最后第6節(jié)將對本文內(nèi)容進行總結(jié).
2. 圖像異常檢測的定義
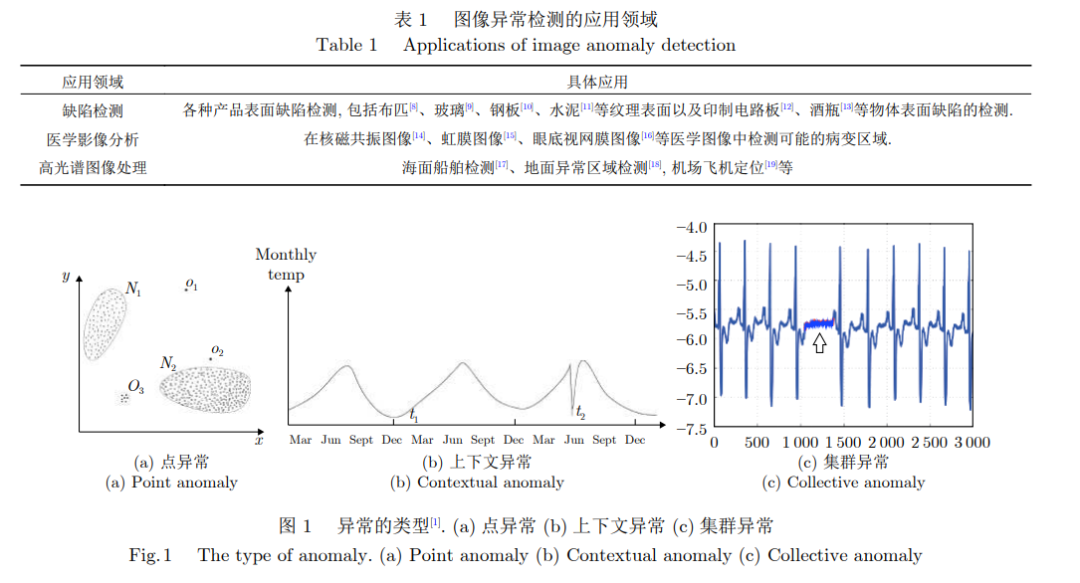
異常, 又被稱為離群值, 是一個在數(shù)據(jù)挖掘領(lǐng)域中常見的概念[24], 已經(jīng)有不少的工作嘗試對異常數(shù)據(jù)進行定義[25, 26]. Hawkins等[25]將異常定義為與其余觀測結(jié)果完全不同, 以至于懷疑其是由不同機制產(chǎn)生的觀測值. 一般情況下, 會將常見的異常樣本分為三個類別[1]: 點異常、上下文異常和集群異常. 點異常一般表現(xiàn)為某些嚴(yán)重偏離正常數(shù)據(jù)分布范圍的觀測值, 如圖1(a)所示的二維數(shù)據(jù)點, 其中偏離了正常樣本點的分布區(qū)域(N1, N2)的點(O1, O2和O3)即為異常點。
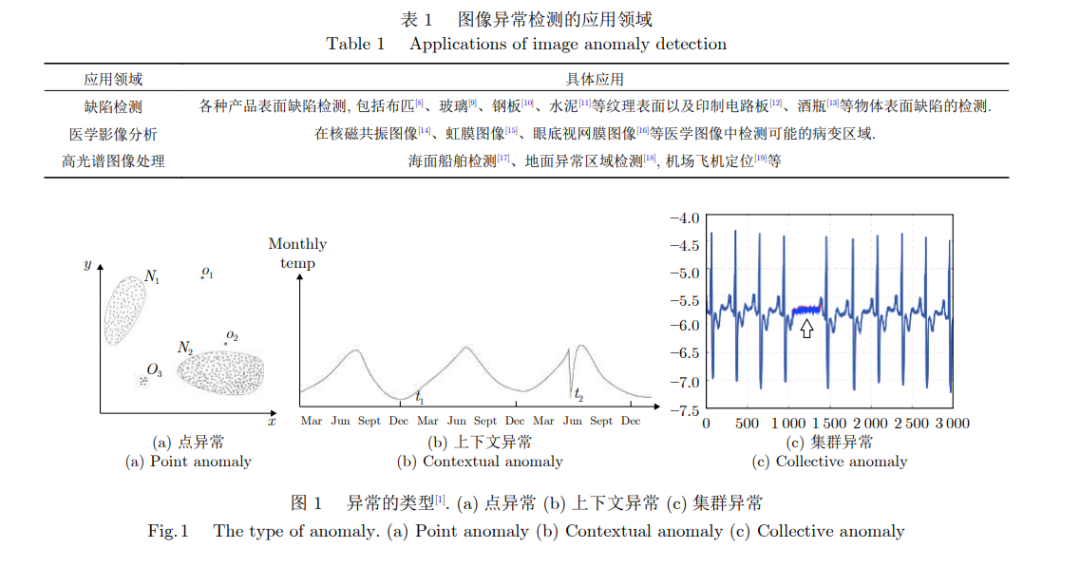
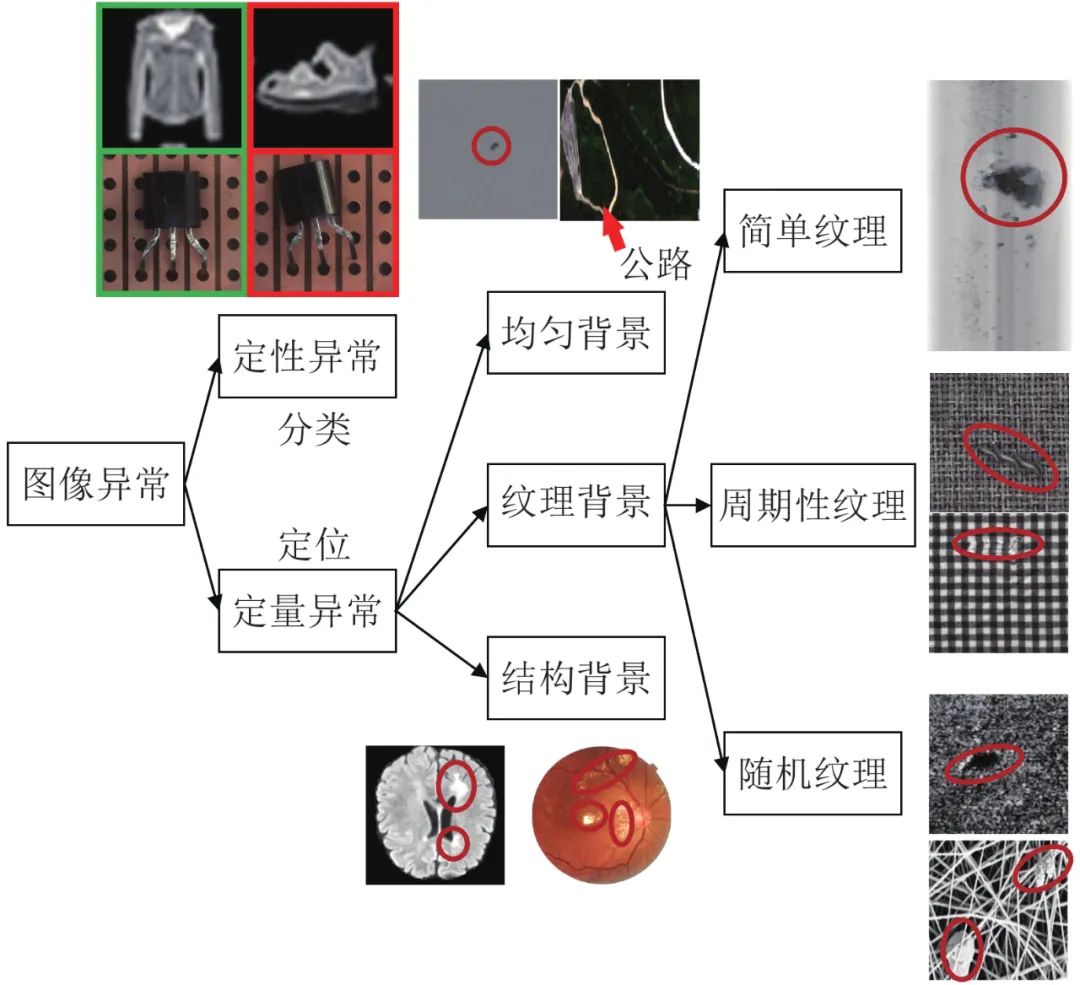
圖像數(shù)據(jù)中每一個像素點上的像素值就對應(yīng)著一個觀測結(jié)果. 由于圖像內(nèi)像素值的多樣性, 僅僅分析某一個點的像素值很難判斷其是否屬于異常. 所以在大部分圖像異常檢測任務(wù)中, 需要聯(lián)合分析圖像背景以及周圍像素信息來進行分類, 檢測的異常也大多屬于上下文或者模式異常. 當(dāng)然, 這三種異常類型之間并沒有非常嚴(yán)格的界限. 例如, 有一部分方法就提取圖像的各類特征[27], 并將其與正常圖像的特征進行比較以判斷是否屬于異常, 這就將原始圖像空間內(nèi)模式異常的檢測轉(zhuǎn)換到了特征空間內(nèi)點異常的檢測. 圖像異常檢測任務(wù)根據(jù)異常的形態(tài)可以分為定性異常的分類和定量異常的定位兩個類別. 定性異常的分類, 類似于傳統(tǒng)圖像識別任務(wù)中的圖像分類任務(wù), 即整體地給出是否異常的判斷, 無需準(zhǔn)確定位異常的位置. 如圖2左上圖所示, 左側(cè)代表正常圖像, 右側(cè)代表異常圖像, 在第一行中, 模型僅使用服飾數(shù)據(jù)集(Fashion mixed national institute of standards and technology database, Fashion-MNIST)[28]中衣服類型的樣本進行訓(xùn)練, 則其他類別的樣本圖像(鞋子等)對模型來說都是需要檢測的異常樣本, 因為他們在紋理、結(jié)構(gòu)和語義信息等方面都不相同. 又或者如第二行所示, 異常圖像中的三極管與正常圖像之間只是出現(xiàn)了整體的偏移, 而三極管表面并不存在任何局部的異常區(qū)域, 難以準(zhǔn)確地定義出現(xiàn)異常的位置, 更適合整體地進行異常與否的分類.
3 圖像異常檢測技術(shù)研究現(xiàn)狀
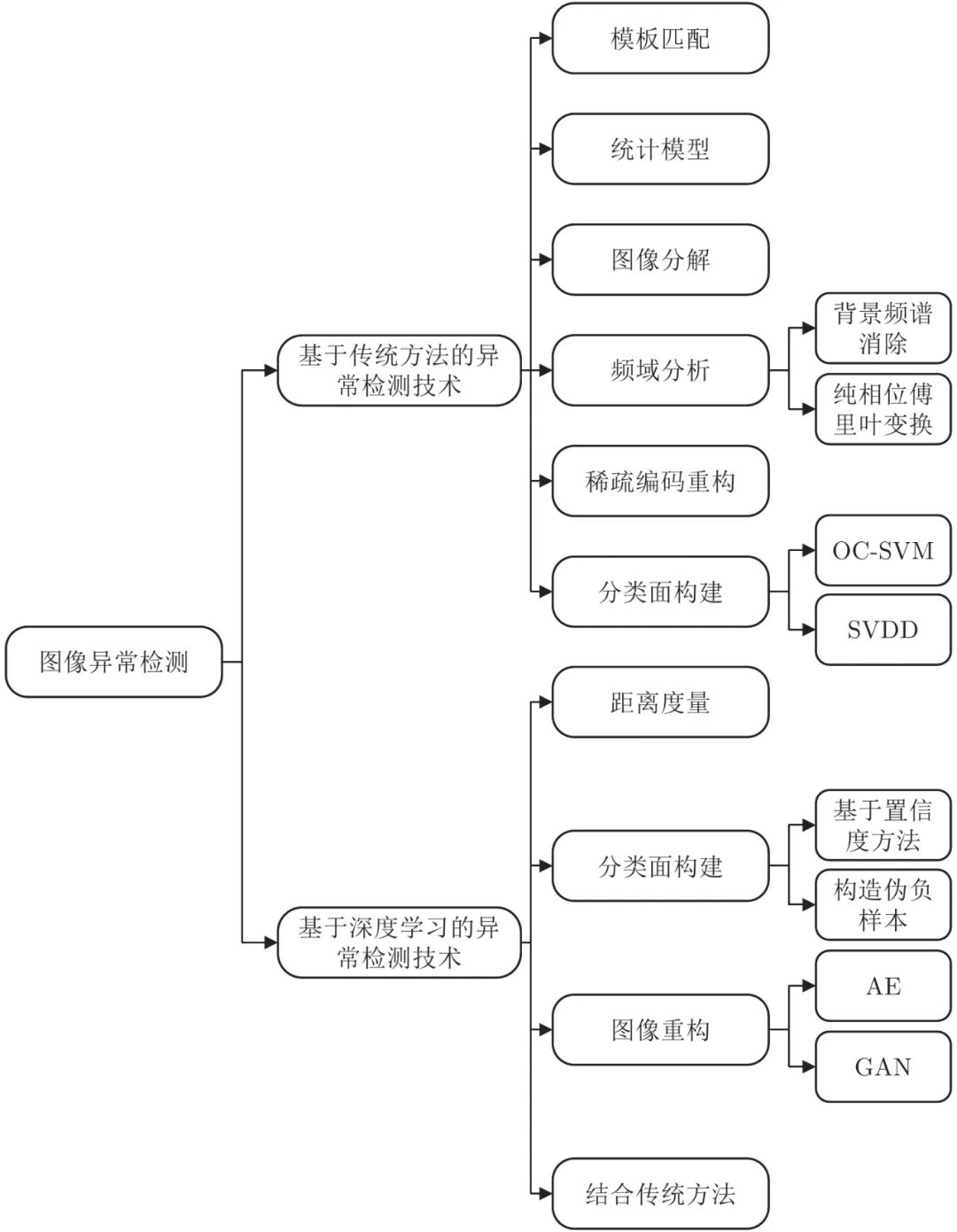

近年來, 深度學(xué)習(xí)在計算機視覺中的各個領(lǐng)域內(nèi)都得到了長足的發(fā)展. 相比于傳統(tǒng)的方法, 深度學(xué)習(xí)由于其無需人工設(shè)計特征, 算法通用性更高等優(yōu)點, 已經(jīng)被廣泛引入到了圖像異常檢測任務(wù)當(dāng)中. 現(xiàn)有的方法大致可以分為以下幾類: 基于距離度量的方法、基于分類面構(gòu)建的方法、基于圖像重構(gòu)的方法和與傳統(tǒng)方法相結(jié)合的方法.

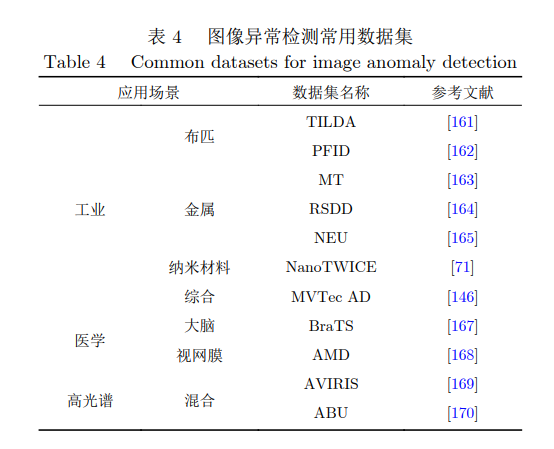
4. 圖像異常檢測數(shù)據(jù)集
5. 圖像異常檢測數(shù)展望
本文對近年來圖像異常檢測方法的發(fā)展?fàn)顩r進行了回顧, 可以看到針對這一問題已經(jīng)有了一定數(shù)量的研究. 關(guān)于未來可能的研究方向, 我們認(rèn)為可以從以下幾個角度進行考慮:
1) 構(gòu)建更為高效的異常檢測算法. 對于異常檢測而言, 不僅僅需要對待檢圖像進行正常與否的判斷, 往往還需要對異常區(qū)域進行定位. 比如工業(yè)圖像表面的缺陷檢測, 醫(yī)學(xué)圖像中病變區(qū)域的定位等等. 然而, 由于在訓(xùn)練階段沒有任何關(guān)于異常區(qū)域的標(biāo)注信息, 傳統(tǒng)的目標(biāo)檢測或者圖像分割的方法無法直接應(yīng)用到異常檢測任務(wù)中. 因此, 現(xiàn)有的方法大多采用的是將待檢圖像切分成一系列的圖像塊, 然后分塊進行異常與否的二分類來進行異常區(qū)域的定位. 而且, 為了獲得異常區(qū)域的準(zhǔn)確輪廓, 這種切分的步長一般較小, 會顯著影響算法的效率. 現(xiàn)有的一些方法比如頻譜分析雖然能夠同時處理整張圖像以實現(xiàn)高效的定位, 但該方法對于圖像有一定的要求. 而基于深度學(xué)習(xí)的圖像重構(gòu)方法雖然沒有上述約束, 但重構(gòu)圖像中殘留的異常區(qū)域會影響后續(xù)的檢測. 因此, 如何兼顧檢測精度和實時性仍需進一步的探索.
2) 小樣本/半監(jiān)督學(xué)習(xí). 現(xiàn)階段的異常檢測方法大部分僅利用正常樣本來訓(xùn)練模型. 但是在實際檢測任務(wù)中, 并不是完全無法獲取真實的異常樣本. 比如在工業(yè)外觀檢測任務(wù)中, 少量的缺陷樣本是可以獲取的. 而且對幾張缺陷圖像進行標(biāo)注并不會顯著地增加訓(xùn)練成本. 而且相關(guān)文獻(xiàn)[96]初步嘗試了在訓(xùn)練過程中引入一張真實異常圖像并且獲得了一定的效果提升. 因此可以考慮結(jié)合小樣本學(xué)習(xí)的方法, 利用大量正常樣本和幾張真實的異常樣本來進行模型訓(xùn)練以提高性能. 而有些異常檢測任務(wù)面臨的是嚴(yán)格無監(jiān)督的環(huán)境[98], 連所用樣本是否屬于正常樣本也不可預(yù)知, 此時訓(xùn)練樣本中存在的少量異常樣本就會對模型的訓(xùn)練產(chǎn)生性能上的影響, 如果采用半監(jiān)督的訓(xùn)練方式, 對少量正常和異常樣本進行標(biāo)注, 可以有效提升模型對潛在異常樣本的檢測能力. 但是這種方法還是會面臨一些問題, 比如采集到的異常樣本顯然不可能囊括所有類別, 如何讓模型兼顧對已知類型和未知類型異常樣本的檢測能力, 也是一個待研究的任務(wù).
3) 更自適應(yīng)的樣本合成方法. 在許多相關(guān)的文獻(xiàn)中[105, 108, 110]都已經(jīng)證明了在模型訓(xùn)練階段, 引入各種人工構(gòu)造的異常圖像能有效地提升檢測性能. 即便構(gòu)造的異常圖像與真實的異常圖像并不相同, 額外增加的異常圖像可以提升分類面的貼合度或者背景重構(gòu)的穩(wěn)定度, 這都可以增加模型對潛在異常圖像的檢測能力. 但相關(guān)文獻(xiàn)表明這些額外的異常樣本越接近與正常樣本模型的性能越好[105]. 然而, 相關(guān)方法中額外使用的異常圖像大多是采集自別的數(shù)據(jù)集, 這些圖像一般與正常樣本的分布之間存在較為明顯的差異. 雖然有方法嘗試采用梯度上升的方式合成異常圖像, 但該方法在更為復(fù)雜的圖像上的結(jié)果還有待論證. 因此, 如何針對各種正常圖像自適應(yīng)地合成異常樣本也是一個有待解決的問題.
4) 輕量化網(wǎng)絡(luò)設(shè)計. 基于深度學(xué)習(xí)的異常檢測方法得益于神經(jīng)網(wǎng)絡(luò)強大的學(xué)習(xí)能力往往能得到比傳統(tǒng)方法更優(yōu)秀的性能, 但代價是需要更多的計算量和更長的處理時間. 對于一張待測圖像, 需要利用深層神經(jīng)網(wǎng)絡(luò)提取特征向量以區(qū)分正常和異常樣本, 而且重構(gòu)類的方法還需要再次經(jīng)過第二個深層神經(jīng)網(wǎng)絡(luò)來重構(gòu)輸入圖像. 因此, 更為輕量化的網(wǎng)絡(luò)設(shè)計能夠減少方法的運行時間. 此外, 大多數(shù)方法在驗證時硬件條件較好, 而實際生產(chǎn)現(xiàn)場要部署同等算力的設(shè)備會需要較高的成本, 因此, 輕量化的網(wǎng)絡(luò)設(shè)計在減少計算量的同時, 還能降低對硬件設(shè)備的需求, 降低在實際應(yīng)用中的成本. 針對這一問題, 現(xiàn)階段常用的有兩類方法: 1)輕量模型設(shè)計, 設(shè)計更為高效的網(wǎng)絡(luò)計算方法以實現(xiàn)減小模型體積的同時保持性能不變, 例如MobileNet[175]等. 也可以采用知識蒸餾的方式, 用復(fù)雜網(wǎng)絡(luò)的輸出作為目標(biāo)來訓(xùn)練一個更為簡單的網(wǎng)絡(luò); 2)模型壓縮, 有通過剪枝的方式剔除冗余的權(quán)重以減小模型大小, 也有通過網(wǎng)絡(luò)量化的方式, 以犧牲一定精度為代價減小網(wǎng)絡(luò)參數(shù)所占空間, 其中二值化模型具有突出的壓縮性能, 更利于模型部署.
5) 更高精度的異常定位方法. 對于異常定位任務(wù), 現(xiàn)有的方法大多會采用滑窗的方式將原始圖像分解成一系列小的圖像區(qū)域, 然后再利用異常分類的方式對每一個區(qū)域進行異常與否的分析. 這種分塊分析的方式無法精準(zhǔn)地定位異常區(qū)域, 處于異常紋理與正常紋理的交界處的圖像區(qū)域也很有可能被誤判為異常. 而對于能直接定位異常的圖像重構(gòu)類方法, 又會因自身重構(gòu)精度的限制, 在正常紋理區(qū)域也會出現(xiàn)差異, 這也會影響對一些微弱異常區(qū)域的定位效果. 在醫(yī)學(xué)和工業(yè)等領(lǐng)域內(nèi)異常目標(biāo)的檢測中, 不僅要關(guān)注召回率, 異常檢測的精準(zhǔn)率也十分重要. 但從現(xiàn)有方法的效果看, 許多方法主要在召回率方面性能優(yōu)異, 因為在實際應(yīng)用領(lǐng)域中漏檢的危害性遠(yuǎn)高于誤檢. 但如果能夠在保證召回率的同時提高精準(zhǔn)率, 盡可能減少后續(xù)人工或者算法的二次處理, 異常檢測方法將能更廣泛地應(yīng)用在相關(guān)領(lǐng)域中. 因此, 如何精準(zhǔn)定位異常區(qū)域并減少對正常圖像區(qū)域的誤判情況, 同樣也是一個值得研究的問題.
-------------------
END
--------------------
交流群
歡迎加入公眾號讀者群一起和同行交流,目前有美顏、三維視覺、計算攝影、檢測、分割、識別、醫(yī)學(xué)影像、GAN、算法競賽等微信群
個人微信(如果沒有備注不拉群!) 請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會分享
在「AI算法與圖像處理」公眾號后臺回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號后臺回復(fù):c++,即可下載。歷經(jīng)十年考驗,最權(quán)威的編程規(guī)范!
下載3 CVPR2021 在「AI算法與圖像處理」公眾號后臺回復(fù):CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
