AAAI 2022|中科院自動(dòng)化所新作速覽!

??新智元報(bào)道??
??新智元報(bào)道??
來(lái)源:中國(guó)科學(xué)院自動(dòng)化研究所
【新智元導(dǎo)讀】在國(guó)際人工智能頂級(jí)會(huì)議AAAI 2022中,自動(dòng)化所共有21篇論文被收錄,本文將對(duì)部分論文進(jìn)行簡(jiǎn)要梳理介紹,與各位共同交流領(lǐng)域前沿進(jìn)展。
01
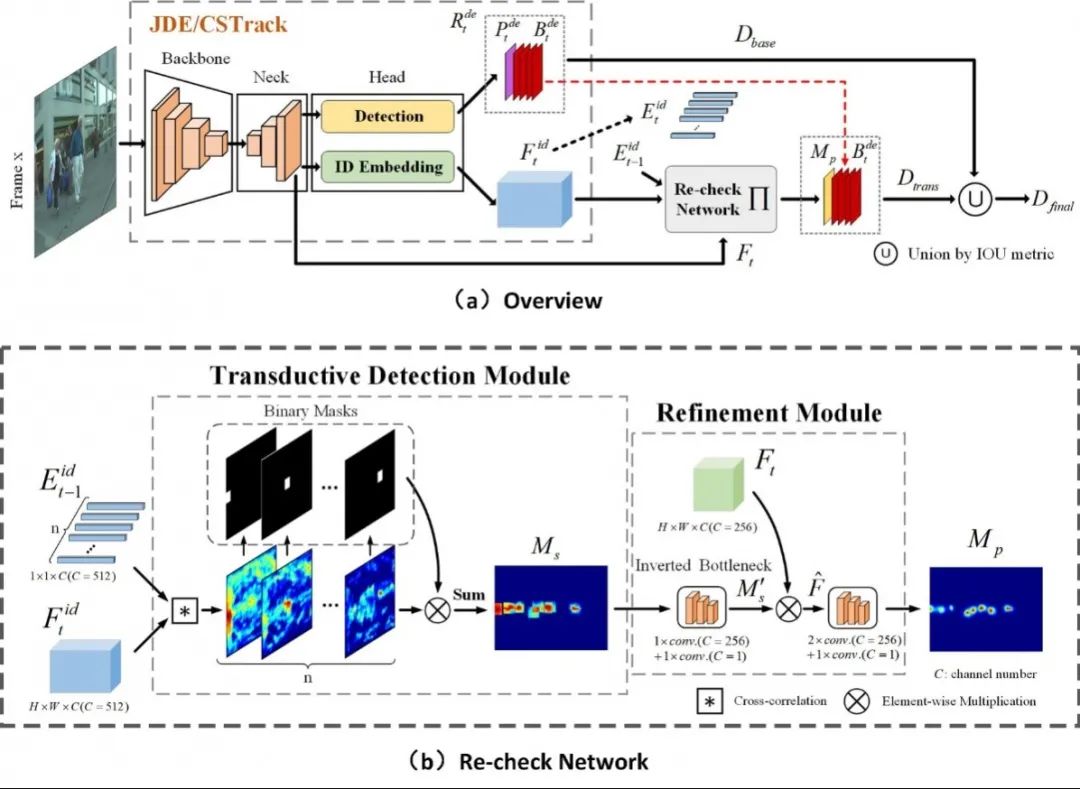
基于再查詢機(jī)制的一體化多目標(biāo)跟蹤算法
One More Check: Making “Fake Background” Be Tracked Again
近年來(lái),將檢測(cè)和ReID統(tǒng)一到一個(gè)網(wǎng)絡(luò)之中來(lái)完成多目標(biāo)跟蹤的方法取得了巨大的突破,且引起了研究人員的廣泛關(guān)注。然而當(dāng)前的一體化跟蹤器僅依賴于單幀圖片進(jìn)行目標(biāo)檢測(cè),在遇到一些現(xiàn)實(shí)場(chǎng)景的干擾,如運(yùn)動(dòng)模糊、目標(biāo)相互遮擋時(shí),往往容易失效。一旦檢測(cè)方法因?yàn)樘卣鞯牟豢煽慷鴮?dāng)前幀的目標(biāo)錯(cuò)判成背景時(shí),難免會(huì)破壞目標(biāo)所對(duì)應(yīng)的軌跡的連貫性。
在本文中,我們提出了一個(gè)再查詢網(wǎng)絡(luò)來(lái)召回被錯(cuò)分為“假背景”的目標(biāo)框。該再查詢網(wǎng)絡(luò)創(chuàng)新性地將ID向量的功能從匹配擴(kuò)展到運(yùn)動(dòng)預(yù)測(cè),從而實(shí)現(xiàn)以較小的計(jì)算開(kāi)銷將已有目標(biāo)的軌跡有效地傳播到當(dāng)前幀。而通過(guò)ID向量為媒介進(jìn)行時(shí)序信息傳播,所生成的遷移信息有效地防止了模型過(guò)度依賴于檢測(cè)結(jié)果。因此,再查詢網(wǎng)絡(luò)有助于一體化方法召回“假背景”同時(shí)修復(fù)破碎的軌跡。
基于已有的一體化方法CSTrack,本文構(gòu)建了一個(gè)新穎且高性能的一體化跟蹤器,其在MOT16和MOT17兩個(gè)基準(zhǔn)上分別取得了巨大的增益,即相比于CSTrack,MOTA分?jǐn)?shù)從70.7/70.6提高到76.4/76.3。此外,它還取得了新SOTA的MOTA和IDF1性能。
其代碼已開(kāi)源在:
https://github.com/JudasDie/SOTS
作者:Chao Liang , Zhipeng Zhang , Xue Zhou, Bing Li, Weiming Hu
02
從目標(biāo)中學(xué)習(xí): 用于小樣本語(yǔ)義分割的雙原型網(wǎng)絡(luò)
Learning from the Target: Dual Prototype Network for Few Shot Semantic Segmentation
由于標(biāo)注樣本的稀缺,支持集和查詢集之間的樣本差異(目標(biāo)的外觀,尺寸,視角等)成為小樣本語(yǔ)義分割的主要難點(diǎn)。現(xiàn)有的基于原型的方法大多只從支持集特征中挖掘原型,而忽略了利用來(lái)自查詢集樣本的信息,因此無(wú)法解決這個(gè)由樣本間差異帶來(lái)的痛點(diǎn)。
在本文中,我們提出了一種雙原型網(wǎng)絡(luò) (DPNet),它從一個(gè)新穎的角度來(lái)處理小樣本語(yǔ)義分割問(wèn)題,即在從支持集中提取原型的基礎(chǔ)上,進(jìn)一步提出了從查詢圖像中提取可靠的前景信息作為偽原型。
為了實(shí)現(xiàn)這一目的,我們?cè)O(shè)計(jì)了循環(huán)比較模塊,通過(guò)兩次匹配過(guò)程篩選出符合要求的前景查詢特征,并利用這些前景特征生成偽原型。然后根據(jù)原型與偽原型之間的內(nèi)在關(guān)聯(lián),利用原型交互模塊對(duì)原型與偽原型的信息進(jìn)行交互整合。最后,引入一個(gè)多尺度融合模塊,在原型(偽原型)與查詢特征的密集比較過(guò)程中引入上下文信息,以獲得更好的分割結(jié)果。
在兩個(gè)標(biāo)準(zhǔn)數(shù)據(jù)集 (PASCAL-5i, COCO-20i)上進(jìn)行的大量實(shí)驗(yàn)表明,我們的方法取得了優(yōu)越的性能,證明了提出方法的有效性。
作者:Binjie Mao,Xinbang Zhang,Lingfeng Wang,Qian Zhang, Shiming Xiang, Chunhong Pan
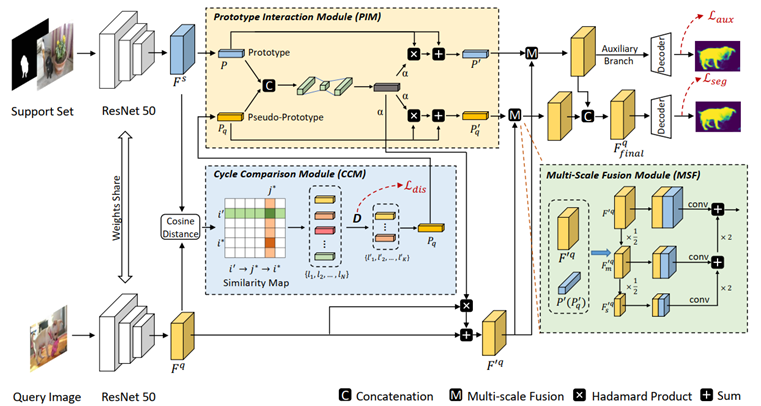
DPNet的網(wǎng)絡(luò)框架圖
03
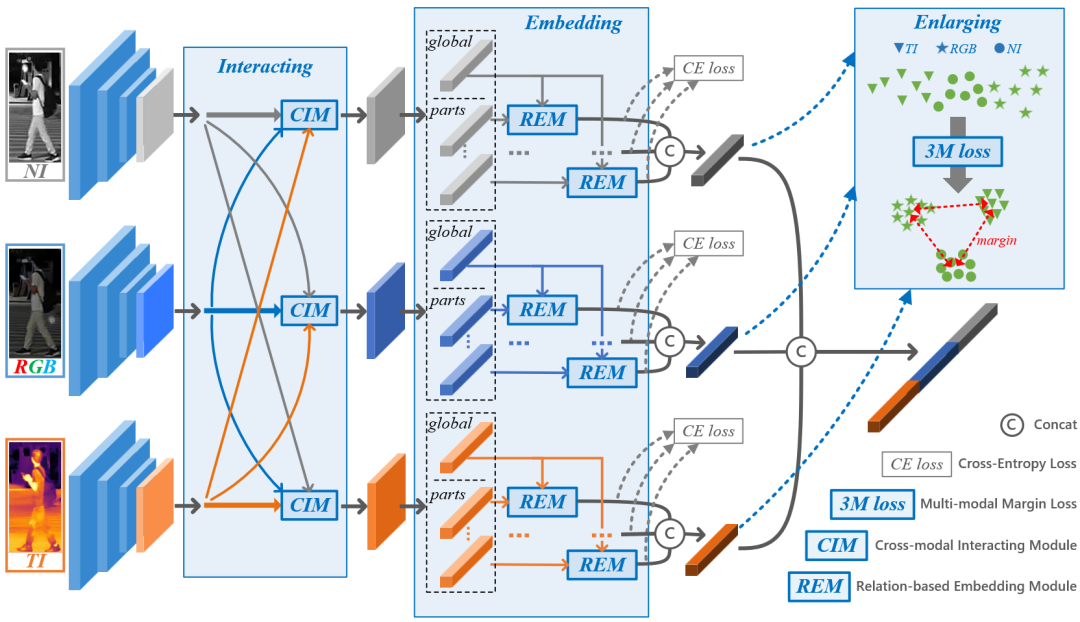
基于模態(tài)特定信息增強(qiáng)的多模態(tài)行人重識(shí)別
Interact, Embed, and EnlargE (IEEE): Boosting Modality-specific Representations for Multi-Modal Person Re-identification
多模態(tài)行人重識(shí)別通過(guò)引入模態(tài)互補(bǔ)信息來(lái)輔助傳統(tǒng)的單模態(tài)重識(shí)別任務(wù)。現(xiàn)有的多模態(tài)方法在融合不同模態(tài)特征的過(guò)程中忽略模態(tài)特異信息的重要性。為此,我們提出了一種新方法來(lái)增強(qiáng)多模態(tài)行人重識(shí)別的模態(tài)特定信息表示 (IEEE) :交互 (Interact) 、嵌入 (Embed) 和擴(kuò)大 (EnlargE) 。
首先,提出了一種新穎的跨模態(tài)交互模塊,用于在特征提取階段在不同模態(tài)之間交換有用的信息。其次,提出了一種基于關(guān)系的嵌入模塊,通過(guò)將全局特征嵌入到細(xì)粒度的局部信息中來(lái)增強(qiáng)模態(tài)特異特征的豐富度。最后,提出了一種新穎的多模態(tài)邊界損失,通過(guò)擴(kuò)大類內(nèi)不同模態(tài)的差異來(lái)迫使網(wǎng)絡(luò)學(xué)習(xí)每種模態(tài)的模態(tài)特定信息。在真實(shí)的和構(gòu)建的行人重識(shí)別數(shù)據(jù)集上優(yōu)越性驗(yàn)證了所提出方法的有效性。
作者:Zi Wang, Chenglong Li, Aihua Zheng, Ran He, Jin Tang
04
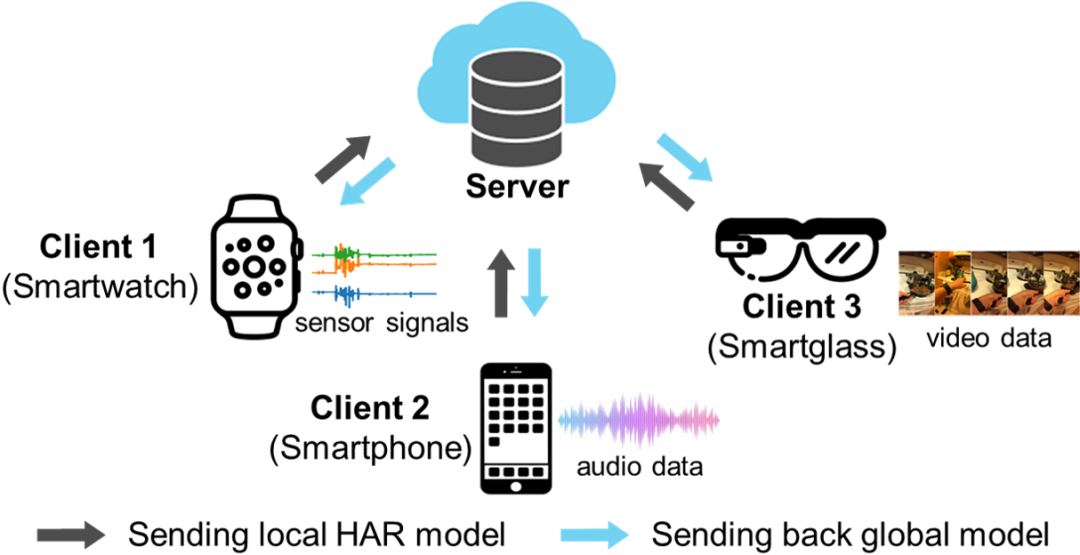
面向人體活動(dòng)識(shí)別的跨模態(tài)聯(lián)邦學(xué)習(xí)
Cross-Modal Federated Human Activity Recognition via Modality-Agnostic and Modality-Specific Representation Learning
為了在更多本地客戶端上進(jìn)行人體活動(dòng)識(shí)別,我們提出一個(gè)新的面向人體活動(dòng)識(shí)別的跨模態(tài)聯(lián)邦學(xué)習(xí)任務(wù)。為了解決這一新問(wèn)題,我們提出一種特征解糾纏的活動(dòng)識(shí)別網(wǎng)絡(luò)(FDARN),模型由共有特征編碼器、私有特征編碼器、模態(tài)判別器、共享活動(dòng)分類器和私有活動(dòng)分類器五個(gè)模塊組成。
共有特征編碼器的目標(biāo)是協(xié)同學(xué)習(xí)不同客戶端樣本的模態(tài)無(wú)關(guān)特征;私有特征編碼器旨在學(xué)習(xí)不能在客戶端之間共享的模態(tài)獨(dú)有特征;模態(tài)鑒別器的作用是以對(duì)抗學(xué)習(xí)的方式指導(dǎo)共有特征編碼器和私有特征編碼器的參數(shù)學(xué)習(xí)。
通過(guò)采用球面模態(tài)判別損失的去中心化優(yōu)化,我們提出的方法可以綜合利用模態(tài)無(wú)關(guān)的客戶端共享特征以及模態(tài)特有的判別特征,因此可以得到在不同客戶端上具有更強(qiáng)泛化能力的模型。在四個(gè)數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果充分表明了該方法的有效性。
作者:Xiaoshan Yang, Baochen Xiong, Yi Huang, Changsheng Xu
05
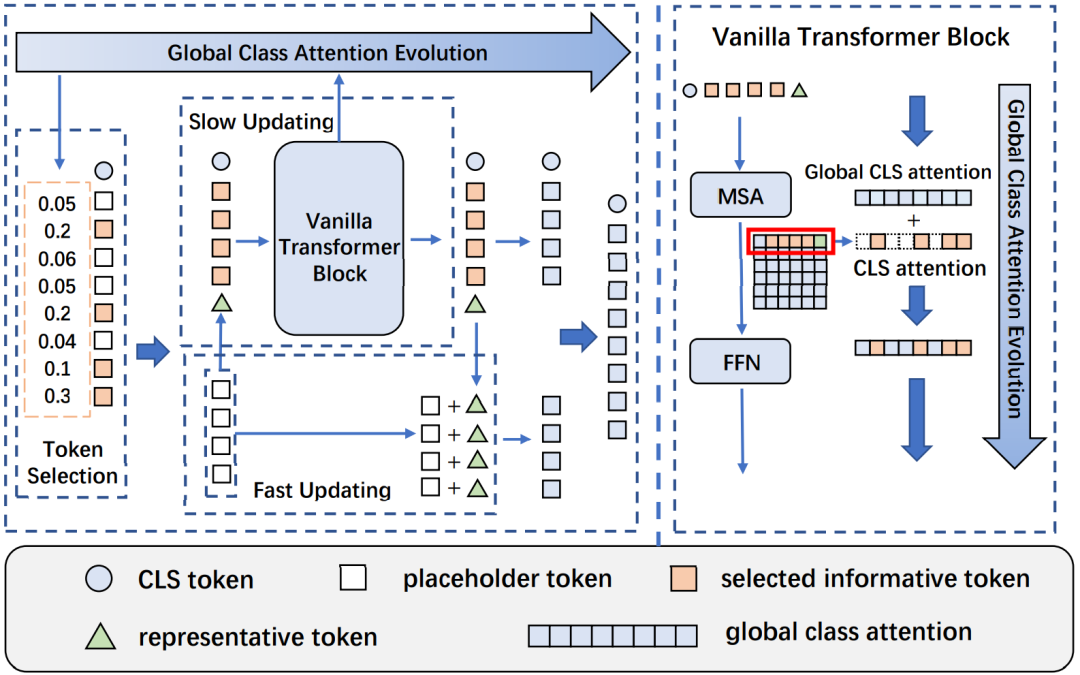
Evo-ViT:基于快速-慢速雙流更新的視覺(jué)Transformer動(dòng)態(tài)加速策略
Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer
視覺(jué)Transformer通過(guò)自注意力機(jī)制捕獲長(zhǎng)程視覺(jué)依賴的能力使其在各種計(jì)算機(jī)視覺(jué)任務(wù)中顯示出巨大的潛力,但是長(zhǎng)程感受野同樣帶來(lái)了巨大的計(jì)算開(kāi)銷,特別是對(duì)于高分辨率視覺(jué)任務(wù)。為了能夠在盡量保持原有模型準(zhǔn)確率的前提下,降低模型計(jì)算復(fù)雜度,從而使得視覺(jué) Transformer成為一種更加通用、高效、低廉的解決框架,目前工作分為基于空間結(jié)構(gòu)先驗(yàn)的結(jié)構(gòu)化壓縮和非結(jié)構(gòu)化特征裁剪兩個(gè)主流方向。其中,非結(jié)構(gòu)化的特征裁剪破壞了二維空間結(jié)構(gòu),使得這類裁剪方法不能適用于基于空間結(jié)構(gòu)先驗(yàn)的結(jié)構(gòu)化壓縮的模型,而目前主流的先進(jìn)視覺(jué)Transformer都應(yīng)用了結(jié)構(gòu)化壓縮。此外,直接裁剪帶來(lái)的不完整的信息流使得目前的特征裁剪方法無(wú)法直接訓(xùn)練得到很好的效果,而要依賴于未裁剪的預(yù)訓(xùn)練模型。
為了解決這些問(wèn)題,我們提出了快速-慢速雙流標(biāo)識(shí)更新策略,在保持了完整空間結(jié)構(gòu)的同時(shí)給高信息量標(biāo)識(shí)和低信息量標(biāo)識(shí)分配不同的計(jì)算通道,從而在不改變網(wǎng)絡(luò)結(jié)構(gòu)的情況下,以極低的精度損失大幅提升直筒狀和金字塔壓縮型的Transformer模型推理性能。不同于以往方法需要依靠外部的可學(xué)習(xí)網(wǎng)絡(luò)來(lái)對(duì)每一層的標(biāo)識(shí)進(jìn)行選擇,我們進(jìn)一步提出了基于Transformer原生的全局類注意力的標(biāo)識(shí)選擇策略來(lái)增強(qiáng)層間的通信聯(lián)系,從而使得我們的方法可以在穩(wěn)定標(biāo)識(shí)選擇的同時(shí)去除了外部可學(xué)習(xí)參數(shù)帶來(lái)的直接訓(xùn)練難的問(wèn)題。
該算法能夠在保證分類準(zhǔn)確率損失較小的情況下,大幅提升各種結(jié)構(gòu)Transformer的推理速度,如在ImageNet-1K數(shù)據(jù)集下,Evo-ViT可以提升DeiT-S 60%推理速度的同時(shí)僅僅損失0.4%的精度。
作者:Yifan Xu, Zhijie Zhang, Mengdan Zhang, Kekai Sheng, Ke Li, Weiming Dong, Liqing Zhang, Changsheng Xu, Xing Sun
06
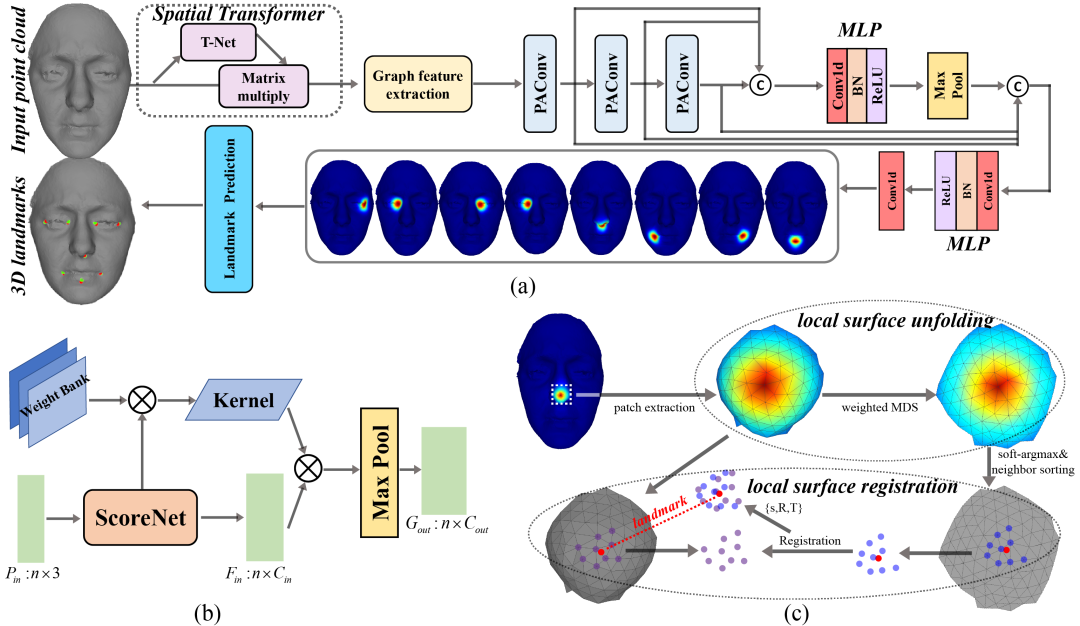
基于圖卷積網(wǎng)絡(luò)及熱力圖回歸的3D人臉關(guān)鍵點(diǎn)檢測(cè)
Learning to detect 3D facial landmarks via heatmap regression with Graph Convolutional Network
三維人臉關(guān)鍵點(diǎn)檢測(cè)廣泛應(yīng)用于人臉配準(zhǔn)、人臉形狀分析、人臉識(shí)別等多個(gè)研究領(lǐng)域。現(xiàn)有的關(guān)鍵點(diǎn)檢測(cè)方法大多涉及傳統(tǒng)特征和三維人臉模型(3DMM),其性能受限于手工制作的中間表征量。
本文提出了一種新的三維人臉關(guān)鍵點(diǎn)檢測(cè)的方法,該方法利用精心設(shè)計(jì)的圖卷積網(wǎng)絡(luò),直接從三維點(diǎn)云中定位關(guān)鍵點(diǎn)的坐標(biāo)。熱力圖是三維人臉上每個(gè)地標(biāo)距離的高斯函數(shù),圖卷積網(wǎng)絡(luò)在構(gòu)建的三維熱力圖的幫助下可以自適應(yīng)學(xué)習(xí)幾何特征,用于三維人臉關(guān)鍵點(diǎn)檢測(cè)。在此基礎(chǔ)上,我們進(jìn)一步探索了局部曲面展開(kāi)與曲面配準(zhǔn)模塊,從3D熱力圖中直接回歸3D坐標(biāo)。
實(shí)驗(yàn)證明,該方法在BU-3DFE和FRGC數(shù)據(jù)集上的關(guān)鍵點(diǎn)定位精度和穩(wěn)定性明顯優(yōu)于現(xiàn)有方法,并在最近的大規(guī)模數(shù)據(jù)集FaceScape上取得了較高的檢測(cè)精度。
作者:YuanWang, Min Cao, Zhenfeng Fan, Silong Peng
07
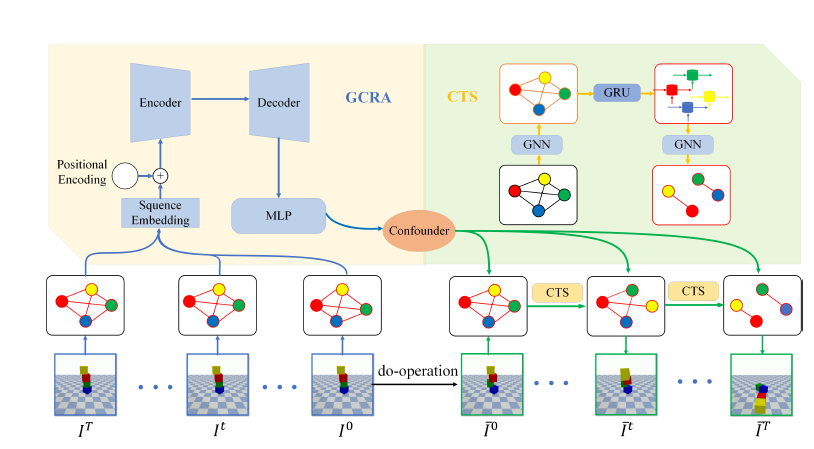
基于因果關(guān)聯(lián)及混雜因子傳遞解耦物理動(dòng)力學(xué)的反事實(shí)預(yù)測(cè)
Deconfounding Physical Dynamics with Global Causal Relation and Confounder Transmission for Counterfactual Prediction
發(fā)現(xiàn)潛在的因果關(guān)系是推理周?chē)h(huán)境和預(yù)測(cè)物理世界未來(lái)狀態(tài)的基礎(chǔ)能力。基于視覺(jué)輸入的反事實(shí)預(yù)測(cè)根據(jù)過(guò)去未出現(xiàn)的情況推斷未來(lái)狀態(tài),是因果關(guān)系任務(wù)中的重要組成部分。
本文研究了物理動(dòng)力學(xué)中的混雜影響因子,包括質(zhì)量、摩擦系數(shù)等,建立干預(yù)變量和未來(lái)狀態(tài)之間的關(guān)聯(lián)關(guān)系,進(jìn)而提出了一種包含全局因果關(guān)系注意力(GCRA)和混雜因子傳輸結(jié)構(gòu)(CTS)的神經(jīng)網(wǎng)絡(luò)框架。GCRA尋找不同變量之間的潛在因果關(guān)聯(lián),通過(guò)捕獲空域和時(shí)序信息來(lái)估計(jì)混雜因子。CTS以殘差的方式整合和傳輸學(xué)習(xí)到的混雜因子,在反事實(shí)預(yù)測(cè)過(guò)程中,通過(guò)編碼對(duì)網(wǎng)絡(luò)中對(duì)象位置進(jìn)行約束。
實(shí)驗(yàn)證明,在混雜因子真實(shí)值未知的情況下,本文的方法能夠充分學(xué)習(xí)并利用混雜因子形成的約束,在相關(guān)數(shù)據(jù)集的預(yù)測(cè)任務(wù)上取得了目前最優(yōu)的性能,并可以較好地泛化到新的環(huán)境,實(shí)現(xiàn)良好的預(yù)測(cè)精度。
作者:Zongzhao Li, Xiangyu Zhu, Zhen Lei(Corresponding author), Zhaoxiang Zhang
08
基于多相機(jī)系統(tǒng)的全局運(yùn)動(dòng)平均算法
MMA: Multi-camera Based Global Motion Averaging
為了實(shí)現(xiàn)三維場(chǎng)景的完全感知,在自動(dòng)駕駛汽車(chē)和智能機(jī)器人等設(shè)備中通常會(huì)安裝多相機(jī)系統(tǒng)以觀察周?chē)?60度的場(chǎng)景。基于多相機(jī)之間剛性固定的約束,我們提出了一種全局式的多相機(jī)運(yùn)動(dòng)平均算法,以實(shí)現(xiàn)全自動(dòng)的大規(guī)模場(chǎng)景快速魯棒建模和多相機(jī)標(biāo)定。
首先,根據(jù)拍攝相機(jī)的不同將圖像分為參考圖像和非參考圖像,進(jìn)而將場(chǎng)景圖中的邊劃分成四類。針對(duì)每一類邊上的多相機(jī)相對(duì)極幾何約束,我們進(jìn)行了重新的推導(dǎo)和展示。基于相對(duì)旋轉(zhuǎn)和絕對(duì)旋轉(zhuǎn)之間的約束,我們提出了一種基于多相機(jī)的旋轉(zhuǎn)平均算法,并通過(guò)一種兩階段(L1+IRLS)的方式對(duì)它進(jìn)行求解。基于相對(duì)平移和絕對(duì)位置之間的約束,我們提出了一種基于多相機(jī)的平移平均算法,通過(guò)求解L1范數(shù)下的優(yōu)化方程獲得所有的攝像機(jī)位姿。
我們?cè)诠_(kāi)的自動(dòng)駕駛數(shù)據(jù)集和多組自采的多相機(jī)數(shù)據(jù)集上進(jìn)行了廣泛的測(cè)試和對(duì)比,顯示我們的建模精度和魯棒性要遠(yuǎn)遠(yuǎn)好于傳統(tǒng)方法。
作者:Hainan Cui, Shuhan Shen

09
基于解耦的屬性特征的魯棒的行人屬性識(shí)別
Learning Disentangled Attribute Representations for Robust Pedestrian Attribute?Recognition
盡管學(xué)界已經(jīng)提出了各種行人屬性識(shí)別的方法,但大多數(shù)研究都遵循相同的特征學(xué)習(xí)機(jī)制,即學(xué)習(xí)一個(gè)共享的行人圖像特征來(lái)對(duì)多個(gè)屬性進(jìn)行分類。然而,這種機(jī)制導(dǎo)致了推理階段的低可信度預(yù)測(cè)和模型的非穩(wěn)健性。
在本文中,我們研究了為什么會(huì)出現(xiàn)這種情況。我們從數(shù)學(xué)上發(fā)現(xiàn),核心原因是在最小化分類損失的情況下,最佳共享特征不能同時(shí)與多個(gè)分類器保持高相似度。此外,這種特征學(xué)習(xí)機(jī)制忽略了不同屬性之間的空間和語(yǔ)義區(qū)別。
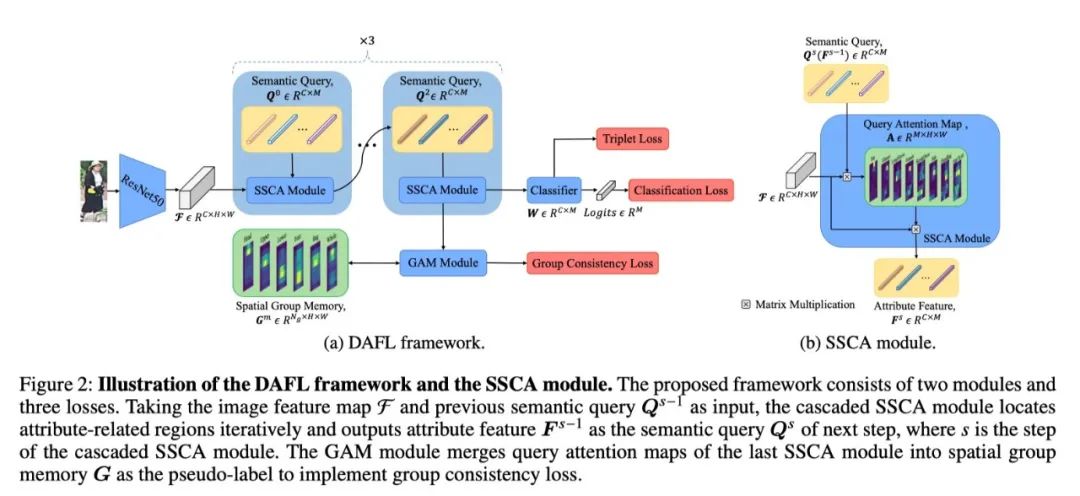
為了解決這些局限性,我們提出了一個(gè)新穎的分離屬性特征學(xué)習(xí)(DAFL)框架,為每個(gè)屬性學(xué)習(xí)一個(gè)分離的特征,該框架利用了屬性的語(yǔ)義和空間特征。該框架主要由可學(xué)習(xí)的語(yǔ)義查詢、級(jí)聯(lián)式語(yǔ)義空間交叉注意(SSCA)模塊和群體注意合并(GAM)模塊組成。具體來(lái)說(shuō),基于可學(xué)習(xí)語(yǔ)義查詢,級(jí)聯(lián)式SSCA模塊迭代地增強(qiáng)了屬性相關(guān)區(qū)域的空間定位,并將區(qū)域特征聚合為多個(gè)分解的屬性特征,用于分類和更新可學(xué)習(xí)語(yǔ)義查詢。GAM模塊根據(jù)空間分布將屬性分成小組,并利用可靠的小組注意力來(lái)監(jiān)督查詢注意力圖。在PETA、RAPv1、PA100k和RAPv2上的實(shí)驗(yàn)表明,所提出的方法與最先進(jìn)的方法相比表現(xiàn)良好。
作者:Jian Jia, Naiyu Gao, Fei He, Xiaotang Chen, Kaiqi Huang
10
基于對(duì)象查詢傳播的高性能視頻物體檢測(cè)
QueryProp: Object Query Propagation for High-Performance Video Object?Detection
視頻物體檢測(cè)旨找出視頻每一幀中包含物體的位置和類別,是一個(gè)重要且具有挑戰(zhàn)性的任務(wù)。傳統(tǒng)方法主要聚焦于設(shè)計(jì)圖像級(jí)別或者物體框級(jí)別的相鄰幀信息傳播方法,以利用視頻時(shí)序信息來(lái)提升檢測(cè)器。本文認(rèn)為,通過(guò)更有效和高效的特征傳播框架,視頻物體檢測(cè)器可以在準(zhǔn)確性和速度方面獲得提升。
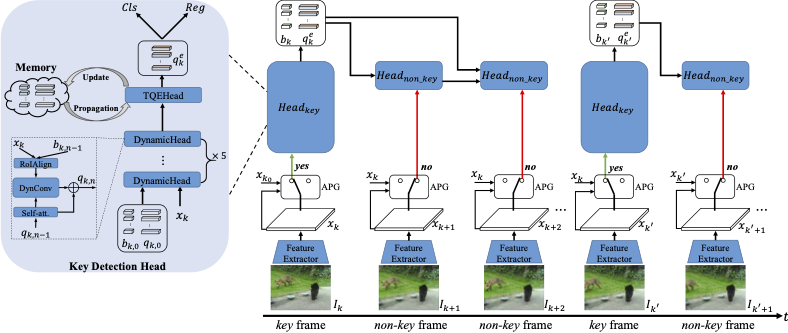
為此,本文研究了對(duì)象級(jí)特征傳播,并提出了一種用于高性能視頻物體檢測(cè)的對(duì)象查詢傳播(QueryProp)框架。提出的QueryProp包含兩種傳播策略:1)對(duì)象查詢從稀疏關(guān)鍵幀傳播至密集非關(guān)鍵幀,以減少對(duì)非關(guān)鍵幀的冗余計(jì)算;2)對(duì)象查詢從之前的關(guān)鍵幀傳播至當(dāng)前關(guān)鍵幀,以建模時(shí)間上下文來(lái)提升特征表示。
為了進(jìn)一步提升查詢傳播的質(zhì)量,我們?cè)O(shè)計(jì)了自適應(yīng)傳播門(mén)以實(shí)現(xiàn)靈活的關(guān)鍵幀選擇。我們?cè)谝曨l物體檢測(cè)的大規(guī)模數(shù)據(jù)集 ImageNet VID 上進(jìn)行了大量實(shí)驗(yàn)。QueryProp 與當(dāng)前最先進(jìn)的方法實(shí)現(xiàn)了可比的準(zhǔn)確性,并在準(zhǔn)確性/速度之間取得了不錯(cuò)的平衡。
作者:Fei He, Naiyu Gao, Jian Jia, Xin Zhao, Kaiqi Huang
11
基于空間相似性的完全稀疏訓(xùn)練加速
Towards Fully Sparse Training: Information Restoration with Spatial Similarity
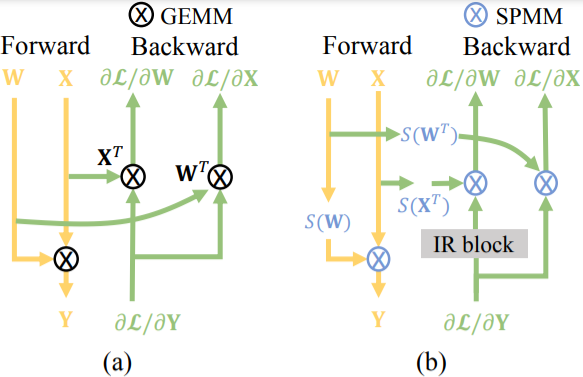
英偉達(dá)安培架構(gòu)發(fā)布的2:4結(jié)構(gòu)化稀疏模式,要求連續(xù)的四個(gè)值至少包含兩個(gè)零元素,可以使得矩陣乘法的計(jì)算吞吐量翻倍。最近的工作主要集中在通過(guò)2:4稀疏性來(lái)提高推理速度,而忽視了其在訓(xùn)練加速方面的潛力,因?yàn)榉聪騻鞑フ紦?jù)了大約70%的訓(xùn)練時(shí)間。然而,與推理階段不同,由于需要保持梯度的保真度并減少在線執(zhí)行2:4稀疏的額外開(kāi)銷,用結(jié)構(gòu)化剪枝來(lái)提高訓(xùn)練速度是不容易的。
本文首次提出了完全稀疏訓(xùn)練,其中"完全"是指在保持精度的同時(shí),對(duì)前向和后向傳播的所有矩陣乘法進(jìn)行結(jié)構(gòu)化修剪。為此,我們從顯著性分析開(kāi)始,研究不同的稀疏對(duì)象對(duì)結(jié)構(gòu)化修剪的敏感性。基于對(duì)激活的空間相似性的觀察,我們提出用固定的2:4掩碼來(lái)修剪激活。此外,我們還提出了一個(gè)信息恢復(fù)模塊來(lái)恢復(fù)丟失的信息,該模塊可以通過(guò)有效的梯度移位操作來(lái)實(shí)現(xiàn)。對(duì)準(zhǔn)確性和效率的評(píng)估表明,在具有挑戰(zhàn)性的大規(guī)模分類和檢測(cè)任務(wù)中,我們可以實(shí)現(xiàn)2倍的訓(xùn)練加速,而準(zhǔn)確性的下降可以忽略不計(jì)。
作者:Weixiang Xu, Xiangyu He, Ke Cheng, Peisong Wang, Jian Cheng
12
通過(guò)學(xué)習(xí)深度神經(jīng)網(wǎng)絡(luò)在語(yǔ)義分割中學(xué)習(xí)噪聲標(biāo)簽的元結(jié)構(gòu)
Deep Neural Networks Learn Meta-Structures from Noisy Labels in Semantic Segmentatio
關(guān)于深度神經(jīng)網(wǎng)絡(luò)(DNN)如何從帶噪標(biāo)簽中進(jìn)行學(xué)習(xí),大部分研究聚焦于圖像分類而不是語(yǔ)義分割。迄今為止,我們對(duì)于深度神經(jīng)網(wǎng)絡(luò)在噪聲分割標(biāo)簽下的學(xué)習(xí)行為仍然知之甚少。
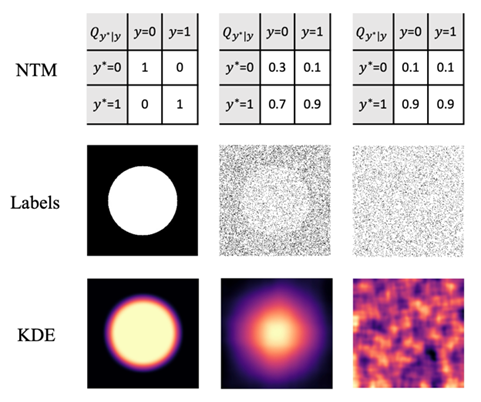
在本研究中,為填補(bǔ)這一空白,我們研究了生物顯微圖像的二類語(yǔ)義分割和自然場(chǎng)景圖像下的多類語(yǔ)義分割。通過(guò)從干凈標(biāo)簽中隨機(jī)抽樣一小部分(例如10%)或隨機(jī)翻轉(zhuǎn)一大部分(例如90%)像素標(biāo)簽,我們合成了信噪比極低的噪聲標(biāo)簽。當(dāng)使用這些低信噪比標(biāo)簽訓(xùn)練DNN時(shí),我們發(fā)現(xiàn)模型的分割性能幾乎沒(méi)有下降。這表明DNN在基于監(jiān)督學(xué)習(xí)的語(yǔ)義分割中是從標(biāo)簽中學(xué)習(xí)語(yǔ)義類別的結(jié)構(gòu)信息,而不僅僅是像素信息。我們將上述標(biāo)簽中隱含的結(jié)構(gòu)信息稱為元結(jié)構(gòu)。當(dāng)我們對(duì)標(biāo)簽中的元結(jié)構(gòu)進(jìn)行不同程度的擾動(dòng),我們發(fā)現(xiàn)模型的分割性能出現(xiàn)不同程度的下降。而當(dāng)我們?cè)跇?biāo)簽中融入元結(jié)構(gòu)時(shí),可以極大提高基于無(wú)監(jiān)督學(xué)習(xí)的二類語(yǔ)義分割模型的性能。我們將元結(jié)構(gòu)在數(shù)學(xué)上定義為點(diǎn)集的空間分布函數(shù),并在理論上和實(shí)驗(yàn)中證明該數(shù)學(xué)模型可以很好的解釋我們?cè)诒狙芯恐杏^察到的深度神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)行為。
作者:Yaoru Luo, Guole Liu, Yuanhao Guo, Ge Yang
01
基于參數(shù)分化的多語(yǔ)言神經(jīng)機(jī)器翻譯
Parameter Differentiation based Multilingual Neural Machine Translation
多語(yǔ)言神經(jīng)機(jī)器翻譯旨在通過(guò)一個(gè)共享的模型同時(shí)處理多個(gè)語(yǔ)言的翻譯,并通過(guò)共享的參數(shù)實(shí)現(xiàn)不同語(yǔ)言之間的知識(shí)遷移。但是,模型中哪些參數(shù)需要共享,哪些參數(shù)是語(yǔ)言獨(dú)有的,仍是一個(gè)開(kāi)放性問(wèn)題。目前,通常的做法是啟發(fā)式地設(shè)計(jì)或者搜索語(yǔ)言特定地模塊,但很難找到一個(gè)最優(yōu)的參數(shù)共享策略。
在本文中,我們提出一個(gè)新穎的基于參數(shù)分化的方法,該方法允許模型在訓(xùn)練的過(guò)程中決定哪些參數(shù)應(yīng)該是語(yǔ)言特定的。受到細(xì)胞分化的啟發(fā),在我們的方法中,每個(gè)通用的參數(shù)都可以動(dòng)態(tài)分化為語(yǔ)言特定的參數(shù)。我們進(jìn)一步將參數(shù)分化準(zhǔn)則定義為任務(wù)間梯度相似性。如果一個(gè)參數(shù)上不同任務(wù)的梯度出現(xiàn)沖突,那么這個(gè)參數(shù)更有可能分化為語(yǔ)言特定的類型。在多語(yǔ)言數(shù)據(jù)集上的實(shí)驗(yàn)表明我們的方法相比于基線方法取得了較大的提升。分析實(shí)驗(yàn)進(jìn)一步揭示了我們的方法生成的參數(shù)共享策略和語(yǔ)言學(xué)特征的相似性具有緊密的關(guān)系。
作者:Qian Wang, Jiajun Zhang
02
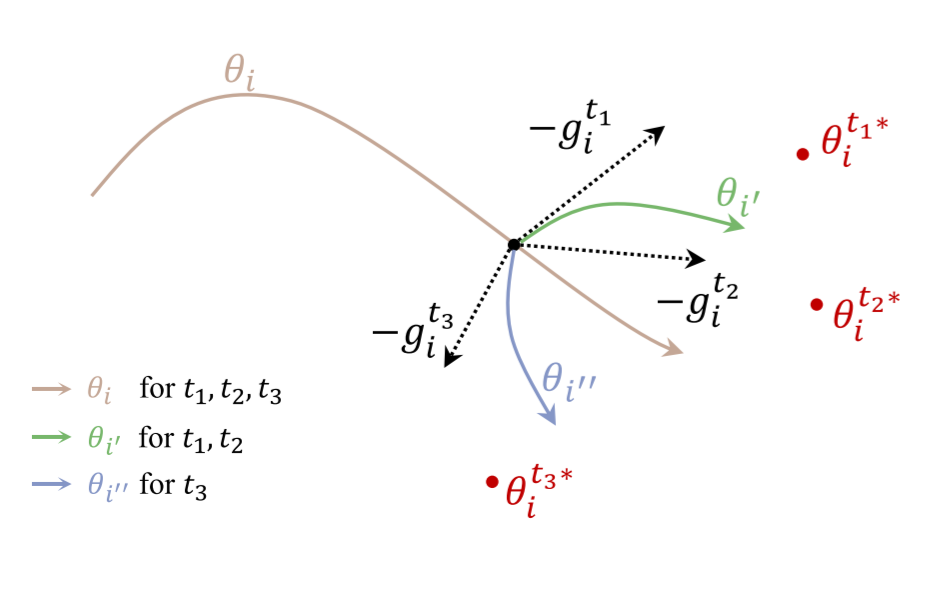
基于特征消除方法的大腦詞匯語(yǔ)法表征研究
Probing Word Syntactic Representations in the Brain by a Feature Elimination Method
神經(jīng)影像研究發(fā)現(xiàn)大腦在理解語(yǔ)言時(shí),多個(gè)腦區(qū)與語(yǔ)義和語(yǔ)法處理相關(guān)。然而,現(xiàn)有的方法不能探索詞性和依存關(guān)系等細(xì)粒度詞匯語(yǔ)法特征的神經(jīng)基礎(chǔ)。
本文提出了一種新的框架來(lái)研究不同詞匯語(yǔ)法特征在大腦中的表征。為了分離不同句法特征,我們提出了一種特征消除方法——均值向量零空間投影(MVNP),來(lái)消除詞向量中的某一特征。然后,我們分別將消除某一特征的詞向量和原始詞向量與大腦成像數(shù)據(jù)聯(lián)系起來(lái),以探索大腦如何表示被消除的特征。本文首次在同一實(shí)驗(yàn)中同時(shí)研究了多個(gè)細(xì)粒度語(yǔ)法特征的皮層表征,并提出了多個(gè)腦區(qū)在語(yǔ)法處理分工中的可能貢獻(xiàn)。這些發(fā)現(xiàn)表明,語(yǔ)法信息處理的大腦基礎(chǔ)可能比經(jīng)典研究所涉及的更為廣泛。
作者:Xiaohan Zhang, Shaonan Wang, Nan Lin, Jiajun Zhang, Chengqing Zong
01
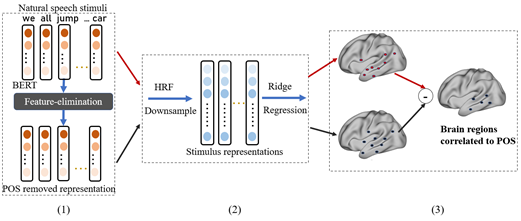
多尺度動(dòng)態(tài)編碼助力脈沖網(wǎng)絡(luò)實(shí)現(xiàn)高效強(qiáng)化學(xué)習(xí)
Multi-scale Dynamic Coding improved Spiking Actor Network for Reinforcement Learning
在深度神經(jīng)網(wǎng)絡(luò)(DNN)的幫助下,深度強(qiáng)化學(xué)習(xí) (DRL) 在許多復(fù)雜任務(wù)上取得了巨大成功,如游戲任務(wù)和機(jī)器人控制任務(wù)。DNN被認(rèn)為只是部分受到了大腦結(jié)構(gòu)和功能的啟發(fā),與之相比,脈沖神經(jīng)網(wǎng)絡(luò) (Spiking Neural Network,SNN) 考慮了更多的生物細(xì)節(jié),包括具有復(fù)雜動(dòng)力學(xué)的脈沖神經(jīng)元和生物合理的可塑性學(xué)習(xí)方法。
受生物大腦中細(xì)胞集群(Cell Assembly)高效計(jì)算的啟發(fā),我們提出了一種多尺度動(dòng)態(tài)編碼方法來(lái)提升脈沖人工網(wǎng)絡(luò)(MDC-SAN)模型,并應(yīng)用于強(qiáng)化學(xué)習(xí)以實(shí)現(xiàn)高效決策。多尺度表現(xiàn)為網(wǎng)絡(luò)尺度的群體編碼和神經(jīng)元尺度的動(dòng)態(tài)神經(jīng)元編碼(包含二階神經(jīng)元?jiǎng)恿W(xué)),可以幫助SNN形成更加強(qiáng)大的時(shí)空狀態(tài)空間表示。大量實(shí)驗(yàn)結(jié)果表明,我們的 MDC-SAN 在 OpenAI Gym的四個(gè)連續(xù)控制任務(wù)上取得了相比無(wú)編碼SNN和相同參數(shù)下DNN更好的性能。
我們認(rèn)為這是一次從生物高效編碼角度探討網(wǎng)絡(luò)性能提升的有效嘗試,就像在生物網(wǎng)絡(luò)中一樣,前期的復(fù)雜化信息編碼可以讓后期的智能決策變得更簡(jiǎn)單。?
作者:Duzhen Zhang, Tielin Zhang, Shuncheng Jia, Bo Xu
詳細(xì)解讀
點(diǎn)擊即可查看
AAAI 2022 |?多尺度動(dòng)態(tài)編碼助力脈沖網(wǎng)絡(luò)實(shí)現(xiàn)高效強(qiáng)化學(xué)習(xí)
02
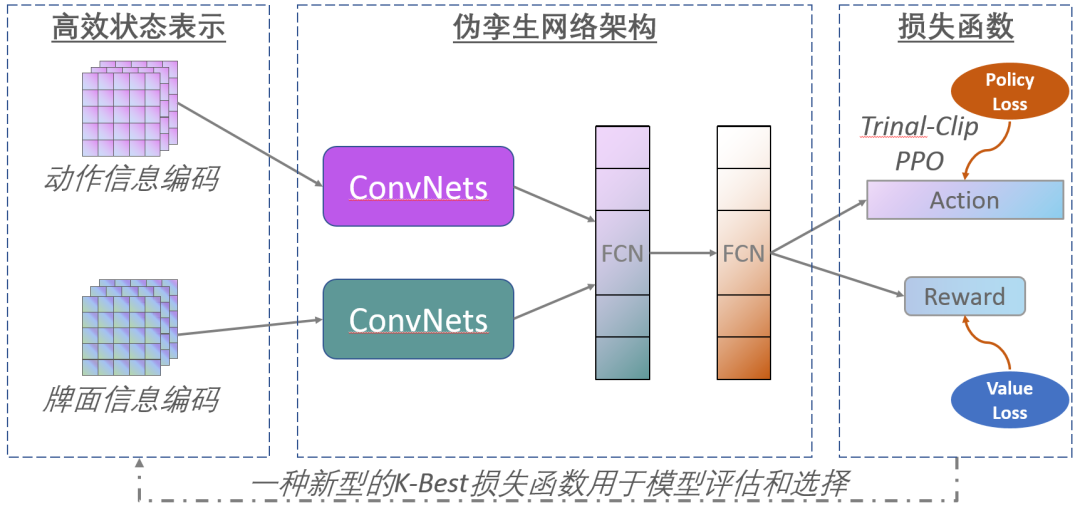
AlphaHoldem: 端到端強(qiáng)化學(xué)習(xí)驅(qū)動(dòng)的高性能兩人無(wú)限注撲克人工智能
AlphaHoldem: High-Performance Artificial Intelligence for Heads-Up No-Limit Poker via End-to-End Reinforcement Learning
無(wú)限注德州撲克(HUNL)是一個(gè)典型的不完美信息博弈。之前的代表性工作如DeepStack和Libratus嚴(yán)重依賴于反事實(shí)遺憾最小化(CFR)算法及其變體來(lái)求解。然而,由于CFR迭代的計(jì)算成本高昂,使得后續(xù)研究人員很難在HUNL中學(xué)習(xí)CFR模型,并將該算法應(yīng)用于其他實(shí)際問(wèn)題。
在這項(xiàng)工作中,我們提出了一個(gè)高性能和輕量級(jí)的德州撲克人工智能AlphaHoldem。AlphaHolddem是一種端到端的自學(xué)習(xí)強(qiáng)化學(xué)習(xí)框架,采用了一種偽孿生網(wǎng)絡(luò)結(jié)構(gòu),通過(guò)將學(xué)習(xí)到的模型與不同的歷史版本進(jìn)行對(duì)打,直接從輸入狀態(tài)信息學(xué)習(xí)到輸出的動(dòng)作。
文章的主要技術(shù)貢獻(xiàn)包括一種新的手牌和投注信息的狀態(tài)表示、一種多任務(wù)的自我游戲訓(xùn)練損失函數(shù),以及一種新的模型評(píng)估和選擇度量來(lái)生成最終的模型。在10萬(wàn)手撲克的研究中,AlphaHoldem只用了三天的訓(xùn)練就擊敗了Slumbot和DeepStack。與此同時(shí),AlphaHoldem只使用一個(gè)CPU核心進(jìn)行每個(gè)決策僅需要4毫秒,比DeepStack快1000多倍。我們將提供一個(gè)在線開(kāi)放測(cè)試平臺(tái),以促進(jìn)在這個(gè)方向上的進(jìn)一步研究。
作者:Enmin Zhao, Renye Yan, Jinqiu Li, Kai Li, Junliang Xing
詳細(xì)解讀
點(diǎn)擊即可查看
人類專業(yè)玩家水平!自動(dòng)化所研發(fā)輕量型德州撲克AI程序AlphaHoldem
03
AutoCFR:通過(guò)學(xué)習(xí)設(shè)計(jì)反事實(shí)后悔值最小化算法
AutoCFR: Learning to Design Counterfactual Regret Minimization Algorithms
反事實(shí)遺憾最小化(Counterfactual Regret Minimization, CFR)算法是最常用的近似求解兩人零和不完美信息博弈的算法。近年來(lái),人們提出了一系列新的CFR變體如CFR+、Lienar CFR、DCFR,顯著提高了樸素CFR算法的收斂速度。然而,這些新的變體大多是由研究人員基于不同的動(dòng)機(jī)通過(guò)反復(fù)試錯(cuò)來(lái)手工設(shè)計(jì)的,通常需要花費(fèi)大量和時(shí)間精力和洞察力。
這項(xiàng)工作提出采用演化學(xué)習(xí)來(lái)元學(xué)習(xí)新的CFR算法,從而減輕人工設(shè)計(jì)算法的負(fù)擔(dān)。我們首先設(shè)計(jì)了一種豐富的搜素語(yǔ)言來(lái)表示現(xiàn)有的手工設(shè)計(jì)的CFR變體。然后我們利用可擴(kuò)展的演化算法以及一系列加速技術(shù),在這種語(yǔ)言所定義的算法的組合空間中進(jìn)行高效地搜索。學(xué)習(xí)到的新的CFR算法可以泛化到訓(xùn)練期間沒(méi)有見(jiàn)過(guò)的新的不完美信息博弈游戲下,并與現(xiàn)有的的最先進(jìn)的CFR變體表現(xiàn)相當(dāng)或更好。
作者:Hang Xu, Kai Li, Haobo Fu, Qiang Fu, Junliang Xing

04
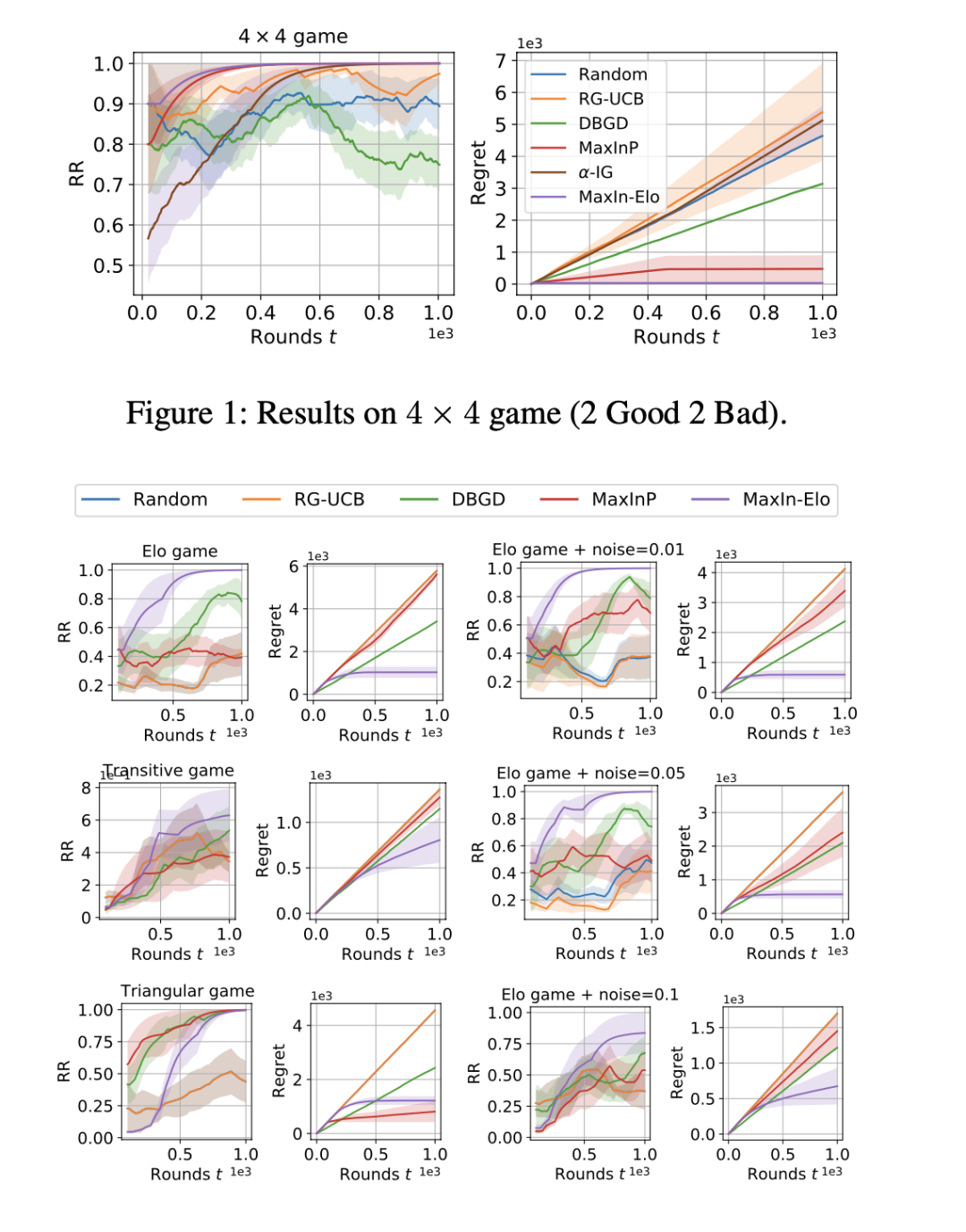
基于對(duì)戰(zhàn)老虎機(jī)方法學(xué)習(xí)頂級(jí)Elo評(píng)級(jí)
Learning to Identify Top Elo Ratings as A Dueling Bandits Problem
Elo 評(píng)分系統(tǒng)被廣泛用于評(píng)估(國(guó)際象棋)游戲和體育競(jìng)技中玩家的技能。最近,它還被集成到機(jī)器學(xué)習(xí)算法中,用于評(píng)估計(jì)算機(jī)化的 AI 智能體的性能。然而,準(zhǔn)確估計(jì) Elo 等級(jí)分(對(duì)于頂級(jí)玩家)通常需要較多輪比賽,而采集多輪對(duì)戰(zhàn)信息的代價(jià)可能是昂貴的。
在本文中,為了盡量減少比較次數(shù)并提高 Elo 評(píng)估的樣本效率(針對(duì)頂級(jí)玩家),我們提出了一種高效的在線匹配調(diào)度算法。具體來(lái)說(shuō),我們通過(guò)對(duì)戰(zhàn)老虎機(jī)(dueling bandits)框架識(shí)別和匹配頂級(jí)玩家,并根據(jù) Elo 基于梯度的更新方式來(lái)設(shè)計(jì)老虎機(jī)算法。我們表明,與傳統(tǒng)的需要 O(t) 時(shí)間的最大似然估計(jì)相比,我們能夠?qū)⒚坎絻?nèi)存和時(shí)間復(fù)雜度降低到常數(shù)。我們的算法有一個(gè)遺憾(regret)保證 O ?(√T) (O ?忽略對(duì)數(shù)因子),與比賽輪數(shù)是次線性相關(guān)。并且算法已經(jīng)被擴(kuò)展到處理非傳遞性游戲的多維 Elo 評(píng)級(jí)。實(shí)驗(yàn)結(jié)果證明我們的方法在各種游戲任務(wù)上實(shí)現(xiàn)了較優(yōu)的收斂速度和時(shí)間效率。
作者:Xue Yan, Yali Du, Binxin Ru, Jun Wang, Haifeng Zhang, Xu Chen
05
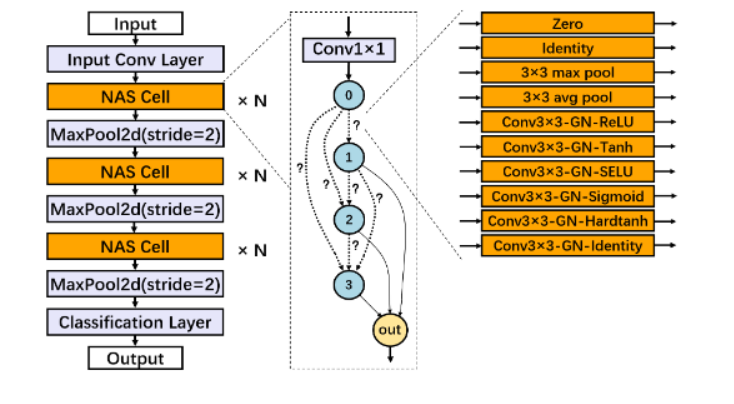
DPNAS:面向差分隱私深度學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索
DPNAS:Neural Architecture Search for Deep Learning with Differential Privacy
在保證有意義的差分隱私(DP)條件下訓(xùn)練深度神經(jīng)網(wǎng)絡(luò)(DNN)通常會(huì)嚴(yán)重降低模型的精度。在本文中我們指出,在面向隱私保護(hù)的深度學(xué)習(xí)中,DNN的拓?fù)浣Y(jié)構(gòu)對(duì)訓(xùn)練得到的模型精度有顯著影響,而這種影響在以前的研究中基本未被探索。
鑒于這一缺失,我們提出了第一個(gè)面向隱私保護(hù)深度學(xué)習(xí)的神經(jīng)網(wǎng)絡(luò)設(shè)計(jì)框架DPNAS。該框架采用神經(jīng)網(wǎng)絡(luò)架構(gòu)搜索來(lái)自動(dòng)設(shè)計(jì)隱私保護(hù)深度學(xué)習(xí)模型。為了將隱私保護(hù)學(xué)習(xí)方法與網(wǎng)絡(luò)架構(gòu)搜索相結(jié)合,我們精心設(shè)計(jì)了一個(gè)新的搜索空間,并提出了一種基于DP的候選模型訓(xùn)練方法。我們通過(guò)實(shí)驗(yàn)證明了所提出框架的有效性。搜索得到的模型DPNASNet實(shí)現(xiàn)了最先進(jìn)的隱私/效用權(quán)衡,例如,在(?,δ)=(3,1×10^-5)的隱私預(yù)算下,我們的模型在MNIST上的測(cè)試準(zhǔn)確率為98.57%,在FashionMNIST上的測(cè)試準(zhǔn)確率為88.09%,在CIFAR-10上的測(cè)試準(zhǔn)確率為68.33%。此外,通過(guò)研究生成的網(wǎng)絡(luò)結(jié)構(gòu),我們提供了一些關(guān)于隱私保護(hù)學(xué)習(xí)友好的DNN的有趣發(fā)現(xiàn),這可以為滿足差分隱私的深度學(xué)習(xí)模型設(shè)計(jì)提供新的思路。
作者:Anda Cheng, Jiaxing Wang, Xi Sheryl Zhang, Qiang Chen, Peisong Wang, Jian Cheng