
基于度量學(xué)習(xí)的行人重識(shí)別(一)
在前面的推文中,我們使用了表征學(xué)習(xí)來(lái)進(jìn)行行人的重識(shí)別,但是在實(shí)際使用的時(shí)候,我們會(huì)發(fā)現(xiàn)一個(gè)問(wèn)題,不同人之間的特征向量距離并不是特別的大,很容易造成誤識(shí)別。那么有沒(méi)有一個(gè)比較好的方法能夠使不同人之間的特征距離盡可能地大而同一個(gè)人之間的距離盡可能小呢?
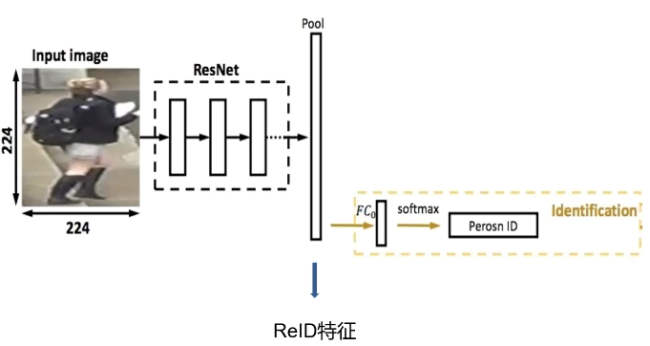
度量學(xué)習(xí)
當(dāng)然是有的,這就是本章要說(shuō)到度量學(xué)習(xí),所謂度量學(xué)習(xí)(Metric Learning)是一種空間映射的方法,其能夠?qū)W習(xí)到一種特征(Embedding)空間,在此空間中,所有的數(shù)據(jù)都被轉(zhuǎn)換成一個(gè)特征向量,并且相似樣本的特征向量之間距離小,不相似樣本的特征向量之間距離大,從而對(duì)數(shù)據(jù)進(jìn)行區(qū)分。度量學(xué)習(xí)應(yīng)用在很多領(lǐng)域中,比如圖像檢索,人臉識(shí)別,目標(biāo)跟蹤等等。
三元組損失
其中,使用最為廣泛的就當(dāng)屬三元組損失了(Triplet loss),Triplet Loss的思想是讓負(fù)樣本對(duì)之間的距離大于正樣本對(duì)之間的距離,在訓(xùn)練過(guò)的過(guò)程中同時(shí)選取一對(duì)正樣本對(duì)和負(fù)樣本對(duì),且正負(fù)樣本對(duì)中有一個(gè)樣本是相同的。以狗、狼、貓數(shù)據(jù)為例,首先隨機(jī)選取一個(gè)樣本,此樣本稱(chēng)之為anchor 樣本,假設(shè)此樣本類(lèi)別為狗,然后選取一個(gè)與anchor樣本同類(lèi)別的樣本(另一個(gè)狗狗),稱(chēng)之為positive,并讓其與anchor樣本組成一個(gè)正樣本對(duì)(anchor-positive);再選取一個(gè)與anchor不同類(lèi)別的樣本(貓),稱(chēng)之為negative,讓其與anchor樣本組成一個(gè)負(fù)樣本對(duì)(anchor-negative)。這樣一共選取了三個(gè)樣本,這也是為什么叫triplet的原因了。
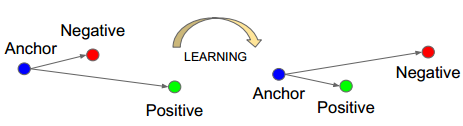
Triplet Loss 的公式如下,通過(guò)公式可以看出,當(dāng)負(fù)樣本對(duì)之間的距離比正樣本對(duì)之間的距離大m的時(shí)候,loss為0 ,認(rèn)為當(dāng)前模型已經(jīng)學(xué)的不錯(cuò)了,所以不對(duì)模型進(jìn)行更新。

Triplet Loss最先被用于人臉識(shí)別中,如下圖,輸入一個(gè)triplet對(duì)(三張圖像),使用同一個(gè)網(wǎng)絡(luò)對(duì)這個(gè)三張圖像進(jìn)行特征提取,得到三個(gè)embedding向量,三個(gè)向量輸入到Triplet Loss中得到loss,然后根據(jù)loss值使用反向傳播算法對(duì)模型進(jìn)行更新。
在python中,Triplet loss的實(shí)現(xiàn)如下
import tensorflow as tffrom keras import backend as Kimport osdef triplet_loss(alpha = 0.2, batch_size = 32):def _triplet_loss(y_true, y_pred):anchor, positive, negative = y_pred[:batch_size], y_pred[batch_size:int(2*batch_size)], y_pred[-batch_size:]# 同一張人臉的 歐幾里得距離pos_dist = K.sqrt(K.sum(K.square(anchor - positive), axis=-1))# 不同人臉的 歐幾里得距離neg_dist = K.sqrt(K.sum(K.square(anchor - negative), axis=-1))# Triplet Lossbasic_loss = pos_dist - neg_dist + alpha #小idxs = tf.where(basic_loss > 0)select_loss = tf.gather_nd(basic_loss,idxs) #大loss = K.sum(K.maximum(basic_loss, 0)) / tf.cast(tf.maximum(1, tf.shape(select_loss)[0]), tf.float32)return lossreturn _triplet_loss
模型結(jié)構(gòu)搭建
接下來(lái)我們進(jìn)行模型搭建,模型我們使用的Google 的MobileNetV2,別問(wèn)為什么,問(wèn)就是它快!代碼如下,由于tensorflow中自帶預(yù)訓(xùn)練模型的優(yōu)勢(shì),我們很快就可以搭建出一個(gè)模型出來(lái)。具體思路為
加載預(yù)訓(xùn)練模型MobileNetV2
獲取MobileNetV2的global_average_pooling2d層的輸出
進(jìn)行隨機(jī)失活,并全連接到128層的特征向量
使用批量標(biāo)準(zhǔn)化層將數(shù)據(jù)標(biāo)準(zhǔn)化
創(chuàng)建基礎(chǔ)模型結(jié)構(gòu)
使用normalize以及 softmax 作為模型的輸出
normalize層我們使用三元組損失進(jìn)行訓(xùn)練、softmax我們使用交叉熵?fù)p失輔助訓(xùn)練,這是為了模型更快地進(jìn)行收斂。
返回訓(xùn)練模型以及基礎(chǔ)模型
from tensorflow.keras.applications import MobileNetV2import tensorflow as tffrom tensorflow.keras.layers import *import tensorflow.keras.backend as K# import os# os.environ['CUDA_VISIBLE_DEVICES'] = "-1"def Create_Model(inpt=(128,128,3),num_classes=10,embedding_size=128, dropout_keep_prob=0.4):inpt = tf.keras.Input(inpt)base_model = MobileNetV2(include_top=True, input_tensor=inpt)out = base_model.get_layer('global_average_pooling2d').outputx = Dropout(1.0 - dropout_keep_prob, name='Dropout')(out)# 全連接層到128# 128x = Dense(embedding_size, use_bias=False, name='Bottleneck')(x)x = BatchNormalization(momentum=0.995, epsilon=0.001, scale=False,name='BatchNorm_Bottleneck')(x)# 創(chuàng)建模型model = tf.keras.Model(inpt, x, name='mobilenet')logits = Dense(num_classes)(model.output)softmax = Activation("softmax", name="Softmax")(logits)normalize = Lambda(lambda x: K.l2_normalize(x, axis=1), name="Embedding")(model.output)combine_model = tf.keras.Model(inpt, [softmax, normalize])x = Lambda(lambda x: K.l2_normalize(x, axis=1), name="Embedding")(model.output)model = tf.keras.Model(inpt, x)return combine_model,model
然后使用下面的代碼就可以看到我們的模型結(jié)構(gòu)啦!
model,_= Create_Model()model.summary()
最重要的數(shù)據(jù)處理以及模型訓(xùn)練由于篇幅的原因,就往后稍稍啦!有興趣的同學(xué)記得關(guān)注一波