
基于表征學(xué)習(xí)的行人重識別(二)
在前面的推文中,我想你已經(jīng)訓(xùn)練好了一個行人重識別的模型,那么我們應(yīng)該怎么使用這個模型呢?
前面我們提到過,測試的時候我們會拋棄最后的輸出層不用,而使用倒數(shù)第二層的全局平均池化作為輸出。這是因?yàn)槲覀兛梢酝ㄟ^這一層輸出圖片的特征向量,并計算圖像之間的相似度。用來判別兩張圖片是否是同一人。
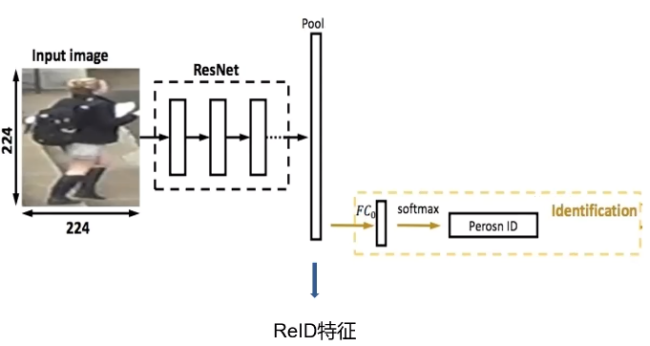
計算圖像的相似度有很多種方法,例如歐式距離,余弦距離,漢明距離等。這里我們使用的歐氏距離,歐氏距離是最常見的距離度量(用于衡量個體在空間上存在的距離,距離越遠(yuǎn)說明個體間的差異越大)。
# 歐氏距離 #
歐式距離的公式如下,當(dāng) p = 1 時,稱為曼哈頓距離;當(dāng) p = 2 時,稱為歐式距離;當(dāng) p = ∞ 時,稱為切比雪夫距離。它是各個坐標(biāo)距離的最大值。
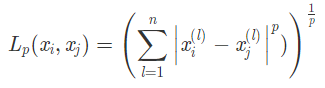
那么,在python中,我們?nèi)绾斡嬎氵@個歐式距離呢,在numpy中,已經(jīng)幫我們實(shí)現(xiàn)了這個功能,我們只需要使用numpy中求范數(shù)的方法 np.linalg.norm()即可實(shí)現(xiàn)。
#01
特征向量提取
接下來,我們來實(shí)際操作一番,完成行人重識別的測試吧,新建一個test.py文件,首先導(dǎo)入依賴,然后去掉最后的FC層。完成提取特征向量的模型。
import osimport cv2import tensorflow.keras as kimport globfrom image_recognition.DarkNet.model import dreaknet53_outputimport numpy as npfrom tqdm import tqdmimport matplotlib.pyplot as pltimport matplotlib.image as imgpltinpt=k.Input((200,60,3))model=dreaknet53_output(inpt)model.load_weights('darknet_reid.h5')out=model.get_layer('global_average_pooling2d').outputmodel=k.models.Model(inpt,out)model.summary()
#02
歐式距離計算
接著,我們寫入如下4個函數(shù),分別對應(yīng)的功能是,l2正則化,將特征向量的值變小;求歐氏距離;判斷距離和預(yù)設(shè)值的關(guān)系;獲得特征向量。
# 正則化def l2_normalize(x,axis=1,epsilon=1e-10):output=x/np.sqrt(np.maximum(np.sum(np.square(x),axis=axis,keepdims=True),epsilon))return output# 求歐式距離def person_distance(person_encodings,person_unknow):if len(person_encodings)==0:return np.empty((0))return np.linalg.norm(person_encodings-person_unknow,axis=1)# 判斷距離是否小于預(yù)設(shè)值def com_person(person_list,person,tolerance=0.8):dis=person_distance(person_list,person)return list(dis <= tolerance)# 獲得特征向量def get_fulters(img):img=cv2.resize(img,(60,200))img=img.reshape(-1,200,60,3)/255.p=model.predict(img)norm=l2_normalize(p).reshape([1024])return norm
#03
識別結(jié)果可視化
接著,我們可以對測試數(shù)據(jù)集進(jìn)行提取,定義重識別的id進(jìn)行對比,獲得重識別的圖片。
# 路徑path=r'E:\DataSets\DukeMTMC-reID\DukeMTMC-reID\bounding_box_test'image_paths=[os.path.join(path,p) for p in os.listdir(path)]#要進(jìn)行重識別的行人idrandom_persons=['0005','0019','0023']# 存放重識別的路徑img_dict={}for person in random_persons:img_paths=glob.glob(os.path.join(path,'%s_*'%person))# 隨機(jī)取得一張圖片img_path=np.random.choice(img_paths,1)[0]img_dict[person]=[img_path]# 獲得特征向量know_img=cv2.imread(img_path)know_img_norm=get_fulters(know_img)# 在未知的圖片中進(jìn)行特征向量的對比for path_ in tqdm(image_paths):unknow_img=cv2.imread(path_)unknow_img_norm=get_fulters(unknow_img)out = com_person([unknow_img_norm],know_img_norm , tolerance=0.58)if out[0]:print(out,path_)img_dict[person].append(path_)# 只獲取前4張重識別的圖片if len(img_dict[person])>4:break
最后,我們可以通過matplotlib對重識別的結(jié)果進(jìn)行可視化:
plt.figure()i = 1for key in img_dict.keys():img_paths=img_dict[key]for img_ in img_paths:img=imgplt.imread(img_)# 判斷重識別是否正確if img_.split('\\')[-1].split('_')[0]!=key:img=img*[1,0,0]# 定義一個 3行5列的圖plt.subplot(3,5,i)plt.imshow(img)plt.xticks([])plt.yticks([])i+=1plt.show()
程序運(yùn)行結(jié)果如下,第一列的圖片是我們隨機(jī)選取的某個id的圖片,作為我們的已知數(shù)據(jù),后4列是進(jìn)行重識別之后的結(jié)果:

#04
小結(jié)
本實(shí)驗(yàn)涉及到了DarkNet53、行人重識別等。DrkNet53被應(yīng)用在yolov3中,是一個優(yōu)秀的特征提取網(wǎng)絡(luò)。Yolov4也在DarkNet53的基礎(chǔ)上修改或增加了一些tricks,如SPPNet、CSPNet不僅提高了精度,還提高了速度。而行人重識別是一個比較大的領(lǐng)域,如果你多次運(yùn)行我們的測試程序,你會發(fā)現(xiàn)一些有意思的情況發(fā)生:

如果我們隨機(jī)取到的已知圖片出現(xiàn)了多個人重疊的情況,后續(xù)的重識別效果并不理想,這也說明,行人檢測算法的精度對行人重識別算法具有一定的影響。
#05
后續(xù)
表征學(xué)習(xí)的內(nèi)容到此就結(jié)束了,運(yùn)行過程序的小伙伴們應(yīng)該會發(fā)現(xiàn)一個問題,不同人之間的特征向量距離并不是特別的大,很容易造成誤識別。那么有沒有一個比較好的方法能夠使不同人之間的特征距離盡可能地大而同一個人之間的距離盡可能小呢?歡迎點(diǎn)關(guān)注接收后續(xù)推文 ,最終實(shí)現(xiàn)效果在本次推文中的視頻可以看到哦!
,最終實(shí)現(xiàn)效果在本次推文中的視頻可以看到哦!