
GPU架構和渲染技術
 ?
?

GPU技術篇
- GPU分析:全球競爭格局與未來發(fā)展
- 2023年GPU顯卡技術詞條報告
- 英偉達GPU龍頭穩(wěn)固,國內(nèi)逐步追趕(詳解)
- GPU/CPU領域散熱工藝的發(fā)展與路徑演繹
- 探析ARM第五代GPU架構
- 新型GPU云桌面發(fā)展白皮書
- 十大國產(chǎn)GPU產(chǎn)品及規(guī)格概述
- GPU平臺生態(tài):英偉達CUDA和AMD ROCm對比分析
- GPU競爭壁壘:微架構和平臺生態(tài)
- GPU微架構、性能指標、場景、生態(tài)鏈及競爭格局(2023)
- 大模型訓練,繞不開GPU和英偉達
- Nvidia/AMD競爭:GPU架構創(chuàng)新和新興領域前瞻探索
- 走進芯時代:AI算力GPU行業(yè)深度報告
- 獨立GPU市場,AMD份額大跌?
- CPU渲染和GPU渲染優(yōu)劣分析
- NVIDIA Hopper GPU:芯片三圍、架構、成本和性能分析
- 國內(nèi)GPU廠商及細分行業(yè)前景(2023)
- ChatGPT對GPU算力的需求測算與分析
- AMD RDNA2 GPU架構詳解
- GPU研究框架(2023)
GPU架構 GPU概括來講,就是由顯存和許多計算單元組成。 顯存(Global Memory)主要指的是在GPU主板上的DRAM,類似于CPU的內(nèi)存,特點是容量大但是速度慢,CPU和GPU都可以訪問。 計算單元通常是指SM(Stream Multiprocessor,流多處理器),這些SM在不同的顯卡上組織方式還不太一樣。作為執(zhí)行計算的單元,其內(nèi)部還有自己的控制模塊、寄存器、緩存、指令流水線等部件。
 計算單元
計算單元
下面是Maxwell架構圖和Turing架構圖。
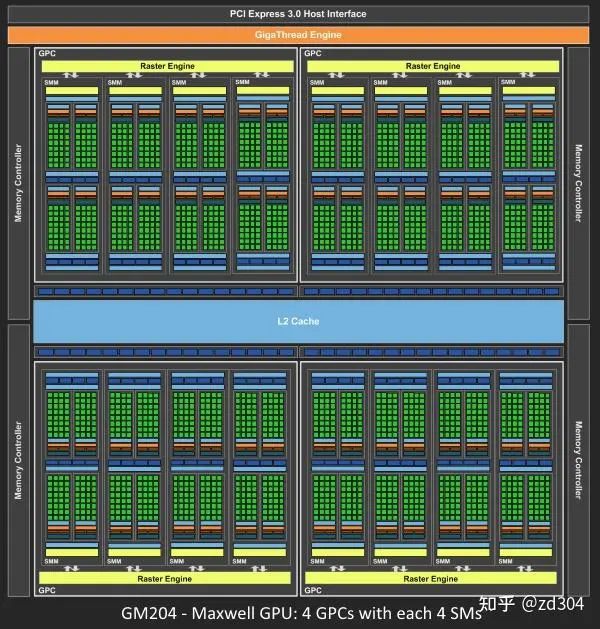 Maxwell架構圖
Maxwell架構圖
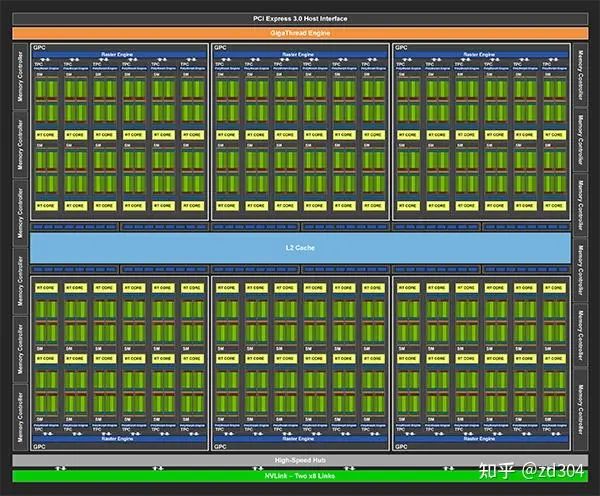 Turing架構圖 從Fermi開始NVIDIA使用類似的原理架構。 GPU包含若干個GPC(Graphics Processing Cluster,圖形處理簇),不同架構的GPU包含的GPC數(shù)量不一樣。例如Maxwell由4個GPC組成;Turing由6個GPC組成。 GPC包含若干個SM(Stream Multiprocessor,流多處理器),不同架構的GPU的GPC包含的SM數(shù)量不一樣。例如Maxwell的一個GPC有4個SM;而Turing的一個GPC包含了6個TPC(Texture/Processor Cluster,紋理處理簇),每個TPC又包含了2個SM。
Turing架構圖 從Fermi開始NVIDIA使用類似的原理架構。 GPU包含若干個GPC(Graphics Processing Cluster,圖形處理簇),不同架構的GPU包含的GPC數(shù)量不一樣。例如Maxwell由4個GPC組成;Turing由6個GPC組成。 GPC包含若干個SM(Stream Multiprocessor,流多處理器),不同架構的GPU的GPC包含的SM數(shù)量不一樣。例如Maxwell的一個GPC有4個SM;而Turing的一個GPC包含了6個TPC(Texture/Processor Cluster,紋理處理簇),每個TPC又包含了2個SM。
補充:GPC里除了有SM還有一些其它的部件,比如光柵化引擎(Raster Engine)。另外,連接每個GPC靠的是Crossbar,例如某一個GPC計算完的數(shù)據(jù)需要另外GPC來處理,這個分配就是靠的Crossbar。這里的SM就是本章節(jié)所說的計算單元,同時需要知道的是,程序員平時寫的Shader就是在SM上進行處理的。
SM(Stream Multiprocessor,流多處理器)
不同GPU廠商的架構中,SM的叫法不盡相同。-
? 高通稱作Streaming Processor / Shder Processor。
-
? Mali稱作Shader Core。
-
? PowerVR稱作Unified Shading Cluster,通常簡稱為Shading Cluster或USC。
-
? ATI/OpenCL稱作Compute Unit,通常簡稱為CU。
 以Fermi架構的單個SM來說,其包含以下部件。
以Fermi架構的單個SM來說,其包含以下部件。
-
? PolyMorph Engine:多邊形變形引擎。負責處理和多邊形頂點相關的工作,包括以下模塊。
-
? Vertex Fetch模塊:頂點處理前期的通過三角形索引取出三角形數(shù)據(jù)。
-
? Tesselator模塊:對應著DX11引入的新特性曲面細分。
-
? Stream Output模塊:對應著DX10引入的新特性Stream Output。
-
? Viewport Transform模塊:對應著頂點的視口變換,三角形會被裁剪準備柵格化。
-
? Attribute Setup模塊:負責頂點的插值運算并輸出給后續(xù)像素處理階段使用。
-
? Core:運算核心,也叫流處理器(SP——Stream Processor)。每個SM由32個運算核心組成。由Warp Scheduler調度,接收Dispatch Units的指令并執(zhí)行,下面會詳細介紹。
-
? Warp Schedulers:Warp調度模塊。Warp的概念其實就是一組線程,通常由32個線程組成,對應著32個運算核心。Warp調度器的指令通過Dispatch Units送到運算核心(Core)執(zhí)行。
-
? Instruction Cache:指令緩存。存放將要執(zhí)行的指令,通過Dispatch Units填裝到每個運算核心(Core)進行運算。
-
? SFU:特殊函數(shù)單元(Special function units)。與Adreno GPU中的初等函數(shù)單元(Elementary Function Unit,EFU)類似,執(zhí)行特殊數(shù)學運算。由于其數(shù)量少,在高級數(shù)學函數(shù)使用較多時有明顯瓶頸。特殊函數(shù)例如以下幾類。
-
? 冪函數(shù):pow(x, a)、sqrt(x)。
-
? 對數(shù)函數(shù):log(x)、log2(x)。
-
? 三角函數(shù):sin(x)、cos(x)、tan(x)。
-
? 反三角函數(shù):asin(x)、acos(x)、atan(x)。
-
? LD/ST:加載/存儲模塊(Load/Store)。輔助一個Warp(線程組)從Share Memory或顯存加載(Load)或存儲(Store)數(shù)據(jù)。
-
? Register File:寄存器堆。存放將要處理的數(shù)據(jù)。
-
? L1 Cache:L1緩存。不同GPU架構不一樣,有些L1緩存和Shared Memory共用,有的L1緩存和Texture Cache共用。
-
? Uniform Cache:全局統(tǒng)一內(nèi)存緩存。
-
? Tex Unit和Texture Cache:紋理讀取單元和紋理緩存。Fermi有4個Texture Units,每個Texture Unit在一個運算周期最多可取4個采樣器,這時剛好喂給一個線程束(Warp)(的16個車道),每個Texture Uint有16K的Texture Cache,并且在往下有L2 Cache的支持。
-
? Interconnect Network:內(nèi)部鏈接網(wǎng)絡。
-
-
GPU內(nèi)存架構
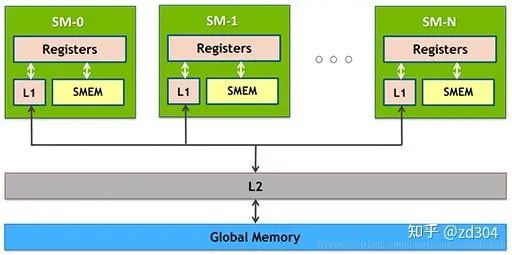 圖中越往上,存取速度越快,越往下存取速度越慢。其中, Global Memory(全局內(nèi)存) 即我們通常所說的顯存,通常放在GPU芯片的外部。 L2 Cache 是GPU芯片內(nèi)部跨GPC而存在的。 L1 Cache/Shared Memory 、 Uniform Cache 、 Tex Unit 和 Texture Cache 以及 寄存器 都是存在于SM內(nèi)部的。 它們的存取速度從寄存器到全局內(nèi)存依次變慢:
圖中越往上,存取速度越快,越往下存取速度越慢。其中, Global Memory(全局內(nèi)存) 即我們通常所說的顯存,通常放在GPU芯片的外部。 L2 Cache 是GPU芯片內(nèi)部跨GPC而存在的。 L1 Cache/Shared Memory 、 Uniform Cache 、 Tex Unit 和 Texture Cache 以及 寄存器 都是存在于SM內(nèi)部的。 它們的存取速度從寄存器到全局內(nèi)存依次變慢:
| 存儲類型 | 訪問周期 |
| 寄存器 | 1 |
| 共享內(nèi)存 | 1~32 |
| L1緩存 | 1~32 |
| L2緩存 | 32~64 |
| 紋理、常量緩存 | 400~600 |
| 全局內(nèi)存 | 400~600 |
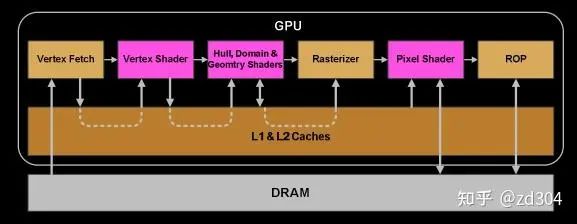 應用階段
應用階段
這個階段主要是CPU在準備數(shù)據(jù),包括圖元數(shù)據(jù)、渲染狀態(tài)等,并將數(shù)據(jù)傳給GPU的過程。如下圖所示就是數(shù)據(jù)如何進入GPU處理的過程。
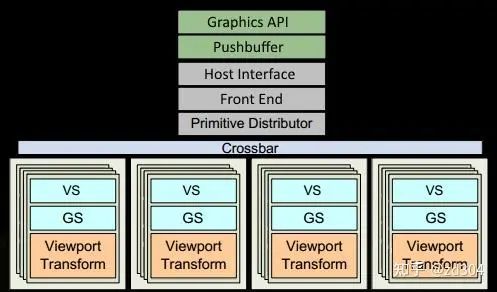 CPU和GPU之間的數(shù)據(jù)傳輸是一個異步的過程,類似于服務器和客戶端之間的數(shù)據(jù)傳輸。CPU和GPU構造了一種生產(chǎn)者/消費者異步處理模型。CPU生產(chǎn)“命令”,GPU消費“命令”,通過這種關系CPU就可以將數(shù)據(jù)和行為傳輸?shù)紾PU,GPU來執(zhí)行對應動作。 CPU端通過調用渲染API(Graphics API),比如DX或者GL,將操作封裝為一個一個的命令存放到命令隊列中(FIFO Push Buffer),即上圖中的PushBuffer。 當內(nèi)存寫滿或者顯示調用(Present或者Flush等)提交命令隊列的時候,CPU將命令隊列提交給應用驅動,并在命令隊列末尾壓入一條改變Fence值的命令。 接下來,通過系統(tǒng)驅動的調度,輪到這個應用傳輸?shù)臅r候,就將數(shù)據(jù)寫入到內(nèi)存中的RingBuffer中。RingBuffer好比一個旋轉的水車,將命令一點一點“搬運”到GPU的前端(Front End)。當這個“水車”滿了,也就是RingBuffer滿了,CPU就會發(fā)生擁塞。
CPU和GPU之間的數(shù)據(jù)傳輸是一個異步的過程,類似于服務器和客戶端之間的數(shù)據(jù)傳輸。CPU和GPU構造了一種生產(chǎn)者/消費者異步處理模型。CPU生產(chǎn)“命令”,GPU消費“命令”,通過這種關系CPU就可以將數(shù)據(jù)和行為傳輸?shù)紾PU,GPU來執(zhí)行對應動作。 CPU端通過調用渲染API(Graphics API),比如DX或者GL,將操作封裝為一個一個的命令存放到命令隊列中(FIFO Push Buffer),即上圖中的PushBuffer。 當內(nèi)存寫滿或者顯示調用(Present或者Flush等)提交命令隊列的時候,CPU將命令隊列提交給應用驅動,并在命令隊列末尾壓入一條改變Fence值的命令。 接下來,通過系統(tǒng)驅動的調度,輪到這個應用傳輸?shù)臅r候,就將數(shù)據(jù)寫入到內(nèi)存中的RingBuffer中。RingBuffer好比一個旋轉的水車,將命令一點一點“搬運”到GPU的前端(Front End)。當這個“水車”滿了,也就是RingBuffer滿了,CPU就會發(fā)生擁塞。
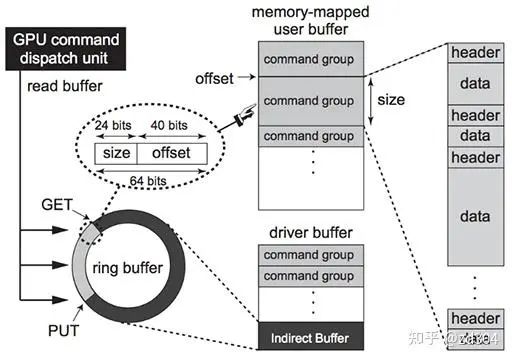 當命令隊列最后一條命令,也就是修改Fence值的命令被前端接收后,CPU接到了Fence修改的信號,擁塞就會被解除,CPU繼續(xù)運行產(chǎn)生接下來的命令。
當命令隊列最后一條命令,也就是修改Fence值的命令被前端接收后,CPU接到了Fence修改的信號,擁塞就會被解除,CPU繼續(xù)運行產(chǎn)生接下來的命令。
圖元裝配器(Primitive Distributor)根據(jù)圖元類型、頂點索引以及圖元裝配命令,開始分配渲染工作,并發(fā)送給多個GPC處理。
頂點處理 PolyMorph Engine的Vertex Fetch模塊通過三角形索引,將數(shù)據(jù)從顯存中取得三角形數(shù)據(jù),傳入SM寄存器中。 前文說過Shader就是在SM上進行處理的。熟悉Shader開發(fā)的人都知道,Shader會對不同的“語義”進行處理,這些語義也叫“寄存器”。Shader中使用到的寄存器不光這些“語義”的寄存器,它們分為很多種類型,包括輸入寄存器、常量寄存器、臨時寄存器等。| |
Shader Model 2.0/2.X | Shader Model 3.0 | Shader Model 4.0 |
| 臨時寄存器 | ≥12 | 32 | 4096 |
| VS常量寄存器 | ≥256 | ≥256 | 14×4096 |
| PS常量寄存器 | 32 | 224 | 14×4096 |
| VS紋理 | None | 4 | 128×512 |
| PS紋理 | 16 | 16 | 128×512 |
| VS輸入寄存器 | 16 | 16 | 16 |
| 插值寄存器 | 8 | 10 | 16/32 |
| PS輸出寄存器 | 4 | 4 | 8 |
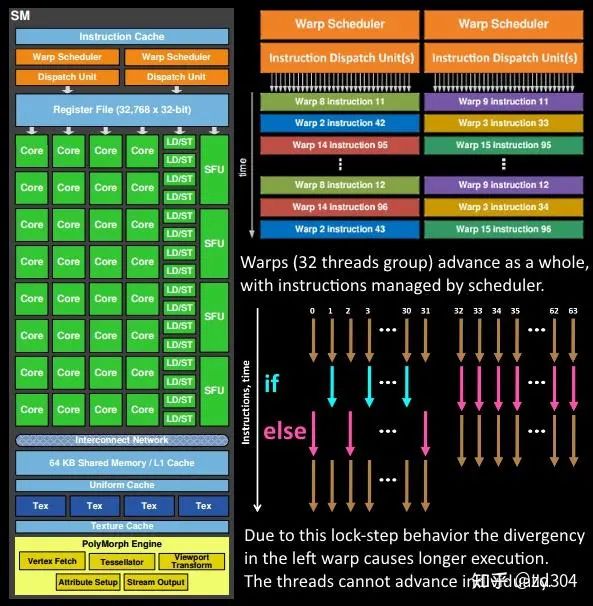 那么要深入理解SM工作的這種機制,這里需要解釋一下三個重要的概念: 統(tǒng)一著色器架構 、 SIMT 和 線程束 。
那么要深入理解SM工作的這種機制,這里需要解釋一下三個重要的概念: 統(tǒng)一著色器架構 、 SIMT 和 線程束 。
統(tǒng)一著色器架構
Shader Model 在誕生之初就為我們提供了Pixel Shader(頂點著色器)和Vertex Shader(像素著色器)兩種具體的硬件邏輯,它們是互相分置彼此不干涉的。 但是在長期的開發(fā)過程中,發(fā)現(xiàn)了以下的問題。-
? 如果一個場景包含的三角形相當細碎,那么這個為了渲染這個場景,頂點著色器的處理單元就會負載很高,但是會有很大一部分像素著色器的處理單元閑置。
-
? 如果一個場景僅包含一個大的三角形,而且這個大三角形覆蓋了大部分的屏幕像素且運算很復雜,那么像素著色器的處理單元就會負載很高,但是會有一大部分頂點著色器的處理單元閑置。
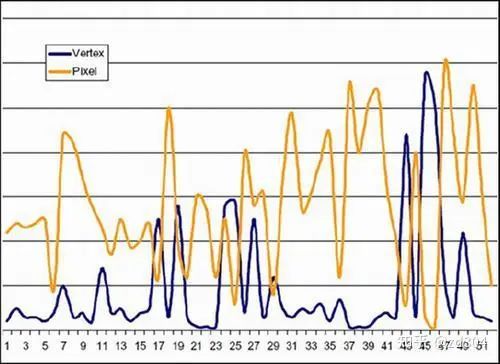 在長期的發(fā)展過程中,NVIDIA和ATI的工程師都認為,要達到最佳的性能和電力使用效率,還是必須使用統(tǒng)一著色器架構才能解決上述問題。 在統(tǒng)一著色器架構的GPU中,Vertex Shader和Pixel Shader概念都將被廢除,取而代之的就是“運算核心(Core)”。運算核心是個完整的圖形處理體系,它既能夠執(zhí)行對頂點操作的指令(代替VS),又能夠執(zhí)行對象素操作的指令(代替PS)。GPU內(nèi)部的運算核心甚至能夠根據(jù)需要隨意切換調用,從而極大的提升游戲的表現(xiàn)。
在長期的發(fā)展過程中,NVIDIA和ATI的工程師都認為,要達到最佳的性能和電力使用效率,還是必須使用統(tǒng)一著色器架構才能解決上述問題。 在統(tǒng)一著色器架構的GPU中,Vertex Shader和Pixel Shader概念都將被廢除,取而代之的就是“運算核心(Core)”。運算核心是個完整的圖形處理體系,它既能夠執(zhí)行對頂點操作的指令(代替VS),又能夠執(zhí)行對象素操作的指令(代替PS)。GPU內(nèi)部的運算核心甚至能夠根據(jù)需要隨意切換調用,從而極大的提升游戲的表現(xiàn)。
SIMT
前文提到指令(Instruction)會經(jīng)過調度單元(Dispatch Unit)的調度,分配到每一個運算核心去執(zhí)行。 那么,指令是什么呢?其實指令可以理解為一條一條的操作命令,也就是告訴運算核心要怎么做的“描述語句”。比如 “將tmp25號寄存器里的值加上tmp26號寄存器里的值,得到的值存入tmp27號寄存器”這種操作,就是一條指令。 調度單元這里分配給每一個運行核心去執(zhí)行的指令其實都是相同的。也就是說調度單元(Dispatch Unit)讓每個運算核心在同一刻干的事情都是一樣的。每一個運算核心雖然同一時刻做的操作是一樣的,但是它們所操作的數(shù)據(jù)各自都是不同的。 舉個例子,還是上面的這條指令——“將tmp25號寄存器里的值加上tmp26號寄存器里的值,得到的值存入tmp27號寄存器”。對于A運算核心和B運算核心來說,它們各自的tmp25號、tmp26號寄存器里存的值都是不一樣的,以下為兩個核心可能出現(xiàn)情況的例子。-
? 對于A運算核心來說,tmp25號存了“2”,tmp26號存了“3”,最終計算后寫入tmp27號寄存器的數(shù)是“5”。
-
? 對于B運算核心來說,tmp25號存了“8”,tmp26號存了“12”,最終計算后寫入tmp27號寄存器的數(shù)是“20”。
線程束
每個SM包含了很多寄存器,每個Shader核心函數(shù)(VS/GS/PS等)會當作一個線程去執(zhí)行。Shader經(jīng)過編譯后,可以明確知道要執(zhí)行的核心函數(shù)需要多少個寄存器,也就是說每個線程需要多少個寄存器是明確的。當線程要執(zhí)行時,會從寄存器堆上分配得到這個線程需要數(shù)目的寄存器。比如一個SM總共有32768個寄存器,如果一個線程需要256個寄存器,那么這個SM上總共可以執(zhí)行32768/256=128個線程。 SM上每一個運算核心同一時間內(nèi)執(zhí)行一個線程,也就是說一個線程其實是對應一個運算核心,但是,一個運算核心卻是對應多個線程。這該怎么理解呢? 上文說到Shader所需要的寄存器數(shù)量決定了SM上總共能執(zhí)行多少個線程。一個SM上總共也就有32個運算核心,但是如果多于32個線程需要執(zhí)行怎么辦? 線程調度器會將所有線程分為若干個組,每一個組叫做一個線程束(Warp),它又包含了32個線程。因此如果一個SM總共有32768個寄存器,這個SM總共可以執(zhí)行128線程,那么這個SM上總共可以分配128/32=4個線程束。 一個運算核心同一時間只能處理一個線程,一組(32個)運算核心同一時間只能處理一個線程束,而線程束中有些指令處理起來會比較費時間,特別是內(nèi)存加載。每當當前線程束(Warp)遇到費時操作,它就會被阻塞(Stall)。為了降低延遲,GPU的線程調度器會采用一種簡單而有效的策略,就是切換另一組線程來運行。 運算核心在多個線程束(Warp)間切換著執(zhí)行,最大化利用運算資源,也就解釋了上文中所描述的線程和運算核心之間的關系了。 下圖展示了一個SM執(zhí)行三個線程束的例子。例子中一個線程束只有4個線程是一種簡化圖形的表示方式,根據(jù)上文可知,其實一個線程束中的線程數(shù)遠大于4。下圖中的txr指令延遲會比較高,所以容易使線程阻塞(Stall)。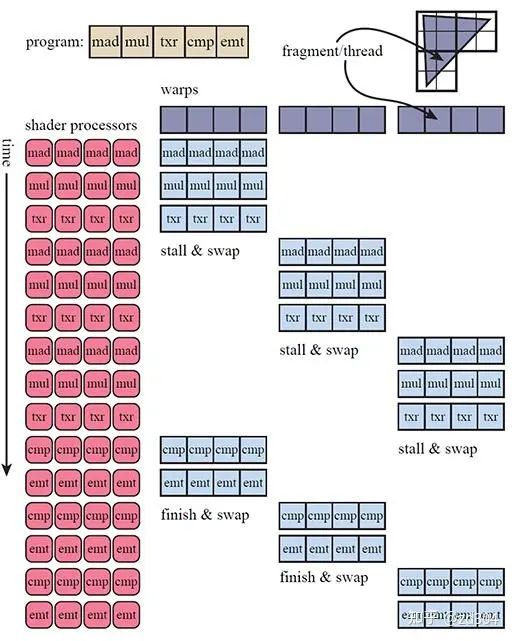 細心的你如果仔細思考,也許會產(chǎn)生一個疑問:為什么 線程調度器 不去調度線程而是調度線程束? 通過上一小節(jié)介紹“SIMT”的時候我們了解到運算核心是以lock-step的方式執(zhí)行的,也就是說線程執(zhí)行的“步調”是一致的,每條指令對于所有線程來說都是“一起開始一起結束”。所以線程調度器調度的單位是線程束(Warp)。
細心的你如果仔細思考,也許會產(chǎn)生一個疑問:為什么 線程調度器 不去調度線程而是調度線程束? 通過上一小節(jié)介紹“SIMT”的時候我們了解到運算核心是以lock-step的方式執(zhí)行的,也就是說線程執(zhí)行的“步調”是一致的,每條指令對于所有線程來說都是“一起開始一起結束”。所以線程調度器調度的單位是線程束(Warp)。
由于線程束的機制,可以推出以下結論。由于寄存器堆的寄存器數(shù)量是固定的,如果一個Shader需要的寄存器數(shù)量越多,也就是每個線程分配到的寄存數(shù)量越多,那么線程束數(shù)量就越少。線程束少,供線程調度器調度的資源就少,當遇到耗時指令時,由于沒有更多線程束去靈活調配,所有線程就只能死等,不利于資源的充分利用,最終導致執(zhí)行效率低下。
裁剪空間當Warp完成了VS的所有指令運算,就會被PolyMorph Engine的Viewport Transform模塊處理,并將三角形數(shù)據(jù)存放到L1和L2緩存里面。此時的三角形會被變換到裁剪空間(Clip空間),在這個空間下的頂點為像素處理階段做好了準備。
像素處理 為了平衡光柵化的負載壓力,WDC(Work Distribution Crossbar)會根據(jù)一定策略,將屏幕劃分成多個區(qū)域塊,并重新分配給每一個GPC。下圖為WDC為屏幕劃分區(qū)域塊的示意圖。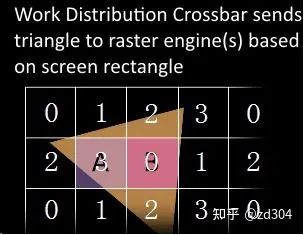 前文提到GPC里有一個 光柵化引擎(Raster Engine) ,這里GPC接收到分配的任務后,就是交給 光柵化引擎 來負責這些三角形像素信息的生成。同時還會處理其他的一些渲染流水線步驟,包括 裁剪(Cliping) 、 背面剔除 以及 Early-Z 。 接下來光柵化引擎將插值好的數(shù)據(jù)轉交給PolyMorph Engine的Attribute Setup模塊,將Vertex Shader計算后存放在L1和L2緩存里面的數(shù)據(jù)加載出來,經(jīng)過插值的數(shù)據(jù)填充到Pixel Shader的寄存器里,供SM的運算核心做像素計算的時候使用。 在邏輯上,一個線程執(zhí)行一個Pixel Shader的核心函數(shù),也就是一個線程處理一個像素。GPU將屏幕分成一個一個的2×2的像素塊,因為邏輯上一個Warp包含了32個線程,也就是說一個Warp處理的是8個像素塊。 上文提到WDC會根據(jù)一定策略劃分區(qū)域塊,實際上的劃分可能比上圖更加復雜。網(wǎng)上有博主根據(jù)NV shader thread group[1]提供的OpenGL擴展,基于OpenGL 4.3+和Geforce RTX 2060做了如下實驗。 首先,應用程序畫了兩個覆蓋全屏的三角形。頂點著色器就不贅述了,下面看看片元著色器。
前文提到GPC里有一個 光柵化引擎(Raster Engine) ,這里GPC接收到分配的任務后,就是交給 光柵化引擎 來負責這些三角形像素信息的生成。同時還會處理其他的一些渲染流水線步驟,包括 裁剪(Cliping) 、 背面剔除 以及 Early-Z 。 接下來光柵化引擎將插值好的數(shù)據(jù)轉交給PolyMorph Engine的Attribute Setup模塊,將Vertex Shader計算后存放在L1和L2緩存里面的數(shù)據(jù)加載出來,經(jīng)過插值的數(shù)據(jù)填充到Pixel Shader的寄存器里,供SM的運算核心做像素計算的時候使用。 在邏輯上,一個線程執(zhí)行一個Pixel Shader的核心函數(shù),也就是一個線程處理一個像素。GPU將屏幕分成一個一個的2×2的像素塊,因為邏輯上一個Warp包含了32個線程,也就是說一個Warp處理的是8個像素塊。 上文提到WDC會根據(jù)一定策略劃分區(qū)域塊,實際上的劃分可能比上圖更加復雜。網(wǎng)上有博主根據(jù)NV shader thread group[1]提供的OpenGL擴展,基于OpenGL 4.3+和Geforce RTX 2060做了如下實驗。 首先,應用程序畫了兩個覆蓋全屏的三角形。頂點著色器就不贅述了,下面看看片元著色器。 圖中有32個亮度色階也就說明有32個不同編號的SM,由渲染結果可以看到SM的劃分并不是按編號順序簡單地依次劃分的。另外根據(jù)上圖可見,同一個色塊內(nèi)的像素分屬不同三角形,就會分給不同的SM進行處理。如果三角形越細碎,分配SM的次數(shù)就會越多。
 這里一個色塊是16×16,也就說明一個SM里運行了256個線程。 將片元著色器改為如下代碼,顯示W(wǎng)arp的分布情況。
這里一個色塊是16×16,也就說明一個SM里運行了256個線程。 將片元著色器改為如下代碼,顯示W(wǎng)arp的分布情況。
// warp id
float lightness = gl\_WarpIDNV / gl\_WarpsPerSMNV;
FragColor = vec4(lightness);
渲染畫面如下圖所示。
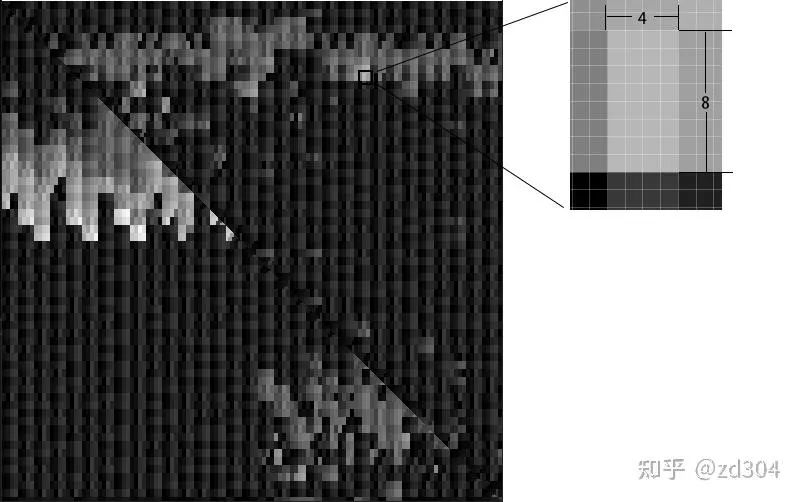
由于一個色塊是由4×8個像素組成,也就證明了一個Warp包含了32個線程。
輸出到渲染目標 經(jīng)過PS計算,SM將數(shù)據(jù)轉交給Crossbar,讓它分配給ROP(渲染輸出單元)。像素在這里進行深度測試以及幀緩沖混合等處理,并將最終值寫入到一塊FrameBuffer里面,這塊FB就是雙緩沖技術里面的后備緩沖。最終將FB寫入到顯存(DRAM)里。
 多平臺渲染架構
多平臺渲染架構
關于IMR、TBR、TBDR介紹的文章有很多,下面簡單歸納一下。
IMR
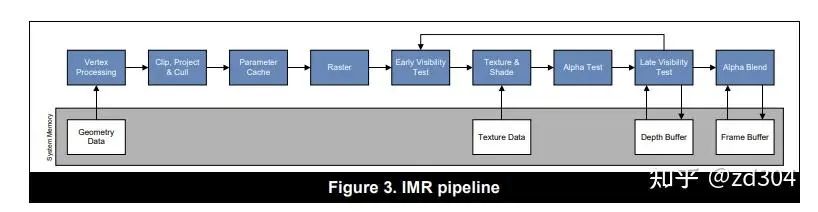
IMR架構主要是PC上GPU采用的渲染架構,這個架構主要是渲染快、帶寬消耗大。 特點:-
? 每一個Drawcall按順序、連續(xù)地執(zhí)行完成。每一個Drawcall從VS、PS到最終寫入FrameBuffer中的顏色緩沖、深度緩沖,中間沒有打斷。
-
? FrameBuffer可以被多次訪問。也就是說每個Drawcall的每像素渲染都會直接寫入FrameBuffer。
-
? 每個像素頻繁訪問顯存上的FrameBuffer,帶寬消耗大。
 IMR模式的GPU執(zhí)行的偽代碼如下。
IMR模式的GPU執(zhí)行的偽代碼如下。
for (draw in renderPass)
{
for (primitive in draw)
{
execute\_vertex\_shader(vertex);
}
if (primitive is culled)
break;
for (fragment in primitive)
{
execute\_fragment\_shader(fragment);
}
}
問題:
-
? 發(fā)熱量大。主要是帶寬消耗大導致的,這個在PC上沒有太大問題。
-
? 耗電量大。主要是帶寬消耗大導致的,這個在PC上沒有太大問題。
-
? 芯片大小大。這個在PC上沒有太大問題,為了優(yōu)化帶寬會有L1 Cache和L2 Cache,所以芯片會變大。
TBR
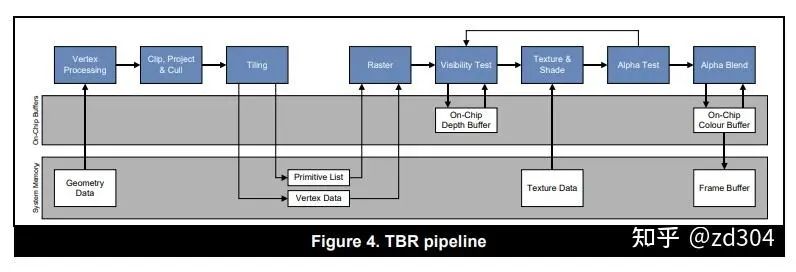
TBR全稱Tile-Based Rendering,是一種基于分塊的渲染架構。 分析:-
? 發(fā)熱、費電,移動設備接受不了。
-
? 芯片太大,移動設備接受不了。
-
? 每一個Drawcall執(zhí)行時僅僅經(jīng)過分塊(Tiling)和頂點計算,存入FrameData。“合適”的時機(如Flush、clear)進行Early-Z、著色、各種測試,最終一次性寫入FrameBuffer中的顏色緩沖、深度緩沖,中間過程是不連續(xù)。
-
? FrameBuffer訪問次數(shù)很少,F(xiàn)rameData會被頻繁訪問。
-
? 由于分塊(Tile)的顏色緩沖和深度緩沖會放到On Chip Memory上,Early-Z和Z-Test都在這上面進行,節(jié)省帶寬。
TBDR
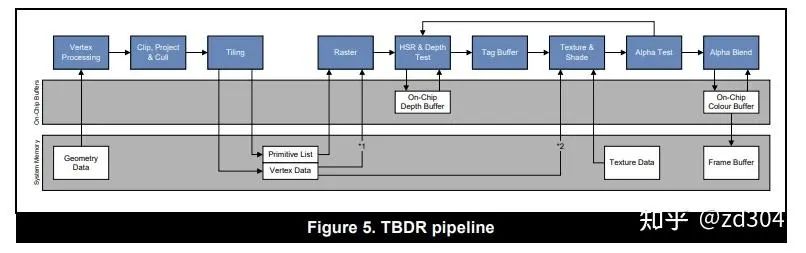
TBDR全稱Tile-Base-Deffered Rendering,是一種基于分塊的延遲渲染架構。 分析:-
? Early-Z可以很好的降低Overdraw,但是TBR依賴物體繪制順序。如果物體循環(huán)遮擋,無法完美地做到降低Overdraw。
 相關渲染優(yōu)化
相關渲染優(yōu)化
寄存器充分使用
前文提到過,如果寄存器使用過多,會導致Warp數(shù)量變少,使得GPU遇到耗時操作的時候沒有空閑Warp去調度,不利于GPU的充分利用,因此要節(jié)約使用寄存器。 對于Shader的語義也好,寄存器也好,都是作為矢量存在的。對于GPU的ALU來說,一條指令可以處理的數(shù)據(jù)一般是四維(4D)的,這就是SIMD(Single Instruction Multiple Data),類似的SIMD指令可以參考SSE指令集。 例如下面的代碼。 float4 c = a + b;
如果沒有SIMD處理單元,匯編偽代碼如下,四個數(shù)據(jù)需要四個指令周期才能完成。
ADD c.x, a.x, b.x
ADD c.y, a.y, b.y
ADD c.z, a.z, b.z
ADD c.w, a.w, b.w
而使用SIMD處理后就變?yōu)橐粭l指令處理四個數(shù)據(jù)了,大大提高了處理效率。
SIMD_ADD c, a, b
由于SIMD的特性,寄存器要盡可能完全利用。例如Unity里有一個宏用來縮放并且偏移圖片采樣用的UV坐標——TRANSFORM_TEX。按道理縮放UV需要乘以一個二維向量,偏移UV也需要加一個二維向量,這里應該是需要兩個寄存器的。然而Unity將兩個二維向量都裝入同一個四維向量里面(xy為縮放,zw為偏移),這樣就只用到一個寄存器了。總而言之,要充分利用寄存器向量的每一個分量。其定義如下。
// Transforms 2D UV by scale/bias property
#define TRANSFORM\_TEX(tex,name) (tex.xy \* name##\_ST.xy + name##\_ST.zw)
為了充分利用SIMD運算單元,GPU還提供了一種叫做co-issue的技術來優(yōu)化代碼。例如下圖,由于float數(shù)量的不同,ALU利用率從100%依次下降為75%、50%、25%。
 為了解決著色器在低維向量的利用率低的問題,可以通過合并1D與3D或2D與2D的指令。例如下圖,原本的兩條指令,co-issue會自動將它們合并,這樣一個指令周期就可以執(zhí)行完成。
為了解決著色器在低維向量的利用率低的問題,可以通過合并1D與3D或2D與2D的指令。例如下圖,原本的兩條指令,co-issue會自動將它們合并,這樣一個指令周期就可以執(zhí)行完成。
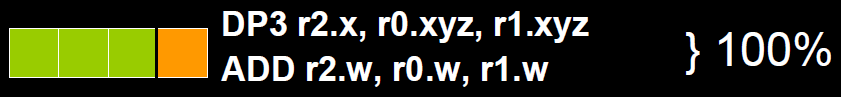 但是如果其中一個變量既是操作數(shù),又是存儲數(shù),則無法啟用co-issue來優(yōu)化。
但是如果其中一個變量既是操作數(shù),又是存儲數(shù),則無法啟用co-issue來優(yōu)化。
 于是 標量指令著色器(Scalar Instruction Shader) 應運而生,它可以有效地組合任何向量,開啟co-issue技術,充分發(fā)揮SIMD的優(yōu)勢。
于是 標量指令著色器(Scalar Instruction Shader) 應運而生,它可以有效地組合任何向量,開啟co-issue技術,充分發(fā)揮SIMD的優(yōu)勢。
邏輯控制語句 GPU和CPU由于其設計目標就有很大的區(qū)別,于是出現(xiàn)了非常不同的架構。
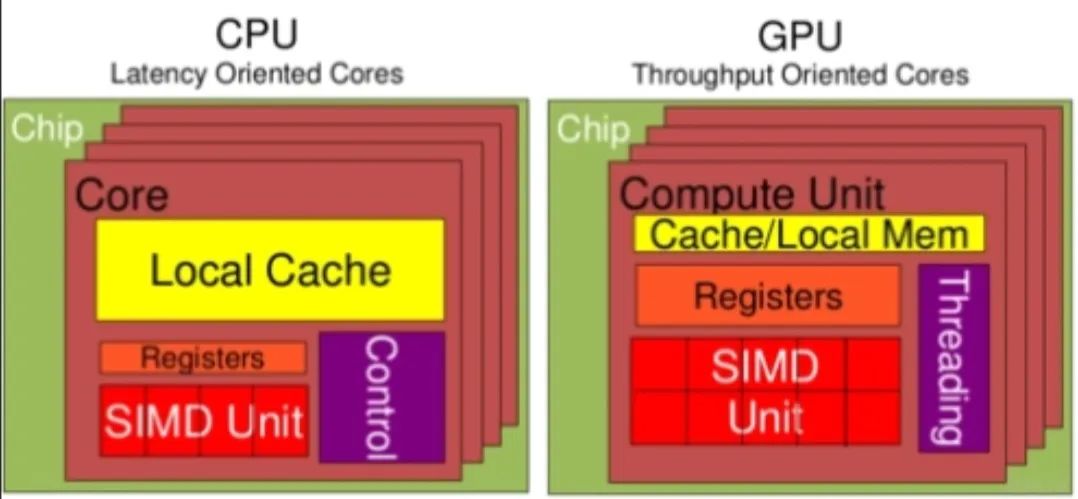
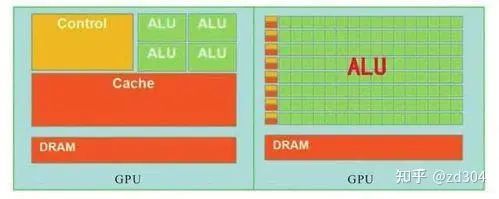 CPU有大量的存儲單元(紅色部分)和控制單元(黃色部分),相比起GPU來說,CPU的計算單元(綠色部分)只占了很少一部分。因此CPU不擅長大規(guī)模并行計算,更擅長于邏輯控制。相反,GPU擅長大規(guī)模并行計算,不擅長邏輯控制。 因此,不要在Shader里寫邏輯控制語句,包括if-else和for循環(huán)等邏輯。下面介紹一下兩種芯片在分支控制上都有哪些區(qū)別。
CPU有大量的存儲單元(紅色部分)和控制單元(黃色部分),相比起GPU來說,CPU的計算單元(綠色部分)只占了很少一部分。因此CPU不擅長大規(guī)模并行計算,更擅長于邏輯控制。相反,GPU擅長大規(guī)模并行計算,不擅長邏輯控制。 因此,不要在Shader里寫邏輯控制語句,包括if-else和for循環(huán)等邏輯。下面介紹一下兩種芯片在分支控制上都有哪些區(qū)別。
CPU - 分支預測
有人在JVM上做過一個測試。如果有一個有序數(shù)組,和一個同樣大的無序數(shù)組,分別取出一百萬次其數(shù)組中大于128的數(shù)字之和,消耗的時間是否相同呢? long long sum = 0;
for (unsigned i = 0; i < 1000000; ++i)
{
for (unsigned c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
以上這段代碼,按實驗步驟來做。
-
? 第一次data數(shù)組是個無序數(shù)組,消耗時間為18.7739秒,sum = 312426300000。
-
? 第二次data數(shù)組事先給排好序,消耗時間是5.69566秒,sum = 312426300000。
-
1. fetch(獲取指令)
-
2. decode(解碼指令)
-
3. execute(執(zhí)行指令)
-
4. write-back(寫回數(shù)據(jù))
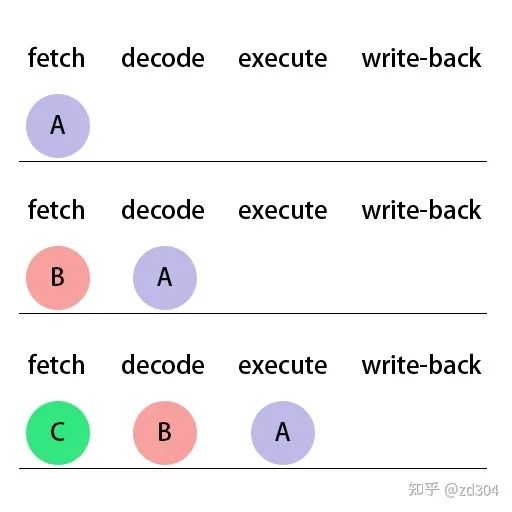 那么如果 if指令 已經(jīng)執(zhí)行到 decode 了,接下來該執(zhí)行if語句塊里面的指令,還是該執(zhí)行else語句塊里面的指令,CPU還不知道,因為只有 if條件判斷 執(zhí)行完成才能知道接下來該執(zhí)行哪個語句塊里的指令。
那么如果 if指令 已經(jīng)執(zhí)行到 decode 了,接下來該執(zhí)行if語句塊里面的指令,還是該執(zhí)行else語句塊里面的指令,CPU還不知道,因為只有 if條件判斷 執(zhí)行完成才能知道接下來該執(zhí)行哪個語句塊里的指令。
 此時,CPU會先嘗試將上一次判斷的歷史記錄拿來這一次作為判斷條件來先用著,這就是所謂的“ 分支預測 ”。如果預測對了,那么對于性能來說就是賺了;如果預測錯誤,那么就從 fetch 開始用正確的值重新來執(zhí)行,也不虧性能。
此時,CPU會先嘗試將上一次判斷的歷史記錄拿來這一次作為判斷條件來先用著,這就是所謂的“ 分支預測 ”。如果預測對了,那么對于性能來說就是賺了;如果預測錯誤,那么就從 fetch 開始用正確的值重新來執(zhí)行,也不虧性能。
GPU - 遮掩
GPU講究的是大規(guī)模并行計算,沒有那么強大的邏輯控制,所以GPU也不會去做分支預測。那么GPU是怎么去處理條件分支判斷的呢? 由于GPU的執(zhí)行是以lock-step的方式鎖步執(zhí)行的,也就是每一個運算核心一定要執(zhí)行完當前指令的所有步驟才能執(zhí)行下一條指令,也就是前文中所說的“比較笨一點的辦法”,所以GPU是沒有分支預測的。但是GPU有一個特殊的機制叫做遮掩(mask out)。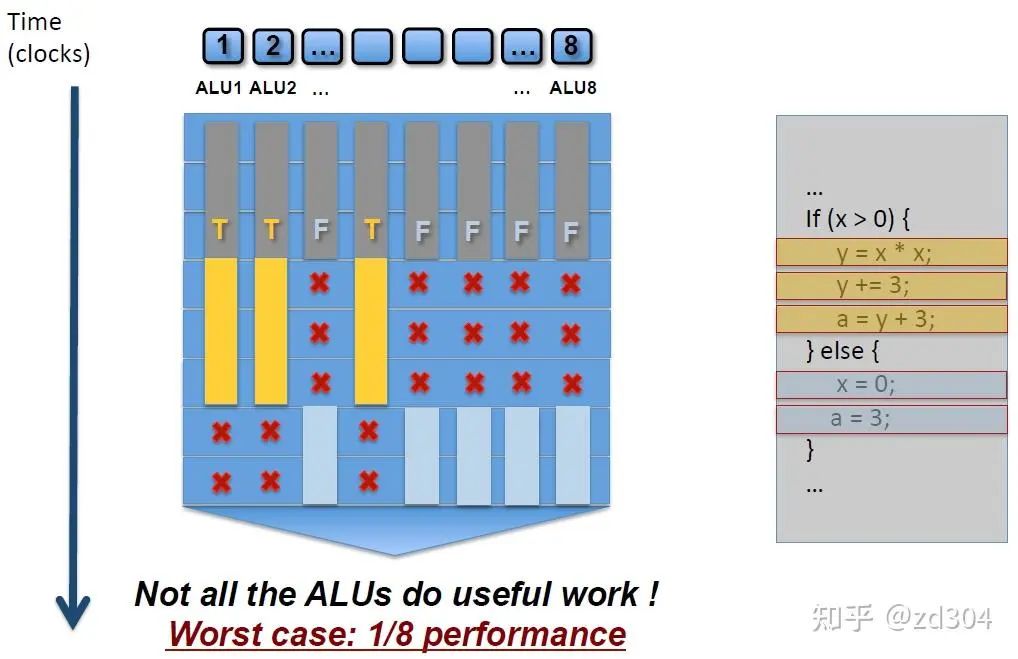 如上圖所示,同時有8個線程在執(zhí)行右邊代碼的指令。有的線程滿足x大于0,那么左圖中黃色部分就會被執(zhí)行,但是同一指令周期內(nèi),其他的線程x小于或等于0,這些線程的指令就會被 遮掩 ,也就是雖然也是要消耗時間,但是不會被執(zhí)行,就處于了等待。同理,滿足else條件的語句在接下來的指令執(zhí)行周期內(nèi)執(zhí)行淺藍色部分,不滿足的在同一指令周期內(nèi)就被遮掩,處于等待。 被遮掩的代碼同樣是要消耗相同的指令周期時間去等待未被遮掩的代碼執(zhí)行。因此,如果一個Shader里有太多的if-else語句,就會白白浪費很多時間周期。 同樣的原理應用在for循環(huán)上,如果有的線程循環(huán)3遍,有的線程循環(huán)5遍,就需要等待循環(huán)最久的那個線程執(zhí)行完成才能繼續(xù)往下執(zhí)行,造成很多線程的浪費。 因此,在Shader中不是不能寫邏輯控制語句,而是要思考一下有沒有被浪費的資源。換句話說,Shader里不要用不固定的數(shù)值來控制邏輯執(zhí)行。
如上圖所示,同時有8個線程在執(zhí)行右邊代碼的指令。有的線程滿足x大于0,那么左圖中黃色部分就會被執(zhí)行,但是同一指令周期內(nèi),其他的線程x小于或等于0,這些線程的指令就會被 遮掩 ,也就是雖然也是要消耗時間,但是不會被執(zhí)行,就處于了等待。同理,滿足else條件的語句在接下來的指令執(zhí)行周期內(nèi)執(zhí)行淺藍色部分,不滿足的在同一指令周期內(nèi)就被遮掩,處于等待。 被遮掩的代碼同樣是要消耗相同的指令周期時間去等待未被遮掩的代碼執(zhí)行。因此,如果一個Shader里有太多的if-else語句,就會白白浪費很多時間周期。 同樣的原理應用在for循環(huán)上,如果有的線程循環(huán)3遍,有的線程循環(huán)5遍,就需要等待循環(huán)最久的那個線程執(zhí)行完成才能繼續(xù)往下執(zhí)行,造成很多線程的浪費。 因此,在Shader中不是不能寫邏輯控制語句,而是要思考一下有沒有被浪費的資源。換句話說,Shader里不要用不固定的數(shù)值來控制邏輯執(zhí)行。
減少調用費時指令
通常一些需要從緩存里,甚至內(nèi)存里讀取數(shù)據(jù)的操作會比較費時,例如貼圖采樣的指令。 從上文中可以了解到,一般GPU架構里SFU這種處理單元比較少,因此特殊數(shù)學函數(shù)盡量少調用,例如pow、sin、cos等。移動渲染架構的優(yōu)化
及時clear或者discard
由于TB(D)R架構下數(shù)據(jù)會一直積攢到FrameData里,直到“合適”的時機才會清空。如果一直不調用clear指令就會一直將數(shù)據(jù)積累到FrameData里清不掉。如果不用RenderTexture了就及時Discard掉。 例如有一張RenderTexture,渲染之前調用clear就能清空前一次的FrameData,不用這張RenderTexture了,就及時調用Discard(),以提高性能。不要頻繁切換RenderTexture
頻繁切換RenderTexture會導致頻繁將Tile數(shù)據(jù)拷貝到FrameBuffer上,增加性能消耗。Early-Z
Early-Z可以很好的降低Overdraw,但是某些操作會使Early-Z失效。-
? Alpha Test / Clip / discard:需要執(zhí)行完 PS 后,才能確定該像素深度是否被寫入。
-
? 手動修改GPU插值得到的深度。
-
? 開啟透明混合(AlphaBlend)。
-
? 關閉深度測試。
特別說明:因為Early-Z是通過深度去屏蔽不透明物體的,如果透明物體(Alpha Blend)或者挖洞的物體(Alpha Test)通過深度測試屏蔽了背景的不透明(Opaque)物體,那么背景就會鏤空,看到clear指令指定的固有色,就會出現(xiàn)渲染錯誤,因此無論IMR還是T(D)BR的Early-Z都會受Alpha Test影響。因此要做到以下幾點。
-
? 渲染物體時,渲染程序要按“Opaque → AlphaTest → AlphaBlend”的順序渲染物體。
-
? 由于一般來說地形覆蓋面積最大,“Opaque”的內(nèi)部可以按“其他不透明物件 → 地形”的順序渲染,最大化利用Early-Z優(yōu)化Overdraw。
-
? 無論PowerVR還是Mali/Adreno芯片,AlphaTest都會影響性能,盡量少使用AlphaTest技術。
-
? 不支持Early-Z的硬件,可以適當使用PreDepathPass多渲染一遍圖元來優(yōu)化Overdraw,但是會增加頂點繪制的負擔,需要權衡。
避免大量drawcall和頂點數(shù)
FrameData里會儲存當前幀變換過的圖元列表,也就是頂點數(shù)據(jù),F(xiàn)rameData數(shù)據(jù)會隨著Drawcall數(shù)增加而增加,F(xiàn)rameData增大有可能會存儲到其他地方,影響讀寫速度,因此在移動平臺渲染上百萬個頂點或者三四百Drawcall就比較吃力了。 總結 本文主要歸納了GPU內(nèi)部的一些基本單元及其作用,簡單總結了一下對渲染架構的描述,并針對以上兩方面介紹了一些優(yōu)化性能的技巧。本文更多是歸納總結性質的,如果要更加深入的了解可以細讀以下參考文章,如果有總結不到位的歡迎探討。 參考《GPU Fundamentals》[2]
《Life of a triangle - NVIDIA's logical pipeline》[3](翻譯[4]) 《深入GPU硬件架構及運行機制》[5] 《CPU 的分支預測》[6] 《移動端GPU——渲染流程》[7] 《剖析虛幻渲染體系(12)- 移動端專題Part 2(GPU架構和機制)》[8] 《針對移動端TBDR架構GPU特性的渲染優(yōu)化》[9] 《Unity 著色器中"discard"操作符的問題》[10] 《移動平臺GPU硬件學習與理解》[11] 《圖形 3.4+3.5 正向渲染/延遲渲染 和 深度測試Early-z / Z-prepass(Z-buffer)》[12]
計算機專題:鴻蒙生態(tài)加速發(fā)展 2024年人形機器人專題策略:量產(chǎn)漸行漸近,未來不遠 供需端雙擊推進AI PC產(chǎn)業(yè)發(fā)展(2024) 2024年 AI智算產(chǎn)業(yè)趨勢展望 2024 AIGC 應用層十大趨勢白皮書 FMS 2023閃存峰會:CXL技術篇(1) FMS 2023閃存峰會:CXL技術篇(2) FMS 2023閃存峰會:CXL技術篇(3) FMS 2023閃存峰會:UCIe和PCIe技術篇 FMS 2023閃存峰會:NVMe技術篇(1) FMS 2023閃存峰會:NVMe技術篇(2) FMS 2023閃存峰會:DDR/DRAM技術篇 《HotChips 2023及歷年技術合集(匯總)》 1、HotChips 2023:開場閉幕總結 2、HotChips 2023:FPGAs技術專題 3、HotChips 2023:芯片互聯(lián)技術專題 4、HotChips 2023:ML訓練/推理技術專題 5、HotChips 2023:ML技術專題 6、HotChips 2023:CPU技術專題(1) 7、HotChips 2023:CPU技術專題(2) 8、HotChips 2023:UCIe技術專題 9、HotChips 2023:關鍵技術總結合集 10、HotChips歷年技術合集
本號資料全部上傳至知識星球,更多內(nèi)容請登錄智能計算芯知識(知識星球)星球下載全部資料。
免責申明: 本號聚焦相關技術分享,內(nèi)容觀點不代表本號立場,可追溯內(nèi)容均注明來源,發(fā)布文章若存在版權等問題,請留言聯(lián)系刪除,謝謝。
溫馨提示:
請搜索“AI_Architect”或“掃碼”關注公眾號實時掌握深度技術分享,點擊“閱讀原文”獲取更多原創(chuàng)技術干貨。
