
(附論文&代碼)神經(jīng)網(wǎng)絡(luò)搜索:Once for all
點(diǎn)擊左上方藍(lán)字關(guān)注我們

0. Info
Title: Once-for-All: Train one Network and Specialize it for Efficient Deployment
Author: 韓松組
Link: https://arxiv.org/pdf/1908.09791v5
Publish: ICLR2020
代碼:https://github.com/mit-han-lab/once-for-all
論文:https://arxiv.org/pdf/1908.09791.pdf
1. Motivation
傳統(tǒng)網(wǎng)絡(luò)搜索方法往往只能針對某個(gè)特定設(shè)備或者特定資源限制的平臺進(jìn)行針對性搜索。對于不同的設(shè)備,往往需要在該設(shè)備上從頭訓(xùn)練。這樣的方法擴(kuò)展性很差并且計(jì)算代價(jià)太大,所以once for all從這個(gè)角度出發(fā),希望能做到將訓(xùn)練和搜索過程解耦,從而可以訓(xùn)練一個(gè)支持不同架構(gòu)配置的once-for-all網(wǎng)絡(luò)(類似超網(wǎng)的概念),通過從once-for-all網(wǎng)絡(luò)中選擇一個(gè)子網(wǎng),就可以在不需要額外訓(xùn)練的情況下得到一個(gè)專門的子網(wǎng)絡(luò)。
不同的硬件平臺有著不同的硬件效率限制,比如延遲、功耗 不同的硬件平臺的硬件資源差別很大,比如最新的手機(jī)和最老的手機(jī)。 相同的硬件上,不同的電池條件、工作負(fù)載下使用的網(wǎng)絡(luò)模型也是不同的。
也就是說,網(wǎng)絡(luò)設(shè)計(jì)主要受平臺的以下幾方面約束:
部署的硬件設(shè)備不同。 相同硬件設(shè)備上不同的部署要求,比如期望的延遲。
2. Contribution
提出了解決以上問題的方法:設(shè)計(jì)once-for-all網(wǎng)絡(luò),可以在不同的網(wǎng)絡(luò)配置下進(jìn)行部署。 推理過程使用的模型是once-for-all網(wǎng)絡(luò)的一部分,可以無需重新訓(xùn)練就能靈活的支持深度、寬度、卷積核大小、分辨率等參數(shù)的不同。 提出了漸進(jìn)式收縮的訓(xùn)練策略來訓(xùn)練once-for-all網(wǎng)絡(luò)
3. Method
方法部分需要搞清楚兩個(gè)問題,一個(gè)是網(wǎng)絡(luò)是什么樣的?一個(gè)是網(wǎng)絡(luò)是如何訓(xùn)練的?
第一個(gè)問題:once-for-all網(wǎng)絡(luò)長什么樣子?
once-for-all網(wǎng)絡(luò)支持深度、寬度、卷積核大小、圖像分辨率四個(gè)因素的變化。
elastic depth: 代表選擇任意深度的網(wǎng)絡(luò),每個(gè)單元的深度有{2,3,4}三個(gè)選項(xiàng)。 elastic width: 代表選擇任意數(shù)量的通道,寬度比例有{3,4,6}三個(gè)選項(xiàng)。 elastic kernel size: 代表選擇任意的卷積核大小,有{3,5,7}三個(gè)選項(xiàng)。 arbitrary resolution: 代表圖像的分辨率是可變的,從128到224,stride=4的分辨率均可。
由于網(wǎng)絡(luò)包括5個(gè)單元,所以候選的子網(wǎng)大概有個(gè)不同的子網(wǎng),并且是在25個(gè)不同輸入分辨率下進(jìn)行訓(xùn)練。所有的子網(wǎng)都共享權(quán)重,只需要7.7M的參數(shù)量。
第二個(gè)問題:once-for-all怎樣才能同時(shí)訓(xùn)練這么多子網(wǎng)絡(luò)?
由于once-for-all的目標(biāo)是同時(shí)優(yōu)化所有的子網(wǎng),所以需要考慮使用新的訓(xùn)練策略。
最簡單的想法:不考慮計(jì)算代價(jià)的情況下,每次梯度的更新都是由全體子網(wǎng)計(jì)算得到的。雖然這樣最準(zhǔn)確,但是可想而知計(jì)算代價(jià)過高,并不實(shí)際。 可行的想法:每次梯度是由一部分子網(wǎng)計(jì)算得到的。筆者曾經(jīng)嘗試過這種方法(single path one shot),收斂的速度非常慢,得到的準(zhǔn)確率也非常低。這很可能是在訓(xùn)練過程中,由于權(quán)重是共享的,梯度在同一個(gè)參數(shù)的更新上可能帶來沖突,減緩了訓(xùn)練的過程,并且達(dá)到最終的準(zhǔn)確率也不夠高。
通過以上分析可以看出,訓(xùn)練超網(wǎng)是非常困難的,需要采用更好的訓(xùn)練策略才能訓(xùn)練得動(dòng)超網(wǎng)。
本文提出了Progressive Shrinking策略來解決以上問題,如下圖所示:
先訓(xùn)練最大的kernel size, depth , width的網(wǎng)絡(luò) 微調(diào)網(wǎng)絡(luò)來支持子網(wǎng),即將小型的子網(wǎng)加入采樣空間中。比如說,當(dāng)前正在微調(diào)kernel size的時(shí)候,其他的幾個(gè)選項(xiàng)depth, width需要維持最大的值。另外,分辨率大小是每個(gè)batch隨機(jī)采樣的,類似于yolov3里的訓(xùn)練方法。 采用了知識蒸餾的方法,讓最大的超網(wǎng)來指導(dǎo)子網(wǎng)的學(xué)習(xí)。

以上策略的特點(diǎn)是:先訓(xùn)練最大的,然后訓(xùn)練小的。這樣可以盡可能減小訓(xùn)練小模型的時(shí)候?qū)Υ竽P偷挠绊憽?/p>
下面對照上圖詳細(xì)展開PS策略:
訓(xùn)練整個(gè)網(wǎng)絡(luò),最大kernel,最寬channel,最深depth 訓(xùn)練可變kernel size, 每次采樣一個(gè)子網(wǎng),使用0.96的初始學(xué)習(xí)率訓(xùn)練125個(gè)epoch 訓(xùn)練可變depth,采樣兩個(gè)子網(wǎng),每次更新收集兩者的梯度。第一個(gè)stage使用0.08的學(xué)習(xí)率訓(xùn)練25個(gè)epoch;使用0.24的學(xué)習(xí)率訓(xùn)練125個(gè)epoch。 訓(xùn)練可變width,采樣四個(gè)子網(wǎng),每次更新收集四個(gè)子網(wǎng)梯度。第一個(gè)stage使用0.08的學(xué)習(xí)率訓(xùn)練25個(gè)epoch;使用0.24的學(xué)習(xí)率訓(xùn)練125個(gè)epoch。
通過以上描述可以看出來,權(quán)重共享的網(wǎng)絡(luò)優(yōu)化起來非常復(fù)雜,上邊的選擇的子網(wǎng)個(gè)數(shù)、學(xué)習(xí)率的選擇、epoch的選擇可能背后作者進(jìn)行了無數(shù)次嘗試調(diào)參,才得到了一個(gè)比較好的結(jié)果。
**Elastic Kernel Size: **Kernel Size是如何共享的呢?

簡單來說就是,中心共享+變換矩陣。從直覺上來講,優(yōu)化7x7的卷積核以后,再優(yōu)化中間的5x5卷積核勢必會(huì)影響原先7x7卷積核的結(jié)果,兩者在分布和數(shù)值上有較大的不同,強(qiáng)制訓(xùn)練會(huì)導(dǎo)致性能有較大的下降,所以這就需要引入變換矩陣,具體實(shí)現(xiàn)是一個(gè)MLP,具體方法是:
不同層使用各自獨(dú)立的變換矩陣來共享權(quán)重。 相同層內(nèi)部,不同的通道之間共享變換矩陣。
Elastic Depth: 如何優(yōu)化不同深度的網(wǎng)絡(luò)呢?

深度為2、3、4的時(shí)候,按照上圖所示,選擇前i個(gè)層,進(jìn)行訓(xùn)練和優(yōu)化。
**Elastic Width: ** 如何優(yōu)化不同的通道個(gè)數(shù)?

并沒有使用類似slimmable network中那種選取前n個(gè)通道的策略,而是選取了一個(gè)channel importance進(jìn)行排序,通道重要性計(jì)算方法是L1范數(shù),L1范數(shù)越大,代表其重要性比較高,選擇重要性最高的前n個(gè)通道。
部署階段的其他技術(shù)細(xì)節(jié):
搜索子網(wǎng),滿足一定的條件,比如延遲、功率等限制。 預(yù)測器:neural-network-twins, 功能是給定一個(gè)網(wǎng)絡(luò)結(jié)構(gòu),預(yù)測其延遲和準(zhǔn)確率。采樣了16K個(gè)不同架構(gòu)、不同分辨率的子網(wǎng),然后再10K的驗(yàn)證數(shù)據(jù)集上得到他們真實(shí)的準(zhǔn)確率。【arch, accuracy】可以作為準(zhǔn)確率預(yù)測器的訓(xùn)練數(shù)據(jù)集。 構(gòu)建了一個(gè)延遲查找表 latency lookup table來預(yù)測不同目標(biāo)硬件平臺的延遲。預(yù)測器訓(xùn)練數(shù)據(jù)集只需要40GPU Days。
4. Experiment
訓(xùn)練細(xì)節(jié):
網(wǎng)絡(luò)搜索空間:MobileNetV3類似的 使用標(biāo)準(zhǔn)的SGD優(yōu)化器,momentum=0.9 weight decay=3e-5 初始學(xué)習(xí)率2.6 使用cosine schedule來進(jìn)行l(wèi)earning rate decay 在32GPU上使用2048的batch size訓(xùn)練了180個(gè)epoch 在V100GPU上訓(xùn)練了1200個(gè)GPU hours
漸進(jìn)收縮策略:

上圖展示了使用漸進(jìn)收縮策略以后帶來的性能提升,可以看出,不同的架構(gòu)配置下,都帶來了2-4%的性能提升。
實(shí)驗(yàn)結(jié)果:
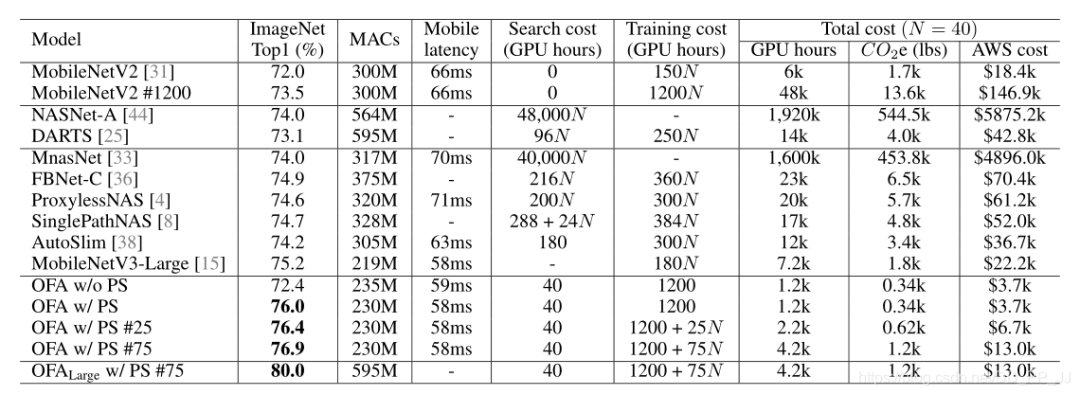
once-for-all在ImageNet上訓(xùn)練結(jié)果如上表所示,其中可以發(fā)現(xiàn)雖然訓(xùn)練代價(jià)比較高,但是搜索的代價(jià)穩(wěn)定在40GPU Hours并且取得了相同量級MACs下不錯(cuò)結(jié)果。
5. Revisiting
并沒有什么突破性的創(chuàng)新點(diǎn),但是每個(gè)點(diǎn)都做得很扎實(shí),在一個(gè)不錯(cuò)的motivation下,將故事講的非常引人入勝。所以會(huì)講故事+扎實(shí)的實(shí)驗(yàn)結(jié)果+(大量的算力) 才得到這個(gè)結(jié)果。 漸進(jìn)收縮策略中先訓(xùn)練kernel size,在訓(xùn)練depth,最后訓(xùn)練width的順序并沒有明確指出為何是這樣的順序。 通道的搜索策略筆者把它搬到single path one shot上進(jìn)行了實(shí)驗(yàn),效果并不理想。 通道搜索策略中once for all計(jì)算L1 Norm是根據(jù)輸入的通道來計(jì)算的,有點(diǎn)違背直覺,通常來講根據(jù)輸出通道計(jì)算更符合直覺一些。這一點(diǎn)可以參考通道剪枝,可能兩種方法都是可行的,具體選哪個(gè)需要看實(shí)驗(yàn)結(jié)果。 共享kernel size那部分工作的分析非常好,想到使用一個(gè)轉(zhuǎn)移矩陣來適應(yīng)不同kernel所需要的分布非常符合直覺。 這篇工作代碼量非常大,非常的工程化,從文章的實(shí)驗(yàn)也能看出里邊需要非常強(qiáng)的工程能力,調(diào)參能力、才能在頂會(huì)上發(fā)表。
6. Reference
https://zhuanlan.zhihu.com/p/164695166
https://github.com/mit-han-lab/once-for-all
https://arxiv.org/abs/1908.09791
https://file.lzhu.me/projects/OnceForAll/OFA%20Slides.pdf
END
整理不易,點(diǎn)贊三連↓