
Python AI 換臉,宋小寶換臉劉敏濤唱紅色高跟鞋,是怎么實現(xiàn)的?
應該有一些 b 友知道他吧,可能你之前看過他的博客:
或者逛過他的 Github,他在 Github 上面開源了挺多不錯的項目,比如爬蟲、機器學習啥的,那個 star 量我都酸了...中國區(qū) Top 100!
那么接下來有請 Jack Cui 閃亮登場!!!!

哈嘍,各位小帥b的朋友們,你們好哇~小帥b大佬人很nice,要帶小弟飛一次~特此有了今天的邀請分享。我本身做算法工作,所以今天給大家?guī)砹薃I換臉的分享,希望各位喜歡!
咱們進入正題:
紅色高跟鞋
劉敏濤,中國內地知名女演員。
我還是從 2015 年上映的《偽裝者》知道她的。
5 月 5 日,又憑借著在晚會合唱的《紅色高跟鞋》上了微博熱搜,直拍視頻的播放量高達 4000 多萬,逗趣的表情管理,讓人忍俊不禁。
AI 換臉技術,可以直接讓你也擁有這自我陶醉的表情管理能力。
比如,看下宋小寶“演唱”一首《紅色高跟鞋》。

公眾號上傳了 Deepfake 視頻,但是一直無法過審。
人臉這東西還是有些風險的,索性就不放視頻了,想看視頻的,可以去 B 站搜索,宋小寶紅色高跟鞋,有很多其他人的作品,絕對驚艷。
今天,我繼續(xù)手把手教學。
算法原理、環(huán)境搭建、模型訓練、效果測試,一條龍服務,盡在下文!
搞起來!
Faceswap
這種換臉的算法,其實有很多。
例如 Faceswap 、DeepFaceLab、Faceswap-GAN 等等。
本文以 star 量最多的 Faceswap 為例,進行說明。
Faceswap 項目地址:https://github.com/deepfakes/faceswap
算法原理
Faceswap 是一個名為 deepfakes 的 Github 用戶開源的項目。
Deepfake 就是“Deep Machine Learning”(深度學習)和“Fake Photo”(假照片)組合而成的。
早期技術可以追溯到 2018 年,當時在構建模型的時候使用了 Encoder-Decoder 自編解碼架構。
而 Faceswap 算法,在此之上又引入 GAN(生成對抗網絡)技術,顯著提升了換臉的效果。
總體上,「Faceswap」換臉主要分為以下三個過程:
人臉檢測
特征提取
人臉轉換
人臉檢測
想要替換人臉,那首先得找到人臉的位置,這就需要用到人臉檢測算法。

Faceswap 算法采用了 SSD 這類比較成熟的檢測框架,同于提取面部圖像。
與傳統(tǒng)人臉檢測略有不同的,F(xiàn)aceswap 算法需要裁剪的人臉邊界框(bouding box, bbox)是正方形的,同時還會適當的向外擴充一些,以保證人臉都在 bbox 內。
特征提取
檢測到人臉后,需要提取人臉的特征。
首先要做的就是,人臉關鍵點檢測,也就是 landmark。

這些關鍵點,抽取了人臉的表情特征,同時大致描述了人臉的器官分布。
我們可以直接通過 dlib 和 OpenCV 等主流的工具包直接提取人臉的關鍵點。
當然,為了取得更好的定位精度,也可以使用 CNN 訓練一個人臉關鍵點檢測模型,簡單好用。
人臉轉換
人臉轉換的思想,其實和我上篇文章?ALAE?的思想很像。
就是采用自編碼器的原理,不記得它是啥的話,可以去上一篇文章看一看。
簡單來講,就是將人臉圖像壓縮到短向量,再由短向量恢復到人臉圖像。這些短向量包含了人臉的主要信息,例如該向量的元素可能表示人臉膚色、眉毛位置、眼睛大小等等。
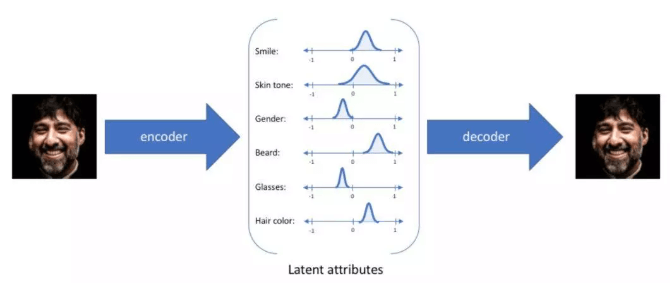
所以如果我們用某個編碼器學習所有人,那么它就能學習到人臉的共性;如果再用某個解碼器學習特定的某個人,那么就能學習到這個人的特性。
簡單而言,當我們用通用編碼器編碼人臉 A,再使用特定解碼器 B 解碼短向量,那么就能生成出擁有 A 的人臉表情,但卻是 B 人臉的圖像。
就好比,你擺出一個表情,我根據你睜眼的大小,嘴巴咧開的大小等面部特征,模仿出你的表情。
我們表情一樣,但長相不一樣。
人臉轉換,除了自編碼器的方法,還有一種 GAN 方法。
GAN 會利用提取的人臉特征點,使用生成器直接生成對應的目標人臉圖像,這跟 StyleGAN 人臉生成算法很類似,但不同的是需要生成指定表情的人臉。
在生成的圖片后,會接一個判別器,判斷圖片的逼真程度。
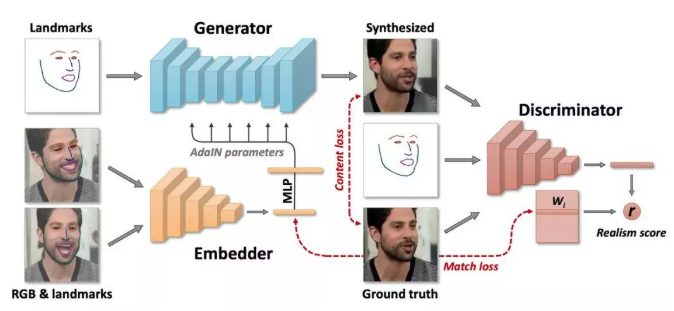
上述算法都是針對單張圖片而言的,對于視頻而言,就是多了一個視頻拆分成圖片,圖片拼接成視頻的過程。
DeepFakes 技術發(fā)展已久,2020 年有一篇最新發(fā)表的綜述論文,包含了各種 DeepFakes 算法的概述,想了解更多的讀者,可以去“啃”一下論文了。
論文地址:https://arxiv.org/pdf/2001.00179.pdf
預處理和后處理
大致思路就是這樣,里面還有很多細節(jié),我們稱之為 Tricks ,這就需要通過閱讀源碼去學習了。
比如,在進行提取人臉特征之前,需要進行圖像的預處理。
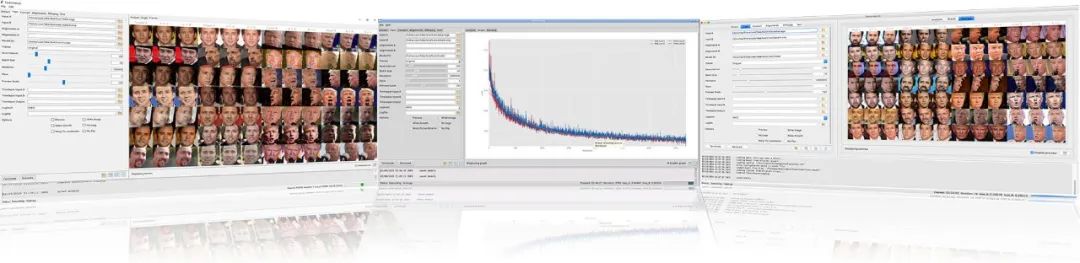
對數據進行規(guī)范化(Normalization),使訓練的圖像的分布信息盡可能相近:
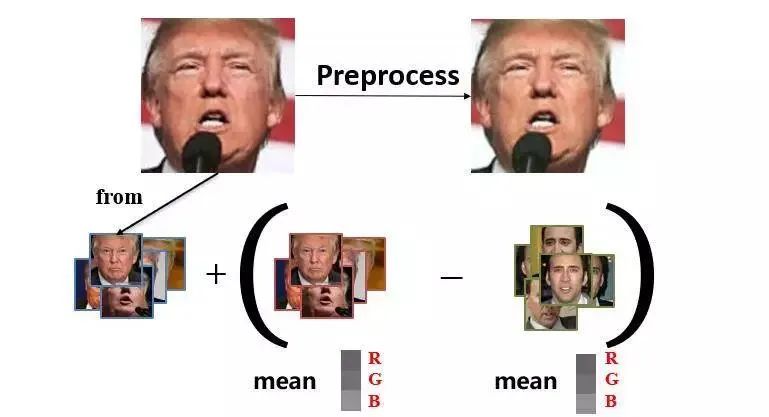
訓練的數據集是分為 A 數據集和 B 數據集的,如上圖,A 數據集為川普,B 數據集為凱奇。
我們可以將 A 數據集(川普)加上兩者數據集的平均差值(RGB三通道差值)來使兩個輸入圖像圖像的分布盡可以相近,這樣我們的損失函數曲線下降會更快些。
用代碼表示就是:
images_A += images_B.mean(axis=(0, 1, 2)) - images_A.mean(axis=(0, 1, 2))再比如,換臉之后,需要進行圖像的后處理。
為了是生成的人臉效果更加,會進行諸如邊緣融合、色彩均衡等處理方法。
想要了解算法背后的實現(xiàn)方法,那就得耐著性子看源碼了。
環(huán)境搭建
大致的原理講完了,開始進入實戰(zhàn)部分,環(huán)境搭建。
Faceswap 項目地址:https://github.com/deepfakes/faceswap
Faceswap 這類的換臉算法,計算量很大,強烈推薦使用 GPU 搭建開發(fā)環(huán)境。
我是 RXT 2060 super ,訓練模型都需要 12 個小時以上,如果只用 CPU 訓練,那可能需要幾個星期的時間才能訓練好。
Faceswap 程序,對于 Python 版本、 CUDA 版本和 tensoflow-gpu 版本都有要求。

經過我的熬夜測試,Python 版本必須是 3.6.x,如果是 3.7.x 都跑不起來。
CUDA 版本也得是 10.0 或 9.0,版本高了,比如 10.2,訓練的時候會出現(xiàn) gpu 用不起來的情況。
我的運行環(huán)境是:
CUDA 10.0
Python 3.6
tensorflow-gpu 1.14.0
還是推薦使用 Anaconda 配置環(huán)境,直接創(chuàng)建一個 Python 3.6 的環(huán)境,然后在里面折騰:
conda create -n tf python==3.6只要這幾個基礎庫版本沒有問題,其他就好說了,根據項目的 requirements.txt 直接安裝第三方庫即可:
python -m pip install -r _requirements_base.txt
除了這些第三方庫,官方還少統(tǒng)計了一個 pynvml,直接用 pip 安裝即可。
python -m pip install pynvml
此外還需要配置一下 FFmpeg,安裝好后記得配置環(huán)境變量。
下載地址:
http://ffmpeg.org/
模型訓練
faceswap 有一個強大的 GUI 。
輸入如下指令,打開 GUI。
python?faceswap.py?gui
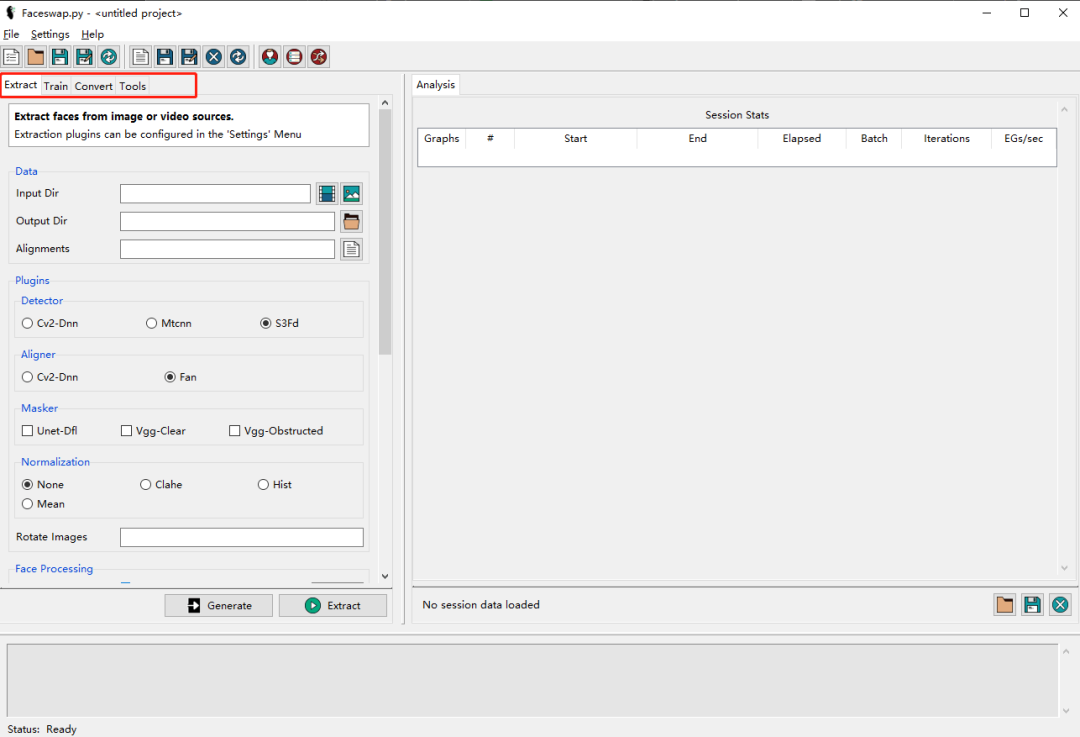
主要提供了四個功能:
Extract:數據集制作,可以自動提取視頻或圖片中的人臉。
Train:訓練模型,有多種算法可供選擇。
Convert:換臉,使用訓練好的模型對圖片或視頻換臉。
Tools:工具,很多圖像處理小工具。
數據集制作
想要訓練換臉模型,首先要處理數據集,可以用 Extract ,比如下載一些宋小寶的高清視頻,然后使用 Extract 處理。
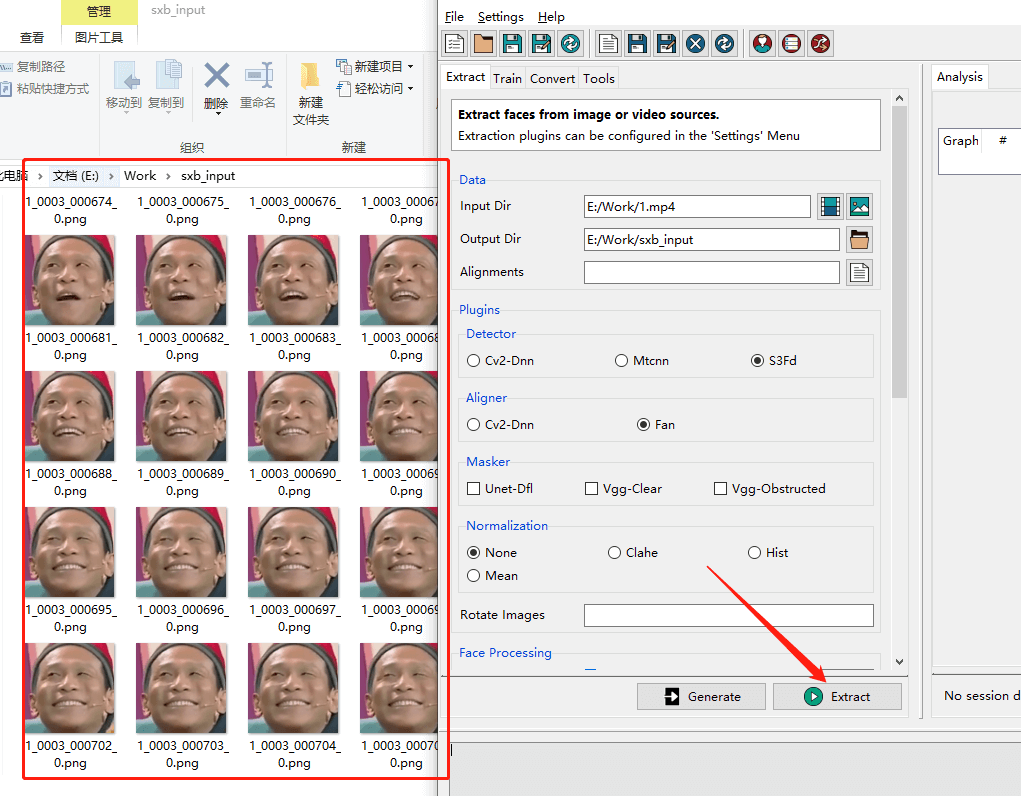
指定好視頻路徑和輸出圖片路徑,點擊 Extract 即可處理圖片。
Extract 除了會生成參見后的人臉數據意外,還會生成 alignments.fsa 文件,也就是人臉對齊文件。
這個提取,是提取視頻中所有的人臉,所以提取完之后,需要使用人臉識別接口或者人工清晰一遍數據,將無用的數據刪除。
刪除圖片之后,需要根據剩余的圖片重新生成 alignments.fsa 文件。
這時候,就需要用到 Tools 里面的功能。
選擇 Tools 標簽下的 Sort 選項,Input 填寫為剛剛處理完圖片的文件夾,Output 填寫新的文件夾,其余選項默認,點擊 Sort 執(zhí)行按鈕,對所有圖片進行重新排序。
圖片名處理完了,再選擇 Tools 標簽下的 Alignments,job 選項 Remove-Faces:
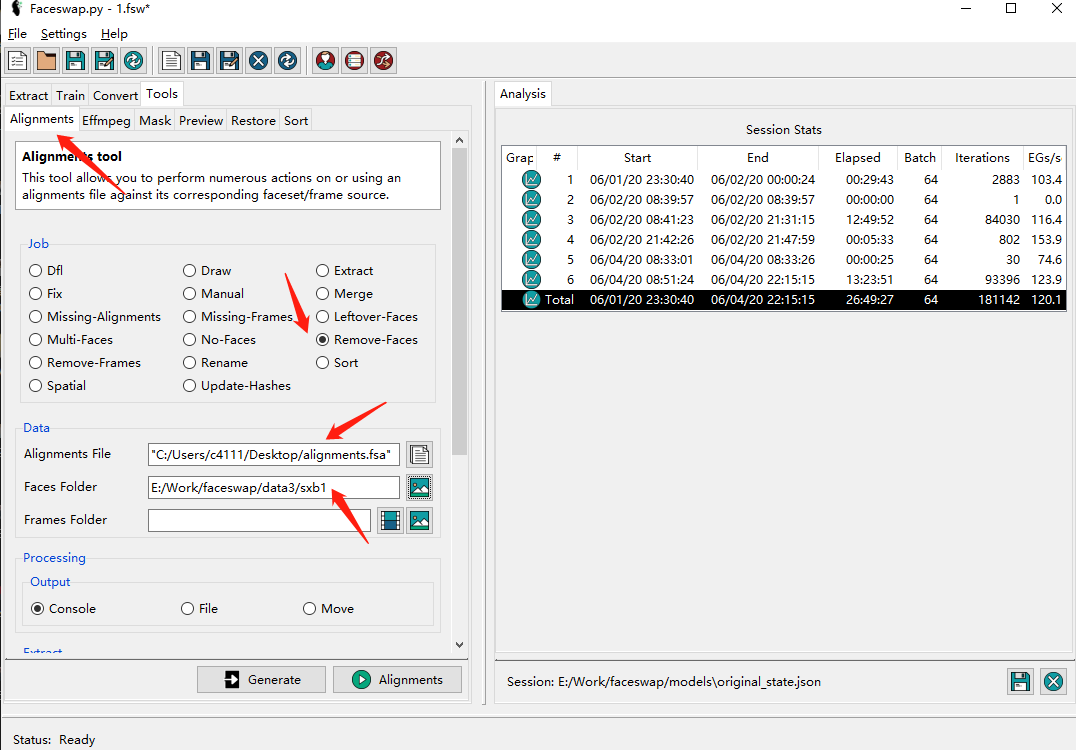
其中 Alignments files 是 Extract 后生成的對齊文件,F(xiàn)aces Folder 是我們剛剛 Sort 后的輸出目錄。設置完畢后點擊Alignments 即可。
這樣我們就獲得了,重新排序好,干凈的宋小寶人臉數據集和人臉對齊文件。
另外一個數據集,處理方法同理。

數據集要保證一下幾點:
圖片要高清!模糊的圖片訓練效果欠佳。
圖片要多樣化!僅僅一個處理一個視頻得到的圖片是不夠的,要找足夠多樣豐富的圖片作為數據集。
數據集 A 和 數據集 B 越多越好,至少各 1000 張左右。
模型訓練
訓練模型不麻煩,選擇數據集 A 和 數據集 B 的地址,以及兩個數據集對應的人臉對齊文件。
最后再指定一個模型保存地址即可。
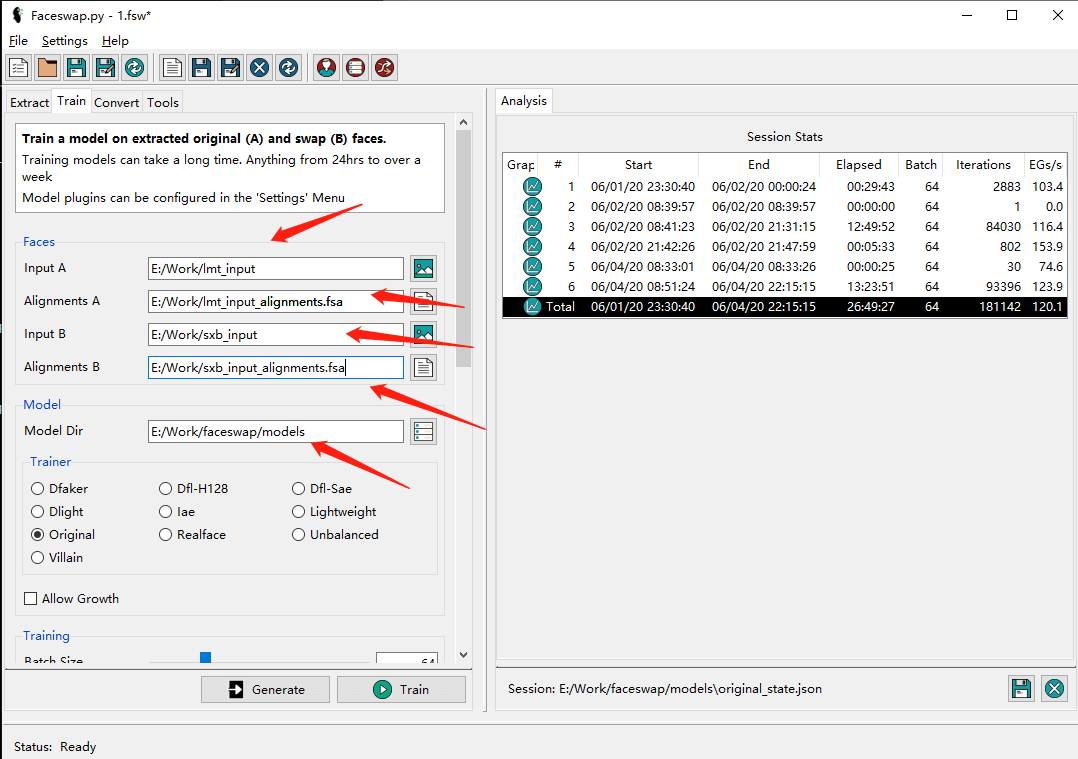
數據集 A 和 數據集 B 要區(qū)分一下,誰替換誰。
比如,我是要將《紅色高跟鞋》的劉敏濤替換為宋小寶。
那么,數據集 A 就是劉敏濤的圖片,數據集 B 就是宋小寶的圖片。
點擊 Train 就可以開始訓練了。
訓練過程中,點擊 Preview,可以看到中間的訓練結果。
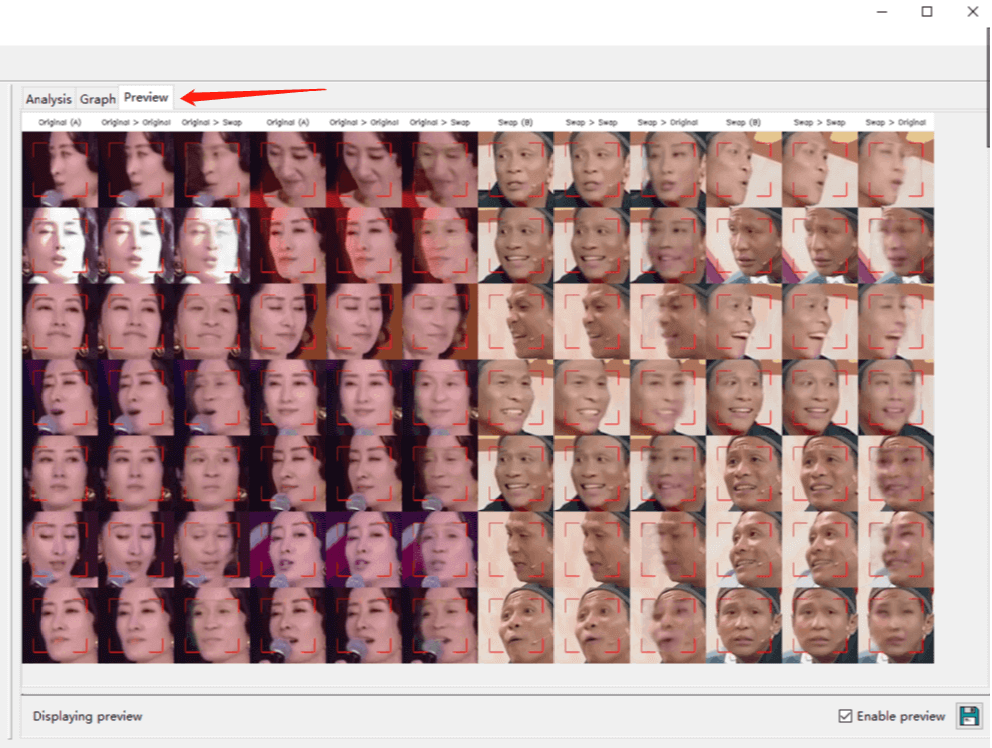
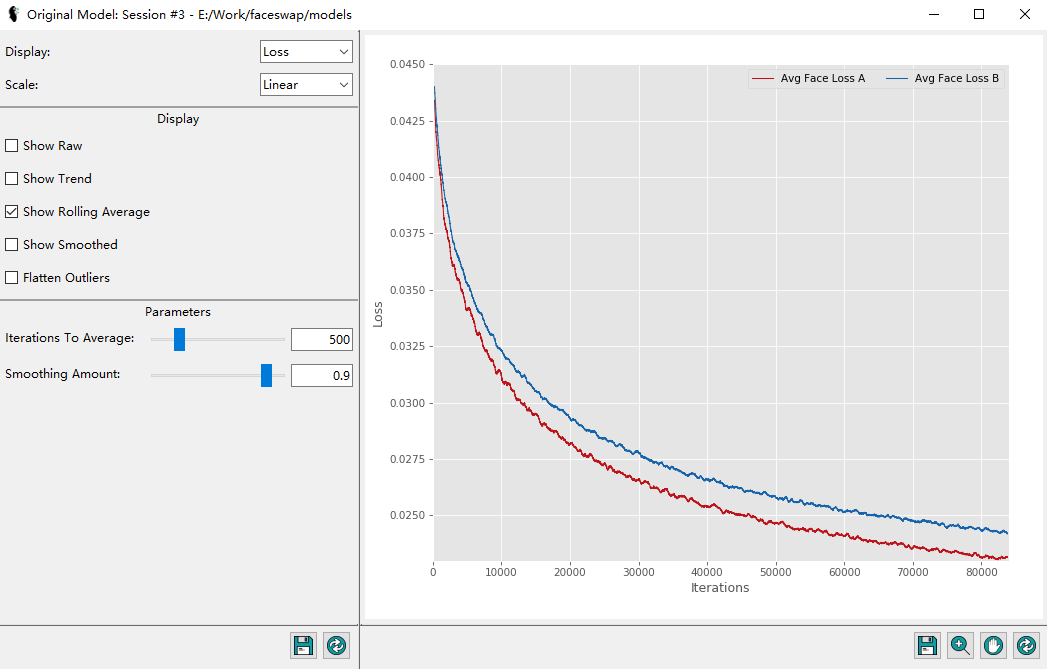
點擊 Analysis 可以看到 Loss 的收斂情況。
你需要的,它都有,就問你香不香!
訓練的時候,可以選擇多種算法,也有各種訓練參數,了解一下每個算法的特點,每個訓練參數的含義,怎么訓練的更好,可以去官方論壇,看一下英文教程。
論壇地址(需代理):https://forum.faceswap.dev/
官方文檔,很全面。
效果測試
模型訓練可能需要花費一天的時間。
訓練好模型后,就可以直接搞起了。
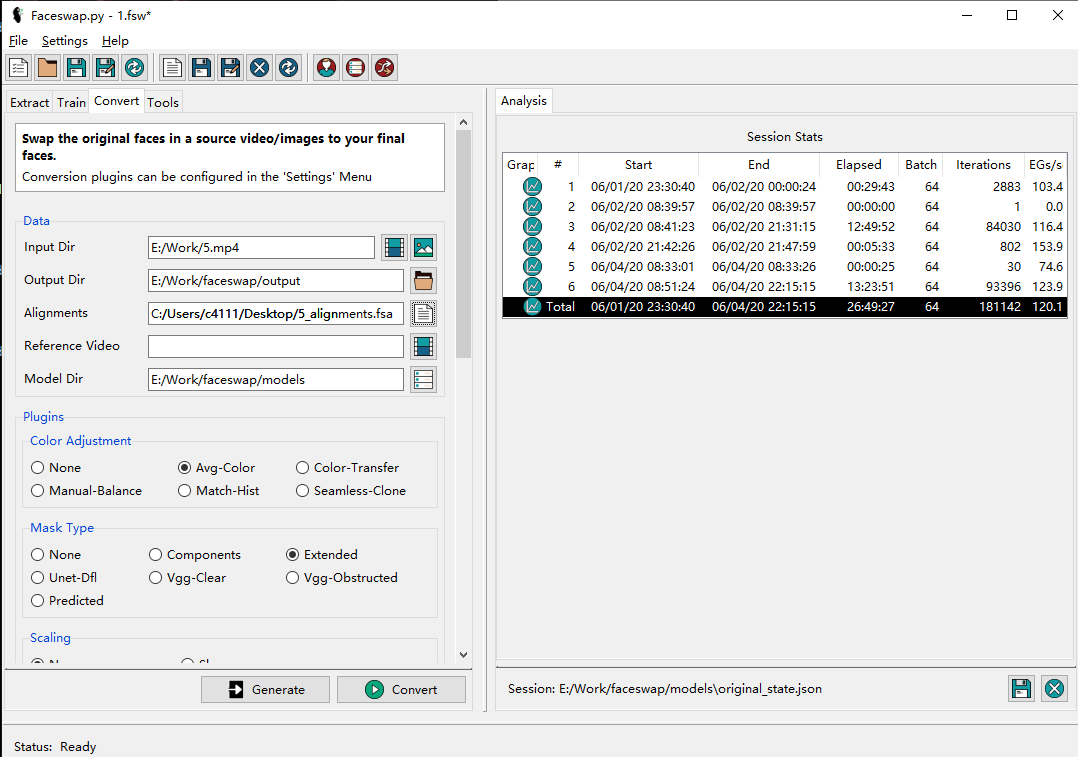
首先,需要指定需要想要替換的視頻,以及對應的人臉對齊文件(可以使用 Extract 生成)。
點擊 Convert 開始轉換!
換臉大功告成,再看一下效果!
最后
切勿濫用技術,切勿商用。
算法的魅力無處不在,多多學習背后的技術。
感謝 Jack Cui 給我們帶來了非常 nice 的分享,如果你對他感興趣的話(壞笑),不妨關注下他,就在小帥b的隔壁喲:

那么,我們下回見咯,peace!
評論
圖片
表情