
CVPR2023,中山大學(xué)和字節(jié)跳動聯(lián)合出品--虛擬試穿GP-VTON,已開源!
轉(zhuǎn)載自計算機(jī)視覺前沿

論文解讀視頻:
https://www.koushare.com/video/videodetail/56158
開源代碼:
https://github.com/xiezhy6/GP-VTON
虛擬試穿:
https://github.com/minar09/awesome-virtual-try-on
https://www.drip.com/blog/virtual-try-on-examples
摘要
基于圖像的虛擬試穿(Virtual Try-ON)旨在將店內(nèi)服裝轉(zhuǎn)移到特定的人身上。現(xiàn)有的方法采用全局扭曲模塊來建模不同服裝部分的各向異性變形,這在接收具有挑戰(zhàn)性的輸入時(例如,復(fù)雜的姿勢和復(fù)雜的服裝)不能保留不同部分之間的語義信息。此外,它們中的大多數(shù)會直接扭曲輸入的服裝以對齊保留區(qū)域的邊界,通常需要紋理壓縮來滿足邊界形狀約束,從而導(dǎo)致紋理失真。上述性能不佳阻礙了現(xiàn)有方法在現(xiàn)實世界中的應(yīng)用。為了解決這些問題并朝著現(xiàn)實世界的虛擬試穿邁進(jìn),我們提出了一個通用虛擬試穿(Virtual Try-ON)框架,稱為GP-VTON,通過開發(fā)創(chuàng)新的局部流全局解析(LFGP)扭曲模塊和動態(tài)梯度截斷(DGT)訓(xùn)練策略。具體來說,與之前的全局扭曲機(jī)制相比,LFGP使用局部流單獨扭曲服裝部分,并通過全局服裝解析組裝局部扭曲的結(jié)果,產(chǎn)生合理的扭曲部分和語義正確的完整服裝,即使在具有挑戰(zhàn)性的輸入下也是如此。另一方面,我們的DGT訓(xùn)練策略動態(tài)地截斷了重疊區(qū)域中的梯度,并且不再需要扭曲的服裝來滿足邊界約束,這有效地避免了紋理壓縮問題。此外,我們的GP-VTON可以很容易地擴(kuò)展到多類別場景,并通過使用來自不同服裝類別的數(shù)據(jù)進(jìn)行聯(lián)合訓(xùn)練。在兩個高分辨率基準(zhǔn)上的大量實驗表明了我們在現(xiàn)有最先進(jìn)方法上的優(yōu)勢。
1.簡介
虛擬試穿(VTON)的問題,旨在將一件衣服轉(zhuǎn)移到特定的人身上,對于當(dāng)今的電子商務(wù)和未來的元宇宙尤為重要。與基于3D的解決方案[2,14,16,28,34]相比,這些解決方案依賴于3D掃描設(shè)備或勞動密集型的3D注釋,基于2D圖像的方法[1,9,12,17,19,20,29,30,32,36,38-40,43]直接在圖像上進(jìn)行操作,對于現(xiàn)實世界的情況更實用,因此在過去幾年中得到了廣泛的研究。
雖然基于2D圖像的虛擬試穿方法[12,19,29]在廣泛使用的基準(zhǔn)[6,8,18]上能夠合成令人信服的結(jié)果,但仍然存在一些缺陷,使其無法應(yīng)用于現(xiàn)實場景。我們認(rèn)為這些缺陷主要包括三個方面。首先,現(xiàn)有方法對輸入圖像有嚴(yán)格的約束,并且在接收具有挑戰(zhàn)性的輸入時容易產(chǎn)生偽影。具體來說,如圖1(A)的第一行所示,當(dāng)輸入人物的姿勢復(fù)雜時,現(xiàn)有方法[12,19]無法保留不同服裝部分的語義信息,導(dǎo)致難以分辨的扭曲袖子。此外,如圖1(A)的第二行所示,如果輸入服裝是長袖且袖子和軀干之間沒有明顯的接縫,現(xiàn)有方法會在袖子和軀干之間產(chǎn)生粘性偽影。第二,大多數(shù)現(xiàn)有方法直接擠壓輸入服裝以使其與保留區(qū)域?qū)R,導(dǎo)致保留區(qū)域周圍的紋理扭曲(例如圖1(A)的第三行)。第三,大多數(shù)現(xiàn)有作品只關(guān)注上半身的試穿而忽略了其他服裝類別(即下半身、連衣裙),這進(jìn)一步限制了它們在現(xiàn)實世界場景中的可擴(kuò)展性。

為了緩解虛擬試穿系統(tǒng)的輸入約束并充分發(fā)揮其應(yīng)用潛力,本文邁出了重要一步,提出了一種名為GP-VTON的通用虛擬試穿框架,該框架可以生成逼真的試穿結(jié)果,即使在具有挑戰(zhàn)性的場景(圖1(A))中也是如此(例如,復(fù)雜的人體姿勢、難以處理的服裝輸入等),并且可以輕松擴(kuò)展到多類別場景(圖1(B))。
我們的GP-VTON的創(chuàng)新之處在于,它使用了一種名為局部流全局解析(Local-Flow Global-Parsing,LFGP)的變形模塊和動態(tài)梯度截斷(Dynamic Gradient Truncation,DGT)訓(xùn)練策略,這使得網(wǎng)絡(luò)能夠生成高保真的變形服裝,并進(jìn)一步促進(jìn)我們的GP-VTON生成逼真的試穿結(jié)果。
具體來說,大多數(shù)現(xiàn)有方法使用神經(jīng)網(wǎng)絡(luò)來建模服裝變形,通過引入薄板樣條(Thin Plate Splines,TPS)變換[3]或外觀流[44]到網(wǎng)絡(luò)中,并以弱監(jiān)督的方式訓(xùn)練網(wǎng)絡(luò)(即,沒有變形函數(shù)的真實值)。然而,基于TPS的方法[6, 18, 30, 36, 40]和基于流的方法[1, 12, 17, 19, 29]都直接學(xué)習(xí)全局變形場,因此無法表示復(fù)雜的非剛性服裝變形,這需要為不同的服裝部分采用不同的變換。以圖1(A)中復(fù)雜的姿勢為例,現(xiàn)有方法[12, 19]無法同時保證軀干區(qū)域和袖子區(qū)域的準(zhǔn)確變形,導(dǎo)致袖子扭曲過度。相比之下,我們的LFGP變形模塊選擇為不同的服裝部分學(xué)習(xí)不同的局部變形場,這可以單獨對每個服裝部分進(jìn)行變形,并生成語義正確的變形服裝,即使對于復(fù)雜的姿勢也是如此。此外,由于每個局部變形場只影響一個相應(yīng)的服裝部分,其他部分的服裝紋理與當(dāng)前變形場無關(guān),不會出現(xiàn)在當(dāng)前的局部變形結(jié)果中。因此,復(fù)雜服裝場景中的服裝粘連問題可以完全得到解決(如圖1(A)的第二行所示)。但是,將局部變形部分直接組裝在一起無法獲得逼真的變形服裝,因為不同的變形部分會重疊。為了解決這個問題,我們的LFGP變形模塊協(xié)同估計全局服裝解析以融合不同的局部變形部分,從而生成完整且明確的變形服裝。
另一方面,現(xiàn)有方法中的扭曲網(wǎng)絡(luò)[12,19,29]將平坦的服裝和保留區(qū)域的掩碼作為輸入(即在試衣過程中要保留的區(qū)域,例如上身的VTON的下裝),并強(qiáng)制將輸入服裝與保留區(qū)域的邊界對齊(例如上裝和下裝的交界處),這通常需要壓縮服裝以滿足形狀約束,并導(dǎo)致服裝交界處的紋理失真(請參考圖1(A)的第三行)。解決這個問題的一個有效辦法是利用網(wǎng)絡(luò)的梯度截斷策略進(jìn)行訓(xùn)練,其中扭曲的服裝在計算扭曲損失和保留區(qū)域的梯度之前將經(jīng)過保留掩碼的處理。通過使用這種策略,扭曲的服裝不再需要嚴(yán)格與保留邊界對齊,這在很大程度上避免了服裝壓縮和紋理失真。然而,由于對保留區(qū)域中的扭曲服裝的監(jiān)督很差,直接對所有訓(xùn)練數(shù)據(jù)使用梯度截斷會導(dǎo)致變形場有過多的自由度,這通常會導(dǎo)致扭曲結(jié)果中的紋理拉伸。為了解決這個問題,我們提出了一種動態(tài)梯度截斷(DGT)訓(xùn)練策略,該策略根據(jù)平坦服裝和扭曲服裝之間高度-寬度比例的差異,對不同的訓(xùn)練樣本動態(tài)地執(zhí)行梯度截斷。通過引入動態(tài)機(jī)制,我們的LFGP扭曲模塊可以緩解紋理拉伸問題,并獲得更佳紋理保真的現(xiàn)實扭曲服裝。
總的來說,我們的貢獻(xiàn)可以概括如下:
(1)我們提出了一種統(tǒng)一的試衣框架,名為GP-VTON,用于為各種場景生成照片級逼真的結(jié)果。
(2)我們提出了一種新型的LFGP扭曲模塊,即使在輸入條件非常苛刻的情況下,也能生成語義正確的扭曲服裝。
(3)我們引入了一種簡單而有效的DGT訓(xùn)練策略,用于訓(xùn)練扭曲網(wǎng)絡(luò)以獲得無失真的扭曲服裝。
(4)在兩個具有挑戰(zhàn)性的高分辨率基準(zhǔn)上的大量實驗表明,GP-VTON在現(xiàn)有的SOTAs之上具有優(yōu)越性。
2.相關(guān)工作
以人為中心的圖像合成
生成對抗網(wǎng)絡(luò)(GAN)[13],特別是基于StyleGAN的模型[24-27],在最近的逼真的圖像合成方面取得了顯著的成功。因此,在人體合成領(lǐng)域,大多數(shù)現(xiàn)有方法[10,11]都繼承了基于StyleGAN的架構(gòu)以獲得高保真度的合成結(jié)果。InsetGAN[10]將來自幾個預(yù)先訓(xùn)練好的GAN的結(jié)果組合成一個全身人體圖像,其中不同的預(yù)先訓(xùn)練好的GAN分別負(fù)責(zé)不同身體部位(例如人體、面部、手等)的生成。StyleGAN-Human[11]探索了高質(zhì)量人體合成的三個關(guān)鍵因素,即數(shù)據(jù)集大小、數(shù)據(jù)分布和數(shù)據(jù)對齊。在本文中,我們關(guān)注基于圖像的VTON,其目標(biāo)是通過將店內(nèi)服裝圖像擬合到參考人員上來生成逼真的人體圖像。
基于圖像的虛擬試衣
現(xiàn)有的大多數(shù)基于圖像的VTON方法[1, 6-8, 12, 17, 19, 22, 29, 30, 32, 36, 40, 41]遵循一個兩階段的生成框架,該框架將店內(nèi)服裝分別變形為目標(biāo)形狀,并通過將變形的服裝和參考人員組合來合成試穿結(jié)果。由于服裝變形的質(zhì)量直接決定了生成結(jié)果的逼真程度,因此在這個生成框架中設(shè)計一個強(qiáng)大的變形模塊是至關(guān)重要的。一些先前的方法[6, 8, 22, 36, 40, 41]利用神經(jīng)網(wǎng)絡(luò)來回歸目標(biāo)圖像中的稀疏服裝控制點,然后使用這些控制點來擬合一個TPS轉(zhuǎn)換[3]來進(jìn)行服裝變形。其他方法[1, 7, 12, 17, 19]估計一個外觀流圖[44]來建模非剛性變形,其中流圖描述目標(biāo)圖像中每個像素對應(yīng)于源圖像中的位置。與基于TPS的方法相比,基于流的方法直接預(yù)測每個像素的密集對應(yīng)關(guān)系,因此對于復(fù)雜的變形更加富有表現(xiàn)力。然而,現(xiàn)有的TPS和流基方法都直接為各種服裝部件學(xué)習(xí)全局變形場,這無法為不同的服裝部件建模不同的局部變換。因此,在接收復(fù)雜的人體姿勢時,它們無法獲得逼真的變形結(jié)果。在本文中,我們創(chuàng)新地為不同的服裝部件學(xué)習(xí)多樣化的局部變形場,從而能夠處理具有挑戰(zhàn)性的輸入。此外,現(xiàn)有方法通常會忽略受保護(hù)區(qū)域周圍的紋理失真。為了解決這個問題,我們提出了一種動態(tài)梯度截斷策略用于網(wǎng)絡(luò)訓(xùn)練。
3.文本方法
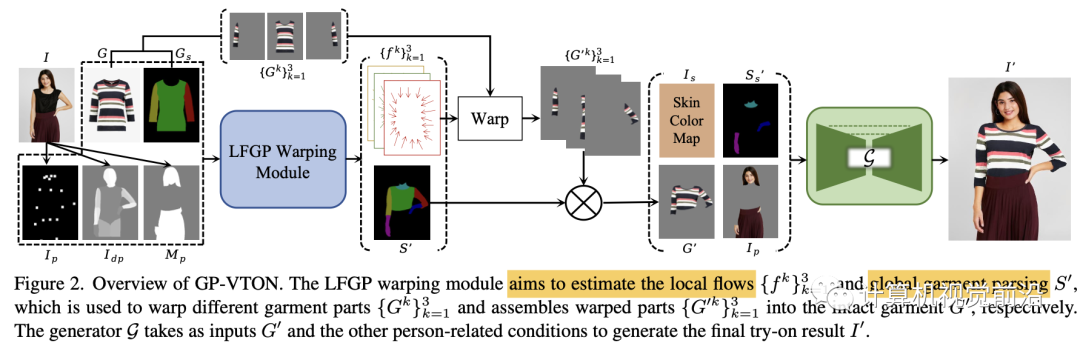
基于圖像的虛擬試衣算法旨在將店內(nèi)服裝G無縫地轉(zhuǎn)移到特定人員I上。為了實現(xiàn)這個目標(biāo),我們的GP-VTON提出了一種局部流全局解析(LFGP)變形模塊(第3.1節(jié))來對服裝進(jìn)行變形處理,該模塊首先單獨變形局部服裝部分,然后組裝不同的變形部分在一起,以獲得完整的變形服裝G′。此外,為了解決紋理失真問題,GP-VTON引入了一種動態(tài)梯度截斷(DGT)訓(xùn)練策略(第3.2節(jié))用于變形網(wǎng)絡(luò)。最后,GP-VTON采用試衣生成器(第3.3節(jié))來根據(jù)G′和其他與人員相關(guān)的輸入合成試穿結(jié)果I′。此外,GP-VTON可以很容易地擴(kuò)展到多類別場景,并使用來自不同類別的數(shù)據(jù)進(jìn)行聯(lián)合訓(xùn)練(第3.4節(jié))。GP-VTON的概述如圖2所示。
3.1. 局部流全局解析模塊Local-Flow Global-Parsing Warping Module
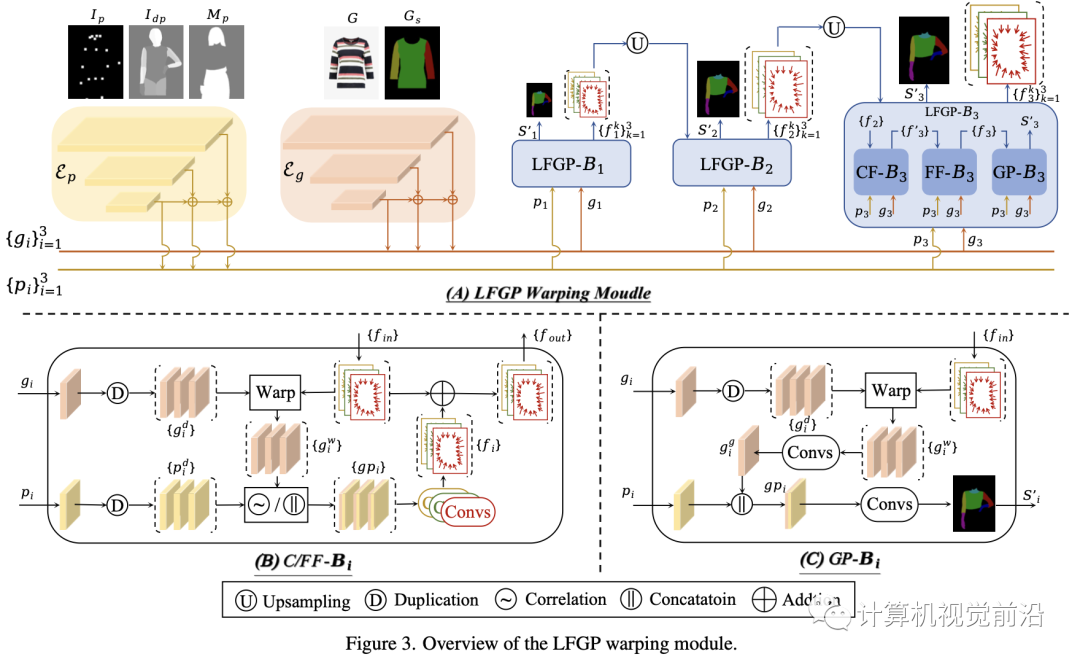
如圖3所示,我們的LFGP變形模塊遵循[12, 17, 19, 29]中的流估計管道,并由金字塔特征提取和級聯(lián)流估計組成。下面我們將解釋我們的專門改進(jìn)。
金字塔特征提取
我們的LFGP變形模塊采用兩個特征金字塔網(wǎng)絡(luò)(FPN)【31】(即圖3中的Ep和Eg)來分別提取多尺度人體特征{pi}和服裝特征{gi}。具體來說,Ep采用人體姿勢Ip、密集姿勢Idp和保護(hù)區(qū)域掩碼Mp作為輸入,其中Ip和Idp共同提供用于流估計的人體姿勢信息,而Mp對于生成保護(hù)區(qū)域感知的解析至關(guān)重要。Eg采用完好店內(nèi)服裝G及其相應(yīng)解析圖Gs作為輸入,其中Gs可以明確提供不同服裝部件的語義信息用于解析生成。值得注意的是,我們在模型中提取了五個多尺度特征(即N=5),但在圖3中為簡潔起見設(shè)定了N=3。
級聯(lián)局部流全局解析估計
大多數(shù)現(xiàn)有方法[12, 17, 19, 29]直接利用全局流對完好服裝進(jìn)行變形,當(dāng)不同服裝部分需要不同的變形時,這往往會產(chǎn)生不現(xiàn)實的變形結(jié)果。為了解決這個問題,我們的LFGP模塊將完好服裝明顯地分為三個局部部分(即左右袖子和軀干區(qū)域),并估計三個局部流以單獨對不同部分進(jìn)行變形。由于同一部分內(nèi)的變形多樣性很小,局部流可以精確處理變形并產(chǎn)生語義正確的變形結(jié)果。此外,我們的LFGP估計全局服裝解析以將局部部分組裝成完好服裝。
具體來說,如圖3(A)所示,LFGP變形模塊利用N個LFGP塊級聯(lián)估計N個多尺度局部流和全局服裝解析。每個LFGP塊由粗/精細(xì)流塊(C/FF-B)和服裝解析塊(GP-B)組成,分別估計粗/精細(xì)局部流和全局服裝解析。如圖3(B)所示,CF-B首先復(fù)制服裝特征gi并利用來自前一個LFGP塊的入站局部流{fin}將復(fù)制的服裝特征{gid}變形為三個部分感知的局部變形特征{giw}。然后,采用flownet2 [21]中的相關(guān)操作符將{giw}和復(fù)制的人體特征{pdi}集成到三個局部融合特征{gpi}中,這些{gpi}被分別發(fā)送到三個卷積層以估計相應(yīng)的局部流{f′}。最后,{f′}被添加到{fin}并產(chǎn)生精細(xì)的局部流{fout},它們是CF-B的輸出。FF-B除了將CF-B的輸出視為{fin}并將{giw}和{pdi}直接串聯(lián)起來以獲得{gpi}之外,與CF-B具有相同的結(jié)構(gòu)。對于GP-B,如圖3(C)所示,它采用FF-B中的精細(xì)局部流{fin}來將復(fù)制的特征{gid}變形為部分感知的局部特征{giw},這些{giw}被卷積層融合并成為一個全局變形特征gig。最后,將gig和傳入的pi串聯(lián)起來傳遞到卷積層以估計全局服裝解析Si′,其標(biāo)簽包括背景、左/右袖子、軀干、左/右手臂和脖子。在變形特征gig的強(qiáng)有力指導(dǎo)下,GP-B傾向于生成不同局部區(qū)域的服裝解析,這些區(qū)域的服裝形狀與其相應(yīng)的局部變形部分一致。
在LFGP模塊中的最后一個估計完成后,如圖2所示,GP-VTON通過相應(yīng)的局部流{fk}單獨對局部部分{Gk}進(jìn)行變形,并利用全局服裝解析S′將局部變形部分組裝成完整的變形服裝G′。
值得注意的是,全局服裝解析對于我們的局部變形機(jī)制是至關(guān)重要的。因為不同的變形部分之間會有重疊,直接將變形部分組合在一起會導(dǎo)致重疊區(qū)域出現(xiàn)明顯的偽影。相反,在全局服裝解析的指導(dǎo)下,完整變形服裝中的每個像素應(yīng)該來自特定的變形部分,因此可以完全消除重疊偽影。
3.2. 動圖梯度截斷Dynamic Gradient Truncation
現(xiàn)有方法[12,19,29,36,40]根據(jù)保留區(qū)域掩碼變形店內(nèi)服裝,并迫使變形后的服裝與保留區(qū)域的邊界對齊。然而,當(dāng)輸入人員是收腹?fàn)顟B(tài)時,直接將服裝變形以滿足邊界約束會導(dǎo)致保留區(qū)域周圍的紋理擠壓(如圖4的第1個案例所示)。

解決這個問題的直觀方法是,在計算訓(xùn)練損失之前使用保留掩碼來處理變形后的服裝。這樣,保留區(qū)域中的梯度將被截斷,不再需要變形后的服裝與邊界對齊。然而,當(dāng)訓(xùn)練數(shù)據(jù)是收腹?fàn)顟B(tài)時(如圖4的第二個案例所示),梯度截斷是不合適的,因為保留區(qū)域中不準(zhǔn)確的變形結(jié)果將不會受到懲罰,從而導(dǎo)致拉伸的變形結(jié)果。
為了解決上述問題,我們的DGT訓(xùn)練策略根據(jù)不同訓(xùn)練樣本的穿著風(fēng)格(即,收腹或敞開)動態(tài)地執(zhí)行梯度截斷,穿著風(fēng)格由平面服裝和真實變形服裝之間高度-寬度比例的差異(從人物圖像中提取)來確定。圖4直觀地比較了不同的訓(xùn)練策略。具體來說,我們首先通過使用相應(yīng)的服裝解析來提取平面服裝和變形服裝的軀干區(qū)域邊界框。然后,我們分別計算每個邊界框的高度-寬度比例,并使用變形服裝項R(warped)和平面服裝項R(flat)之間的比率R(style)來反映當(dāng)前訓(xùn)練樣本的穿著風(fēng)格,可以將其表示為:
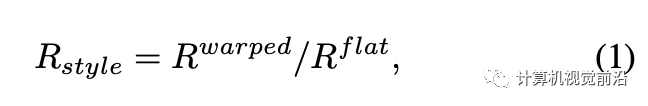
3.3. 試穿生成器
在流解析估計階段之后,GP-VTON采用基于Res-UNet的生成器G來合成試穿結(jié)果I′。如圖2所示,G將皮膚顏色圖Is、皮膚解析圖Ss′、變形服裝G′和保留區(qū)域圖像Ip作為輸入,其中Is是一個三通道RGB圖像,其值是皮膚區(qū)域(即,臉部、頸部、手臂)的中位數(shù),而Ss′是一個一通道標(biāo)簽圖,其中包含S′中的皮膚區(qū)域(即,頸部、手臂)。
3.4. 多類別虛擬試穿
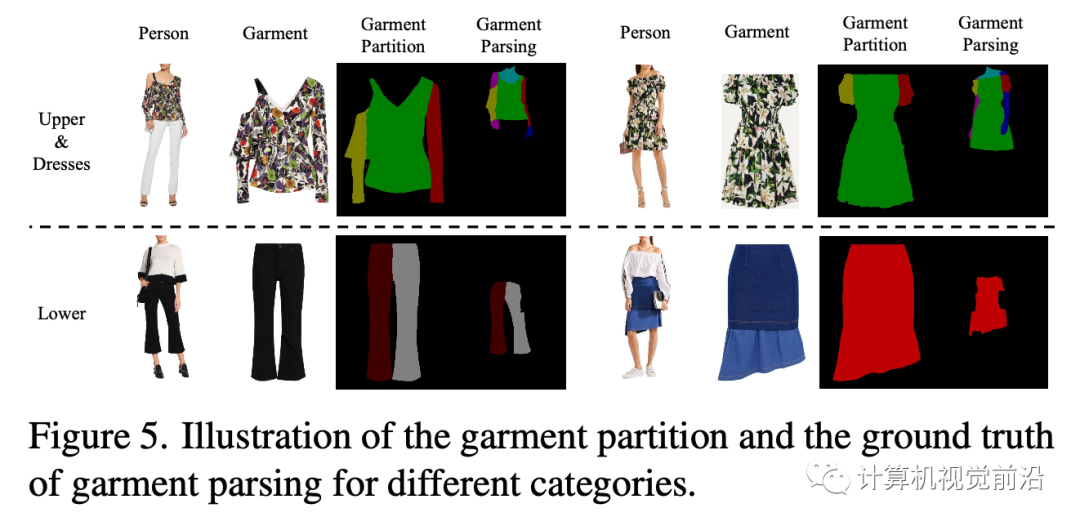
我們的GP-VTON可以通過一些微小的修改輕松地擴(kuò)展到多類別場景。核心思想是使用各種服裝類別的統(tǒng)一分區(qū)機(jī)制。在Dresscode [32]中提到,常見的服裝可以分為三個宏觀類別(即,上裝、下裝和連衣裙)。由于上裝和連衣裙具有相似的拓?fù)浣Y(jié)構(gòu),我們可以對上裝和連衣裙應(yīng)用相同的分區(qū)機(jī)制,即,將服裝分為左/右部分(即,左/右袖子)和中間部分(即,軀干區(qū)域)。為了使下裝與其他類別一致,我們將褲子和裙子視為一個單獨的類型并將其分為三個部分,這也由左/右部分(即,左/右褲腿)和中間部分(即,裙子)組成。通過使用這種分區(qū)機(jī)制,來自任意類別的服裝都可以分為三個局部部分,這些部分將單獨變形并由我們的LFGP扭曲模塊組裝成完整的變形服裝。此外,在多類別場景中,估計的服裝解析被擴(kuò)展到包括下裝、左/右褲子和裙子的標(biāo)簽。圖5顯示了不同服裝類別的服裝分區(qū)和地面真實服裝解析。
3.5 目標(biāo)函數(shù)
在訓(xùn)練過程中,我們分別訓(xùn)練LFGP扭曲模塊和生成器。對于LFGP,我們使用l1損失L1和感知損失[23] Lper來計算扭曲結(jié)果,并使用l1損失Lm來計算扭曲掩碼。我們還使用像素級交叉熵?fù)p失Lce和對抗損失Ladv來估計解析。此外,我們遵循PFAFN [12]并使用估計流場的第二階平滑損失Lsec。LFGP模塊的總損失可以表示為:

對于生成器,我們使用l1損失L1、感知損失[23] Lper以及試穿結(jié)果的對抗損失,并且還對alpha掩碼Mc使用l1損失。總損失定義如下:
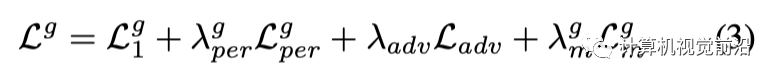
4.實驗
數(shù)據(jù)集
我們的實驗在512×384的分辨率下進(jìn)行,使用兩個現(xiàn)有的高分辨率虛擬試穿基準(zhǔn)VITON-HD [6]和Dress-Code [32]。VITON-HD包含13,679個女性正面上半身和上衣的圖像對,這些圖像對又被進(jìn)一步分為11,647/2,032個訓(xùn)練/測試對。DressCode由48,392/5,400個不同類別的正面全身人物和服裝的圖像對組成(即,上裝、下裝、連衣裙)。對于每個數(shù)據(jù)集,我們使用[4]和[15]來提取2D姿態(tài)和密集姿態(tài)。此外,我們使用一個統(tǒng)一的解析估計器來預(yù)測人物/服裝圖像的解析,該估計器基于[5],并使用80k個手工標(biāo)注的時尚圖像進(jìn)行訓(xùn)練。
基線和評估指標(biāo)
我們將GP-VTON與幾種最先進(jìn)的方法進(jìn)行比較,包括PF-AFN [12]、FS-VTON [19]、HR-VITON [29]和SDAFN [1],這些方法都是通過使用作者提供的官方代碼從零開始在VITON-HD [6]和DressCode [32]上進(jìn)行訓(xùn)練。
我們使用三種廣泛使用的指標(biāo)(即,結(jié)構(gòu)相似性指數(shù)(SSIM) [37]、感知距離(LPIPS) [42]和Fr?echet Inception Distance(FID) [33])來評估合成圖像與真實圖像之間的相似性,其中SSIM和LPIPS用于配對設(shè)置,F(xiàn)ID用于非配對設(shè)置。我們還使用扭曲服裝解析和其對應(yīng)的真實值(從人類解析中提取)之間的平均交并比(mIoU)來評估不同方法中扭曲模塊的語義正確性。此外,我們還進(jìn)行人類評估(HE),根據(jù)它們的合成質(zhì)量評估不同的方法。
4.1.定性結(jié)果
圖6和圖7分別顯示了GP-VTON與VITON-HD數(shù)據(jù)集[6]和DressCode數(shù)據(jù)集[32]上最先進(jìn)的基線的定性比較。這兩個數(shù)字都表明了GP-VTON優(yōu)于基線。首先,當(dāng)遇到復(fù)雜的姿勢時,基線無法生成語義正確的試穿結(jié)果,導(dǎo)致袖子和手臂受損(如圖6中的第一行),褲腿混雜,袖子難以區(qū)分(如圖7中的第二行中的第一例和第三行中的第一例)。其次,在接收復(fù)雜服裝(即相鄰部分之間沒有明顯間隔)時,基線容易產(chǎn)生粘合劑偽影(例如,圖6中的第二行和圖7中第二行的第二種情況)。第三,現(xiàn)有方法[12,19,29]傾向于在保留區(qū)域周圍產(chǎn)生扭曲的紋理(例如,圖6中的第三行)。相比之下,GP-VTON首先使用局部流分別扭曲不同的服裝部件,從而產(chǎn)生精確的局部扭曲部件,然后使用全局服裝解析將局部部件組裝成語義正確的扭曲服裝。因此,GP-VTON對復(fù)雜的姿勢或復(fù)雜的輸入服裝更具有魯棒性。此外,通過使用動態(tài)梯度截斷訓(xùn)練策略,GP-VTON可以避免在保留區(qū)域周圍產(chǎn)生失真的紋理。


4.2.量化結(jié)果

如表1所示,我們的GP-VTON在VITON-HD數(shù)據(jù)集的所有指標(biāo)上均持續(xù)超過基線[6],表明GP-VTON可以獲得更精確的扭曲服裝,并生成具有更好視覺質(zhì)量的試穿結(jié)果。特別是,在mIoU指標(biāo)上,GP-VTON大幅優(yōu)于其他方法,這進(jìn)一步表明我們的LFGP變形模塊能夠獲得語義正確的變形結(jié)果。表2顯示了GP-VTON在DressCode數(shù)據(jù)集[32]上與其他方法的定量比較。如表所示,對于DressCode-Upper,GP-VTON在所有指標(biāo)上均取得了最佳成績。對于DressCode-Lower和DressCode-Dresses,GP-VTON在大多數(shù)指標(biāo)上優(yōu)于其他方法,并且與SDAFN [1]相比,獲得了相當(dāng)?shù)偷腇ID分?jǐn)?shù)。這主要是因為《著裝規(guī)范-下裝》和《著裝規(guī)范-連衣裙》中的人體姿勢通常很簡單,在試穿過程中不需要復(fù)雜的變形,因此高級SDAFN[1]也可以獲得令人信服的FID分?jǐn)?shù)。然而,GP-VTON在mIoU和HE指標(biāo)上的優(yōu)勢仍然表明,其扭曲的結(jié)果在語義上更正確,其合成結(jié)果更逼真。

4.3.消融實驗
為了驗證LFGP翹曲模塊和DGT訓(xùn)練策略的有效性,我們設(shè)計了三種變體,并根據(jù)翹曲結(jié)果的度量得分評估不同變體的性能。此外,我們定義了另一個度量標(biāo)準(zhǔn)Rdiff來衡量經(jīng)扭曲的服裝和店內(nèi)服裝之間的高寬比的差異,其中較低的值表示原始高寬比的保存情況更好,從而意味著扭曲效果更好。
我們將PF-AFN[12]視為我們的第一個變體(記為LFGP ?),因為它利用全局流進(jìn)行翹曲并且未經(jīng)梯度截斷訓(xùn)練。我們進(jìn)一步通過對LFGP模塊進(jìn)行未經(jīng)梯度截斷和未經(jīng)動態(tài)梯度截斷的分別訓(xùn)練,實現(xiàn)了另外兩個變體(即LFGP ? 和LFGP ?)。
LFGP模塊

如表3所示,與LFGP ?相比,采用局部流的其他方法在SSIM和LPIPS上有所增加,并且在mIoU度量上取得了明顯的改進(jìn),這表明我們的局部流翹曲機(jī)制可以獲得更逼真且語義正確的翹曲結(jié)果。此外,我們還對完整的LFGP模型(記作LFGP')進(jìn)行了進(jìn)一步實驗,以證明全局解析的有效性。如圖8(A)所示,通過使用全局解析來組裝不同的翹曲部分,不同部分之間的重疊偽影可以得到完全消除。

DGT訓(xùn)練策略如表3所示,與LFGP ?相比,采用常規(guī)GT策略的LFGP ?獲得較低的Rdiff分?jǐn)?shù),而采用DGT策略的完整LFGP模型獲得了最低的Rdiff分?jǐn)?shù)。圖8(B)進(jìn)一步提供了不同方法之間的可視化比較,其中LFGP ?傾向于擠壓紋理,而LFGP ?傾向于拉伸紋理。相比之下,完整的LFGP模塊可以很好地保留紋理細(xì)節(jié)。定量和定性比較都表明,使用DGT進(jìn)行訓(xùn)練有助于翹曲模型保持服裝的原始高寬比,從而避免紋理擠壓或拉伸。
5.結(jié)論
在本工作中,我們提出了針對通用虛擬試衣的GP-VTON,它能夠在具有挑戰(zhàn)性的自遮擋場景中生成語義正確且逼真的試衣結(jié)果,并且可以輕松擴(kuò)展到多類別場景。具體來說,為了使服裝翹曲對復(fù)雜的輸入具有穩(wěn)健性,GP-VTON引入了局部流全局解析(LFGP)翹曲模塊,以單獨翹曲局部部分并通過估計的全局服裝解析來組裝局部翹曲部分。此外,為了緩解現(xiàn)有方法中的紋理失真問題,GP-VTON采用了動態(tài)梯度截斷(DGT)訓(xùn)練策略來進(jìn)行翹曲網(wǎng)絡(luò)訓(xùn)練。在兩個高分辨率虛擬試衣基準(zhǔn)上的實驗表明了GP-VTON在現(xiàn)有方法上的優(yōu)越性。我們的GP-VTON的局限性和社會影響將在補(bǔ)充材料中進(jìn)行討論。

點擊閱讀原文