
針對初學(xué)者的循環(huán)神經(jīng)網(wǎng)絡(luò)介紹

Python部落(python.freelycode.com)組織翻譯,歡迎轉(zhuǎn)發(fā)。
簡單介紹什么是RNN,它們?nèi)绾芜\行,以及如何用Python從頭構(gòu)建一個RNN。
循環(huán)神經(jīng)網(wǎng)絡(luò)(RNN)是一種專門處理序列的神經(jīng)網(wǎng)絡(luò)。它們通常用于自然語言處理(NLP)任務(wù),因為它們在處理文本方面非常有效。在本文中,我們將探索什么是RNN,了解它們是如何工作的,并使用Python從頭構(gòu)建一個真正的RNN(僅使用numpy庫)。
這篇文章假設(shè)你有神經(jīng)網(wǎng)絡(luò)的基本知識。我對神經(jīng)網(wǎng)絡(luò)的介紹涵蓋了你需要知道的一切,所以我建議你先讀一下(https://victorzhou.com/blog/intro-to-neural-networks/ )。
我們開始吧!
1. 為什么有用
標(biāo)準(zhǔn)神經(jīng)網(wǎng)絡(luò)(以及CNN)的一個問題是,它們只能處理預(yù)先確定的大小: 它們接受固定大小的輸入并產(chǎn)生固定大小的輸出。RNN是有用的,因為它允許我們使用可變長度的序列作為輸入和輸出。下面是一些RNN的例子:

輸入為紅色,RNN本身為綠色,輸出為藍(lán)色。來源:Andrej Karpathy
這種處理序列的能力使RNN非常有用。例如:
機(jī)器翻譯(比如谷歌翻譯)是通過“多對多”RNN完成的。原始文本序列被輸入一個RNN,然后該RNN會生成翻譯文本作為輸出。
情感分析 (例如,這是一個積極的還是消極的評論?)通常是通過“多對一” 的RNN完成的。要分析的文本被輸入一個RNN,然后該RNN會生成一個單獨的輸出分類(例如,這是一個積極的評論)。
在本文的后面,我們將從頭構(gòu)建一個“多對一”的RNN來執(zhí)行基本的情感分析。
2. 工作原理
我們假設(shè)有一個帶有輸入x0,x1,...xn的“多對多”的RNN,我們希望它產(chǎn)生輸出y0,y1,...yn。這些xi 和yi是向量,可以有任意的維數(shù)。
RNN利用以任意給定的步長t反復(fù)地更新一個隱藏狀態(tài)h來運行,h是一個向量,也可以有任意的維數(shù)。
下一個隱藏狀態(tài)ht是使用前一個隱藏狀態(tài)ht -1和下一個輸入xt進(jìn)行計算的。
下一個輸出yt是使用ht進(jìn)行計算的。

一個多對多RNN
這就是使RNN循環(huán)的東西: 它對每個步驟使用相同的權(quán)重。具體來說,一個典型的標(biāo)準(zhǔn)RNN只使用3組權(quán)重來進(jìn)行計算:
Wxh, 用于所有的 xt → ht 連接。
Whh, 用于所有的 ht-1 → ht 連接。
Why, 用于所有的 ht → yt 連接。
我們也對我們的RNN使用兩個偏差:
bh,計算ht時加上。
by, 計算yt時加上。
我們用矩陣表示權(quán)重,用向量表示偏差。這3個權(quán)重和2個偏差就構(gòu)成了整個RNN!
下面是把所有東西放在一起的方程式:
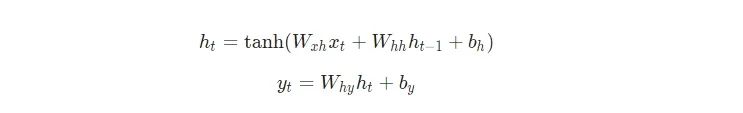
不要略過這些方程。停下來,盯著這個方程看一分鐘。另外,記住權(quán)重是矩陣,其它變量是向量。
所有的權(quán)重都使用矩陣乘法進(jìn)行應(yīng)用,并將偏差加到結(jié)果乘積中。然后,我們使用tanh作為第一個方程的激活函數(shù)(其它激活函數(shù)像sigmoid也可以使用)。
不知道什么是激活函數(shù)?請認(rèn)真閱讀我之前提到的神經(jīng)網(wǎng)絡(luò)介紹。
3. 要解決的問題
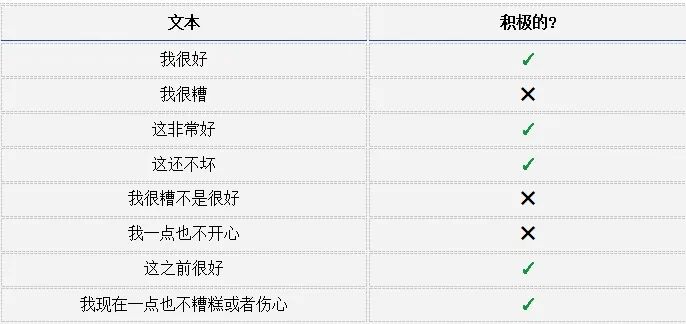
我們來動手干吧!我們將從頭實現(xiàn)一個RNN來執(zhí)行一個簡單的情感分析任務(wù): 確定給定的文本字符串是積極的還是消極的。
下面是我為本文收集的小數(shù)據(jù)集中的一些例子:
4. 計劃
由于這是一個分類問題,我們將使用“多對一" RNN。這與我們前面討論的“多對多”RNN類似,只不過它只使用最終的隱藏狀態(tài)來產(chǎn)生一個輸出y:
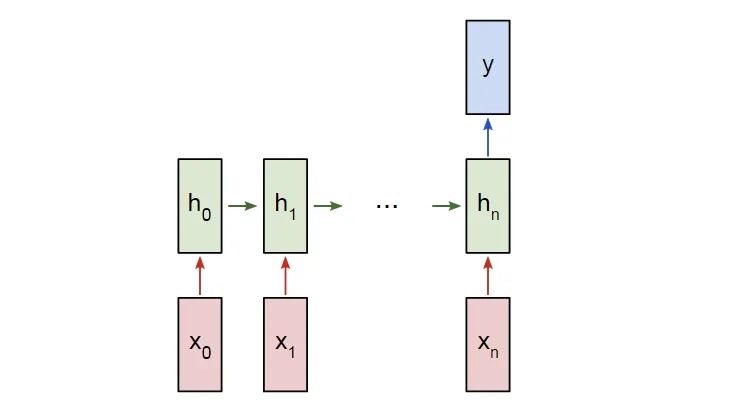
一個多對一RNN
每個xi都是一個向量,表示文本中的一個單詞。輸出y將是一個包含兩個數(shù)字的向量,一個表示積極的,另一個表示消極的。我們將使用Softmax將這些值轉(zhuǎn)換為概率,并最終在積極的/消極的之間進(jìn)行決定。
我們來開始構(gòu)建我們的RNN!
5. 預(yù)處理
我前面提到的數(shù)據(jù)集由兩個Python字典組成:

True=積極的,F(xiàn)alse=消極的
我們必須做一些預(yù)處理才能把數(shù)據(jù)轉(zhuǎn)換成可用的格式。首先,我們將構(gòu)造一個包含我們數(shù)據(jù)中所有單詞的詞匯表:

vocab現(xiàn)在包含了至少在一個訓(xùn)練文本中出現(xiàn)的所有單詞的列表。接下來,我們將分配一個整數(shù)索引來表示vocab中的每個單詞。
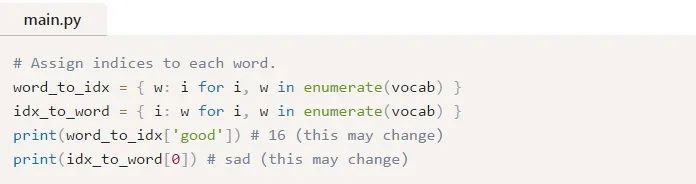
我們現(xiàn)在可以用對應(yīng)的整數(shù)索引表示任意給定的單詞!這是必要的,因為RNN不能理解單詞——我們必須給它們提供數(shù)字。
最后,回想一下RNN的每個輸入xi都是一個向量。我們將使用one-hot向量,它除了包含一個1之外,其余值都是0。每個one-hot向量中的“1”將位于這個單詞對應(yīng)的整數(shù)索引處。
由于我們的詞匯表中有18個唯一的單詞,每個xi將是一個18維的one-hot向量。

稍后,我們將使用createInputs()來創(chuàng)建向量輸入,并將其傳入我們的RNN。
6. 正向階段
是時候開始實現(xiàn)我們的RNN了!我們將從初始化我們的RNN所需要的3個權(quán)重和2個偏差開始:
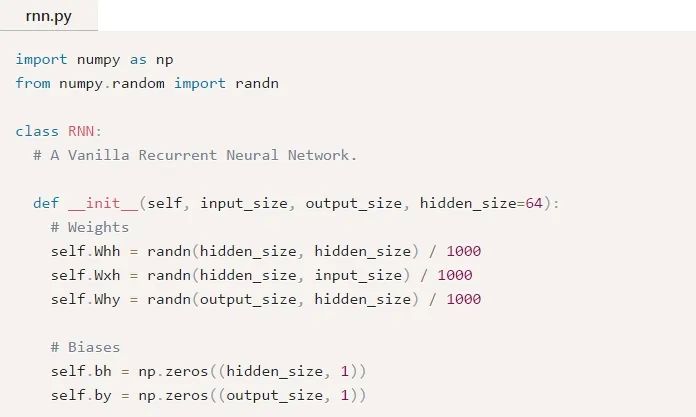
注意:我們除以1000是為了減小權(quán)重的初始方差。這并不是初始化權(quán)重的最佳方法,但它很簡單,適合本文。
我們使用np.random.randn()從標(biāo)準(zhǔn)正態(tài)分布來初始化我們的權(quán)重。
接下來,我們來實現(xiàn)RNN的正向傳遞。還記得我們之前看到的這兩個方程嗎?
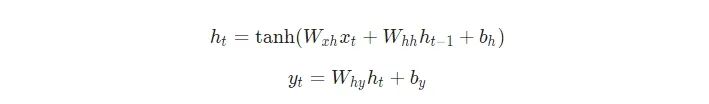
下面是這些同樣的方程被寫入代碼中的形式:
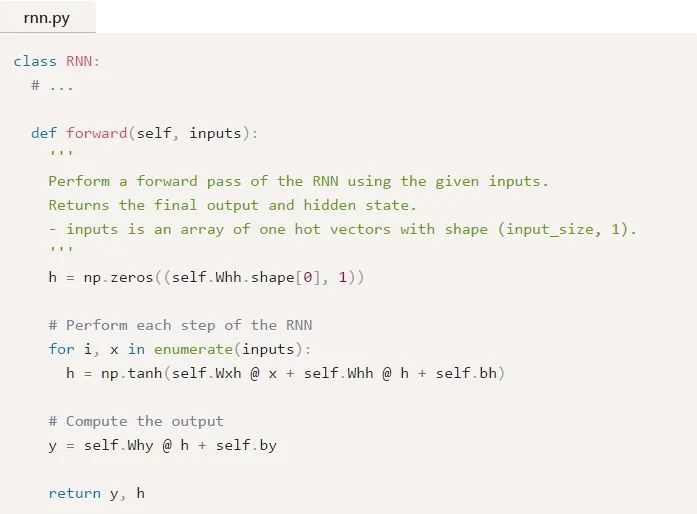
很簡單,對吧?注意,我們在第一步中將h初始化為零向量,因為此時沒有可以供我們使用的前一個h。
讓我們來試試:
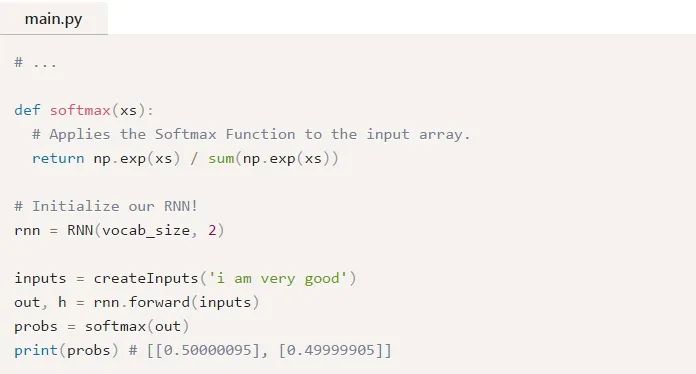
如果你需要復(fù)習(xí)一下Softmax,請閱讀我對Softmax的簡要說明。
我們的RNN可以運行,但還不是很有用。我們來改變這一點……
7. 逆向階段
為了訓(xùn)練我們的RNN,我們首先需要一個損失函數(shù)。我們將使用交叉熵?fù)p失函數(shù),它通常與Softmax配對使用。我們是這樣計算它的:
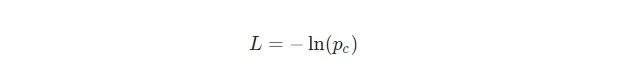
其中pc 是我們的RNN對正確類(積極的或消極的)的預(yù)測概率。例如,如果一個積極的文本被我們的RNN預(yù)測為90%的積極度,則損失為:
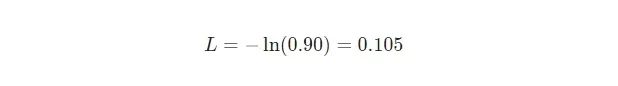
現(xiàn)在我們有了一個損失,我們將使用梯度下降訓(xùn)練我們的RNN來最小化損失。這意味著是時候推導(dǎo)一些梯度了!
??以下部分假設(shè)你有多變量微積分的基本知識。如果你愿意,你可以跳過它,但我建議即使你不太明白也要略讀一下。我們將在推導(dǎo)結(jié)果時逐步編寫代碼,即使表面的理解也會有所幫助。
如果你想了解這部分的額外背景知識,我建議你先閱讀我的《神經(jīng)網(wǎng)絡(luò)介紹》中的《訓(xùn)練神經(jīng)網(wǎng)絡(luò)》部分。此外,這篇文章的所有代碼都在Github上,所以如果你愿意,你可以follow它。
準(zhǔn)備好了嗎?我們開始吧。
7.1 定義
首先,我們來看一些定義:
讓 y代表來自我們RNN的原始輸出。
讓p代表最終的概率:p=softmax(y).
讓c 指代一個特定文本例子的真實標(biāo)簽,也可以說是“正確的”類。
讓L代表交叉熵?fù)p失:L=-ln(pc)
讓W(xué)xh 、Whh 和Why代表我們的RNN中的3個權(quán)重矩陣。
讓bh和by 代表我們的RNN中的兩個偏差向量。
7.2設(shè)置
接下來,我們需要編輯正向階段來緩存一些數(shù)據(jù),以便在反向階段中使用。在此過程中,我們還將為反向階段設(shè)置骨架。它是這樣的:

想知道我們?yōu)槭裁匆M(jìn)行緩存嗎?請閱讀我在我的CNN介紹的訓(xùn)練概述中的說明。我在其中做了同樣的事情。
7.3梯度
是用到數(shù)學(xué)的時候了!我們從計算?L/?y開始。我們知道:
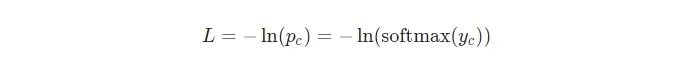
我將把使用鏈?zhǔn)椒▌t推導(dǎo)?L/?y的過程留給你,但是推導(dǎo)出來的結(jié)果是漂亮的:
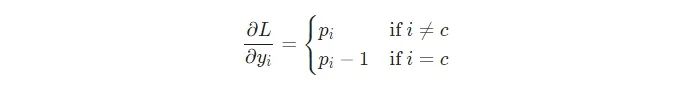
例如,如果我們有p = [0.2, 0.2, 0.6],并且其正確的類是c=0,那么我們就會得到 ?L/?y=[?0.8,0.2,0.6] 。這轉(zhuǎn)換稱代碼也是很容易的:
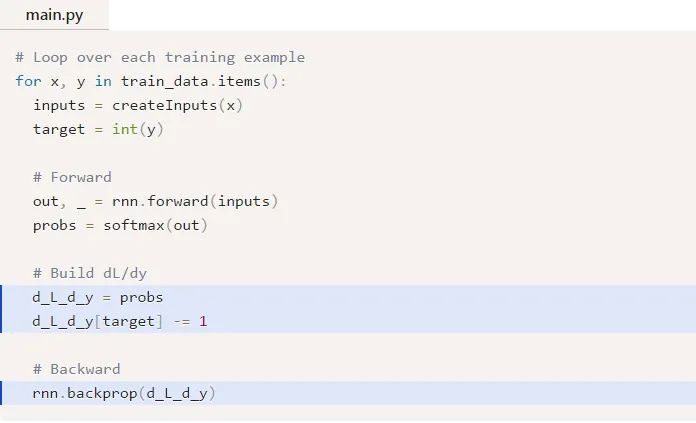
漂亮!下一步,我們來為Why和by嘗試一下梯度,它們的梯度只用與將最終的隱藏狀態(tài)轉(zhuǎn)換為RNN的輸出。我們有:

式中,hn是最終的隱藏狀態(tài),因此,
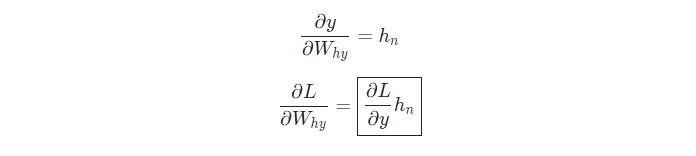
類似地,
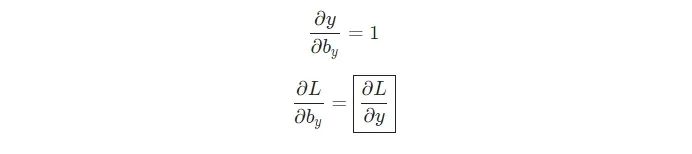
現(xiàn)在,我們可以開始實現(xiàn) backprop()!

提醒: 我們之前在forward()中創(chuàng)建了self.last_hs。
最后,我們需要Whh 、Wxh 和bh的權(quán)重,它們將在RNN中的每一步使用。我們有:
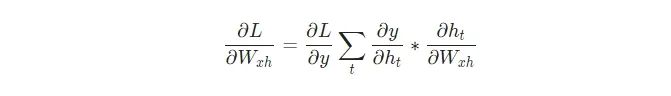
因為改變Wxh會影響每一個ht ,而每一個ht都會影響y,并最終影響L。為了完全計算Wxh的梯度,我們需要反向傳播所有的步長,這也被稱為隨時間反向傳播(BPTT):

隨時間進(jìn)行的反向傳播
Wxh被用于所有的xt —> ht 正向連接,因此我們必須反向傳播回這些連接的每一個。
一旦我們到達(dá)了一個給定的步長t,我們需要計算?ht/?Wxh
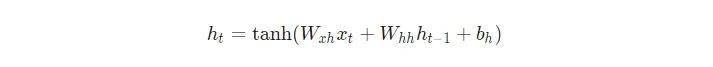
tanh的推導(dǎo)是眾所周知的:
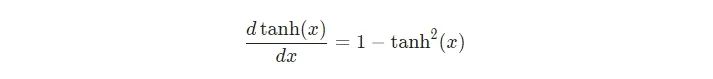
我們和平常一樣使用鏈?zhǔn)椒▌t:

類似地,
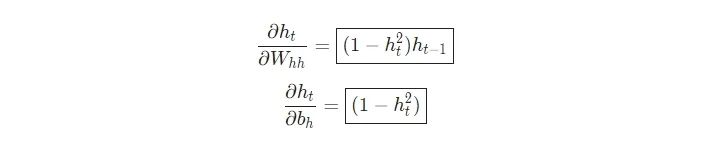
我們需要的最后一個東西是?y/?ht,我們可以遞歸地計算它:

我們將從最后的隱藏狀態(tài)開始,并逆向運行來實現(xiàn)BPTT,這樣當(dāng)我們想要計算?y/?ht+1的時候我們就已經(jīng)有了?y/?ht!最后的隱藏狀態(tài)hn是一個例外:
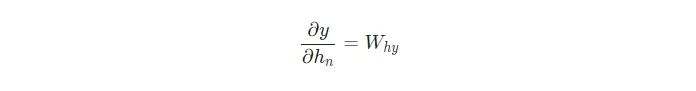
現(xiàn)在我們有了最終實現(xiàn)BPTT和完成backprop()所需要的所有東西:


一些需要注意的東西:
為了方便起見,我們已經(jīng)將(?L/?y)*(?y/?h)合并到 ?L/?h中了。
我們需要不斷地更新一個保存最近的?L/?ht+1值的變量d_h,我們計算?L/?ht需要用到這個值。
在完成BPTT之后,我們使用np.clip()截取小于-1或大于1的梯度值。這有助于緩解梯度爆炸問題,這是因為有很多相乘項時,梯度就會變的非常大。對于普通的RNN來說,梯度爆炸或梯度消失是很有問題的——像LSTM這樣更復(fù)雜的RNN通常能夠很好地處理它們。
一旦所有的梯度被計算出,我們就使用梯度下降來更新權(quán)重和偏差。
我們做到了!我們的RNN是完整的。
8. 高潮
終于到了我們一直等待的時刻——我們來測試我們的RNN!
首先,我們將編寫一個輔助函數(shù)來使用我們的RNN處理數(shù)據(jù):
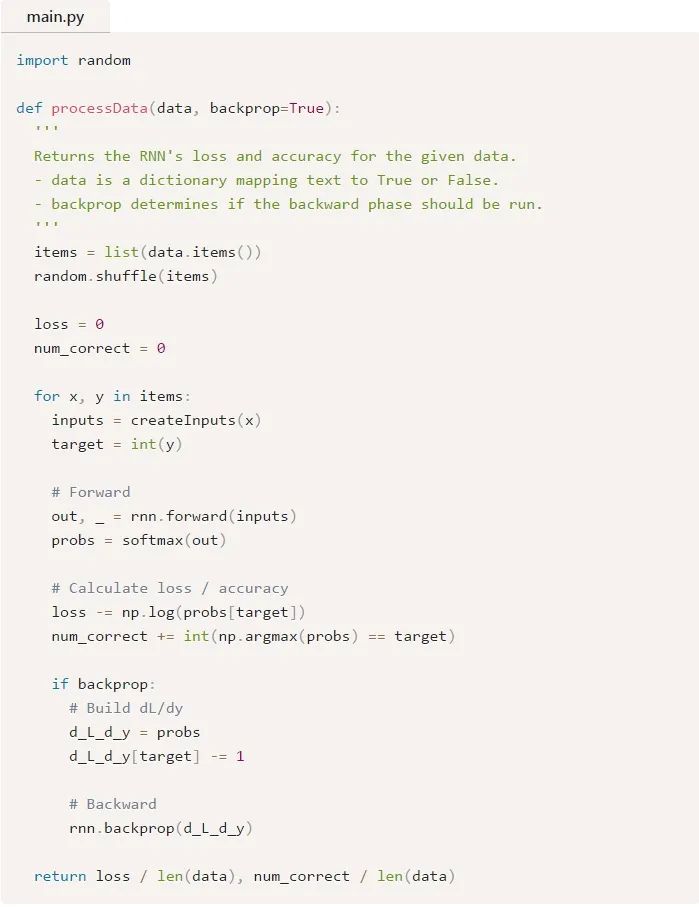
現(xiàn)在,我們可以編寫訓(xùn)練循環(huán):
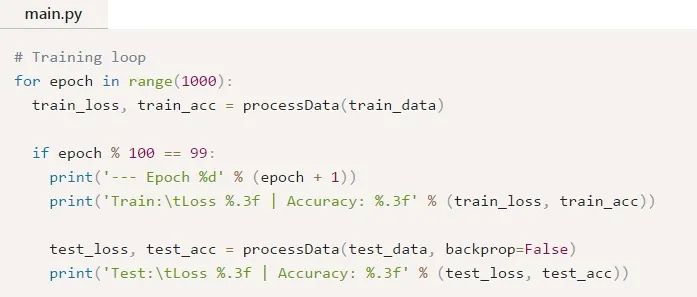
運行main.py應(yīng)該會輸出如下內(nèi)容:
從結(jié)果來看我們自己建立的RNN還不錯。
想自己嘗試或修改這段代碼嗎?請在瀏覽器中運行這個RNN(https://repl.it/@vzhou842/A-RNN-from-scratch)。你也可以在Github上找到它。(https://github.com/vzhou842/rnn-from-scratch)
9. 結(jié)尾
就是這樣!在這篇文章中,我們完成了一個循環(huán)神經(jīng)網(wǎng)絡(luò)的一個演示,包括它們是什么,它們是如何工作的,它們?yōu)槭裁从杏茫绾斡?xùn)練它們,以及如何實現(xiàn)一個。雖然如此,你還有很多事情可以做:
學(xué)習(xí)長短期記憶網(wǎng)絡(luò),一個更強(qiáng)大更流行的RNN架構(gòu),或者學(xué)習(xí)門控循環(huán)單元(GRU),一個著名的LSTM變體。
使用合適的ML庫(比如Tensorflow、 Keras或 PyTorch)對更大/更好的RNN進(jìn)行實驗。
閱讀關(guān)于雙向RNN的內(nèi)容。它會正向和反向處理序列,因此,有更多的信息對于輸出層來說是可用的。
嘗試詞嵌入(比如 GloVe 或 Word2Vec),你可以使用它們將單詞轉(zhuǎn)換成更有用的向量表示形式。
嘗試自然語言工具集(NLTK),一個流行的處理人類語言數(shù)據(jù)的Python庫。
我寫了很多關(guān)于機(jī)器學(xué)習(xí)的文章,所以如果你有興趣從我這里獲得前沿的ML內(nèi)容,請訂閱我的時事通訊。
英文原文:https://victorzhou.com/blog/intro-to-rnns/
↓掃描關(guān)注本號↓