
【學(xué)術(shù)前沿】關(guān)鍵任務(wù)中自動化適應(yīng)的認(rèn)知建模

聲明:本文只是針對個人學(xué)習(xí)記錄,侵權(quán)可刪。本人自覺遵守《中華人民共和國著作權(quán)法》和《伯爾尼公約》等法律,其他個人或組織等轉(zhuǎn)載請保留此聲明,并自負(fù)法律責(zé)任。論文版權(quán)與著作權(quán)等全歸原作者所有。

文章摘要
引言
自動化技術(shù)近年來取得了顯著進(jìn)展,可以部分替代人類的認(rèn)知功能。雖然這種技術(shù)的應(yīng)用領(lǐng)域是多樣的,但最近一個突出的領(lǐng)域是車輛的自動操作。在我們的社會中,船舶和飛機的操作一般都是自動化的。對于汽車,一些功能的自動化,如速度控制(即自適應(yīng)巡航控制)和制動(防抱死)也已經(jīng)使用了很長時間。近年來,隨著傳感技術(shù)和機器學(xué)習(xí)技術(shù)的飛速發(fā)展,轉(zhuǎn)向自動控制得到了積極的發(fā)展。然而,自動駕駛(自動駕駛汽車)的全面應(yīng)用仍然存在障礙。一段時間以來,人們一直認(rèn)為,自動控制系統(tǒng)將與駕駛員的監(jiān)控系統(tǒng)一起,在自動控制系統(tǒng)無法做出正確反應(yīng)的情況下,隨時進(jìn)行干預(yù)。
當(dāng)引進(jìn)不限于車輛自動控制的新技術(shù)時,這些技術(shù)的誤用(過度依賴)和廢棄(不充分利用)往往成為一個問題。不使用新技術(shù)會導(dǎo)致創(chuàng)新減少,而濫用新技術(shù)則會導(dǎo)致嚴(yán)重事故。在人為因素領(lǐng)域,這類問題已被反復(fù)討論。
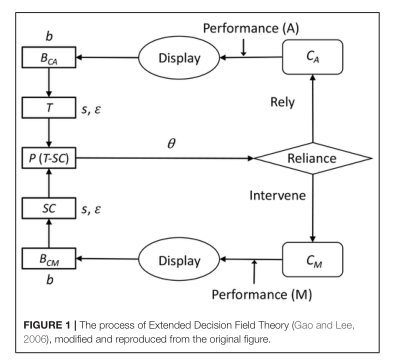
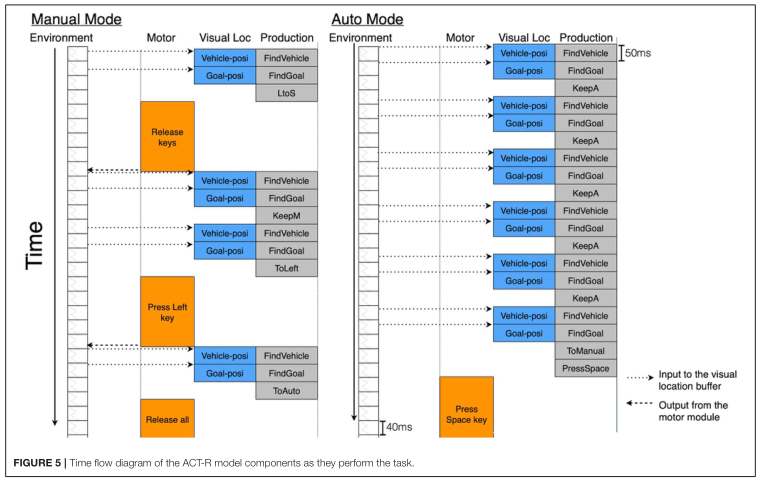
但是,該領(lǐng)域的先前研究并未充分考慮時間因素涉及新技術(shù)的適應(yīng)過程。與人因中研究的其他一些任務(wù)不同,車輛的操作是一個感知、判斷、行動依次重復(fù)的動態(tài)連續(xù)過程。自動化車輛系統(tǒng)部分地替代了這種人工操作。在一個操作人員可以使用自動操作的情況下,他/她重復(fù)感知和判斷的周期,同時觀察到一個自動化系統(tǒng)執(zhí)行整個周期。當(dāng)操作人員注意到自動控制有問題時,需要立即關(guān)閉自動控制,恢復(fù)手動控制。
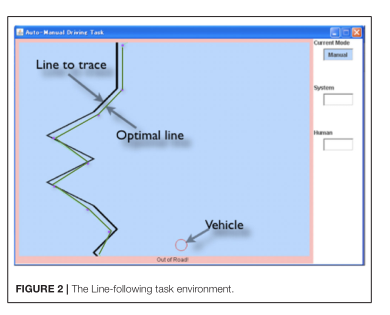
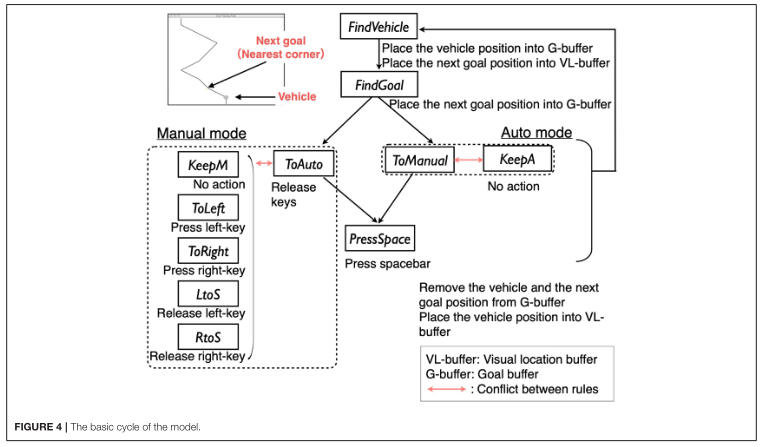
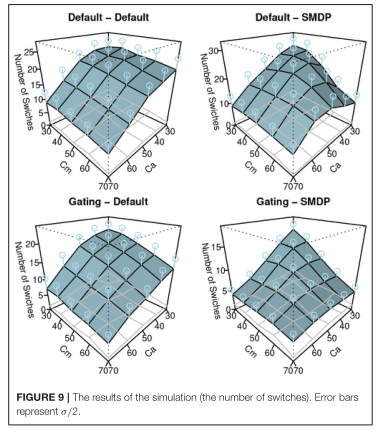
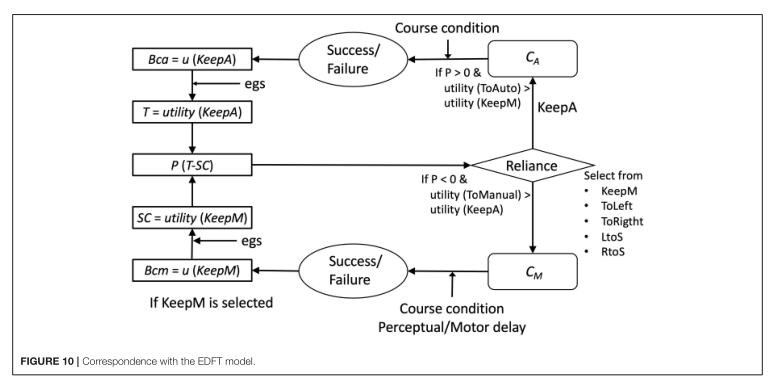
在本文中,我們提出了一個簡單的任務(wù),該任務(wù)具有帶有自動化的車輛連續(xù)操作的一些特征,并構(gòu)建了一個模型來揭示在像車輛自動操作這樣的時間關(guān)鍵任務(wù)中,什么樣的機制可以模擬人類對自動化的適應(yīng)。我們特別嘗試將傳統(tǒng)的強化學(xué)習(xí)算法與認(rèn)知架構(gòu)相結(jié)合來回答這個問題。使用認(rèn)知架構(gòu),我們將探索這個問題使用適當(dāng)?shù)臅r間限制的行為。
主要圖表
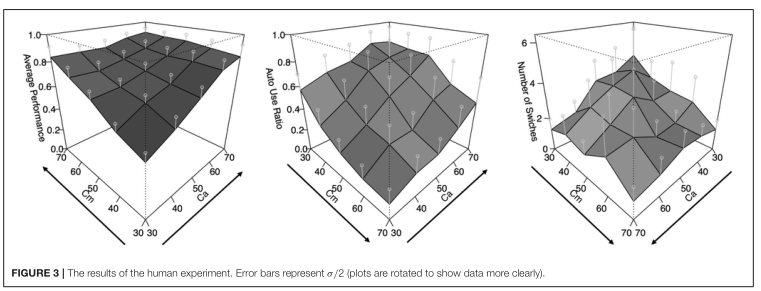

主要結(jié)論