用Python搭建一個股票輿情分析系統(tǒng)

下面的這篇文章將手把手教大家搭建一個簡單的股票輿情分析系統(tǒng),其中將先通過金融界網(wǎng)站爬取指定股票在一段時間的新聞,然后通過百度情感分析接口,用于評估指定股票的正面和反面新聞的占比,以此確定該股票是處于利好還是利空的狀態(tài)。
本地環(huán)境:
Python 3.7IDE:Pycharm
庫版本:
re 2.2.1lxml 4.6.3requests 2.24.0aip 4.15.5matplotlib 3.2.1
其中用到了百度的ai接口,通過pip安裝的方式如下:
pip install baidu-aipimport requestsimport matplotlib.pyplot as pltimport pandas as pdfrom lxml import etreefrom aip import AipNlp
1、獲取新聞數(shù)據(jù)
首先,我們需要通過金融界(http://stock.jrj.com.cn/share)的網(wǎng)站爬取股票的新聞信息。獲取指定股票的新聞資訊的接口形式是:
http://stock.jrj.com.cn/share,股票代碼,ggxw.shtml如:http://stock.jrj.com.cn/share,600381,ggxw.shtml
如600381股票的新聞資訊如下圖所示:
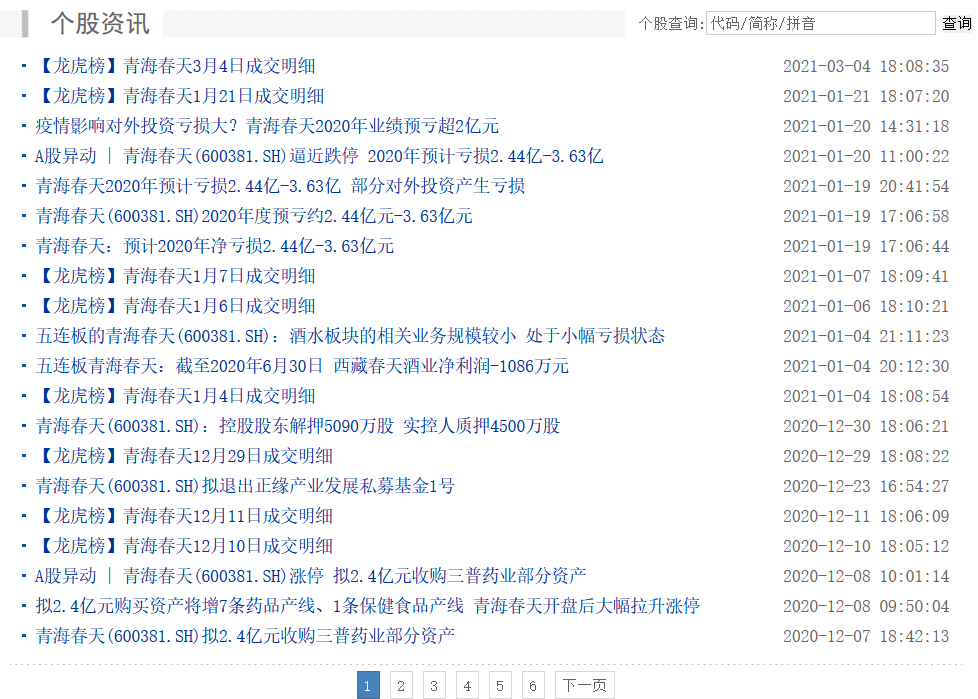
需要注意的是,當獲取后面幾頁的新聞時,其接口需要加一個后綴,形式如下:
http://stock.jrj.com.cn/share,600381,ggxw_page.shtml如獲取第二頁,http://stock.jrj.com.cn/share,600381,ggxw_2.shtml
首先,我們定義一個函數(shù),傳入一個股票代碼的列表,表示用于下載到本地的股票新聞的代碼。然后將每個股票的代碼拼接到api中,然后調(diào)用parse_pages()函數(shù)用于爬取該api下網(wǎng)頁中的數(shù)據(jù)。
# 下載指定的股票的新聞數(shù)據(jù)def download_news(codes):for code in codes:print(code)url = "http://stock.jrj.com.cn/share," + str(code) + ",ggxw.shtml"parse_pages(url, code)
接下來,我們實現(xiàn)上面的parse_pages()函數(shù)。其中需要先獲取每一頁新聞數(shù)據(jù)的總的頁數(shù),然后針對每一頁拼接對應(yīng)的api接口,最后再對每一頁的新聞數(shù)據(jù)進行下載。
# 解析每個頁面的數(shù)據(jù)def parse_pages(url, code):max_page = get_max_page(url)for i in range(1, max_page + 1):if i != 1:url = "http://stock.jrj.com.cn/share," + str(code) + ",ggxw_" + str(i) + ".shtml"download_page(url, code)
獲取最大頁數(shù)的函數(shù)如下,其中用到了lxml下的etree模塊來解析html代碼,然后通過正則表達式獲取最大頁數(shù)。
# 獲取url下的最大page數(shù)def get_max_page(url):page_data = requests.get(url).content.decode("gbk")data_tree = etree.HTML(page_data)if page_data.find("page_newslib"):max_page = data_tree.xpath("http://*[@class=\"page_newslib\"]//a[last()-1]/text()")return int(max_page[0])else:return 1
接下來實現(xiàn)download_page()函數(shù),它的作用通過正則表達式匹配頁面中的新聞標題,并將獲取的標題數(shù)據(jù)保存到本地文件中。
# 解析指定頁面的數(shù)據(jù)并保存至本地def download_page(url, code):try:page_data = requests.get(url).content.decode("gbk")data_tree = etree.HTML(page_data)titles = data_tree.xpath("http://*[@class = \"newlist\"]//li/span/a/text()")for title in titles:title = title + "\r\n"with open(str(code) + ".txt", "a") as file:file.write(title)file.flush()returnexcept:print("服務(wù)器超時")
接下來,通過調(diào)用上面的download_news()函數(shù),并傳入需要爬取新聞的股票代碼列表,就可以將新聞數(shù)據(jù)爬取到本地了。
codes = [600381, 600284, 600570, 600519, 600258, 601179]download_news(codes)
得到的新聞數(shù)據(jù)形式如下圖所示:

2、新聞情緒分析以及統(tǒng)計
在獲取了股票的新聞數(shù)據(jù)之后,我們接下來需要對每支股票的所有新聞進行情感分析了。其中用到了百度人工智能接口aip下的aipNLP用于對所有新聞數(shù)據(jù)進行自然語言處理,并進行情感分析。需要注意的是,在通過百度人工智能接口進行情感分析之前需要先注冊并獲取APP_ID、API_KEY以及SECRET_KEY。獲取的方式如下:
首先,登錄并注冊百度人工智能平臺(https://ai.baidu.com/):

然后,在自己的控制臺中找到自然語言處理,并創(chuàng)建應(yīng)用,如下圖所示:
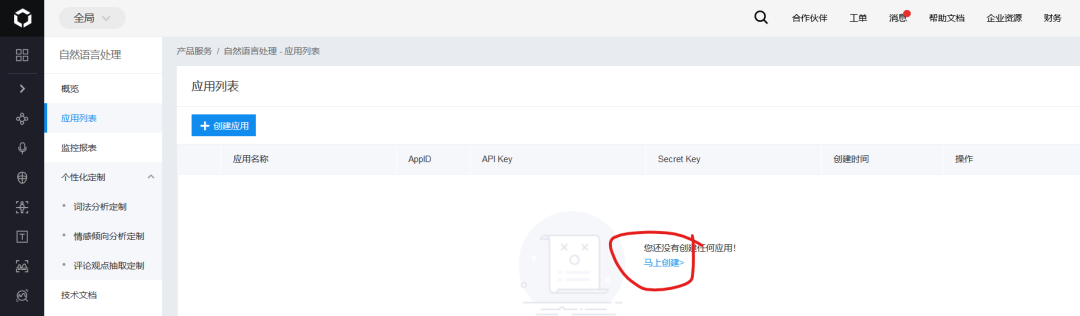
創(chuàng)建完成之后就可以得到自己的APP_ID、API_KEY以及SECRET_KEY,如下圖所示:

接下來通過一個函數(shù)來實現(xiàn)對指定的股票進行情感分析并保存到本地:
# 對指定的股票進行情感分析并保存到本地def analyze_stocks(codes):df = pd.DataFrame()for code in codes:print(code)stock_dict = analyze(code)df = df.append(stock_dict, ignore_index=True)df.to_csv('./stocks.csv')
其中的analyze()函數(shù)實現(xiàn)如下,其中需要將前面申請的APP_ID、API_KEY以及SECRET_KEY進行定義。之后讀取包含每個股票的所有新聞的文件,其中每一行表示一個新聞標題。然后通過aipNLP對每個標題進行情感分析,進而基于得到的分析結(jié)果來統(tǒng)計積極新聞和消極新聞的個數(shù),最后將針對每支股票的分析結(jié)果返回:
# 對指定股票的所有新聞數(shù)據(jù)進行情感分析并進行統(tǒng)計def analyze(code):APP_ID = 'your app id'API_KEY = 'your api key'SECRET_KEY = 'your secret key'positive_nums = 0nagative_nums = 0count = 0aipNlp = AipNlp(APP_ID, API_KEY, SECRET_KEY)lines = open(str(code) + '.txt').readlines()for line in lines:if not line.isspace():line = line.strip()try:result = aipNlp.sentimentClassify(line)positive_prob = result['items'][0]['positive_prob']nagative_prob = result['items'][0]['negative_prob']count += 1if positive_prob >= nagative_prob:positive_nums += 1else:nagative_nums += 1except:passavg_positive = positive_nums / countavg_nagative = nagative_nums / countprint('股票代碼:',code, '消極比例:', avg_nagative, '積極比例:',avg_positive)return {'股票代碼':code, '消極比例':avg_nagative, '積極比例':avg_positive}
調(diào)用下面的代碼進行分析,并生成統(tǒng)計結(jié)果:
codes =analyze_stocks(codes)
3、數(shù)據(jù)可視化
最后我們將得到的結(jié)果進行可視化,可以直觀地看到每支股票的消極新聞和積極新聞所占的比例。
def show():matplotlib.rcParams['font.sans-serif'] = ['SimHei']matplotlib.rcParams['axes.unicode_minus'] = Falsedf = pd.read_csv('./stocks.csv', index_col='股票代碼', usecols=['股票代碼', '消極比例','積極比例'])df.plot(kind='barh', figsize=(10, 8))plt.show()
效果圖如下所示:
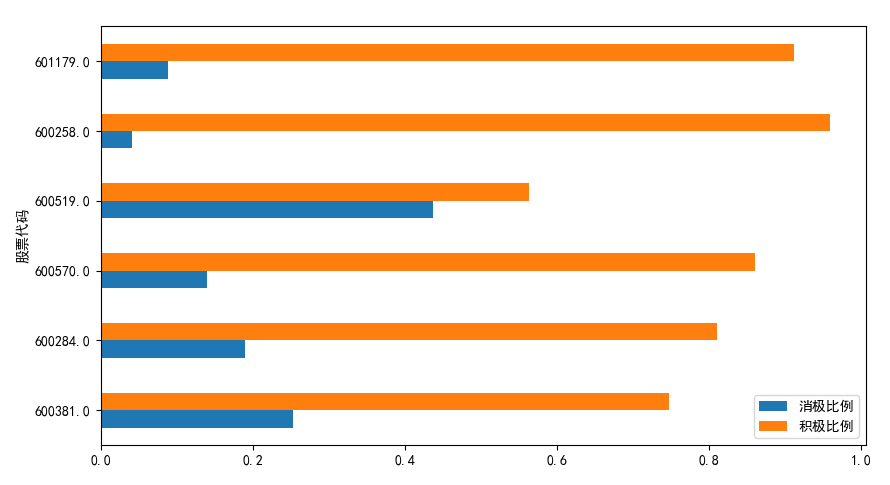
在這篇文章中,我們介紹了如何基于python搭建一個簡單的股票輿情分析系統(tǒng),其中將先通過金融界網(wǎng)站爬取指定股票在一段時間的新聞,然后通過百度情感分析接口對新聞進行情感分析,最后統(tǒng)計股票的正面和反面新聞的占比,以此確定該股票是處于利好還是利空的狀態(tài)。基于此系統(tǒng),大家可以進行進一步的進行擴展以應(yīng)用。
公眾號后臺回復“080”關(guān)鍵字獲取完整代碼。本文內(nèi)容僅僅是技術(shù)探討和學習,并不構(gòu)成任何投資建議。


Chrome 靈魂插件!

谷歌工程師開源:Python 調(diào)試神器 Cyberbrain

哈哈哈哈,這個勒索軟件笑死我了!
讓我知道你在看