
用Python登錄主流網(wǎng)站,我們的數(shù)據(jù)爬取少不了它!


不論是自然語言處理還是計(jì)算機(jī)視覺,做機(jī)器學(xué)習(xí)算法總會(huì)存在數(shù)據(jù)不足的情況,而這個(gè)時(shí)候就需要我們用爬蟲獲取一些額外數(shù)據(jù)。這個(gè)項(xiàng)目介紹了如何用 Python 登錄各大網(wǎng)站,并用簡(jiǎn)單的爬蟲獲取一些有用數(shù)據(jù),目前該項(xiàng)目已經(jīng)提供了知乎、B 站、和豆瓣等 18 個(gè)網(wǎng)站的登錄方法。
作者收集了一些網(wǎng)站的登陸方式和爬蟲程序,有的通過 selenium 登錄,有的則通過抓包直接模擬登錄。作者希望該項(xiàng)目能幫助初學(xué)者學(xué)習(xí)各大網(wǎng)站的模擬登陸方式,并爬取一些需要的數(shù)據(jù)。
作者表示模擬登陸基本采用直接登錄或者使用 selenium+webdriver 的方式,有的網(wǎng)站直接登錄難度很大,比如 qq 空間和 bilibili 等,采用 selenium 登錄相對(duì)輕松一些。雖然在登錄的時(shí)候采用的是 selenium,但為了效率,我們也可以在登錄后維護(hù)得到的 cookie。登錄后,我們就能調(diào)用 requests 或者 scrapy 等工具進(jìn)行數(shù)據(jù)采集,這樣數(shù)據(jù)采集的速度可以得到保證。
目前已經(jīng)完成的網(wǎng)站有:
Facebook
無需身份驗(yàn)證即可抓取 Twitter 前端 API
微博網(wǎng)頁版
知乎
QQZone
CSDN
淘寶
Baidu
果殼
JingDong 模擬登錄和自動(dòng)申請(qǐng)京東試用
163mail
拉鉤
Bilibili
豆瓣
Baidu2
獵聘網(wǎng)
微信網(wǎng)頁版登錄并獲取好友列表
Github
爬取圖蟲相應(yīng)的圖片
如下所示,如果我們滿足依賴項(xiàng),那么就可以直接運(yùn)行代碼,它會(huì)在圖蟲網(wǎng)站中下載搜索到的圖像。
如下所示為搜索「秋天」,并完成下載的圖像:

每一個(gè)網(wǎng)站都會(huì)有對(duì)應(yīng)的登錄代碼,有的還有數(shù)據(jù)的爬取代碼。以豆瓣為例,主要的登錄函數(shù)如下所示,它會(huì)獲取驗(yàn)證碼、處理驗(yàn)證碼、返回登錄數(shù)據(jù)完成登錄,并最后保留 cookies。

其中獲取并解決驗(yàn)證碼的函數(shù)如下:
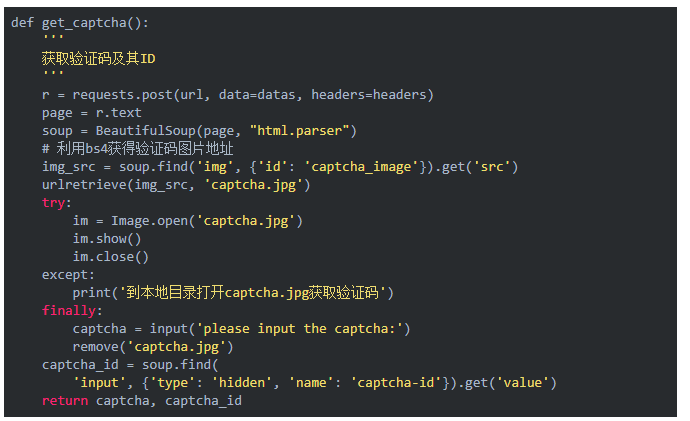
當(dāng)然這些都是簡(jiǎn)單的演示,在 GitHub 項(xiàng)目中可以找到更多的示例。此外,作者表明由于網(wǎng)站策略或者樣式改變而導(dǎo)致代碼失效,我們也可以提 Issue 或 Pull Requests。最后,該項(xiàng)目未來還會(huì)一直維護(hù),很多東西哦也會(huì)慢慢改進(jìn),項(xiàng)目作者表明:
項(xiàng)目寫了一段時(shí)間后,發(fā)現(xiàn)代碼風(fēng)格、程序易用性、可擴(kuò)展性、代碼的可讀性,都存在一定的問題,所以接下來最重要的是重構(gòu)代碼,讓大家可以更容易的做出一些自己的小功能;
如果讀者覺得某個(gè)網(wǎng)站的登錄很有代表性,可以在項(xiàng)目 issue 中提出;
網(wǎng)站的登錄機(jī)制有可能經(jīng)常的變動(dòng),所以當(dāng)現(xiàn)在的模擬的登錄的規(guī)則不能使用的時(shí)候,請(qǐng)項(xiàng)目在 issue 中提出。
*聲明:本文于網(wǎng)絡(luò)整理,版權(quán)歸原作者所有,如來源信息有誤或侵犯權(quán)益,請(qǐng)聯(lián)系我們刪除或授權(quán)事宜。