
本周優(yōu)秀開源項目分享,pytorch 人臉識別、場景文字檢測Python 包 等8大項目
?cnstd 基于 MXNet 的場景文字檢測(Scene Text Detection)Python 包
cnstd 是 Python 3 下的場景文字檢測(Scene Text Detection,簡稱STD)工具包,自帶了多個訓練好的檢測模型,安裝后即可直接使用。
當前的文字檢測模型使用的是 PSENet,目前支持兩種 backbone 模型:mobilenetv3 和 resnet50_v1b。
它們都是在 ICPR 和 ICDAR15 的 11000 張訓練集圖片上訓練得到的。
如需要識別文本框中的文字,可以結(jié)合 OCR 工具包 cnocr 一起使用。

已有模型:
當前的文字檢測模型使用的是PSENet,目前包含兩個已訓練好的模型,分別對應兩種backbone模型:mobilenetv3 和 resnet50_v1b。它們都是在ICPR和ICDAR15訓練數(shù)據(jù)上訓練得到的。

項目地址:
https://github.com/breezedeus/cnstd
?text_scalpel 文本復述任務,用于NLP語料的數(shù)據(jù)增強
文本復述任務是指把一句/段文本A改寫成文本B,要求文本B采用與文本A略有差異的表述方式來表達與之意思相近的文本。
改進谷歌的LaserTagger模型,使用LCQMC等中文語料訓練文本復述模型,即修改一段文本并保持原有語義。
復述的結(jié)果可用于數(shù)據(jù)增強,文本泛化,從而增加特定場景的語料規(guī)模,提高模型泛化能力。
谷歌在文獻《Encode, Tag, Realize: High-Precision Text Editing》中采用序列標注的框架進行文本編輯,在文本拆分和自動摘要任務上取得了最佳效果。
在同樣采用BERT作為編碼器的條件下,本方法相比于Seq2Seq的方法具有更高的可靠度,更快的訓練和推理效率,且在語料規(guī)模較小的情況下優(yōu)勢更明顯。
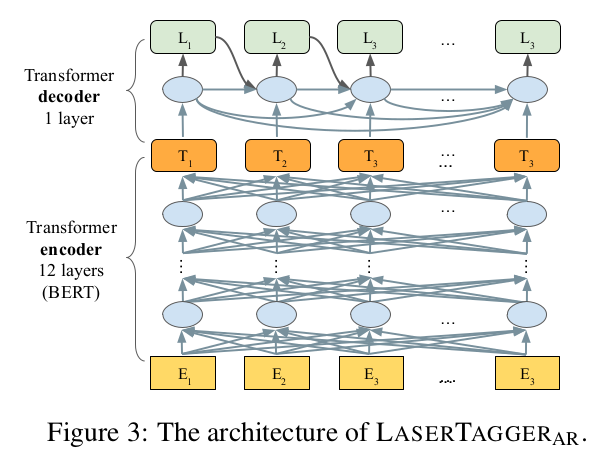
谷歌公開了本文獻對應的代碼,但是原有任務與當前任務有一定的差異性,需要修改部分代碼,主要修改如下:
A.分詞方式:原代碼針對英文,以空格為間隔分成若干詞。現(xiàn)在針對中文,分成若干字。
B.推理效率:原代碼每次只對一個文本進行復述,改成每次對batch_size個文本進行復述,推理效率提高6倍。
項目地址:
https://github.com/Mleader2/text_scalpel
?pretrained_models_and_embeddings 預訓練模型與嵌入
這個項目是從BAAI和JDAI的聯(lián)合實驗室發(fā)布一些開源自然語言模型。與其他開源中文NLP模型不同,我們主要關(guān)注對話系統(tǒng)的一些基本模型,尤其是在電子商務領(lǐng)域。
我們的語料庫非常龐大,目前我們正在使用42 GB的客戶服務對話數(shù)據(jù)(CSDD)進行培訓,其中包含約12億個句子。
我們提供了預訓練的BERT和單詞嵌入。下圖顯示了我們使用的數(shù)據(jù)。

BERT模型:
在進行預訓練時,我們使用預處理器進行數(shù)據(jù)預處理,包括一些泛化處理。
我們使用的初始化檢查點是<12層,隱藏768、12頭,110M參數(shù)>,中文,并且bert_config.json和vocab.txt與Google的原始設置相同。
我們在當前的預培訓中不使用中文全字掩蔽(WWM),而是使用中文字符級別的Google原始WWM。
詞嵌入:
在進行預訓練時,我們使用我們的工具進行預處理和分詞。
我們基于Skip-Gram訓練向量。
項目地址:
https://github.com/jd-aig/nlp_baai/tree/master/pretrained_models_and_embeddings
TNN:由騰訊優(yōu)圖實驗室打造,移動端高性能、輕量級推理框架,同時擁有跨平臺、高性能、模型壓縮、代碼裁剪等眾多突出優(yōu)勢。
TNN框架在原有Rapidnet、ncnn框架的基礎(chǔ)上進一步加強了移動端設備的支持以及性能優(yōu)化,同時也借鑒了業(yè)界主流開源框架高性能和良好拓展性的優(yōu)點。
目前TNN已經(jīng)在手Q、微視、P圖等應用中落地,歡迎大家參與協(xié)同共建,促進TNN推理框架進一步完善。
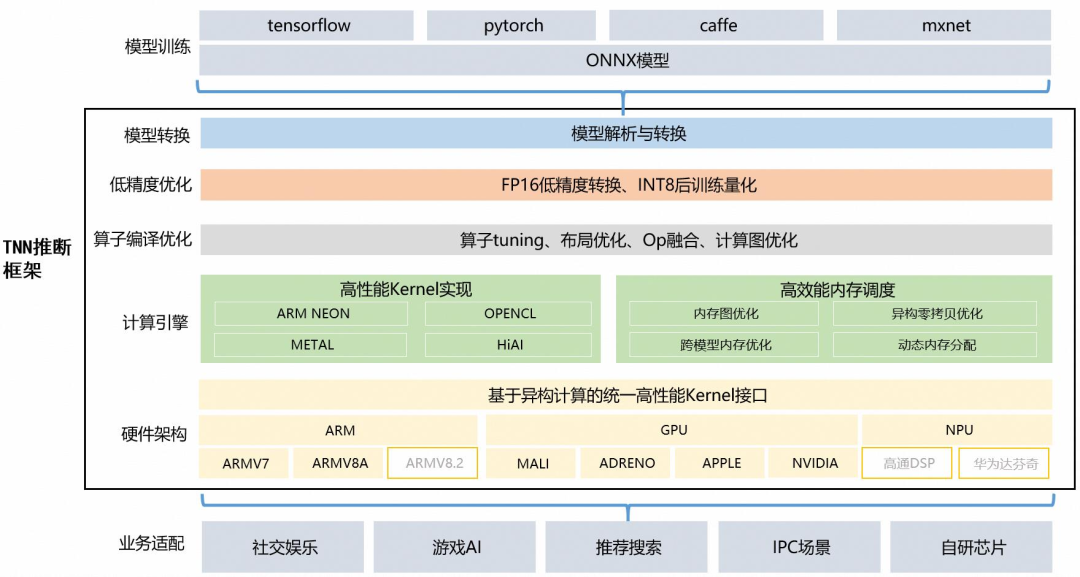
技術(shù)方案:
計算優(yōu)化:
針對不同架構(gòu)在硬件指令發(fā)射、吞吐、延遲、緩存帶寬、緩存延遲、寄存器數(shù)量等特點,深度優(yōu)化底層算子,極致利用硬件算力
主流硬件平臺(CPU: ARMv7, ARMv8, GPU: Mali, Adreno, Apple) 深度調(diào)優(yōu)
CNN 核心卷積運算通過 Winograd,Tile-GEMM, Direct Conv 等多種算法實現(xiàn),保證不同參數(shù)、計算尺度下高效計算
Op 融合:離線分析網(wǎng)絡計算圖,多個小 Op(計算量小、功能較簡單)融合運算,減少反復內(nèi)存讀取、kernel 啟動等開銷
低精度優(yōu)化:
支持 INT8, FP16 低精度計算,減少模型大小、內(nèi)存消耗,同時利用硬件低精度計算指令加速計算
支持 INT8 Winograd 算法,(輸入6bit), 在精度滿足要求的情況下,進一步降低模型計算復雜度
支持單模型多種精度混合計算,加速計算同時保證模型精度
內(nèi)存優(yōu)化:
高效”內(nèi)存池”實現(xiàn):通過 DAG 網(wǎng)絡計算圖分析,實現(xiàn)無計算依賴的節(jié)點間復用內(nèi)存,降低 90% 內(nèi)存資源消耗
跨模型內(nèi)存復用:支持外部實時指定用于網(wǎng)絡內(nèi)存,實現(xiàn)“多個模型,單份內(nèi)存”
主流模型實測性能:
v0.1 2020.05.29
項目地址:
https://github.com/Tencent/TNN
? cavaface.pytorch 人臉識別項目(PyTorch)
此項目為使用pytorch的人臉識別提供了高性能的分布式并行訓練框架,包括各種主干(例如ResNet,IR,IR-SE,ResNeXt,AttentionNet-IR-SE,ResNeSt,HRNet等),各種損失(例如,Softmax,F(xiàn)ocal,SphereFace,CosFace,AmSoftmax,ArcFace,ArcNegFace,CurricularFace,Li-Arcface,QAMFace等),各種數(shù)據(jù)擴充(例如,RandomErasing,Mixup,RandAugment,Cutout,CutMix等)和袋裝改善性能的技巧(例如FP16培訓(頂點),標簽平滑,LR預熱等)
系統(tǒng)需求:
torch == 1.4.0
torchvision == 0.5.0
tensorboardX == 1.7
bcolz == 1.2.1
Python 3
Apex == 0.1
骨干網(wǎng)絡:

損失函數(shù):

并行訓練:
數(shù)據(jù)并行
模型并行
項目地址:
https://github.com/cavalleria/cavaface.pytorch
?ShelfNet-Human-Pose-Estimation 使用ShelfNet和PyTorch進行快速準確的人體姿勢估計

這個項目目的是找出ShelfNet是否是一種有效的CNN架構(gòu),可用于語義分割以外的計算機視覺任務,尤其是用于人體姿勢估計任務。
答案是肯定的,MS COCO Keypoints數(shù)據(jù)集具有74.6 mAP和127 FPS,與HRNet相比,F(xiàn)PS提升了3.5倍,具有類似的準確性。
ShelfNet架構(gòu)是由J. Zhuang,J。Yang,L。Gu和N. Dvornek通過arXiv上的一篇論文介紹的。本文僅在語義分割任務上評估網(wǎng)絡。
作者的貢獻是在PASCAL VOC上創(chuàng)建了一種具有與最新技術(shù)(發(fā)布此存儲庫時為PSPNet和EncNet)相似的性能的快速架構(gòu),并在Cityscapes上獲得了更好的性能。
因此,ShelfNet目前是具有資源限制的最適合實際應用程序的體系結(jié)構(gòu)之一。
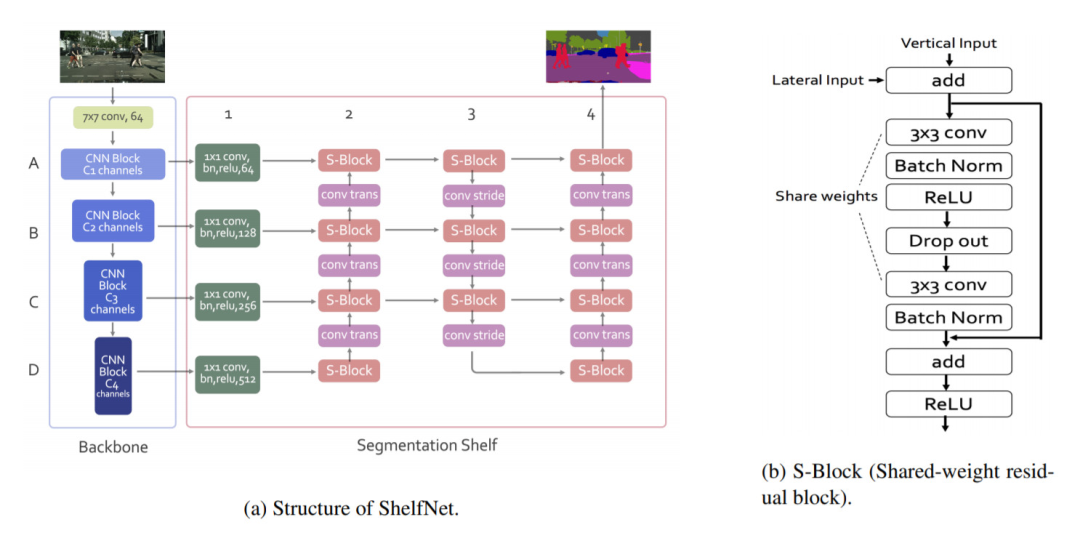
如上所述,ShelfNet使用ResNet主干結(jié)合2個編碼器/解碼器分支。第一個編碼器將信道復雜度降低了4倍,以加快推理速度。S塊是具有權(quán)重的殘差塊,可顯著減少參數(shù)數(shù)量。
網(wǎng)絡使用跨步卷積進行下采樣,并使用轉(zhuǎn)置卷積進行上采樣。該結(jié)構(gòu)可以看作是FCN的集合,其中信息流經(jīng)許多不同的路徑,從而提高了準確性。
項目地址:
https://github.com/fmahoudeau/ShelfNet-Human-Pose-Estimation
? nncf_pytorch 神經(jīng)網(wǎng)絡壓縮框架
該項目包含基于PyTorch的框架和用于神經(jīng)網(wǎng)絡壓縮的樣本。
該框架以Python軟件包的形式組織,可以在獨立模式下構(gòu)建和使用。框架架構(gòu)是統(tǒng)一的,可以輕松添加不同的壓縮方法。
這些樣本演示了在公共模型和數(shù)據(jù)集上三個不同用例中壓縮算法的用法:圖像分類,對象檢測和語義分割。在本文檔末尾的表格中,可以找到使用NNCF驅(qū)動的樣本可獲得的壓縮結(jié)果。
關(guān)鍵特征:
在模型微調(diào)過程中應用的各種壓縮算法的支持,以實現(xiàn)最佳壓縮參數(shù)和精度
量化、二值化、稀疏性、過濾修剪
自動,可配置的模型圖轉(zhuǎn)換以獲得壓縮模型。源模型由自定義類包裝,并且在圖形中插入了其他特定于壓縮的圖層
壓縮方法的通用接口
GPU加速層可加快壓縮模型的微調(diào)
分布式訓練支持
每個受支持的壓縮算法的配置文件示例
杰出的第三方存儲庫(mmdetection,havingface-transformers)的Git補丁,展示了將NNCF集成到定制培訓管道中的過程
將壓縮模型導出到ONNX檢查點,以供OpenVIN工具包使用
系統(tǒng)需求:
Ubuntu16.04 或更高版本 (64-bit)
Python 3.6或更高版本
NVidia CUDA Toolkit 10.2 或更高版本
PyTorch 1.5 或更高版本
項目地址:
https://github.com/openvinotoolkit/nncf_pytorch
9.9元秒殺【SVM與XGBoost】第三期特訓課,8月24號開課。
SVM部分 全面升級,由七月在線AI lab陳博士親授,9節(jié)課 帶你快速掌握SVM與XGBoost理論推導。
并且免費提供2020最新面試題,還有機會獲得職業(yè)規(guī)劃老師1V1簡歷優(yōu)化、1V1職業(yè)規(guī)劃。
在售價119.9元,限時9.9元秒,掃碼搶占名額!(機器學習集訓營預習課之一)
參與方式:
掃描上方海報二維碼
回復“5”
戳↓↓“閱讀原文”查看課程詳情!(機器學習集訓營預習課)