
本周優(yōu)秀開源項目分享,Python ML的核心數(shù)據(jù)框、無模型中文 NLP 工具包 等7大開源項目
?vaex 適用于Python,ML的核心數(shù)據(jù)框
Vaex是一個高性能Python庫,用于懶惰的Out-of-Core DataFrame(類似于Pandas),以可視化和探索大型表格數(shù)據(jù)集。
它在N維網(wǎng)格上以每秒超過十億(10 ^ 9)的樣本/行計算統(tǒng)計數(shù)據(jù),例如平均值,總和,計數(shù),標準差等。
可視化使用直方圖,密度圖和3d體積渲染完成,從而允許交互式探索大數(shù)據(jù)。
Vaex使用內(nèi)存映射,零內(nèi)存復制策略和惰性計算來獲得最佳性能(不浪費內(nèi)存)。
關(guān)鍵特性:
即時打開龐大數(shù)據(jù)文件(內(nèi)存映射)
核外數(shù)據(jù)框
快速分組/聚合
快速高效的合并
集成到Jupyter和Voila中以實現(xiàn)交互式筆記本和儀表板
項目地址:
https://github.com/vaexio/vaex/
?Semantic-Search 使用Transformers等進行語義搜索
使用感知嵌入的簡單應用程序可以將文檔投影到高維空間中,并使用余弦相似度找到大多數(shù)相似度。
目的是演示和比較模型。要進行大規(guī)模部署,必須計算并保存文檔嵌入,以快速搜索和計算相似性。
第一次加載需要很長時間,因為該應用程序?qū)⑾螺d所有模型。除了運行6個模型外,即使在CPU中,推理時間也是可以接受的。
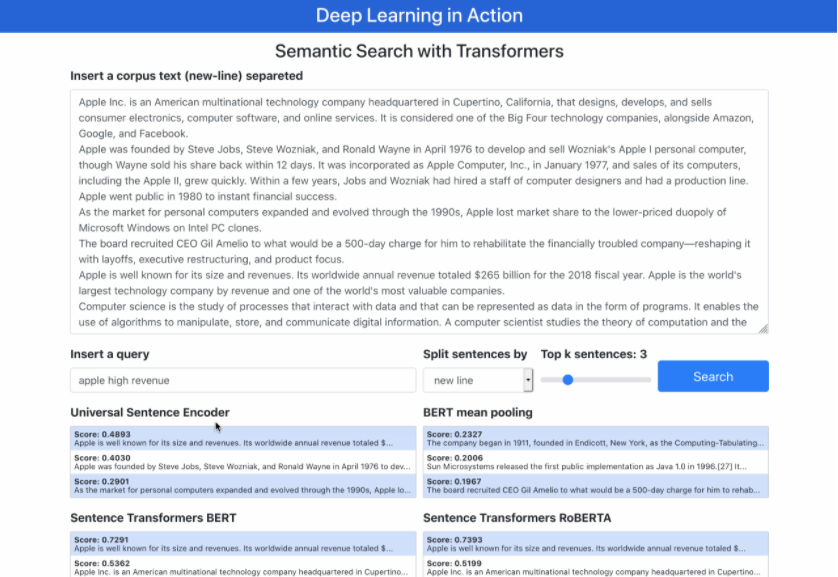
演示文本包含有關(guān)每個主題的4個句子:Apple,操作系統(tǒng),Java和Python。
可能會看到語義搜索效果很好,只過濾了有關(guān)特定查詢的文檔,即使查詢中文檔中沒有俗套的單詞也是如此。
項目地址:
https://github.com/renatoviolin/Semantic-Search
?JioNLP 無模型中文 NLP 工具包
JioNLP 是一個提供常用 NLP 功能的工具包,宗旨是直接提供方便快捷的解析、詞典類、深度學習模型加速的面向中文的工具接口,并提供一步到位的查閱入口。幫助開發(fā)者解決基礎(chǔ)的 NLP 需求和操作。
功能主要包括:文本清洗,去除HTML標簽、異常字符、冗余字符,轉(zhuǎn)換全角字母、數(shù)字、空格為半角,抽取及刪除E-mail及域名、電話號碼、QQ號、括號內(nèi)容、身份證號、IP地址、URL超鏈接、貨幣金額與單位,解析身份證號信息、手機號碼歸屬地、座機區(qū)號歸屬地,按行快速讀寫文件,(多功能)停用詞過濾,(優(yōu)化的)分句,地址解析,新聞地域識別,繁簡體轉(zhuǎn)換,漢字轉(zhuǎn)拼音,漢字偏旁、字形、四角編碼拆解,基于詞典的情感分析,色情數(shù)據(jù)過濾,反動數(shù)據(jù)過濾,關(guān)鍵短語抽取,成語詞典、歇后語詞典、新華字典、新華詞典、停用詞典、中國地名詞典、世界地名詞典,基于詞典的NER,NER的字、詞級別轉(zhuǎn)換,NER的entity和tag格式轉(zhuǎn)換,NER模型的預測階段加速并行工具集,NER標注和模型預測的結(jié)果差異對比,NER標注數(shù)據(jù)集分割與統(tǒng)計,文本分類標注數(shù)據(jù)集的分割與統(tǒng)計。
特性:
正則抽取與解析
文件讀寫工具
詞典加載與使用
實體識別(NER)算法輔助工具集
文本分類
項目地址:
https://github.com/dongrixinyu/JioNLP

deepdow是一個Python包,用于投資項目組合優(yōu)化和深度學習。它的目標是促進對在一個前向計算中執(zhí)行權(quán)重分配的網(wǎng)絡的研究。
deepdow嘗試合并投資組合優(yōu)化中兩個非常常見的步驟:
預測市場的未來發(fā)展(LSTM,GARCH等)
優(yōu)化問題設計和解決方案(凸優(yōu)化,...)
它通過構(gòu)造層流水線來實現(xiàn)。最后一層執(zhí)行分配,所有先前的層充當特征提取器。整個網(wǎng)絡是完全可微的,可以通過梯度下降算法優(yōu)化其參數(shù)。
特性:
所有層都建立在torch上并且完全可區(qū)分;
集成了可微凸優(yōu)化(cvxpylayers);
實現(xiàn)基于聚類的投資組合分配算法;
多種數(shù)據(jù)加載策略(RigidDataLoader,F(xiàn)lexibleDataLoader);
通過回調(diào)與mlflow和tensorboard集成;
提供各種損失,例如銳化比,最大跌幅,...;
易于擴展和定制;
CPU和GPU支持。
項目地址:
https://github.com/jankrepl/deepdow
? detr Transformers端對端物體檢測

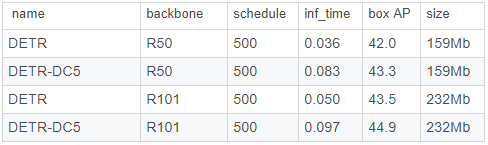
PyTorch訓練代碼和DETR(DEtection TRansformer)的預訓練模型。我們用Transformer代替了整個復雜的手工物體檢測管道,并用ResNet-50匹配了Faster R-CNN,使用一半的計算能力(FLOP)和相同數(shù)量的參數(shù)在COCO上獲得了42個AP。在PyTorch的50行中進行推斷。
與傳統(tǒng)的計算機視覺技術(shù)不同,DETR將對象檢測作為直接設置的預測問題。它由基于集合的全局損失(通過二分匹配強制唯一預測)和Transfromer編碼器-解碼器體系結(jié)構(gòu)組成。
給定固定的學習對象查詢集,則DETR會考慮對象與全局圖像上下文之間的關(guān)系,以直接并行并行輸出最終的預測集。由于這種并行性質(zhì),DETR非常快速和高效。
我們認為,對象檢測不應該比分類困難,也不需要復雜的庫來進行訓練和推理。DETR的實現(xiàn)和實驗非常簡單,我們提供了一個獨立的Colab筆記本,展示了如何僅用幾行PyTorch代碼進行DETR推理。
訓練代碼遵循了這個想法-它不是一個庫,而是一個帶有標準訓練循環(huán)的main.py導入模型和標準定義。
項目地址:
https://github.com/facebookresearch/detr
? FinancialDatasets 金融文本數(shù)據(jù)集
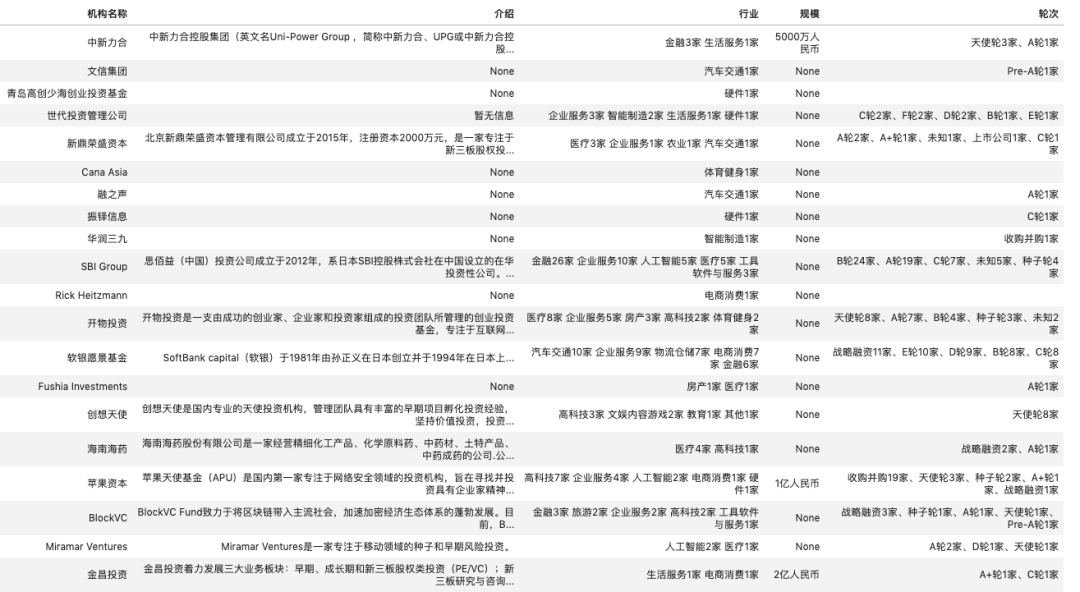

推薦研究方向:
Embedding (Word2Vec, Bert, 等)
實體識別 - NER
無監(jiān)督聚類: 基于企業(yè)描述信息, 進行競品聚類
企業(yè)行業(yè)分類
標題總結(jié) - Text Summary
序列分類 - Sequence Classification
項目地址:
https://github.com/smoothnlp/FinancialDatasets
? mmfashion 基于PyTorch的用于視覺時尚分析的開源工具箱
MMFashion是一個基于PyTorch的開源視覺時尚分析工具箱。這是香港中文大學多媒體實驗室開發(fā)的開放式mmlab項目的一部分。

項目特性:
靈活:模塊化設計,易于擴展
友好:外行用戶的現(xiàn)成模型
全面:支持各種時裝分析任務
功能:
時尚屬性預測
時尚識別與檢索
時尚地標檢測
時尚解析和細分
時尚兼容性和推薦
項目地址:
https://github.com/open-mmlab/mmfashion
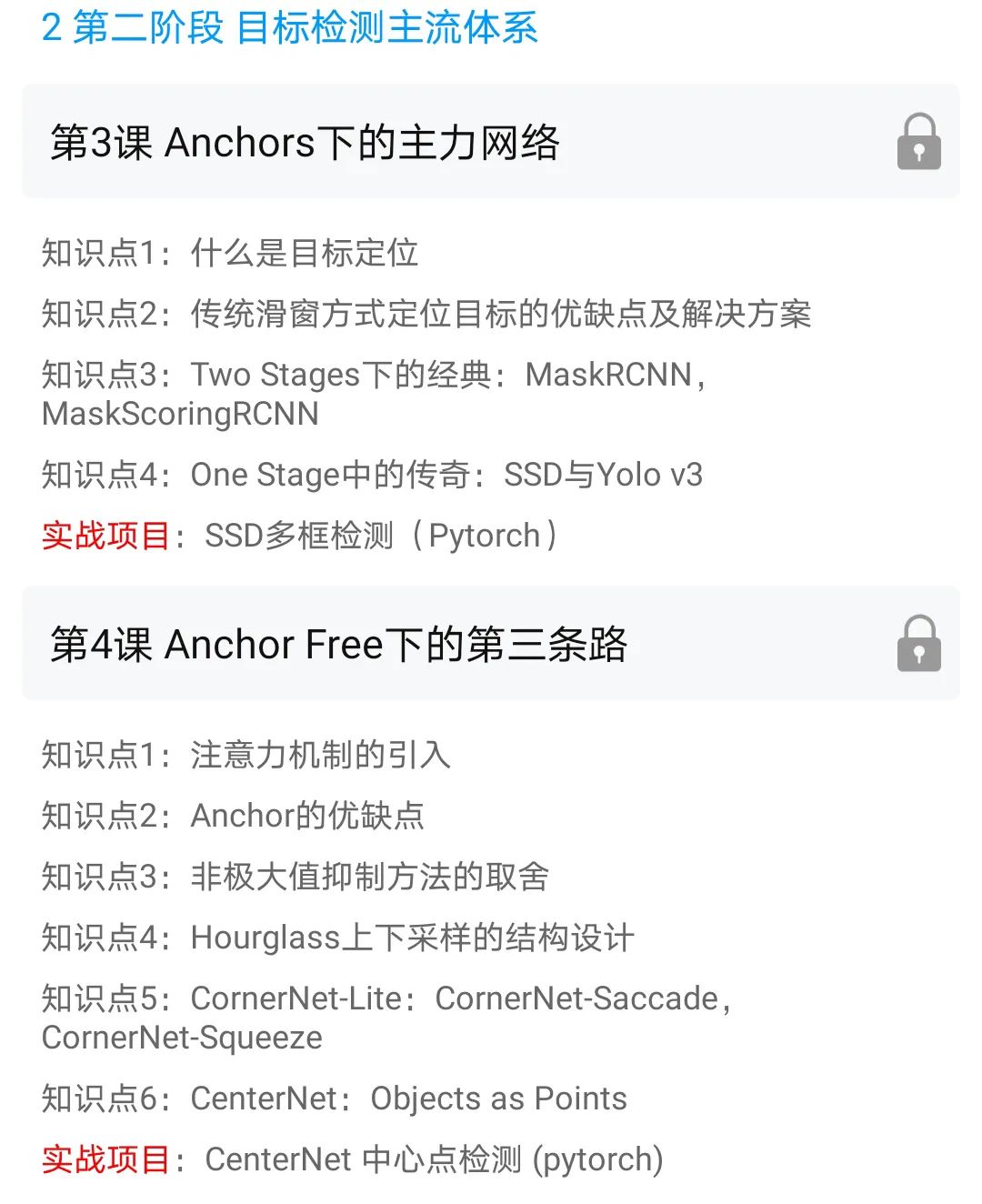
一網(wǎng)打盡:從 Mask RCNN到Y(jié)olo v4

共6大實戰(zhàn)項目

課程大綱如下


CV博士授課
在售價399元的課程,今天大家可以使用優(yōu)惠券按照299元購買,有興趣的小伙伴抓緊搶購,先報先占位!
優(yōu)惠券:?645A777EDB
購買流程:
復制優(yōu)惠券>掃描二維碼>點擊直接購買>點擊優(yōu)惠券>輸入優(yōu)惠券
掃碼搶占名額???
(報名過程中,有任何問題請加客服微信:julyedukefu12)
戳↓↓“閱讀原文”查看課程詳情!