
本文約2300字,建議閱讀8分鐘
本文將嘗試一種非常流行的攻擊:快速梯度符號方法,來證明神經(jīng)網(wǎng)絡的安全漏洞。
標簽:對抗性攻擊,神經(jīng)網(wǎng)絡

來源: neptune.ai
本文最初是由亨利·安薩(Henry Ansah)撰寫,發(fā)布在Neptune的博客上。Henry Ansah
https://www.linkedin.com/in/henry-ansah-6a8b84167
自神經(jīng)網(wǎng)絡出現(xiàn)以來,它已經(jīng)成為了機器學習算法的信條,推動了人工智能領域的絕大部分技術突破。神經(jīng)網(wǎng)絡能勝任那些對于人類富有挑戰(zhàn)性的高度復雜的任務,在執(zhí)行這些任務的同時,表現(xiàn)出非凡的魯棒性。那么,神經(jīng)網(wǎng)絡的魯棒性能超越它的初衷嗎?這便是本文需要尋求的答案。我認為,人工智能這一交叉領域無法保證絕對安全,事實證明,這也是少數(shù)幾個神經(jīng)網(wǎng)絡失敗的原因之一。在這里,將嘗試一種非常流行的攻擊:快速梯度符號方法,來證明神經(jīng)網(wǎng)絡的安全漏洞。首先,來探討不同類別的攻擊。快速梯度符號方法:
https://arxiv.org/abs/1412.6572
對抗性的攻擊
根據(jù)攻擊者對想要攻擊的模型的了解程度,可分為幾類攻擊,這其中最受歡迎的兩種攻擊分別是白盒攻擊和黑匣子攻擊。這兩種攻擊的目的都是通過在網(wǎng)絡輸入中加入噪聲, 誘使神經(jīng)網(wǎng)絡做出錯誤的預測。二者的區(qū)別在于訪問整個模型架構的能力,使用白盒攻擊時,可以完全訪問模型架構(權重)以及模型的輸入和輸出。使用黑匣子攻擊時,對模型的控制程度較低,只能訪問模型的輸入和輸出。在執(zhí)行以下兩種攻擊時,需要考慮到以下這些因素:快速梯度符號法(FGSM)將白盒法和錯誤分類相結合,誘導神經(jīng)網(wǎng)絡模型做出錯誤的預測。快速梯度符號法詳解
從名稱上聽起來,F(xiàn)GSM似乎很令人費解,但實際上,F(xiàn)GSM攻擊非常簡單,它包括以下三個步驟:第一步,計算出正向傳播后的損失,這在一般的機器學習項目中非常常見,使用一個負似然損失函數(shù)來估計模型的預測結果與實際結果的接近程度。FGSM的特別之處是,計算圖像像素的梯度,在訓練到神經(jīng)網(wǎng)絡時,利用梯度確定微移的權重的方向,從而減小損失值。與通常的做法相反,在這里,調整輸入圖像像素的梯度方向,使得損失值最大化。在訓練神經(jīng)網(wǎng)絡時,確定權重方向(即損失函數(shù)相對于該特定權重的梯度)的最常用方法是將梯度 (輸出部分)反向傳播給權重。同樣的概念也適用于FGSM,將梯度從輸出層反向傳播給輸入圖像。在神經(jīng)網(wǎng)絡訓練中,利用以下這個簡單的方程式,通過微移權重來減小損失值:new_weights = old_weights — learning_rate * gradients
同樣的概念可以應用于FGSM,根據(jù)以下方程式微移圖像的像素值,從而使得損失最大化: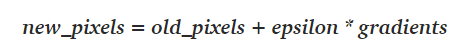
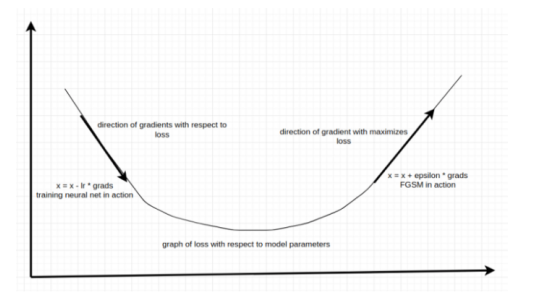
在上述圖像中,兩個箭頭表示兩種不同的調整梯度方法。左邊的方程,是訓練神經(jīng)網(wǎng)絡的基本方程,計算出的梯度指向了使損失最小化的方向,神經(jīng)網(wǎng)絡訓練方程中的負號確保了梯度指向相反的方向——使損失最小化的方向;右邊的方程則相反,這是一個欺騙神經(jīng)網(wǎng)絡的方程。也就是說,既然想要最大化損失,則以其自然的形式來應用梯度。這兩個方程式之間有許多差異,最主要的區(qū)別是加減法。利用方程2,將像素推向與損失最小化的方向相反的方向。這樣做,就是在告訴模型只做一件事——做出錯誤的預測!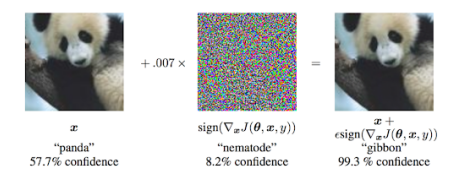
在上圖中,x表示希望模型錯誤預測的輸入圖像,圖像的第二部分表示損失函數(shù)相對于輸入圖像的梯度。記住,梯度只是一個方向張量(它提供有關微移方向的信息)。為了增強微移效應,用一個非常小的值epsilon乘以梯度,(上述圖像中為0.007),然后將結果添加到輸入圖像中,就是這樣!
對上文做一個總結之后,接下來將做一些編碼,誘導神經(jīng)網(wǎng)絡做出錯誤的預測:神經(jīng)網(wǎng)絡前向傳播圖像;
計算出損失;
將梯度反向傳播給圖像;
在損失值最大的方向上微移圖像的像素。
這樣做之后,便相當于告訴神經(jīng)網(wǎng)絡對圖像做出相反的預測。值得注意的是,噪聲對結果圖像上的影響程度取決于epsilon,epsilon值越大,噪聲就越明顯。增加epsilon值,也會加大網(wǎng)絡做出錯誤預測的可能性。代碼
在本教程中,將使用TensorFlow來構建整個管道,將重點關注代碼中最重要的部分,而不涉及與數(shù)據(jù)處理相關的部分。首先,加載TensorFlow的MobileNetV2模型:
將模型的可訓練屬性設置為假,這意味著無法訓練模型,任何通過改變模型參數(shù)以欺騙模型的操作都會失敗。可以將圖像可視化,以了解不同的epsilon值是如何影響預測以及圖像的性質,下述簡單的代碼片段便能處理這個問題。
接下來,加載圖像,通過模型運行它,并獲得圖像的損失梯度。
打印signed_grad顯示出張量。有些張量為正,另一些帶有負號,這表明梯度僅對圖像施加了方向效應。將圖像繪制出來,顯示如下圖片:
有了梯度之后,便可以在與梯度方向相反的方向上微移圖像像素。換句話說,即在損失最大化的方向上微移圖像像素。在不同的epsilon值下對預測進行攻擊,當epsilon=0時,表示沒有運行任何攻擊。
我可以得出以下結果:



注意到上面三張圖片中的模式了嗎?隨著epsilon值的增加,噪聲變得更加明顯,對錯誤預測的置信度也隨之增加。這一方法成功地愚弄了最先進的模型,在沒有對模型作任何改動的情況下,使之做出錯誤的預測。在這里,通過一個小實驗來確認上面討論的概念。在這里,不將像素與epsilon相乘再和梯度相加的方法將圖像的像素微移到損失最大化方向,而是利用減法,將圖像的像素微移到損失最小化的方向(image-eps*signed_grad)。


通過將圖像像素微移到使損失最小化的梯度方向上,增加了模型做出正確預測的置信度,置信度從41.82%上升至97.89%。下一步
自FGSM發(fā)明以來,還出現(xiàn)了其它多種具有不同攻擊角度的方法,可以在這里查看它們:Survey on Attacks。Survey on Attacks:
https://arxiv.org/abs/1810.00069
讀者既可以嘗試不同的模型和不同的圖像,也可以從零開始構建自己的模型,并嘗試不同的epsilon值。Adversarial Attacks on Neural Networks: Exploring the Fast Gradient Sign Methodhttps://medium.com/neptune-ai/adversarial-attacks-on-neural-networks-exploring-the-fast-gradient-sign-method-2ed71e87a1fe?source=topic_page---------9------------------1----------陳之炎,北京交通大學通信與控制工程專業(yè)畢業(yè),獲得工學碩士學位,歷任長城計算機軟件與系統(tǒng)公司工程師,大唐微電子公司工程師,現(xiàn)任北京吾譯超群科技有限公司技術支持。目前從事智能化翻譯教學系統(tǒng)的運營和維護,在人工智能深度學習和自然語言處理(NLP)方面積累有一定的經(jīng)驗。業(yè)余時間喜愛翻譯創(chuàng)作,翻譯作品主要有:IEC-ISO 7816、伊拉克石油工程項目、新財稅主義宣言等等,其中中譯英作品“新財稅主義宣言”在GLOBAL TIMES正式發(fā)表。能夠利用業(yè)余時間加入到THU 數(shù)據(jù)派平臺的翻譯志愿者小組,希望能和大家一起交流分享,共同進步
工作內容:需要一顆細致的心,將選取好的外文文章翻譯成流暢的中文。如果你是數(shù)據(jù)科學/統(tǒng)計學/計算機類的留學生,或在海外從事相關工作,或對自己外語水平有信心的朋友歡迎加入翻譯小組。
你能得到:定期的翻譯培訓提高志愿者的翻譯水平,提高對于數(shù)據(jù)科學前沿的認知,海外的朋友可以和國內技術應用發(fā)展保持聯(lián)系,THU數(shù)據(jù)派產(chǎn)學研的背景為志愿者帶來好的發(fā)展機遇。
其他福利:來自于名企的數(shù)據(jù)科學工作者,北大清華以及海外等名校學生他們都將成為你在翻譯小組的伙伴。
點擊文末“閱讀原文”加入數(shù)據(jù)派團隊~
轉載須知
如需轉載,請在開篇顯著位置注明作者和出處(轉自:數(shù)據(jù)派ID:DatapiTHU),并在文章結尾放置數(shù)據(jù)派醒目二維碼。有原創(chuàng)標識文章,請發(fā)送【文章名稱-待授權公眾號名稱及ID】至聯(lián)系郵箱,申請白名單授權并按要求編輯。
發(fā)布后請將鏈接反饋至聯(lián)系郵箱(見下方)。未經(jīng)許可的轉載以及改編者,我們將依法追究其法律責任。

