本文介紹了haberman乳腺癌生存二分類數(shù)據(jù)集,進行神經(jīng)網(wǎng)絡(luò)模型擬合。包含數(shù)據(jù)準備、MLP模型學習機制、模型穩(wěn)健性評估。
根據(jù)新數(shù)據(jù)集開發(fā)神經(jīng)網(wǎng)絡(luò)預測模型是一個挑戰(zhàn)。一種方法是先對數(shù)據(jù)集進行探查,然后思考什么模型適用于這個數(shù)據(jù)集,先嘗試一些簡單的模型,最后再開發(fā)并調(diào)優(yōu)一個穩(wěn)健的模型。這個流程適用于為分類、回歸預測模型問題開發(fā)高效的神經(jīng)網(wǎng)絡(luò)。本教程中,你將學習如何開發(fā)一個多層感知機神經(jīng)網(wǎng)絡(luò)模型,用于癌癥生存二分類數(shù)據(jù)集。如何加載和匯總癌癥生存數(shù)據(jù)集,根據(jù)結(jié)果來進行數(shù)據(jù)準備和模型配置。
如何探索MLP模型擬合數(shù)據(jù)的學習機制。
如何得到穩(wěn)健的模型,調(diào)優(yōu)并做預測。

Haberman 乳腺癌生存數(shù)據(jù)集首先,定義數(shù)據(jù)集并作數(shù)據(jù)探查。我們使用的是“haberman”標準二分類數(shù)據(jù)集。數(shù)據(jù)集描述的是乳腺癌患者的數(shù)據(jù),結(jié)局事件是患者生存,具體是指病人是否生存了五年活以上,或患者是否存活。這是學習不平衡數(shù)據(jù)分類問題的標準的數(shù)據(jù)集。數(shù)據(jù)集的背景描述表明,研究是在1958年到1970年期間,在芝加哥大學的Billings醫(yī)院開展的。數(shù)據(jù)集有306個樣本,3個輸入變量:我們只有以上數(shù)據(jù),無法選擇組成數(shù)據(jù)集合的病例,以及病例的特征。盡管這個數(shù)據(jù)集描述的是乳腺癌患者的生存情況,但考慮到數(shù)據(jù)集的樣本量少,以及這些數(shù)據(jù)是基于發(fā)生在幾十年前的乳腺癌病例,因此基于這個數(shù)據(jù)集的模型并不具備泛化能力。備注:聲明,我們不是要治愈乳腺癌,而是在探索一種標準的分類數(shù)據(jù)集。
從以下鏈接,可以對這個數(shù)據(jù)集有更多了解:
Haberman Survival Dataset (haberman.csv)(https://github.com/jbrownlee/Datasets/blob/master/haberman.csv)
Haberman Survival Dataset Details (haberman.names)(https://github.com/jbrownlee/Datasets/blob/master/haberman.names)
可以直接從URL中加載數(shù)據(jù)集,保存為pandas DataFrame,如下:
執(zhí)行這個例子,可以直接從這個URL加載數(shù)據(jù),獲得數(shù)據(jù)集的維度。本例中,我們可以確定,數(shù)據(jù)集有4個變量(3個輸入1個輸出變量),有306行數(shù)據(jù)。對于一個神經(jīng)網(wǎng)絡(luò)來說,這個數(shù)據(jù)量不算大,因此一個小的、并適當加入正則項的網(wǎng)絡(luò),可能更合適。另外,相對于直接拆分為訓練集和測試集,k折交叉驗證有助于生成一個更值得信賴的模型結(jié)果,因為單一的模型只需要幾秒鐘就可以擬合得到。
接下來,可以看一看數(shù)據(jù)的總結(jié)信息,并可視化數(shù)據(jù)。
執(zhí)行這個例子,首先加載了數(shù)據(jù),接著打印了對每個變量的統(tǒng)計信息。我們可以看到每個變量的均值和不同,或許在建模之前,需要先進行標準化。
我們發(fā)現(xiàn),第一個變量符合高斯分布,另外兩個輸入變量可能是指數(shù)分布。在每個變量上使用冪變換可以減少概率分布的偏差,從而提高模型的性能。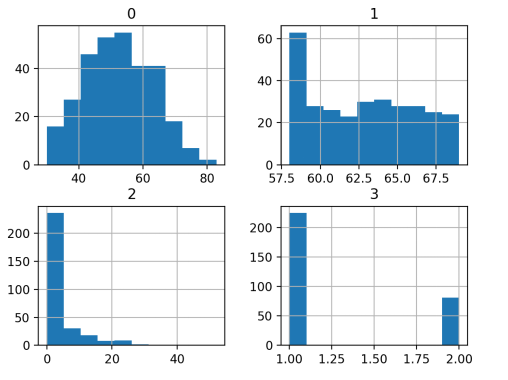
我們可以看到兩個類之間的示例分布有一些偏差,這意味著分類是不平衡的。這是不平衡數(shù)據(jù)。可以用Counter對象統(tǒng)計每個分類下的樣本量,用這個統(tǒng)計結(jié)果總結(jié)分布的特征。
執(zhí)行這個例子,會對數(shù)據(jù)集中類別的分布做一個總結(jié)。類別1包含225個樣本,約為數(shù)據(jù)集的74%,是最多的分類。類別2是未存活的樣本,只有81個,占26%。這個類別的分布是偏態(tài)的,但不是非常嚴重的不平衡。
當我們評估分類準確性的時候,考慮以上信息是有幫助的,因為任何準確度在73.5%以下的模型在這個數(shù)據(jù)集上都是沒有價值的。現(xiàn)在我們已經(jīng)熟悉了這個數(shù)據(jù)集,接下來,一起開發(fā)神經(jīng)網(wǎng)絡(luò)模型吧。神經(jīng)網(wǎng)絡(luò)學習機制我們將用TensorFlow根據(jù)這個數(shù)據(jù)集擬合多層感知機模型。我們無法知道,在這個數(shù)據(jù)集上表現(xiàn)最好的超參數(shù)是多少,所以我們需要經(jīng)過實驗尋找適合的超參數(shù)。考慮到這是個小數(shù)據(jù)集,用小批尺寸進行批量訓練可能是個好主意,例如16或32行。開始時使用Adam版本的隨機梯度下降,因為它將自動調(diào)整學習速率,并在大多數(shù)數(shù)據(jù)集上運行良好。在我們認真評估模型之前,先回顧下學習機制并調(diào)整模型架構(gòu)和學習配置,直到我們有了穩(wěn)定的學習機制,然后看看如何最大限度地利用模型。可以通過簡單地將數(shù)據(jù)劃分為測試集和訓練集,并查看學習曲線來實現(xiàn)以上目標。這個可以幫助我們了解模型過擬合還是欠擬合,接下來,我們可以根據(jù)結(jié)果調(diào)整配置。首先需要確保,輸入變量都是浮點值,目標變量是0/1的整型值。接著,我們把數(shù)據(jù)集劃分為輸入變量和輸出變量,劃分成比例為67/33的訓練集和測試集。還需要保證,訓練集和測試集上不同類別數(shù)據(jù)的分布和整個數(shù)據(jù)集是一致的。
本例中,我們可以定義一個小的MLP模型,包含一個10節(jié)點的隱藏層,一個輸出層(這個是任意選擇的)。隱藏層的激活函數(shù)用ReLu函數(shù),和he_normal 權(quán)重初始化函數(shù) ,通常這些設(shè)定在實踐中表現(xiàn)優(yōu)秀。ReLu函數(shù)
https://machinelearningmastery.com/rectified-linear-activation-function-for-deep-learning-neural-networks/
權(quán)重初始化函數(shù)
https://machinelearningmastery.com/weight-initialization-for-deep-learning-neural-networks/
模型的輸出是sigmoid激活后的二分類結(jié)果,我們將最小化二分類交叉熵損失函數(shù)。二分類交叉熵損失函數(shù)
https://machinelearningmastery.com/how-to-choose-loss-functions-when-training-deep-learning-neural-networks/
我們將擬合這個模型,由于是小樣本數(shù)據(jù),使用200個訓練epoch(任意選擇的),每個批量是16個樣本。我們認為在原始數(shù)據(jù)上擬合模型可能是個好主意,但這是個重要的起點。
訓練結(jié)束,我們將在測試集上評估模型表現(xiàn),報告分類準確度。
最后,我們將繪制訓練過程中的反映交叉熵損失的學習曲線。
把以上操作整合,得到了在癌癥生存數(shù)據(jù)集上的第一個MLP模型的完整代碼示例。
運行該示例首先在訓練數(shù)據(jù)集上擬合模型,然后在測試數(shù)據(jù)集上報告分類準確度。跟隨我的新書 Data Preparation for Machine Learning(https://machinelearningmastery.com/data-preparation-for-machine-learning/),開啟你的項目,其中包括所有示例的分步教程和Python源代碼文件。本例中,我們可以看到模型準確度超過73.5%,比上文提到的全預測為一類的準確度高。
在訓練集和測試集上的損失值的曲線圖如下。我們可以看到模型擬合的很好,沒有出現(xiàn)欠擬合和過擬合。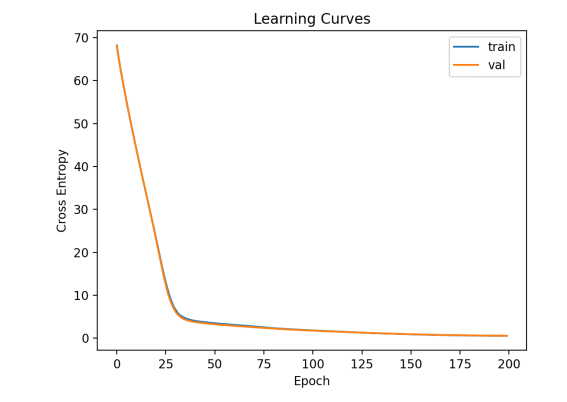
我們已經(jīng)對這個數(shù)據(jù)集上簡單的MLP模型有了一些概念,我們可以尋求更穩(wěn)健的模型評估。K折交叉驗證的過程可以對模型效果提供更可靠的評估,雖然執(zhí)行會慢一點。這是因為k模型必須進行擬合和評估。當數(shù)據(jù)集很小時,這不是問題,例如癌癥生存數(shù)據(jù)集。我們可以用StratifiedKFold這個類,手動循環(huán)每個折子,擬合模型,得到模型評估結(jié)果,然后整個流程結(jié)束后,得到模型評估的平均值。https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.StratifiedKFold.html
我們可以應(yīng)用這個框架得到一個可信賴的MLP模型的結(jié)果,對于不同的數(shù)據(jù)準備、模型架構(gòu)、學習配置,這個框架都適用。關(guān)鍵的是,在使用k-折交叉驗證前,我們先對模型在這個數(shù)據(jù)集上的學習機制有了了解。如果我們直接對模型調(diào)優(yōu) ,可能我們會一下子就得到好的結(jié)果,但如果沒有的話,我們可能不知道為什么,比如說為什么模型會過擬合或者欠擬合。如果我們又對模型進行了大的修改,有必要返回去確認模型是在適當收斂的。
運行示例,報告了評價過程的每次迭代模型性能,并報告了運行結(jié)束時分類準確度的均值和標準偏差。跟隨我的新書 Data Preparation for Machine Learning(https://machinelearningmastery.com/data-preparation-for-machine-learning/),開啟你的項目,其中包括所有示例的分步教程和Python源代碼文件。這個例子中,MLP模型的平均準確度是75.2%,和我們上一部分的模型結(jié)果接近。這證實了我們的期望,即對于這個數(shù)據(jù)集,基本模型配置可能比簡單的模型工作得更好。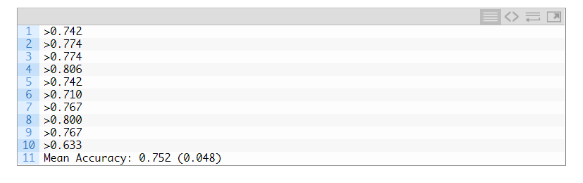
事實上,這是個具有挑戰(zhàn)的分類問題,74.5%的準確度結(jié)果已經(jīng)不錯了。接下來,讓我們看看我們?nèi)绾螖M合最終的模型并用它來預測當我們選擇了模型參數(shù),我們可以在所有數(shù)據(jù)上訓練一個最終的模型,并用模型對新數(shù)據(jù)進行預測。在本例中,我們將使用帶dropout的模型,和小批量訓練。數(shù)據(jù)準備和模型擬合按上文實現(xiàn),盡管是在整個數(shù)據(jù)集上,而不是在數(shù)據(jù)集的訓練子集上。
我們可以利用這個模型對新的數(shù)據(jù)進行預測。
備注:我是提取的數(shù)據(jù)集的第一行數(shù)據(jù),預期輸出結(jié)果是‘1’。

然后對預測結(jié)果進行轉(zhuǎn)置,得到正確形式下可解釋的結(jié)果(是一個整數(shù))。

把以上步驟整合起來,對haberman數(shù)據(jù)集上進行擬合最終模型,并對新數(shù)據(jù)進行預測的完整代碼示例如下所示。
執(zhí)行示例代碼在整個數(shù)據(jù)集上擬合模型,并對新數(shù)據(jù)進行預測。跟隨我的新書 Data Preparation for Machine Learning(https://machinelearningmastery.com/data-preparation-for-machine-learning/),開啟你的項目,其中包括所有示例的分步教程和Python源代碼文件。
如果你想在這個方向繼續(xù)探索,本節(jié)提供了更多學習資源
https://machinelearningmastery.com/how-to-develop-a-probabilistic-model-of-breast-cancer-patient-survival/
https://machinelearningmastery.com/predicting-disturbances-in-the-ionosphere/
https://machinelearningmastery.com/results-for-standard-classification-and-regression-machine-learning-datasets/
https://machinelearningmastery.com/tensorflow-tutorial-deep-learning-with-tf-keras/ https://machinelearningmastery.com/k-fold-cross-validation/在本教程中,您了解了如何應(yīng)用癌癥生存二分類數(shù)據(jù)集開發(fā)多層感知器神經(jīng)網(wǎng)絡(luò)模型。如何加載和匯總癌癥生存數(shù)據(jù)集,并使用結(jié)果來建議要使用的數(shù)據(jù)準備和模型配置。
如何在數(shù)據(jù)集上探索簡單MLP模型的學習動態(tài)。
如何開發(fā)模型性能的穩(wěn)健估計,調(diào)整模型性能并對新數(shù)據(jù)進行預測。
Develop a Neural Network for Cancer Survival Datasethttps://machinelearningmastery.com/neural-network-for-cancer-survival-dataset/工作內(nèi)容:需要一顆細致的心,將選取好的外文文章翻譯成流暢的中文。如果你是數(shù)據(jù)科學/統(tǒng)計學/計算機類的留學生,或在海外從事相關(guān)工作,或?qū)ψ约和庹Z水平有信心的朋友歡迎加入翻譯小組。
你能得到:定期的翻譯培訓提高志愿者的翻譯水平,提高對于數(shù)據(jù)科學前沿的認知,海外的朋友可以和國內(nèi)技術(shù)應(yīng)用發(fā)展保持聯(lián)系,THU數(shù)據(jù)派產(chǎn)學研的背景為志愿者帶來好的發(fā)展機遇。
其他福利:來自于名企的數(shù)據(jù)科學工作者,北大清華以及海外等名校學生他們都將成為你在翻譯小組的伙伴。
點擊文末“閱讀原文”加入數(shù)據(jù)派團隊~
轉(zhuǎn)載須知
如需轉(zhuǎn)載,請在開篇顯著位置注明作者和出處(轉(zhuǎn)自:數(shù)據(jù)派ID:DatapiTHU),并在文章結(jié)尾放置數(shù)據(jù)派醒目二維碼。有原創(chuàng)標識文章,請發(fā)送【文章名稱-待授權(quán)公眾號名稱及ID】至聯(lián)系郵箱,申請白名單授權(quán)并按要求編輯。
發(fā)布后請將鏈接反饋至聯(lián)系郵箱(見下方)。未經(jīng)許可的轉(zhuǎn)載以及改編者,我們將依法追究其法律責任。

