
(附代碼)CVPR 2021大獎(jiǎng)公布!何愷明獲最佳論文提名
點(diǎn)擊左上方藍(lán)字關(guān)注我們

推特上,有學(xué)者打趣說(shuō),CV論文可以分為這幾類:「只想混文憑」、「教電腦生成更多貓的照片」、「ImageNet上實(shí)驗(yàn)結(jié)果提升0.1%!」、「手握超酷數(shù)據(jù)集但并不打算公開」、「3年過去了,代碼仍在趕來(lái)的路上」、「實(shí)驗(yàn)證明還是老baseline性能更牛」、「我們的數(shù)據(jù)集更大!」、「研究范圍超廣,無(wú)他,我們有錢」、「花錢多,結(jié)果好」......
僅為調(diào)侃,請(qǐng)勿對(duì)號(hào)入座。

圖源:Jia-Bin Huang的推特
不過,言歸正傳,讓我們來(lái)看看今年被CVPR選中的都有哪些幸運(yùn)論文。
2021 CVPR 論文獎(jiǎng)
最佳論文獎(jiǎng)(Best Paper)
今年的最佳論文是馬克斯·普朗克智能系統(tǒng)研究所和蒂賓根大學(xué)團(tuán)隊(duì)的Michael Niemeyer, Andreas Geiger,他們的論文是
《GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields》(GIRAFFE:將場(chǎng)景表現(xiàn)為組合生成的神經(jīng)特征場(chǎng))

論文 https://m-niemeyer.github.io/project-pages/giraffe/index.html
源碼 https://github.com/autonomousvision/giraffe
論文簡(jiǎn)介:
深度生成模型可以在高分辨率下進(jìn)行逼真的圖像合成。但對(duì)于許多應(yīng)用來(lái)說(shuō),這還不夠:內(nèi)容創(chuàng)作還需要可控。雖然最近有幾項(xiàng)工作研究了如何分解數(shù)據(jù)中的潛在變化因素,但它們大多在二維中操作,忽略了我們的世界是三維的。此外,只有少數(shù)作品考慮到了場(chǎng)景的組成性質(zhì)。我們的關(guān)鍵假設(shè)是,將組合式三維場(chǎng)景表示納入生成模型,可以使圖像合成更加可控。將場(chǎng)景表示為生成性神經(jīng)特征場(chǎng),使我們能夠從背景中分離出一個(gè)或多個(gè)物體,以及單個(gè)物體的形狀和外觀,同時(shí)無(wú)需任何額外的監(jiān)督就能從非結(jié)構(gòu)化和unposed的圖像集中學(xué)習(xí)。將這種場(chǎng)景表示與神經(jīng)渲染管道結(jié)合起來(lái),可以產(chǎn)生一個(gè)快速而真實(shí)的圖像合成模型。正如我們的實(shí)驗(yàn)所證明的那樣,我們的模型能夠分解單個(gè)物體,并允許在場(chǎng)景中平移和旋轉(zhuǎn)它們,還可以改變攝像機(jī)的姿勢(shì)。
最佳論文榮譽(yù)提名(Best Paper Honorable Mentions)
何愷明和Xinlei Chen的論文《Exploring Simple Siamese Representation Learning》(探索簡(jiǎn)單的連體表征學(xué)習(xí))獲得了最佳論文提名。


https://arxiv.org/abs/2011.10566
論文主要研究了:
「連體網(wǎng)絡(luò)」(Siamese networks)已經(jīng)成為最近各種無(wú)監(jiān)督視覺表征學(xué)習(xí)模型中的一種常見結(jié)構(gòu)。這些模型最大限度地提高了一個(gè)圖像的兩個(gè)增量之間的相似性,但必須符合某些條件以避免collapse的解決方案。在本文中,我們報(bào)告了令人驚訝的經(jīng)驗(yàn)結(jié)果,即簡(jiǎn)單的連體網(wǎng)絡(luò)即使不使用以下任何一種情況也能學(xué)習(xí)有意義的表征。(i) 負(fù)樣本對(duì),(ii) 大batch,(iii) 動(dòng)量編碼器。我們的實(shí)驗(yàn)表明,對(duì)于損失和結(jié)構(gòu)來(lái)說(shuō),collapse的解決方案確實(shí)存在,但stop-gradient操作在防止collapse方面發(fā)揮了重要作用。我們提供了一個(gè)關(guān)于stop-gradient含義的假設(shè),并進(jìn)一步展示了驗(yàn)證該假設(shè)的概念驗(yàn)證實(shí)驗(yàn)。我們的 「SimSiam 」方法在ImageNet和下游任務(wù)中取得了有競(jìng)爭(zhēng)力的結(jié)果。我們希望這個(gè)簡(jiǎn)單的基線能促使人們重新思考連體結(jié)構(gòu)在無(wú)監(jiān)督表征學(xué)習(xí)中的作用。
代碼已開源 https://github.com/facebookresearch/simsiam

另一篇最佳論文提名是明尼蘇達(dá)大學(xué)團(tuán)隊(duì)Yasamin Jafarian, Hyun Soo Park的
《Learning High Fidelity Depths of Dressed Humans by Watching Social Media Dance Videos》

學(xué)習(xí)穿戴人體幾何的一個(gè)關(guān)鍵挑戰(zhàn)在 ground truth 實(shí)數(shù)據(jù)(如三維掃描模型)的有限可用性,這導(dǎo)致三維人體重建在應(yīng)用于真實(shí)圖像時(shí)性的能下降本文們通過利用一個(gè)新的數(shù)據(jù)資源來(lái)應(yīng)對(duì)這一挑戰(zhàn):大量社交媒跳舞蹈視——,涵蓋了不同的外觀、服裝風(fēng)格、表演和身份。每一個(gè)視頻都描述了一個(gè)人的身體和衣服的動(dòng)態(tài)運(yùn)動(dòng),但缺乏3 ground truth實(shí)幾何圖形.
為了很好地利用這些視頻,本文提出了一種新的方法來(lái)使用局部變換,即將預(yù)測(cè)的局部幾何體從一幅圖像在不同的時(shí)刻扭曲到另一幅圖像。這使得自監(jiān)督學(xué)習(xí)對(duì)預(yù)測(cè)實(shí)施時(shí)間一致性。此外,我們還通過最大化局部紋理、褶皺和陰影的幾何一致性,共同學(xué)習(xí)深度以及對(duì)局部紋理、褶皺和陰影高度敏感的曲面法線。
另外本文的方法是端到端可訓(xùn)練的,能產(chǎn)生高保真深度估計(jì)來(lái)預(yù)測(cè)接近于輸入的真實(shí)圖像的精確幾何。本文證明了我們提出的方法在真實(shí)圖像和渲染圖像上都優(yōu)于 SOTA 人體深度估計(jì)和人體形狀恢復(fù)方法。
最佳學(xué)生論文獎(jiǎng)(Best Student Paper)

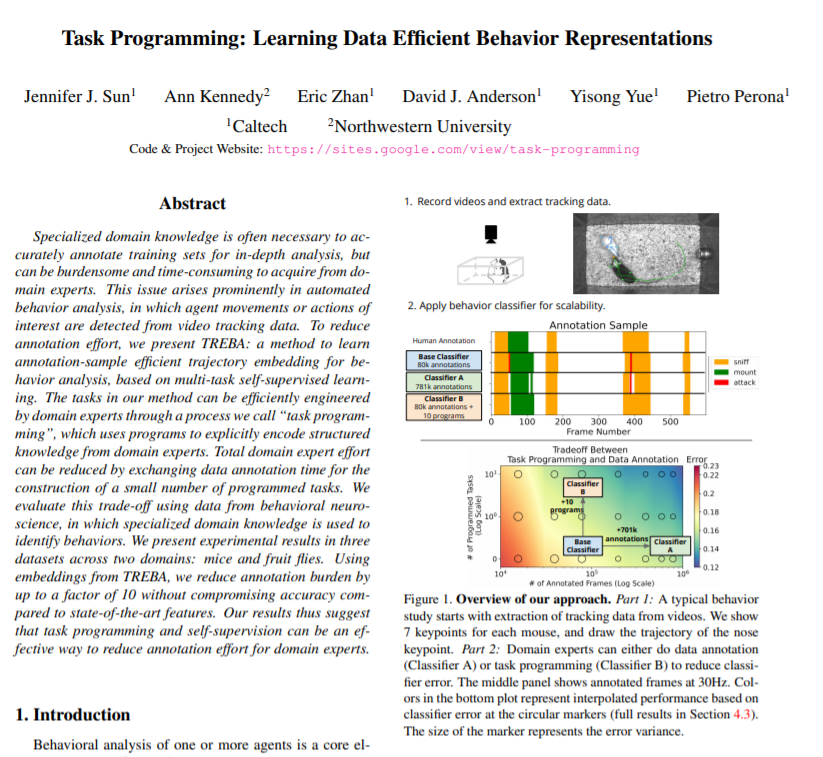
https://openaccess.thecvf.com/content/CVPR2021/html/Sun_Task_Programming_Learning_Data_Efficient_Behavior_Representations_CVPR_2021_paper.html
為了更準(zhǔn)確的標(biāo)注數(shù)據(jù)集,具備該領(lǐng)域的專業(yè)知識(shí)是必要的,但這可能意味專家們將承擔(dān)大量繁重和耗時(shí)的工作。這個(gè)問題在自動(dòng)行為分析(automated behavior analysis)中尤為突顯。例如,從視頻跟蹤數(shù)據(jù)中檢測(cè)智能體運(yùn)動(dòng)或動(dòng)作。
為了減少注釋的工作量,我們基于多任務(wù)自監(jiān)督學(xué)習(xí),提出了一種用于行為分析的有效軌跡嵌入方法—TREBA。利用該方法專家們可以通過“任務(wù)編程”過程來(lái)有效地設(shè)計(jì)任務(wù),即使用程序編碼將領(lǐng)域?qū)<业闹R(shí)結(jié)構(gòu)化。通過交換數(shù)據(jù)注釋時(shí)間來(lái)構(gòu)造少量編程任務(wù),可以減少領(lǐng)域?qū)<业墓ぷ髁俊N覀兪褂眯袨樯窠?jīng)科學(xué)領(lǐng)域的數(shù)據(jù)集評(píng)估了該方法,通過小鼠和果蠅兩個(gè)領(lǐng)域內(nèi)三個(gè)數(shù)據(jù)集的測(cè)試,實(shí)驗(yàn)結(jié)果表明:通過使用TREBA的嵌入,注釋負(fù)擔(dān)減少了10倍。該研究結(jié)果表明,任務(wù)規(guī)劃和自監(jiān)督是減少領(lǐng)域?qū)<易⑨尮ぷ髁康挠行Х椒ā?/span>
最佳學(xué)生論文榮譽(yù)提名(Best Student Paper Honorable Mentions)
獲得「最佳學(xué)生論文」提名的有三篇

1.《Less is More: ClipBERT for Video-and-Language Learning via Sparse Sampling》(少即是多:通過稀疏取樣進(jìn)行視頻和語(yǔ)言學(xué)習(xí)的ClipBERT)
作者團(tuán)隊(duì)來(lái)自北卡羅來(lái)納大學(xué)教堂山分校和Microsoft Dynamics 365 AI Research的Jie Lei, Linjie Li, Luowei Zhou, Zhe Gan, Tamara L. Berg, Mohit Bansal, Jingjing Liu

https://openaccess.thecvf.com/content/CVPR2021/html/Lei_Less_Is_More_ClipBERT_for_Video-and-Language_Learning_via_Sparse_Sampling_CVPR_2021_paper.html

2. 《Binary TTC: A Temporal Geofence for Autonomous Navigation》(二進(jìn)制TTC:用于自主導(dǎo)航的時(shí)間地理圍欄)
作者團(tuán)隊(duì)來(lái)自英偉達(dá)和加州大學(xué)圣巴巴拉分校的Abhishek Badki, Orazio Gallo, Jan Kautz, Pradeep Sen

https://openaccess.thecvf.com/content/CVPR2021/html/Badki_Binary_TTC_A_Temporal_Geofence_for_Autonomous_Navigation_CVPR_2021_paper.html
3. 《Real-Time High-Resolution Background Matting》(實(shí)時(shí)高分辨率的背景消隱)
作者團(tuán)隊(duì)來(lái)自華盛頓大學(xué)的Shanchuan Lin, Andrey Ryabtsev, Soumyadip Sengupta, Brian Curless, Steve Seitz, Ira Kemelmacher-Shlizerman

https://openaccess.thecvf.com/content/CVPR2021/papers/Lin_Real-Time_High-Resolution_Background_Matting_CVPR_2021_paper.pdf
最佳論文評(píng)選委員會(huì)
以上最佳(學(xué)生)論文及提名由以下委員會(huì)評(píng)選:Deva Ramanan (主席),Lourdes Agapito, Zeynep Akata, Karteek Alahari, Xilin Chen, Emily Denton, Piotr Dollar, Ivan Laptev, Kyoung Mu Lee
其中,中科院計(jì)算所視覺信息處理與學(xué)習(xí)組的陳熙霖博士是委員會(huì)成員。

陳熙霖博士,研究員,ACM Fellow, IEEE Fellow, IAPR Fellow, 中國(guó)計(jì)算機(jī)學(xué)會(huì)會(huì)士,國(guó)家杰出青年基金獲得者。主要研究領(lǐng)域?yàn)橛?jì)算機(jī)視覺、模式識(shí)別、多媒體技術(shù)以及多模式人機(jī)接口。先后主持多項(xiàng)自然科學(xué)基金重大、重點(diǎn)項(xiàng)目、973計(jì)劃課題等項(xiàng)目的研究。
曾任IEEE Trans. on Image Processing和IEEE Trans. on Multimedia的Associate Editor,目前是Journal of Visual Communication and Image Representation的Associate Editor、計(jì)算機(jī)學(xué)報(bào)副主編、人工智能與模式識(shí)別副主編,擔(dān)任過FG2013 / FG 2018 General Chair以及CVPR 2017 / 2019 / 2020, ICCV 2019等的Area Chair。
陳熙霖博士先后獲得國(guó)家自然科學(xué)二等獎(jiǎng)1項(xiàng),國(guó)家科技進(jìn)步二等獎(jiǎng)4項(xiàng),省部級(jí)科技進(jìn)步獎(jiǎng)九項(xiàng)。合作出版專著1本,在國(guó)內(nèi)外重要刊物和會(huì)議上發(fā)表論文200多篇。
PAMITC 獎(jiǎng)(PAMITC AWARDS)
Longuet-Higgins 獎(jiǎng)是 IEEE 計(jì)算機(jī)協(xié)會(huì)模式分析與機(jī)器智能(PAMI)技術(shù)委員會(huì)在每年的 CVPR 頒發(fā)的計(jì)算機(jī)視覺基礎(chǔ)貢獻(xiàn)獎(jiǎng),表彰十年前對(duì)計(jì)算機(jī)視覺研究產(chǎn)生了重大影響的 CVPR 論文。該獎(jiǎng)項(xiàng)以理論化學(xué)家和認(rèn)知科學(xué)家 H. Christopher Longuet-Higgins 命名。
第一篇論文獲獎(jiǎng)?wù)撐氖?strong>“Real-Time Human Pose Recognition in Parts from Single Depth Images”,發(fā)表于CVPR 2011,目前引用數(shù)4108,來(lái)自微軟。

這篇論文提出了一種新方法,可以在不使用時(shí)間信息的情況下,從單張深度圖像中快速準(zhǔn)確地預(yù)測(cè)身體關(guān)節(jié)的 3D 位置。
研究人員采用目標(biāo)識(shí)別方法,設(shè)計(jì)一個(gè)中間的身體部位表示步驟,將困難的姿勢(shì)估計(jì)問題映射到更簡(jiǎn)單的每像素分類問題。龐大且高度多樣化的訓(xùn)練數(shù)據(jù)集允許分類器估計(jì)對(duì)姿勢(shì)、體型、服裝等保持不變的身體部位。最后,研究人員通過重新投影分類結(jié)果并找到局部模式來(lái)生成幾個(gè)身體關(guān)節(jié)的置信度評(píng)分 3D 建議。該系統(tǒng)在消費(fèi)級(jí)硬件上以每秒 200 幀的速度運(yùn)行。
這項(xiàng)工作在當(dāng)時(shí)的相關(guān)研究中實(shí)現(xiàn)了最先進(jìn)的準(zhǔn)確率,并展示了對(duì)精確整個(gè)骨架最近鄰匹配的改進(jìn)泛化。
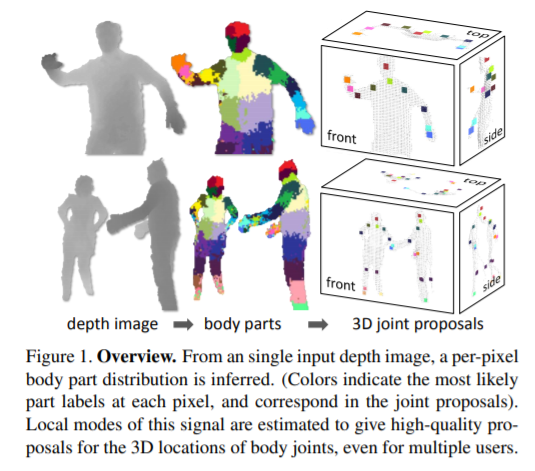
論文鏈接:https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/BodyPartRecognition.pdf
第二篇獲獎(jiǎng)?wù)撐氖?strong>“Baby Talk: Understanding and Generating Simple Image Descriptions“,發(fā)表于CVPR 2011,目前引用數(shù)1159,來(lái)自石溪大學(xué)。

這篇論文假設(shè)視覺描述語(yǔ)言為計(jì)算機(jī)視覺研究人員提供了關(guān)于世界的信息,以及關(guān)于人們?nèi)绾蚊枋鍪澜绲男畔ⅰ?/span>
基于大量語(yǔ)言數(shù)據(jù),研究人員提出了一個(gè)從圖像自動(dòng)生成自然語(yǔ)言描述的系統(tǒng),該系統(tǒng)利用從解析大量文本數(shù)據(jù)和計(jì)算機(jī)視覺識(shí)別算法中收集的統(tǒng)計(jì)數(shù)據(jù)。該系統(tǒng)在為圖像生成相關(guān)句子方面非常有效,是早期圖像到文本生成的重要工作。

論文鏈接:http://acberg.com/papers/baby_talk.pdf
去年,為了緬懷了一代 CV 宗師、84 歲華人計(jì)算機(jī)視覺泰斗 Thomas S. Huang(黃煦濤),CVPR大會(huì)成立了 Thomas S. Huang 紀(jì)念獎(jiǎng),該獎(jiǎng)項(xiàng)的獲獎(jiǎng)?wù)邔⒂?PAMITC 獎(jiǎng)勵(lì)委員會(huì)選出,類似于羅森菲爾德獎(jiǎng)獲獎(jiǎng)?wù)邔⒉⒌玫较嗤莫?jiǎng)金。
黃煦濤先生在華人計(jì)算機(jī)界被譽(yù)為「計(jì)算機(jī)視覺之父」,他在圖像處理、模式識(shí)別等計(jì)算機(jī)視覺領(lǐng)域作出了開創(chuàng)性貢獻(xiàn),為中國(guó)培養(yǎng)了許多杰出人才,是華人計(jì)算機(jī)視覺領(lǐng)域的一座燈塔。此外,他也是首位擔(dān)任CVPR程序主席(1992)的華人。

今年也就是第一屆Thomas S. Huang 紀(jì)念獎(jiǎng)的獲獎(jiǎng)?wù)撸荕IT電子電氣工程與計(jì)算機(jī)科學(xué)教授Antonio Torralba。
Antonio Torralba的研究領(lǐng)域包括場(chǎng)景理解和上下文驅(qū)動(dòng)的目標(biāo)識(shí)別、多感官知覺整合、數(shù)據(jù)集構(gòu)建以及神經(jīng)網(wǎng)絡(luò)表征的可視化和解釋。他目前的論文引用數(shù)為78736,h指數(shù)為111。
個(gè)人主頁(yè):https://groups.csail.mit.edu/vision/torralbalab/

青年研究者獎(jiǎng)(Young Researcher Awards)
青年研究者獎(jiǎng)的目的在于表彰年輕的科學(xué)家,鼓勵(lì)繼續(xù)做出開創(chuàng)性的工作。另外,此獎(jiǎng)項(xiàng)的評(píng)選標(biāo)準(zhǔn)是研究者必須獲得博士學(xué)位的年限少于7年。
今年獲獎(jiǎng)的兩位學(xué)者分別是來(lái)自FAIR和MIT的科學(xué)家。


Georgia Gkioxari是 FAIR 研究科學(xué)家。她在加州大學(xué)伯克利分校獲得博士學(xué)位,導(dǎo)師是 Jitendra Malik 。她是PyTorch3D的開發(fā)者之一,主要研究領(lǐng)域是計(jì)算機(jī)視覺,并且是Mask R-CNN的作者之一(與何愷明合作),目前引用數(shù)為16000。

個(gè)人主頁(yè):https://gkioxari.github.io/
Phillip Isola是麻省理工學(xué)院 EECS 的助理教授,主要研究計(jì)算機(jī)視覺、機(jī)器學(xué)習(xí)和人工智能。
他曾在 OpenAI 做了一年的訪問研究科學(xué)家,在此之前,他是加州大學(xué)伯克利分校 EECS 系的 Alyosha Efros 的博士后學(xué)者。他在 MIT 的大腦與認(rèn)知科學(xué)專業(yè)完成了博士學(xué)位,導(dǎo)師是Ted Adelson 。他目前論文引用數(shù)為28056,其中引用最高的論文為“Image-to-image translation with conditional adversarial networks”(與朱俊彥合作),這篇論文研究了條件形式的圖像到圖像轉(zhuǎn)換,可以說(shuō)是CycleGAN的前階段工作。

個(gè)人主頁(yè):http://web.mit.edu/phillipi/
該年度獎(jiǎng)項(xiàng)旨在表彰對(duì)計(jì)算機(jī)視覺做出杰出研究貢獻(xiàn)的年輕研究人員。
本屆委員會(huì):R. Zabih (主席), S. Lazebnik, G. Medioni, N. Paragios, S. Seitz
END
整理不易,點(diǎn)贊三連↓