
來源:DeepBlueAI
編輯:白峰
【新智元導(dǎo)讀】近日,全球計(jì)算機(jī)視覺頂會(huì)ECCV2020落下帷幕,各個(gè)workshop也公布了各項(xiàng)挑戰(zhàn)賽的結(jié)果,來自中國的DeepBlueAI 團(tuán)隊(duì)斬獲了第一屆GigaVision挑戰(zhàn)賽兩個(gè)賽道的冠軍。
來自中國的 DeepBlueAI 團(tuán)隊(duì)斬獲了「行人和車輛檢測」和「多目標(biāo)追蹤」兩個(gè)賽道的冠軍。
以人為中心的各項(xiàng)計(jì)算機(jī)視覺分析任務(wù),例如行人檢測,跟蹤,動(dòng)作識(shí)別,異常檢測,屬性識(shí)別等,在過去的十年中引起了人們的極大興趣。為了對大規(guī)模時(shí)空范圍內(nèi)具有高清細(xì)節(jié)的人群活動(dòng)進(jìn)行跨越長時(shí)間、長距離分析,清華大學(xué)智能成像實(shí)驗(yàn)室推出一個(gè)新的十億像素視頻數(shù)據(jù)集:PANDA。該數(shù)據(jù)集是在多種自然場景中收集,旨在為社區(qū)貢獻(xiàn)一個(gè)標(biāo)準(zhǔn)化的評測基準(zhǔn),以研究新的算法來理解大規(guī)模現(xiàn)實(shí)世界場景中復(fù)雜的人群活動(dòng)及社交行為。圍繞PANDA數(shù)據(jù)集,主辦方組織了GigaVision 2020挑戰(zhàn)賽。
本次的挑戰(zhàn)賽同時(shí)是ECCV2020的Workshop:「GigaVision: When Gigapixel Videography Meets Computer Vision」。挑戰(zhàn)賽的任務(wù)是在由十億像素相機(jī)收集的大范圍自然場景視覺數(shù)據(jù)集PANDA上進(jìn)行圖像目標(biāo)檢測和視頻多目標(biāo)跟蹤。
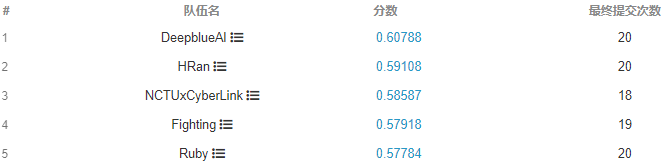
Sub-Track 1 : Pedestrian & Vehicle Detection這項(xiàng)任務(wù)是為了推動(dòng)在十億像素圖像上的目標(biāo)檢測技術(shù)的發(fā)展。挑戰(zhàn)的參與者需要檢測兩類目標(biāo):行人和車輛。對于每個(gè)行人,需要提交三類檢測框:可見身體范圍框、全身范圍框、行人頭部范圍框。對于每個(gè)車輛,需要提交可見范圍框。一些特殊的區(qū)域(如假人、極度擁擠的人群、車群、被嚴(yán)重遮擋的人等)將在評估中被忽略。Sub-Track 2 : Multi-Pedestrian Tracking這項(xiàng)任務(wù)是為了推動(dòng)在十億像素視頻上的多目標(biāo)追蹤技術(shù)的發(fā)展。PANDA寬視場、多目標(biāo)、高分辨的優(yōu)越性能使特別適合于多目標(biāo)長時(shí)間追蹤任務(wù)。然而,巨大的同類目標(biāo)尺度變化和擁有豐富行人擁擠、遮擋的復(fù)雜場景也帶來了各種挑戰(zhàn)。在給定輸入視頻序列的情況下,該任務(wù)需要參與者提交行人在視頻中的軌跡。對于賽道一,類似于MS COCO數(shù)據(jù)集的評估方案,主辦方采用AP、APIOU=0.50、APIOU=0.75、ARmax=10、ARmax=100、ARmax=500五個(gè)指標(biāo)來評估檢測算法的結(jié)果。最終的排名依據(jù)于 AP 和 ARmax=500?兩項(xiàng)指標(biāo)的調(diào)和平均數(shù),高者為優(yōu)。?? ? ?? ? ? ? ?對于賽道二,與MOTChallenge[2]中使用的評測方法類似,主辦方采用了包括MOTA、MOTP、IDF1、FAR、MT和Hz等指標(biāo)來評估多目標(biāo)追蹤算法的結(jié)果。最終的排名依據(jù)于 MOTA 和 MOTP 兩項(xiàng)指標(biāo)的調(diào)和平均數(shù),高者為優(yōu)。
? ? ? ?對于賽道二,與MOTChallenge[2]中使用的評測方法類似,主辦方采用了包括MOTA、MOTP、IDF1、FAR、MT和Hz等指標(biāo)來評估多目標(biāo)追蹤算法的結(jié)果。最終的排名依據(jù)于 MOTA 和 MOTP 兩項(xiàng)指標(biāo)的調(diào)和平均數(shù),高者為優(yōu)。DeepBlueAI團(tuán)隊(duì)榮獲兩項(xiàng)第一
? ? ? ? ? ? ?
? ? ? ?
? ? ?
? ? ? ? ? ? ?圖像分辨率極高、近景和遠(yuǎn)景目標(biāo)尺度差異大十億像素級的超高分辨率是整個(gè)數(shù)據(jù)集的核心問題。一方面,由于計(jì)算資源的限制,超高分辨率使得網(wǎng)絡(luò)無法接受大圖作為輸入,而單純將原圖縮放到小圖會(huì)使得目標(biāo)丟失大量信息。另一方面,圖像中近景和遠(yuǎn)景的目標(biāo)尺度差異大,給檢測器帶來了巨大的挑戰(zhàn)。目標(biāo)在圖像中分布密集,并且遮擋嚴(yán)重數(shù)據(jù)集均從廣場、學(xué)校、商圈等真實(shí)場景采集,其人流和車輛密度極大。同時(shí),行人和車輛的擁擠、遮擋等情況頻發(fā),容易造成目標(biāo)的漏檢和誤檢。
? ? ?圖像分辨率極高、近景和遠(yuǎn)景目標(biāo)尺度差異大十億像素級的超高分辨率是整個(gè)數(shù)據(jù)集的核心問題。一方面,由于計(jì)算資源的限制,超高分辨率使得網(wǎng)絡(luò)無法接受大圖作為輸入,而單純將原圖縮放到小圖會(huì)使得目標(biāo)丟失大量信息。另一方面,圖像中近景和遠(yuǎn)景的目標(biāo)尺度差異大,給檢測器帶來了巨大的挑戰(zhàn)。目標(biāo)在圖像中分布密集,并且遮擋嚴(yán)重數(shù)據(jù)集均從廣場、學(xué)校、商圈等真實(shí)場景采集,其人流和車輛密度極大。同時(shí),行人和車輛的擁擠、遮擋等情況頻發(fā),容易造成目標(biāo)的漏檢和誤檢。賽道一 Pedestrian & Vehicle Detection
根據(jù)以往積累的經(jīng)驗(yàn),團(tuán)隊(duì)首先將原圖縮放到合適尺度,并使用基于Cascade RCNN的檢測器直接檢測行人的三個(gè)類別和車輛,將其作為Baseline: Backbone + DCN + FPN + Cascade RCNN,并在此基礎(chǔ)上進(jìn)行改進(jìn)。
? ? ? ? ? ? ?實(shí)驗(yàn)結(jié)果顯示,模型存在大量的誤檢和漏檢。這些漏檢和無意義的檢測結(jié)果大幅降低了模型的性能。團(tuán)隊(duì)將上述問題歸納為兩方面的原因:
? ? ?實(shí)驗(yàn)結(jié)果顯示,模型存在大量的誤檢和漏檢。這些漏檢和無意義的檢測結(jié)果大幅降低了模型的性能。團(tuán)隊(duì)將上述問題歸納為兩方面的原因:- 訓(xùn)練和測試時(shí)輸入模型的圖像尺度不合適。圖像經(jīng)過縮放后,目標(biāo)的尺度也隨之變小,導(dǎo)致遠(yuǎn)景中人的頭部等區(qū)域被大量遺漏。
- 網(wǎng)絡(luò)本身的分類能力較弱。行人的可見區(qū)域和全身區(qū)域十分相似,容易對分類器造成混淆,從而產(chǎn)生誤檢。
根據(jù)上述問題,團(tuán)隊(duì)進(jìn)行了一些改進(jìn)。首先,使用滑動(dòng)窗口的方式切圖進(jìn)行訓(xùn)練。滑動(dòng)窗口切圖是一種常用的大圖像處理方式,這樣可以有效的保留圖像的高分辨率信息,使得網(wǎng)絡(luò)獲得的信息更加豐富。如果某個(gè)目標(biāo)處于切圖邊界,根據(jù)其IOF大于0.5來決定是否保留。其次,對于每個(gè)類別采用一個(gè)單獨(dú)的檢測器進(jìn)行檢測。經(jīng)過實(shí)驗(yàn)對比,對每個(gè)類別采用單獨(dú)的檢測器可以有效的提高網(wǎng)絡(luò)的效果,尤其是對于可見區(qū)域和全身區(qū)域兩類。同時(shí)向檢測器添加了Global Context (GC) block來進(jìn)一步提高特征提取能力。GC-Block結(jié)合了Non-local的上下文建模能力,并繼承了SE-Net節(jié)省計(jì)算量的優(yōu)點(diǎn),可以有效的對目標(biāo)的上下文進(jìn)行建模。
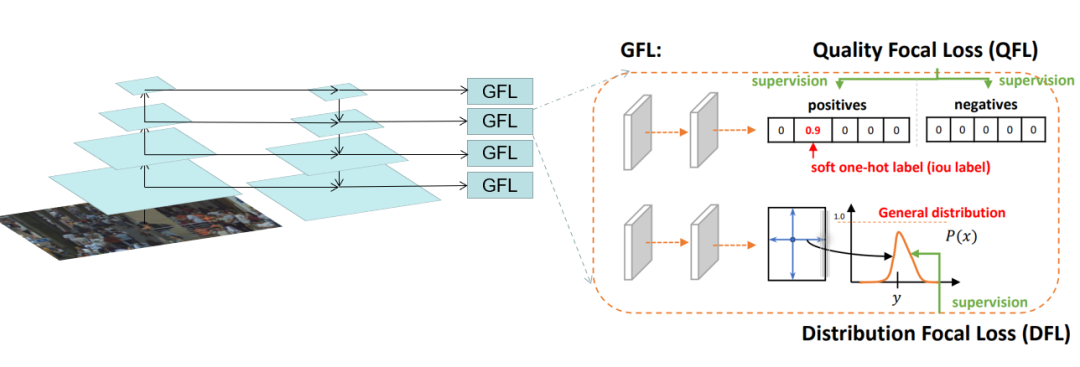
? ? ? ? ? ? ?除Cascade RCNN外,還采用了Generalize Focal Loss (GFL)檢測器進(jìn)行結(jié)果互補(bǔ)。GFL提出了一種泛化的Focal Loss損失,解決了分類得分和質(zhì)量預(yù)測得分在訓(xùn)練和測試時(shí)的不一致問題。?? ? ? ?
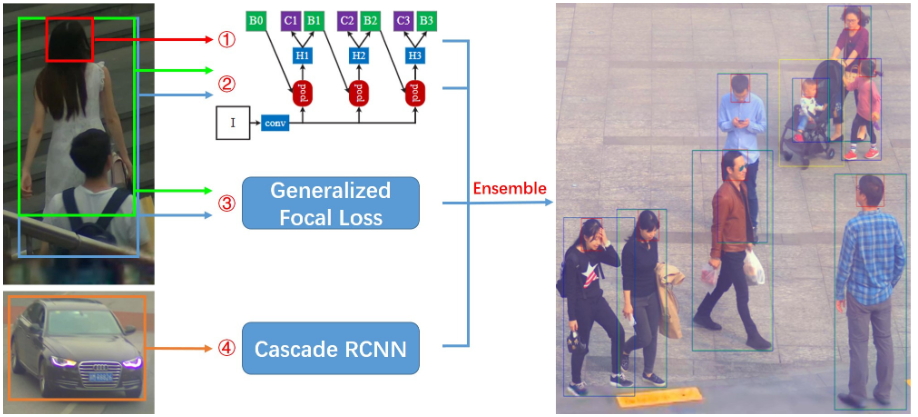
? ? ?除Cascade RCNN外,還采用了Generalize Focal Loss (GFL)檢測器進(jìn)行結(jié)果互補(bǔ)。GFL提出了一種泛化的Focal Loss損失,解決了分類得分和質(zhì)量預(yù)測得分在訓(xùn)練和測試時(shí)的不一致問題。?? ? ? ?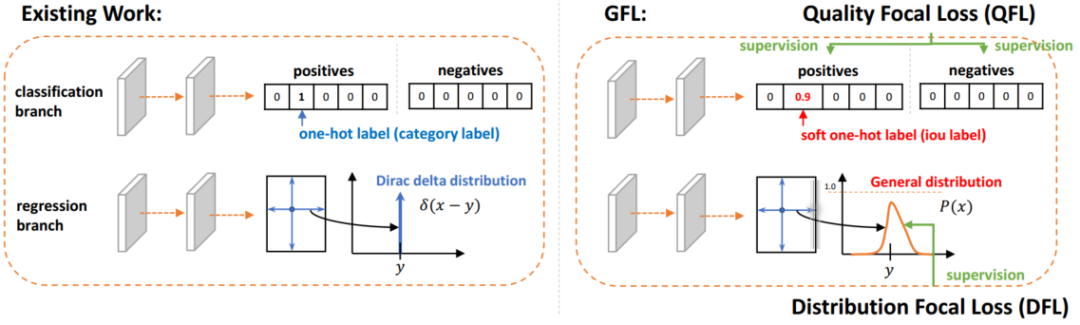 最后,將各檢測器的結(jié)果使用Weighted Box Fusion (WBF)進(jìn)行融合,形成了最終的解決方案。傳統(tǒng)的NMS和Soft-NMS方法會(huì)移除預(yù)測結(jié)果中的一部分預(yù)測框,而WBF使用全部的預(yù)測框,通過進(jìn)行組合來獲得更加準(zhǔn)確的預(yù)測框,從而實(shí)現(xiàn)精度提升。整體pipeline如下圖所示:
? ? ? ?
最后,將各檢測器的結(jié)果使用Weighted Box Fusion (WBF)進(jìn)行融合,形成了最終的解決方案。傳統(tǒng)的NMS和Soft-NMS方法會(huì)移除預(yù)測結(jié)果中的一部分預(yù)測框,而WBF使用全部的預(yù)測框,通過進(jìn)行組合來獲得更加準(zhǔn)確的預(yù)測框,從而實(shí)現(xiàn)精度提升。整體pipeline如下圖所示:
? ? ? ? ? ? ?
? ? ?
? ? ? ? ? ? ?
? ? ?
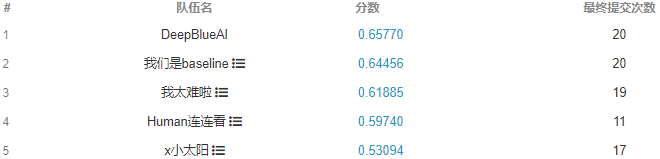
賽道二 ?Multi-Pedestrian Tracking
多行人跟蹤問題是一個(gè)典型的多目標(biāo)跟蹤問題。通過調(diào)研總結(jié)發(fā)現(xiàn),Tracking-by-detection是處理這一問題的常用且精度比較高的方法[2][7]。基本的流程可以總結(jié)如下:3) 通過將特征距離或空間距離將預(yù)測的目標(biāo)與現(xiàn)有軌跡關(guān)聯(lián)。本次挑戰(zhàn)賽更注重精度,因此采用了分離Detection和Embedding的方法,該方法的模塊化設(shè)計(jì)的優(yōu)點(diǎn)使得競賽精度上優(yōu)化空間的十分大。通過簡單的數(shù)據(jù)統(tǒng)計(jì)分析和可視化分析,團(tuán)隊(duì)認(rèn)為該比賽的主要挑戰(zhàn)在于圖像的大分辨率和行人的嚴(yán)重?fù)頂D,如下圖所示。
? ? ? ? ? ? ?
? ? ? ?
? ? ?
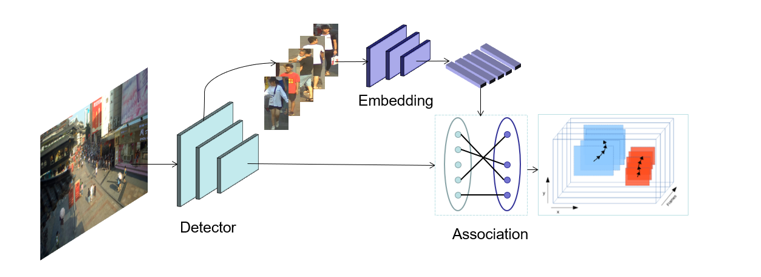
? ? ? ? ? ? ?為了應(yīng)對這些挑戰(zhàn),針對高分辨、小目標(biāo)等問題,引入了一種滑動(dòng)窗口檢測算法。針對遮擋嚴(yán)重的問題,使用局部和全局特征來衡量兩個(gè)相鄰幀之間的預(yù)測邊界框的相似距離,并且借鑒了FairMOT的特征平滑的方法進(jìn)行緩解。本次采用的多目標(biāo)跟蹤系統(tǒng)是基于Detection和Embedding分離的方法,采用了以Generalized Focal Loss(GFL)[9]為損失的anchor-free檢測器,并以Multiple Granularity Network (MGN)[10]作為Embedding模型。在關(guān)聯(lián)過程中,借鑒了DeepSORT[6]和FairMOT[8]的思想,構(gòu)建了一個(gè)簡單的在線多目標(biāo)跟蹤器, 如下圖所示。
? ? ? ?
? ? ?為了應(yīng)對這些挑戰(zhàn),針對高分辨、小目標(biāo)等問題,引入了一種滑動(dòng)窗口檢測算法。針對遮擋嚴(yán)重的問題,使用局部和全局特征來衡量兩個(gè)相鄰幀之間的預(yù)測邊界框的相似距離,并且借鑒了FairMOT的特征平滑的方法進(jìn)行緩解。本次采用的多目標(biāo)跟蹤系統(tǒng)是基于Detection和Embedding分離的方法,采用了以Generalized Focal Loss(GFL)[9]為損失的anchor-free檢測器,并以Multiple Granularity Network (MGN)[10]作為Embedding模型。在關(guān)聯(lián)過程中,借鑒了DeepSORT[6]和FairMOT[8]的思想,構(gòu)建了一個(gè)簡單的在線多目標(biāo)跟蹤器, 如下圖所示。
? ? ? ? ? ? ?
? ? ? ?
? ? ?
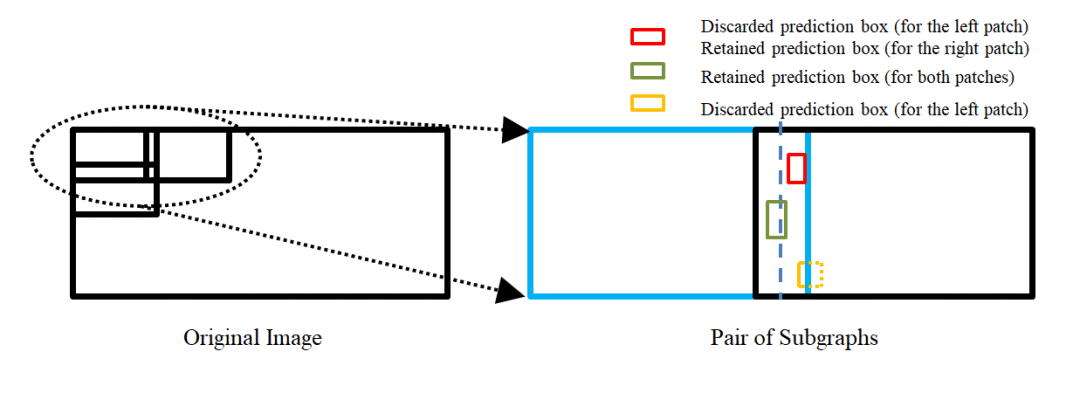
? ? ? ? ? ? ?為了處理高分辨率的圖像,我們提出了一個(gè)segmentation-and-fusion(SF)的方法,如下圖所示。每一張大圖有交疊的切分成多個(gè)子圖,每一個(gè)子圖的分辨率為6000*6000,位于圖像邊緣的子圖直接填充均值。為了防止較大的行人目標(biāo)被切分成進(jìn)兩個(gè)子圖,相鄰的子圖橫向上重疊寬度為1000像素,縱向重疊寬度設(shè)置為2000像素。在融合子圖檢測結(jié)果時(shí),我們采用一種基于子圖重疊中線和檢測框相交判定的規(guī)則。比如,對于一對橫向有重疊的子圖,如果基于左子圖的檢測框處于子圖重疊中線的右側(cè),但與該中線相交,該檢測框就被保留,反之則丟棄該檢測框。通過segmentation-and-fusion方法,與直接合并進(jìn)行NMS的方法相比, 我們在本地檢測驗(yàn)證集取得了0.2AP的提升。
? ? ? ?
? ? ?為了處理高分辨率的圖像,我們提出了一個(gè)segmentation-and-fusion(SF)的方法,如下圖所示。每一張大圖有交疊的切分成多個(gè)子圖,每一個(gè)子圖的分辨率為6000*6000,位于圖像邊緣的子圖直接填充均值。為了防止較大的行人目標(biāo)被切分成進(jìn)兩個(gè)子圖,相鄰的子圖橫向上重疊寬度為1000像素,縱向重疊寬度設(shè)置為2000像素。在融合子圖檢測結(jié)果時(shí),我們采用一種基于子圖重疊中線和檢測框相交判定的規(guī)則。比如,對于一對橫向有重疊的子圖,如果基于左子圖的檢測框處于子圖重疊中線的右側(cè),但與該中線相交,該檢測框就被保留,反之則丟棄該檢測框。通過segmentation-and-fusion方法,與直接合并進(jìn)行NMS的方法相比, 我們在本地檢測驗(yàn)證集取得了0.2AP的提升。
? ? ? ? ? ? ?
? ? ? ?
? ? ?
? ? ? ? ? ? ?
? ? ? ?
? ? ?
? ? ? ?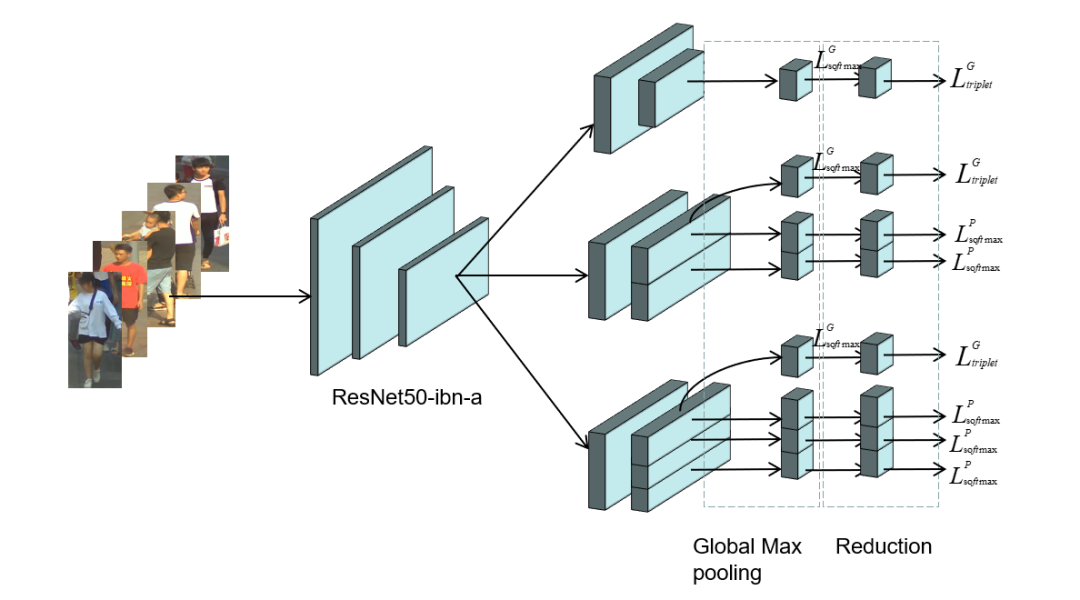 ? ? ?為了解決行人擁擠帶來的問題,我們采用了Multiple Granularity Network(MGN),如上圖所示。我們首先利用Resnet50-ibn-a[4]提取特征,然后使用Triplet loss和Softmax loss計(jì)算三個(gè)全局特征的損失,僅使用Softmax loss計(jì)算局部特征的損失。此外,我們使用了ReID中的常用的訓(xùn)練技巧來優(yōu)化MGN的性能[3]。我們借鑒了DeepSORT和FairMOT的想法,以檢測框的表觀距離為主,以檢測框的空間距離為輔。首先,我們根據(jù)第一幀中的檢測框初始化多個(gè)軌跡。在隨后的幀中,我們根據(jù)embedding features之間的距離(最大距離限制為0.7),來將檢測框和已有的軌跡做關(guān)聯(lián)。與FairMOT一致,每一幀都會(huì)通過指數(shù)加權(quán)平均更新跟蹤器的特征,以應(yīng)對特征變化的問題。對于未匹配的激活軌跡和檢測框通過他們的IOU距離關(guān)聯(lián)起來(閾值為0.8)。最后,對于失活但未完全跟丟的軌跡和檢測框也是由它們的IoU距離關(guān)聯(lián)的(閾值為0.8)。
? ? ? ?
? ? ?為了解決行人擁擠帶來的問題,我們采用了Multiple Granularity Network(MGN),如上圖所示。我們首先利用Resnet50-ibn-a[4]提取特征,然后使用Triplet loss和Softmax loss計(jì)算三個(gè)全局特征的損失,僅使用Softmax loss計(jì)算局部特征的損失。此外,我們使用了ReID中的常用的訓(xùn)練技巧來優(yōu)化MGN的性能[3]。我們借鑒了DeepSORT和FairMOT的想法,以檢測框的表觀距離為主,以檢測框的空間距離為輔。首先,我們根據(jù)第一幀中的檢測框初始化多個(gè)軌跡。在隨后的幀中,我們根據(jù)embedding features之間的距離(最大距離限制為0.7),來將檢測框和已有的軌跡做關(guān)聯(lián)。與FairMOT一致,每一幀都會(huì)通過指數(shù)加權(quán)平均更新跟蹤器的特征,以應(yīng)對特征變化的問題。對于未匹配的激活軌跡和檢測框通過他們的IOU距離關(guān)聯(lián)起來(閾值為0.8)。最后,對于失活但未完全跟丟的軌跡和檢測框也是由它們的IoU距離關(guān)聯(lián)的(閾值為0.8)。
? ? ? ?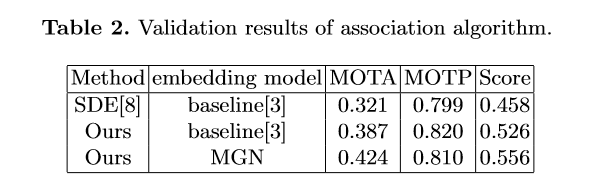 ? ? ?由于只對較高的置信度的檢測框進(jìn)行跟蹤,因此存在大量假陰性的檢測框,導(dǎo)致MOTA[1]性能低下。為了減少置信閾值的影響,團(tuán)隊(duì)嘗試了兩種簡單的插值方法。1) 對總丟失幀不超過20的軌跡進(jìn)行線性插值。我們稱之為簡單插值(simple interpolation, SI);2)對每一個(gè)軌跡只在丟失不超過4幀的幀之間插入。另外,我們稱之為片段插值(fragment interpolation, FI)。雖然插值的方法增加了假陽性樣本的數(shù)量,但是大大減少了假陰性樣本,使我們在測試集上實(shí)現(xiàn)了0.9左右的提升。不同插值方法的效果如下表所示。?? ? ? ?
? ? ?由于只對較高的置信度的檢測框進(jìn)行跟蹤,因此存在大量假陰性的檢測框,導(dǎo)致MOTA[1]性能低下。為了減少置信閾值的影響,團(tuán)隊(duì)嘗試了兩種簡單的插值方法。1) 對總丟失幀不超過20的軌跡進(jìn)行線性插值。我們稱之為簡單插值(simple interpolation, SI);2)對每一個(gè)軌跡只在丟失不超過4幀的幀之間插入。另外,我們稱之為片段插值(fragment interpolation, FI)。雖然插值的方法增加了假陽性樣本的數(shù)量,但是大大減少了假陰性樣本,使我們在測試集上實(shí)現(xiàn)了0.9左右的提升。不同插值方法的效果如下表所示。?? ? ? ?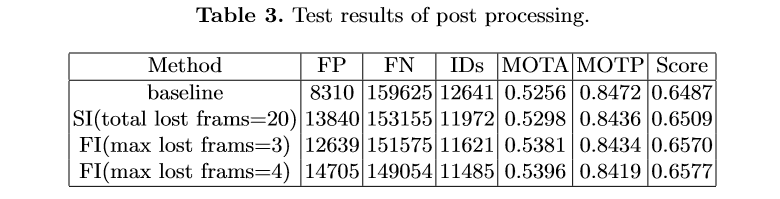 ? ? ? ?
? ? ? ?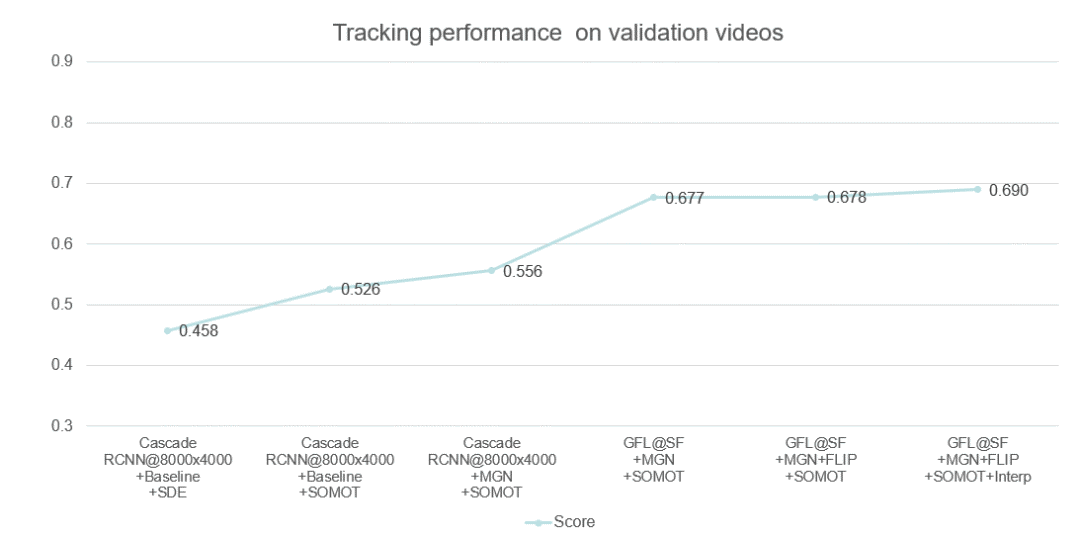 ? ? ? ?以上是團(tuán)隊(duì)對參賽方案的優(yōu)化路線圖,通過優(yōu)化檢測器以及特征提取器,數(shù)據(jù)關(guān)聯(lián)方法、后處理等方法,在GigaVision 2020多行人跟蹤挑戰(zhàn)賽中獲得第一名的成績。本文針對GigaVision多行人跟蹤挑戰(zhàn)賽,設(shè)計(jì)了一個(gè)簡單、在線的多目標(biāo)跟蹤系統(tǒng),包括檢測器、特征提取、數(shù)據(jù)關(guān)聯(lián)和軌跡后處理,在GigaVision 2020多行人跟蹤挑戰(zhàn)賽中獲得第一名。很榮幸取得這次競賽的第一名,在這里也分享一下針對多目標(biāo)跟蹤任務(wù)的一些問題以及思考:1)檢測器和特征提取器mAP越高,最終跟蹤的性能也會(huì)相應(yīng)的提升?2)數(shù)據(jù)關(guān)聯(lián)過程真的需要運(yùn)動(dòng)模型么?團(tuán)隊(duì)對以上問題進(jìn)行了思考,得出一些比較簡單的看法:1) 一般來說檢測器和特征提取器的性能越理想,最終跟蹤的性能也會(huì)有相應(yīng)的提升;mAP作為常用的檢測器評估指標(biāo)來說,mAP的提升不一定能帶來跟蹤的性能提升,當(dāng)然這也和評價(jià)指標(biāo)有關(guān)系,需要具體問題具體分析,比如檢測上多尺度增強(qiáng)帶來的AP增益往往會(huì)造成MOTA的降低。mAP作為特征提取器的評估指標(biāo)來說,mAP的提升也不一定能帶來跟蹤的性能提升,比如Part-Based 的MGN在本次競賽中雖然mAP比全局特征提取器差幾個(gè)點(diǎn),在最后的跟蹤上卻取得不錯(cuò)的效果。2)現(xiàn)實(shí)中的多目標(biāo)跟蹤任務(wù)中,攝像頭的突然運(yùn)動(dòng)以及跟蹤對象的突然加速往往都是存在的,這時(shí)候的運(yùn)動(dòng)模型其實(shí)動(dòng)態(tài)性能十分的差勁,反而造成不好的跟蹤效果,本次競賽采用的是直接不采用運(yùn)動(dòng)模型的方法。3) 跟蹤器的特征平滑操作十分簡單有效,不需要類似于DeepSORT進(jìn)行級聯(lián)匹配,速度比較快,考慮了同一軌跡的歷史特征,使得特征更加魯棒,減少了單幀跟蹤錯(cuò)誤帶來的影響;4) Part-Based的特征提取器針對這種遮擋比較嚴(yán)重的情況在距離度量時(shí)考慮了各個(gè)部分的特征,特別的,遮擋部分往往變化比較大,結(jié)合特征平滑操作,一定程度上消除了遮擋部分的影響,更關(guān)注沒有遮擋部分的特征。羅志鵬,DeepBlue Technology北京AI研發(fā)中心負(fù)責(zé)人,畢業(yè)于北京大學(xué),曾任職于微軟亞太研發(fā)集團(tuán)。現(xiàn)主要負(fù)責(zé)公司AI平臺(tái)相關(guān)研發(fā)工作,帶領(lǐng)團(tuán)隊(duì)已在CVPR、ICCV、ECCV、KDD、NeurIPS、SIGIR等數(shù)十個(gè)世界頂級會(huì)議挑戰(zhàn)賽中獲得近二十項(xiàng)冠軍,以一作在KDD、WWW等國際頂會(huì)上發(fā)表論文,具有多年跨領(lǐng)域的人工智能研究和實(shí)戰(zhàn)經(jīng)驗(yàn)。1. ?Bernardin, K. ? Stiefelhagen, R.: Evaluating multiple object tracking performance(2008)2. ?Milan, A., Leal-Taixe, L., Reid, I., Roth, S., Schindler, K.: Mot16: A benchmark for multi-object tracking (2016)3. ?Luo, H., Gu, Y., Liao, X., Lai, S., Jiang, W.: Bag of tricks and a strong baseline for deep person re-identification (2019)4. ?Pan, X., Luo, P., Shi, J., Tang, X.: Two at once: Enhancing learning and generalization capacities via ibn-net (2018)5. ?Wang, ?X., ?Zhang, ?X., ?Zhu, ?Y., ?Guo, ?Y., ?Yuan, ?X., ?Xiang, ?L., ?Wang, ?Z., ?Ding,G., Brady, D.J., Dai, Q., Fang, L.: Panda: A gigapixel-level human-centric video dataset (2020)6. ?Wojke, N., Bewley, A., Paulus, D.: Simple online and realtime tracking with a deep association metric (2017)7. ?Yu, F., Li, W., Li, Q., Liu, Y., Shi, X., Yan, J.: Poi: Multiple object tracking with high performance detection and appearance feature (2016)8. ?Zhang, Y., Wang, C., Wang, X., Zeng, W., Liu, W.: A simple baseline for multi-object tracking (2020)9. ?Li, X., Wang, W., Wu, L., Chen, S., Hu, X., Li, J., Tang, J., Yang, J.: Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. arXiv (2020)10. ?Wang, G., Yuan, Y., Chen, X., Li, J., Zhou, X.: Learning discriminative features with ?multiple ?granularities ?for ?person ?re-identification. ?CoRRabs/1804.01438(2018)11. ?Cai, Z., Vasconcelos, N.: Cascade r-cnn: Delving into high quality object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition.pp. 6154–6162 (2018)12. ?Cao, Y., Xu, J., Lin, S., Wei, F., Hu, H.: Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In: Proceedings of the IEEE International Conference on Computer Vision Workshops. pp. 0–0 (2019)13. ?Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., Wei, Y.: Deformable convolutional networks. In: Proceedings of the IEEE international conference on computer vision. pp. 764–773 (2017)14. ?Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7132–7141 (2018)15. ?Li, X., Wang, W., Wu, L., Chen, S., Hu, X., Li, J., Tang, J., Yang, J.: Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. arXiv preprint arXiv:2006.04388 (2020)16. ?Solovyev, R., Wang, W.: Weighted boxes fusion: ensembling boxes for object detection models. arXiv preprint arXiv:1910.13302 (2019)
? ? ? ?以上是團(tuán)隊(duì)對參賽方案的優(yōu)化路線圖,通過優(yōu)化檢測器以及特征提取器,數(shù)據(jù)關(guān)聯(lián)方法、后處理等方法,在GigaVision 2020多行人跟蹤挑戰(zhàn)賽中獲得第一名的成績。本文針對GigaVision多行人跟蹤挑戰(zhàn)賽,設(shè)計(jì)了一個(gè)簡單、在線的多目標(biāo)跟蹤系統(tǒng),包括檢測器、特征提取、數(shù)據(jù)關(guān)聯(lián)和軌跡后處理,在GigaVision 2020多行人跟蹤挑戰(zhàn)賽中獲得第一名。很榮幸取得這次競賽的第一名,在這里也分享一下針對多目標(biāo)跟蹤任務(wù)的一些問題以及思考:1)檢測器和特征提取器mAP越高,最終跟蹤的性能也會(huì)相應(yīng)的提升?2)數(shù)據(jù)關(guān)聯(lián)過程真的需要運(yùn)動(dòng)模型么?團(tuán)隊(duì)對以上問題進(jìn)行了思考,得出一些比較簡單的看法:1) 一般來說檢測器和特征提取器的性能越理想,最終跟蹤的性能也會(huì)有相應(yīng)的提升;mAP作為常用的檢測器評估指標(biāo)來說,mAP的提升不一定能帶來跟蹤的性能提升,當(dāng)然這也和評價(jià)指標(biāo)有關(guān)系,需要具體問題具體分析,比如檢測上多尺度增強(qiáng)帶來的AP增益往往會(huì)造成MOTA的降低。mAP作為特征提取器的評估指標(biāo)來說,mAP的提升也不一定能帶來跟蹤的性能提升,比如Part-Based 的MGN在本次競賽中雖然mAP比全局特征提取器差幾個(gè)點(diǎn),在最后的跟蹤上卻取得不錯(cuò)的效果。2)現(xiàn)實(shí)中的多目標(biāo)跟蹤任務(wù)中,攝像頭的突然運(yùn)動(dòng)以及跟蹤對象的突然加速往往都是存在的,這時(shí)候的運(yùn)動(dòng)模型其實(shí)動(dòng)態(tài)性能十分的差勁,反而造成不好的跟蹤效果,本次競賽采用的是直接不采用運(yùn)動(dòng)模型的方法。3) 跟蹤器的特征平滑操作十分簡單有效,不需要類似于DeepSORT進(jìn)行級聯(lián)匹配,速度比較快,考慮了同一軌跡的歷史特征,使得特征更加魯棒,減少了單幀跟蹤錯(cuò)誤帶來的影響;4) Part-Based的特征提取器針對這種遮擋比較嚴(yán)重的情況在距離度量時(shí)考慮了各個(gè)部分的特征,特別的,遮擋部分往往變化比較大,結(jié)合特征平滑操作,一定程度上消除了遮擋部分的影響,更關(guān)注沒有遮擋部分的特征。羅志鵬,DeepBlue Technology北京AI研發(fā)中心負(fù)責(zé)人,畢業(yè)于北京大學(xué),曾任職于微軟亞太研發(fā)集團(tuán)。現(xiàn)主要負(fù)責(zé)公司AI平臺(tái)相關(guān)研發(fā)工作,帶領(lǐng)團(tuán)隊(duì)已在CVPR、ICCV、ECCV、KDD、NeurIPS、SIGIR等數(shù)十個(gè)世界頂級會(huì)議挑戰(zhàn)賽中獲得近二十項(xiàng)冠軍,以一作在KDD、WWW等國際頂會(huì)上發(fā)表論文,具有多年跨領(lǐng)域的人工智能研究和實(shí)戰(zhàn)經(jīng)驗(yàn)。1. ?Bernardin, K. ? Stiefelhagen, R.: Evaluating multiple object tracking performance(2008)2. ?Milan, A., Leal-Taixe, L., Reid, I., Roth, S., Schindler, K.: Mot16: A benchmark for multi-object tracking (2016)3. ?Luo, H., Gu, Y., Liao, X., Lai, S., Jiang, W.: Bag of tricks and a strong baseline for deep person re-identification (2019)4. ?Pan, X., Luo, P., Shi, J., Tang, X.: Two at once: Enhancing learning and generalization capacities via ibn-net (2018)5. ?Wang, ?X., ?Zhang, ?X., ?Zhu, ?Y., ?Guo, ?Y., ?Yuan, ?X., ?Xiang, ?L., ?Wang, ?Z., ?Ding,G., Brady, D.J., Dai, Q., Fang, L.: Panda: A gigapixel-level human-centric video dataset (2020)6. ?Wojke, N., Bewley, A., Paulus, D.: Simple online and realtime tracking with a deep association metric (2017)7. ?Yu, F., Li, W., Li, Q., Liu, Y., Shi, X., Yan, J.: Poi: Multiple object tracking with high performance detection and appearance feature (2016)8. ?Zhang, Y., Wang, C., Wang, X., Zeng, W., Liu, W.: A simple baseline for multi-object tracking (2020)9. ?Li, X., Wang, W., Wu, L., Chen, S., Hu, X., Li, J., Tang, J., Yang, J.: Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. arXiv (2020)10. ?Wang, G., Yuan, Y., Chen, X., Li, J., Zhou, X.: Learning discriminative features with ?multiple ?granularities ?for ?person ?re-identification. ?CoRRabs/1804.01438(2018)11. ?Cai, Z., Vasconcelos, N.: Cascade r-cnn: Delving into high quality object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition.pp. 6154–6162 (2018)12. ?Cao, Y., Xu, J., Lin, S., Wei, F., Hu, H.: Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In: Proceedings of the IEEE International Conference on Computer Vision Workshops. pp. 0–0 (2019)13. ?Dai, J., Qi, H., Xiong, Y., Li, Y., Zhang, G., Hu, H., Wei, Y.: Deformable convolutional networks. In: Proceedings of the IEEE international conference on computer vision. pp. 764–773 (2017)14. ?Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 7132–7141 (2018)15. ?Li, X., Wang, W., Wu, L., Chen, S., Hu, X., Li, J., Tang, J., Yang, J.: Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. arXiv preprint arXiv:2006.04388 (2020)16. ?Solovyev, R., Wang, W.: Weighted boxes fusion: ensembling boxes for object detection models. arXiv preprint arXiv:1910.13302 (2019)




