
神經網絡壓縮方法:模型量化的概念簡介

來源:DeepHub IMBA 本文約3200字,建議閱讀6分鐘?
本文為你介紹如何使用量化的方法優(yōu)化重型深度神經網絡模型。
在過去的十年中,深度學習在解決許多以前被認為無法解決的問題方面發(fā)揮了重要作用,并且在某些任務上的準確性也與人類水平相當甚至超過了人類水平。如下圖所示,更深的網絡具有更高的準確度,這一點也被廣泛接受并且證明。
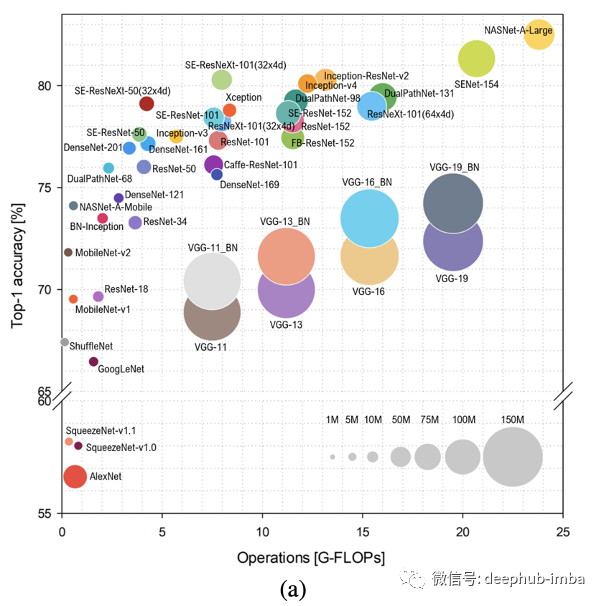
更長的推理時間 更高的計算要求 更長的訓練時間
模型壓縮方法
什么是量化?


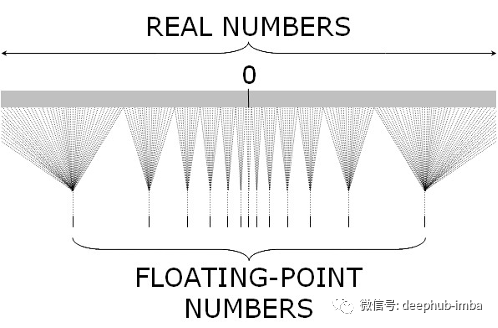
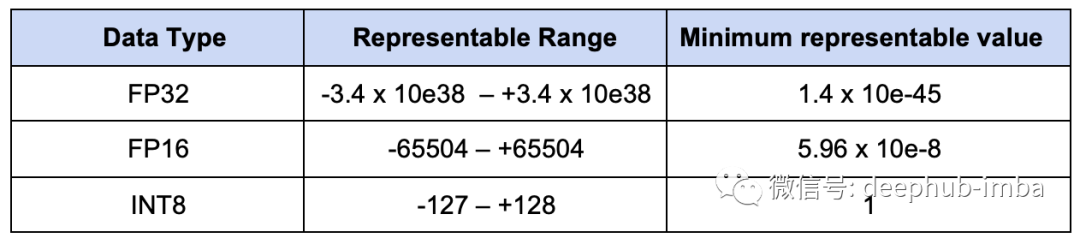
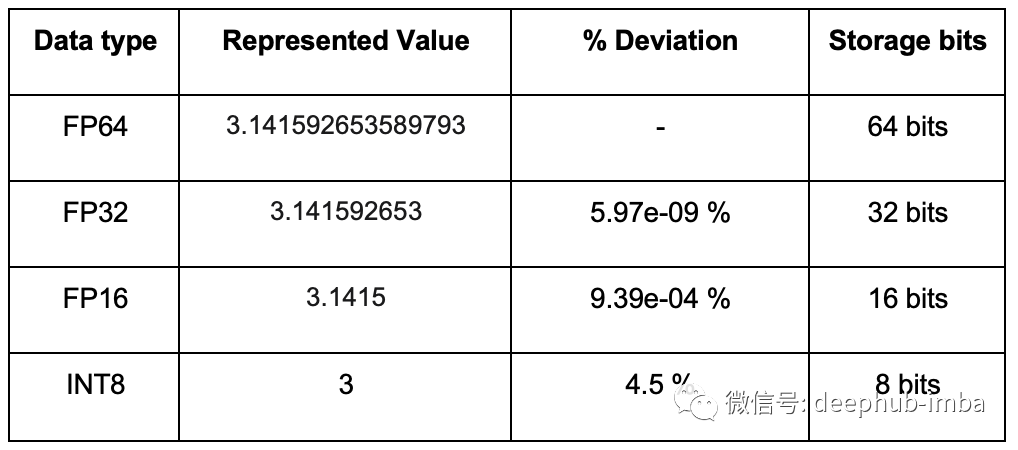
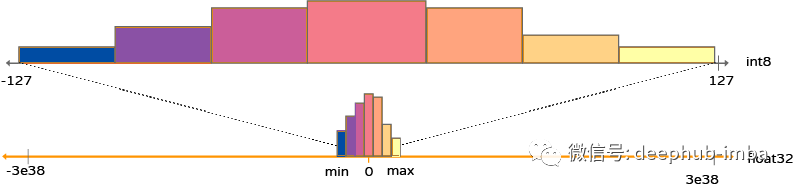


深度學習中的量化
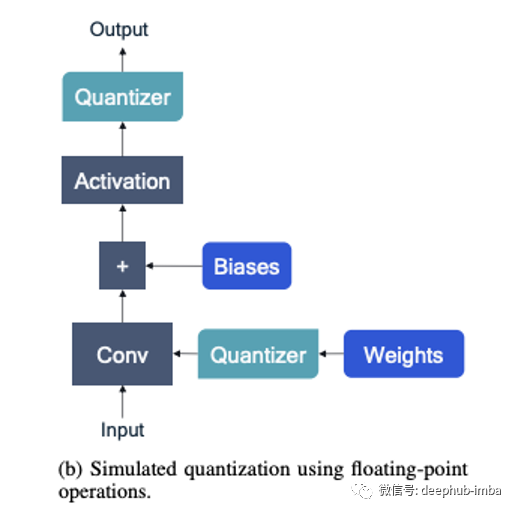
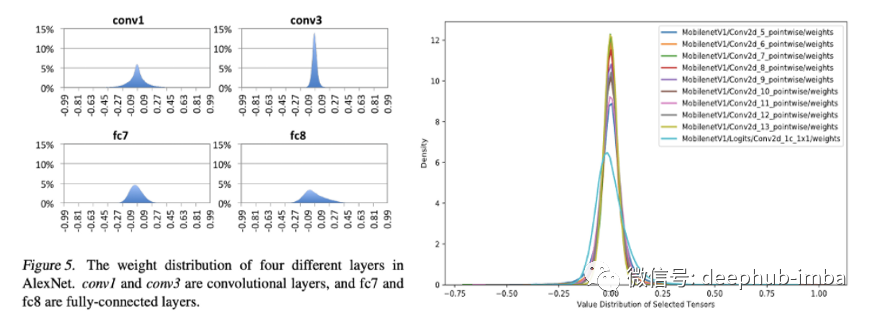
量化類型
訓練后量化:在模型完全訓練后執(zhí)行 量化感知訓練:訓練是在量化約束下完成的



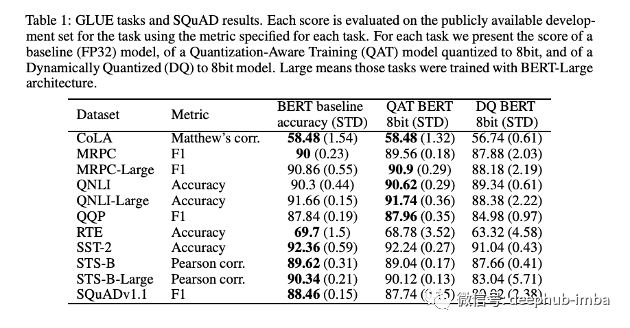
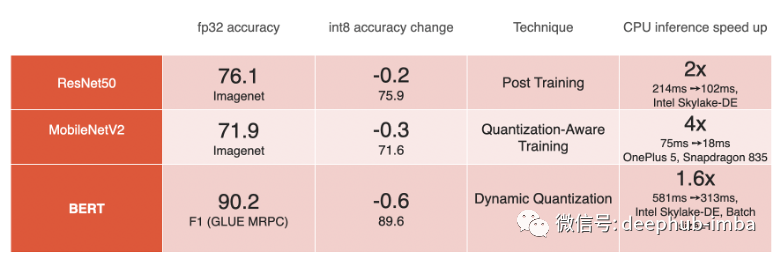
模型的基準測試
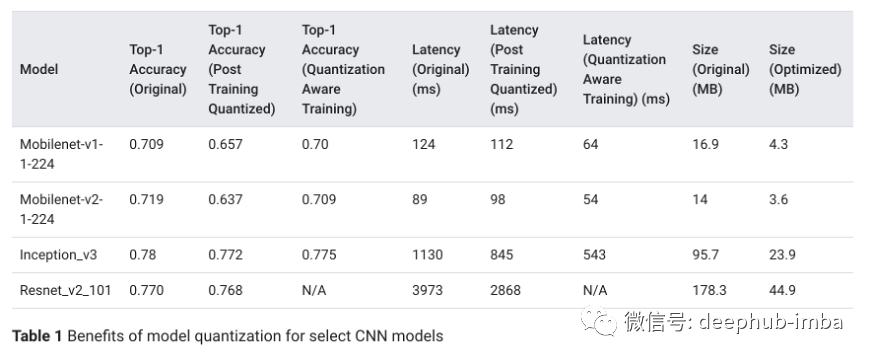
總結
評論
圖片
表情