
實(shí)踐教程 | 卷積神經(jīng)網(wǎng)絡(luò)壓縮方法總結(jié)
點(diǎn)擊下方卡片,關(guān)注“新機(jī)器視覺”公眾號(hào)
視覺/圖像重磅干貨,第一時(shí)間送達(dá)
我們知道,在一定程度上,網(wǎng)絡(luò)越深,參數(shù)越多,模型越復(fù)雜,其最終效果越好。神經(jīng)網(wǎng)絡(luò)的壓縮算法是,旨在將一個(gè)龐大而復(fù)雜的預(yù)訓(xùn)練模型(pre-trained model)轉(zhuǎn)化為一個(gè)精簡(jiǎn)的小模型。按照壓縮過程對(duì)網(wǎng)絡(luò)結(jié)構(gòu)的破壞程度,我們將模型壓縮技術(shù)分為“前端壓縮”和“后端壓縮”兩部分。
前端壓縮,是指在不改變?cè)W(wǎng)絡(luò)結(jié)構(gòu)的壓縮技術(shù),主要包括知識(shí)蒸餾、緊湊的模型結(jié)構(gòu)涉及以及濾波器(filter)層面的剪枝等。
后端壓縮,是指包括低秩近似、未加限制的剪枝、參數(shù)量化以及二值網(wǎng)絡(luò)等,目標(biāo)在于盡可能減少模型大小,會(huì)對(duì)原始網(wǎng)絡(luò)結(jié)構(gòu)造成極大程度的改造。
總結(jié):前端壓縮幾乎不改變?cè)芯W(wǎng)絡(luò)結(jié)構(gòu)(僅僅只是在原模型基礎(chǔ)上減少了網(wǎng)絡(luò)的層數(shù)或者濾波器個(gè)數(shù)),后端壓縮對(duì)網(wǎng)絡(luò)結(jié)構(gòu)有不可逆的大幅度改變,造成原有深度學(xué)習(xí)庫(kù)、甚至硬件設(shè)備不兼容改變之后的網(wǎng)絡(luò)。其維護(hù)成本很高。
1. 低秩近似
簡(jiǎn)單理解就是,卷積神經(jīng)網(wǎng)絡(luò)的權(quán)重矩陣往往稠密且巨大,從而計(jì)算開銷大,有一種辦法是采用低秩近似的技術(shù)將該稠密矩陣由若干個(gè)小規(guī)模矩陣近似重構(gòu)出來,這種方法歸類為低秩近似算法。
一般地,行階梯型矩陣的秩等于其“臺(tái)階數(shù)”----非零行的行數(shù)。
低秩近似算法能減小計(jì)算開銷的原理如下:
給定權(quán)重矩陣 , 若能將其表示為若干個(gè)低秩矩陣的組合, 即 , 其中 為低秩矩陣, 其秩為 , 并滿足 , 則其每一個(gè)低秩矩陣都可分解為小規(guī)模矩陣的乘積, ,其中 , 。當(dāng) 取值很小時(shí), 便能大幅降低總體的存儲(chǔ)和計(jì)算開銷。
基于以上想法, Sindhwani 等人提出使用結(jié)構(gòu)化矩陣來進(jìn)行低秩分解的算法, 具體原理可自行參考論文。另一種比較簡(jiǎn)便的方法 是使用矩陣分解來降低權(quán)重矩陣的參數(shù), 如 Denton 等人提出使用奇異值分解(Singular Value Decomposition, 簡(jiǎn)稱 SVD)分解 來重構(gòu)全連接層的權(quán)重。
1.1 總結(jié)
低秩近似算法在中小型網(wǎng)絡(luò)模型上,取得了很不錯(cuò)的效果,但其超參數(shù)量與網(wǎng)絡(luò)層數(shù)呈線性變化趨勢(shì),隨著網(wǎng)絡(luò)層數(shù)的增加與模型復(fù)雜度的提升,其搜索空間會(huì)急劇增大,目前主要是學(xué)術(shù)界在研究,工業(yè)界應(yīng)用不多。
2. 剪枝與稀疏約束
給定一個(gè)預(yù)訓(xùn)練好的網(wǎng)絡(luò)模型,常用的剪枝算法一般都遵從如下操作:
-
衡量神經(jīng)元的重要程度。
-
移除掉一部分不重要的神經(jīng)元,這步比前 1 步更加簡(jiǎn)便,靈活性更高。
-
對(duì)網(wǎng)絡(luò)進(jìn)行微調(diào),剪枝操作不可避免地影響網(wǎng)絡(luò)的精度,為防止對(duì)分類性能造成過大的破壞,需要對(duì)剪枝后的模型進(jìn)行微調(diào)。對(duì)于大規(guī)模行圖像數(shù)據(jù)集(如ImageNet)而言,微調(diào)會(huì)占用大量的計(jì)算資源,因此對(duì)網(wǎng)絡(luò)微調(diào)到什么程度,是需要斟酌的。
-
返回第一步,循環(huán)進(jìn)行下一輪剪枝。
基于以上循環(huán)剪枝框架,不同學(xué)者提出了不同的方法,Han等人提出首先將低于某個(gè)閾值的權(quán)重連接全部剪除,之后對(duì)剪枝后的網(wǎng)絡(luò)進(jìn)行微調(diào)以完成參數(shù)更新的方法,這種方法的不足之處在于,剪枝后的網(wǎng)絡(luò)是非結(jié)構(gòu)化的,即被剪除的網(wǎng)絡(luò)連接在分布上,沒有任何連續(xù)性,這種稀疏的結(jié)構(gòu),導(dǎo)致CPU高速緩沖與內(nèi)存頻繁切換,從而限制了實(shí)際的加速效果。
基于此方法,有學(xué)者嘗試將剪枝的粒度提升到整個(gè)濾波器級(jí)別,即丟棄整個(gè)濾波器,但是如何衡量濾波器的重要程度是一個(gè)問題,其中一種策略是基于濾波器權(quán)重本身的統(tǒng)計(jì)量,如分別計(jì)算每個(gè)濾波器的 L1 或 L2 值,將相應(yīng)數(shù)值大小作為衡量重要程度標(biāo)準(zhǔn)。
利用稀疏約束來對(duì)網(wǎng)絡(luò)進(jìn)行剪枝也是一個(gè)研究方向,其思路是在網(wǎng)絡(luò)的優(yōu)化目標(biāo)中加入權(quán)重的稀疏正則項(xiàng),使得訓(xùn)練時(shí)網(wǎng)絡(luò)的部分權(quán)重趨向于 0 ,而這些 0 值就是剪枝的對(duì)象。
2.1 總結(jié)
總體而言,剪枝是一項(xiàng)有效減小模型復(fù)雜度的通用壓縮技術(shù),其關(guān)鍵之處在于如何衡量個(gè)別權(quán)重對(duì)于整體模型的重要程度。剪枝操作對(duì)網(wǎng)絡(luò)結(jié)構(gòu)的破壞程度極小,將剪枝與其他后端壓縮技術(shù)相結(jié)合,能夠達(dá)到網(wǎng)絡(luò)模型最大程度壓縮,目前工業(yè)界有使用剪枝方法進(jìn)行模型壓縮的案例。
3. 參數(shù)量化
相比于剪枝操作,參數(shù)量化則是一種常用的后端壓縮技術(shù)。所謂“量化”,是指從權(quán)重中歸納出若干“代表”,由這些“代表”來表示某一類權(quán)重的具體數(shù)值。“代表”被存儲(chǔ)在碼本(codebook)之中,而原權(quán)重矩陣只需記錄各自“代表”的索引即可,從而極大地降低了存儲(chǔ)開銷。這種思想可類比于經(jīng)典的詞包模型(bag-of-words model)。常用量化算法如下:
-
標(biāo)量量化(scalar quantization)。
-
標(biāo)量量化會(huì)在一定程度上降低網(wǎng)絡(luò)的精度,為避免這個(gè)弊端,很多算法考慮結(jié)構(gòu)化的向量方法,其中一種是乘積向量(Product Quantization, PQ),詳情咨詢查閱論文。
-
以PQ方法為基礎(chǔ),Wu等人設(shè)計(jì)了一種通用的網(wǎng)絡(luò)量化算法:QCNN(quantized CNN),主要思想在于Wu等人認(rèn)為最小化每一層網(wǎng)絡(luò)輸出的重構(gòu)誤差,比最小化量化誤差更有效。
標(biāo)量量化算法基本思路是, 對(duì)于每一個(gè)權(quán)重矩陣 , 首先將其轉(zhuǎn)化為向量形式: 。之后對(duì)該權(quán)重向量 的元素進(jìn)行 個(gè)簇的聚類, 這可借助于經(jīng)典的 k-均值 (k-means) 聚類算法快速完成:
這樣,只需將 個(gè)聚類中心 ,標(biāo)量 存儲(chǔ)在碼本中,而原權(quán)重矩陣則只負(fù)責(zé)記錄各自聚類中心在碼本中索引。如果不 考慮碼本的存儲(chǔ)開銷,該算法能將存儲(chǔ)空間減少為原來的 。基于 均值算法的標(biāo)量量化在很多應(yīng)用中非常有效。參數(shù)量化與碼本微調(diào)過程圖如下:

這三類基于聚類的參數(shù)量化算法,其本質(zhì)思想在于將多個(gè)權(quán)重映射到同一個(gè)數(shù)值,從而實(shí)現(xiàn)權(quán)重共享,降低存儲(chǔ)開銷的目的。
3.1 總結(jié)
參數(shù)量化是一種常用的后端壓縮技術(shù),能夠以很小的性能損失實(shí)現(xiàn)模型體積的大幅下降,不足之處在于,量化的網(wǎng)絡(luò)是“固定”的,很難對(duì)其做任何改變,同時(shí)這種方法通用性差,需要配套專門的深度學(xué)習(xí)庫(kù)來運(yùn)行網(wǎng)絡(luò)。
4. 二值化網(wǎng)絡(luò)
-
二值化網(wǎng)絡(luò)可以視為量化方法的一種極端情況:所有的權(quán)重參數(shù)取值只能為 ,也就是使用 1bit 來存儲(chǔ) Weight 和 Feature。在普通神經(jīng)網(wǎng)絡(luò)中,一個(gè)參數(shù)是由單精度浮點(diǎn)數(shù)來表示的,參數(shù)的二值化能將存儲(chǔ)開銷降低為原來的 1/32。
-
二值化神經(jīng)網(wǎng)絡(luò)以其高的模型壓縮率和在前傳中計(jì)算速度上的優(yōu)勢(shì),近幾年格外受到重視和發(fā)展,成為神經(jīng)網(wǎng)絡(luò)模型研究中的非常熱門的一個(gè)研究方向。但是,第一篇真正意義上將神經(jīng)網(wǎng)絡(luò)中的權(quán)重值和激活函數(shù)值同時(shí)做到二值化的是 Courbariaux 等人 2016 年發(fā)表的名為《Binarynet: Training deep neural networks with weights and activations constrained to +1 or -1》的一篇論文。這篇論文第一次給出了關(guān)于如何對(duì)網(wǎng)絡(luò)進(jìn)行二值化和如何訓(xùn)練二值化神經(jīng)網(wǎng)絡(luò)的方法。
-
CNN 網(wǎng)絡(luò)一個(gè)典型的模坱是由卷積(Conv)->批標(biāo)準(zhǔn)化(BNorm)->激活(Activ)->池化 Pool)這樣的順序操作組成的。對(duì)于異或神經(jīng)網(wǎng)絡(luò),設(shè)計(jì)出的模塊是由批標(biāo)準(zhǔn)化 二值化激活(BinActiv) ->二值化卷積(BinConv)->池化 (Pool)的順序操作完成。這樣做的原因是批標(biāo)準(zhǔn)化以后,保證了輸入均值為 0 ,然后進(jìn)行二值化激活,保證了數(shù)據(jù)為 或者 ,然后進(jìn)行二值化卷積,這樣能最大程度上減少特征信息的損失。二值化殘差網(wǎng)絡(luò)結(jié)構(gòu)定義實(shí)例代碼如下:
def residual_unit(data, num_filter, stride, dim_match, num_bits=1):
"""殘差塊 Residual Block 定義
"""
bnAct1 = bnn.BatchNorm(data=data, num_bits=num_bits)
conv1 = bnn.Convolution(data=bnAct1, num_filter=num_filter, kernel=(3, 3), stride=stride, pad=(1, 1))
convBn1 = bnn.BatchNorm(data=conv1, num_bits=num_bits)
conv2 = bnn.Convolution(data=convBn1, num_filter=num_filter, kernel=(3, 3), stride=(1, 1), pad=(1, 1))
if dim_match:
shortcut = data
else:
shortcut = bnn.Convolution(data=bnAct1, num_filter=num_filter, kernel=(3, 3), stride=stride, pad=(1, 1))
return conv2 + shortcut
4.1 二值網(wǎng)絡(luò)的梯度下降
現(xiàn)在的神經(jīng)網(wǎng)絡(luò)幾乎都是基于梯度下降算法來訓(xùn)練的,但是二值網(wǎng)絡(luò)的權(quán)重只有±1,無(wú)法直接計(jì)算梯度信息,也無(wú)法進(jìn)行權(quán)重更新。為解決這個(gè)問題,Courbariaux 等人提出二值連接(binary connect)算法,該算法采取單精度與二值結(jié)合的方式來訓(xùn)練二值神經(jīng)網(wǎng)絡(luò)(),這是第一次給出了關(guān)于如何對(duì)網(wǎng)絡(luò)進(jìn)行二值化和如何訓(xùn)練二值化神經(jīng)網(wǎng)絡(luò)的方法。過程如下:
-
權(quán)重 weight 初始化為浮點(diǎn)
-
前向傳播 Forward Pass:
-利用決定化方式(sign(x)函數(shù))把 Weight 量化為 +1/-1, 以0為閾值 - 利用量化后的 Weight (只有+1/-1)來計(jì)算前向傳播,由二值權(quán)重與輸入進(jìn)行卷積運(yùn)算(實(shí)際上只涉及加法),獲得卷積層輸出。 -
反向傳播 Backward Pass:把梯度更新到浮點(diǎn)的 Weight 上(根據(jù)放松后的符號(hào)函數(shù),計(jì)算相應(yīng)梯度值,并根據(jù)該梯度的值對(duì)單精度的權(quán)重進(jìn)行參數(shù)更新);訓(xùn)練結(jié)束:把 Weight 永久性轉(zhuǎn)化為 +1/-1, 以便 inference 使用。
4.2 兩個(gè)問題
網(wǎng)絡(luò)二值化需要解決兩個(gè)問題:如何對(duì)權(quán)重進(jìn)行二值化和如何計(jì)算二值權(quán)重的梯度。
-
如何對(duì)權(quán)重進(jìn)行二值化? 權(quán)重二值化一般有兩種選擇:
-
直接根據(jù)權(quán)重的正負(fù)進(jìn)行二值化: 。符號(hào)函數(shù) 定義如下:
-
進(jìn)行隨機(jī)的二值化,即對(duì)每一個(gè)權(quán)重, 以一定概率取 。
-
如何計(jì)算二值權(quán)重的梯度? 二值權(quán)重的梯度為 0 ,無(wú)法進(jìn)行參數(shù)更新。為解決這個(gè)問題,需要對(duì)符號(hào)函數(shù)進(jìn)行放松,即用 來代替 。當(dāng) 在區(qū)間 時(shí),存在梯度值 1,否則梯度為 0 。
4.3 二值連接算法改進(jìn)
之前的二值連接算法只對(duì)權(quán)重進(jìn)行了二值化,但是網(wǎng)絡(luò)的中間輸出值依然是單精度的,于是 Rastegari 等人對(duì)此進(jìn)行了改進(jìn),提出用單精度對(duì)角陣與二值矩陣之積來近似表示原矩陣的算法,以提升二值網(wǎng)絡(luò)的分類性能,彌補(bǔ)二值網(wǎng)絡(luò)在精度上弱勢(shì)。該算法 將原卷積運(yùn)算分解為如下過程:
其中 為該層的輸入張量, 為該層的一個(gè)濾波器, 為該濾波器所 對(duì)應(yīng)的二值權(quán)重。
這里,Rastegari 等人認(rèn)為單靠二值運(yùn)算,很難達(dá)到原單精度卷積元素的結(jié)果,于是他們使用了一個(gè)單精度放縮因子 來 對(duì)二值濾波器卷積后的結(jié)果進(jìn)行放縮。而 的取值,則可根據(jù)優(yōu)化目標(biāo):
得到 。二值連接改進(jìn)的算法訓(xùn)練過程與之前的算法大致相同,不同的地方在于梯度的計(jì)算過程還考慮了 的影響。由于 這個(gè)單精度的縮放因子的存在,有效降低了重構(gòu)誤差,并首次在 ImageNet 數(shù)據(jù)集上取得了與 Alex-Net 相當(dāng)?shù)木取H缦聢D所示:
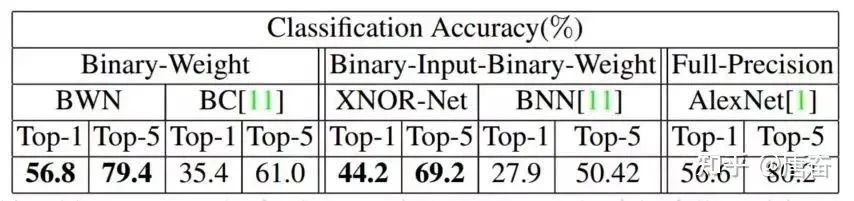
可以看到的是權(quán)重二值化神經(jīng)網(wǎng)絡(luò)(BWN)和全精度神經(jīng)網(wǎng)絡(luò)的精確度幾乎一樣,但是與異或神經(jīng)網(wǎng)絡(luò)(XNOR-Net)相比而言,Top-1 和 Top-5 都有 10+% 的損失。
相比于權(quán)重二值化神經(jīng)網(wǎng)絡(luò),異或神經(jīng)網(wǎng)絡(luò)將網(wǎng)絡(luò)的輸入也轉(zhuǎn)化為二進(jìn)制值,所以,異或神經(jīng)網(wǎng)絡(luò)中的乘法加法 (Multiplication and ACcumulation) 運(yùn)算用按位異或 (bitwise xnor) 和數(shù) 1 的個(gè)數(shù) (popcount) 來代替。
更多內(nèi)容,可以看這兩篇文章:
https://github.com/Ewenwan/MVision/tree/master/CNN/Deep_Compression/quantization/BNN
https://blog.csdn.net/stdcoutzyx/article/details/50926174
4.4 二值網(wǎng)絡(luò)設(shè)計(jì)注意事項(xiàng)
-
不要使用 kernel = (1, 1) 的 Convolution (包括 resnet 的 bottleneck):二值網(wǎng)絡(luò)中的 weight 都為 1bit, 如果再是 1x1 大小, 會(huì)極大地降低表達(dá)能力 -
增大 Channel 數(shù)目 + 增大 activation bit 數(shù) 要協(xié)同配合:如果一味增大 channel 數(shù), 最終 feature map 因?yàn)?bit 數(shù)過低, 還是浪費(fèi)了模型容量。同理反過來也是。 -
建議使用 4bit 及以下的 activation bit,過高帶來的精度收益變小,而會(huì)顯著提高 inference 計(jì)算量
5.知識(shí)蒸餾
本文只簡(jiǎn)單介紹這個(gè)領(lǐng)域的開篇之作-Distilling the Knowledge in a Neural Network,這是蒸 "logits"方法,后面還出現(xiàn)了蒸 "features" 的論文。想要更深入理解,中文博客可參考這篇文章-知識(shí)蒸餾是什么?一份入門隨筆(https://zhuanlan.zhihu.com/p/90049906)。
知識(shí)蒸餾(knowledge distillation)(https://arxiv.org/abs/1503.02531),是遷移學(xué)習(xí)(transfer learning)的一種,簡(jiǎn)單來說就是訓(xùn)練一個(gè)大模型(teacher)和一個(gè)小模型(student),將龐大而復(fù)雜的大模型學(xué)習(xí)到的知識(shí),通過一定技術(shù)手段遷移到精簡(jiǎn)的小模型上,從而使小模型能夠獲得與大模型相近的性能。
在知識(shí)蒸餾的實(shí)驗(yàn)中,我們先訓(xùn)練好一個(gè) teacher 網(wǎng)絡(luò),然后將 teacher 的網(wǎng)絡(luò)的輸出結(jié)果 作為 student 網(wǎng)絡(luò)的目標(biāo),訓(xùn)練 student 網(wǎng)絡(luò),使得 student 網(wǎng)絡(luò)的結(jié)果 接近 ,因此,student 網(wǎng)絡(luò)的損失函數(shù)為 。這里 是交叉熵 (Cross Entropy), 是真實(shí)標(biāo)簽的 onehot 編碼, 是 teacher 網(wǎng)絡(luò)的輸出結(jié)果, 是 student 網(wǎng)絡(luò)的輸出結(jié)果。
但是,直接使用 teacher 網(wǎng)絡(luò)的 softmax 的輸出結(jié)果 ,可能不大合適。因此,一個(gè)網(wǎng)絡(luò)訓(xùn)練好之后, 對(duì)于正確的答案會(huì)有一個(gè) 很高的置信度。例如,在 MNIST 數(shù)據(jù)中,對(duì)于某個(gè) 2 的輸入,對(duì)于 2 的預(yù)測(cè)概率會(huì)很高,而對(duì)于 2 類似的數(shù)字,例如 3 和 7 的預(yù)測(cè)概率為 和 。這樣的話,teacher 網(wǎng)絡(luò)學(xué)到數(shù)據(jù)的相似信息(例如數(shù)字 2 和 3,7 很類似)很難傳達(dá)給 student 網(wǎng)絡(luò),因?yàn)樗鼈兊母怕手到咏?。因此,論文提出了 softmax-T(軟標(biāo)簽計(jì)算公式)公式,如下所示:
這里 是 student 網(wǎng)絡(luò)學(xué)習(xí)的對(duì)象(soft targets) , 是 teacher 網(wǎng)絡(luò) softmax 前一層的輸出 logit。如果將 取 1,上述公式變成 ,根據(jù) logit 輸出各個(gè)類別的概率。如果 接近于 0,則最大的值會(huì)越近 1 ,其它值會(huì)接近 0,近似于 onehot 編碼。
所以,可以知道 student 模型最終的損失函數(shù)由兩部分組成:
-
第一項(xiàng)是由小模型(student 模型)的預(yù)測(cè)結(jié)果與大模型的“軟標(biāo)簽”所構(gòu)成的交叉熵(cross entroy);
-
第二項(xiàng)為小模型預(yù)測(cè)結(jié)果與普通類別標(biāo)簽的交叉熵。
這兩個(gè)損失函數(shù)的重要程度可通過一定的權(quán)重進(jìn)行調(diào)節(jié),在實(shí)際應(yīng)用中, T 的取值會(huì)影響最終的結(jié)果,一般而言,較大的 T 能夠獲得較高的準(zhǔn)確度,T(蒸餾溫度參數(shù)) 屬于知識(shí)蒸餾模型訓(xùn)練超參數(shù)的一種。T 是一個(gè)可調(diào)節(jié)的超參數(shù)、T 值越大、概率分布越軟(論文中的描述),曲線便越平滑,相當(dāng)于在遷移學(xué)習(xí)的過程中添加了擾動(dòng),從而使得學(xué)生網(wǎng)絡(luò)在借鑒學(xué)習(xí)的時(shí)候更有效、泛化能力更強(qiáng),這其實(shí)就是一種抑制過擬合的策略。知識(shí)蒸餾的整個(gè)過程如下圖:
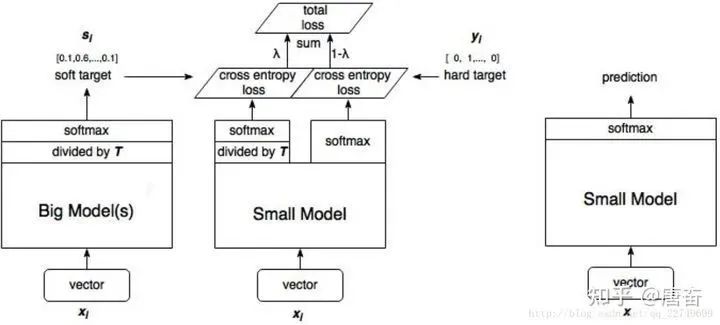
student 模型的實(shí)際模型結(jié)構(gòu)和小模型一樣,但是損失函數(shù)包含了兩部分,分類網(wǎng)絡(luò)的知識(shí)蒸餾 mxnet 代碼示例如下:
# -*-coding-*- : utf-8
"""
本程序沒有給出具體的模型結(jié)構(gòu)代碼,主要給出了知識(shí)蒸餾 softmax 損失計(jì)算部分。
"""
import mxnet as mx
def get_symbol(data, class_labels, resnet_layer_num,Temperature,mimic_weight,num_classes=2):
backbone = StudentBackbone(data) # Backbone 為分類網(wǎng)絡(luò) backbone 類
flatten = mx.symbol.Flatten(data=conv1, name="flatten")
fc_class_score_s = mx.symbol.FullyConnected(data=flatten, num_hidden=num_classes, name='fc_class_score')
softmax1 = mx.symbol.SoftmaxOutput(data=fc_class_score_s, label=class_labels, name='softmax_hard')
import symbol_resnet # Teacher model
fc_class_score_t = symbol_resnet.get_symbol(net_depth=resnet_layer_num, num_class=num_classes, data=data)
s_input_for_softmax=fc_class_score_s/Temperature
t_input_for_softmax=fc_class_score_t/Temperature
t_soft_labels=mx.symbol.softmax(t_input_for_softmax, name='teacher_soft_labels')
softmax2 = mx.symbol.SoftmaxOutput(data=s_input_for_softmax, label=t_soft_labels, name='softmax_soft',grad_scale=mimic_weight)
group=mx.symbol.Group([softmax1,softmax2])
group.save('group2-symbol.json')
return group
tensorflow代碼示例如下:
# 將類別標(biāo)簽進(jìn)行one-hot編碼
one_hot = tf.one_hot(y, n_classes,1.0,0.0) # n_classes為類別總數(shù), n為類別標(biāo)簽
# one_hot = tf.cast(one_hot_int, tf.float32)
teacher_tau = tf.scalar_mul(1.0/args.tau, teacher) # teacher為teacher模型直接輸出張量, tau為溫度系數(shù)T
student_tau = tf.scalar_mul(1.0/args.tau, student) # 將模型直接輸出logits張量student處于溫度系數(shù)T
objective1 = tf.nn.sigmoid_cross_entropy_with_logits(student_tau, one_hot)
objective2 = tf.scalar_mul(0.5, tf.square(student_tau-teacher_tau))
"""
student模型最終的損失函數(shù)由兩部分組成:
第一項(xiàng)是由小模型的預(yù)測(cè)結(jié)果與大模型的“軟標(biāo)簽”所構(gòu)成的交叉熵(cross entroy);
第二項(xiàng)為預(yù)測(cè)結(jié)果與普通類別標(biāo)簽的交叉熵。
"""
tf_loss = (args.lamda*tf.reduce_sum(objective1) + (1-args.lamda)*tf.reduce_sum(objective2))/batch_size
tf.scalar_mul 函數(shù)為對(duì) tf 張量進(jìn)行固定倍率 scalar 縮放函數(shù)。一般 T 的取值在 1 - 20 之間,這里我參考了開源代碼,取值為 3。我發(fā)現(xiàn)在開源代碼中 student 模型的訓(xùn)練,有些是和 teacher 模型一起訓(xùn)練的,有些是 teacher 模型訓(xùn)練好后直接指導(dǎo) student 模型訓(xùn)練。
6. 淺層/輕量網(wǎng)絡(luò)
淺層網(wǎng)絡(luò):通過設(shè)計(jì)一個(gè)更淺(層數(shù)較少)結(jié)構(gòu)更緊湊的網(wǎng)絡(luò)來實(shí)現(xiàn)對(duì)復(fù)雜模型效果的逼近, 但是淺層網(wǎng)絡(luò)的表達(dá)能力很難與深層網(wǎng)絡(luò)相匹敵。因此,這種設(shè)計(jì)方法的局限性在于只能應(yīng)用解決在較為簡(jiǎn)單問題上。如分類問題中類別數(shù)較少的 task。
輕量網(wǎng)絡(luò):使用如 MobilenetV2、ShuffleNetv2 等輕量網(wǎng)絡(luò)結(jié)構(gòu)作為模型的 backbone可以大幅減少模型參數(shù)數(shù)量。
參考資料
-
https://www.cnblogs.com/dyl222/p/11079489.html -
https://github.com/chengshengchan/model_compression/blob/master/teacher-student.py -
https://github.com/dkozlov/awesome-knowledge-distillation -
https://arxiv.org/abs/1603.05279 -
解析卷積神經(jīng)網(wǎng)絡(luò)-深度學(xué)習(xí)實(shí)踐手冊(cè) -
https://zhuanlan.zhihu.com/p/81467832
—版權(quán)聲明—
僅用于學(xué)術(shù)分享,版權(quán)屬于原作者。
若有侵權(quán),請(qǐng)聯(lián)系微信號(hào):yiyang-sy 刪除或修改!