點(diǎn)擊上方“AI算法與圖像處理”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
來源:機(jī)器之心
CVPR 2020 會(huì)議上,有哪些目標(biāo)檢測論文值得關(guān)注?
目標(biāo)檢測是計(jì)算機(jī)視覺中的經(jīng)典問題之一。憑借大量可用數(shù)據(jù)、更快的 GPU 和更好的算法,現(xiàn)在我們可以輕松訓(xùn)練計(jì)算機(jī)以高精度檢測出圖像中的多個(gè)對象。前不久結(jié)束的 CVPR 2020 會(huì)議在推動(dòng)目標(biāo)檢測領(lǐng)域發(fā)展方面做出了一些貢獻(xiàn),本文就為大家推薦其中 6 篇有價(jià)值的目標(biāo)檢測論文。
A Hierarchical Graph Network for 3D Object Detection on Point Clouds
HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection
Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud
Camouflaged Object Detection
Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
D2Det: Towards High-Quality Object Detection and Instance Segmentation
1. A Hierarchical Graph Network for 3D Object Detection on Point Clouds
論文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Chen_A_Hierarchical_Graph_Network_for_3D_Object_Detection_on_Point_CVPR_2020_paper.pdf?這項(xiàng)研究提出了一種基于圖卷積 (GConv) 的新型層次圖網(wǎng)絡(luò) (HGNet),它用于三維目標(biāo)檢測任務(wù),可直接處理原始點(diǎn)云進(jìn)而預(yù)測三維邊界框。HGNet 能夠有效捕獲點(diǎn)之間的關(guān)系,并利用多級語義進(jìn)行目標(biāo)檢測。具體而言,該研究提出了新的 shape-attentive GConv (SA-GConv),它能通過建模點(diǎn)的相對幾何位置來描述物體的形狀,進(jìn)而捕獲局部形狀特征。基于 SA-GConv 的 U 形網(wǎng)絡(luò)捕獲多層次特征,通過改進(jìn)的投票模塊(voting module)將這些特征映射到相同的特征空間中,進(jìn)而生成候選框(proposal)。該研究提出的模型主要以 VoteNet 作為 backbone,并基于它提出了一系列改進(jìn)。由下圖可以看出:將 VoteNet 中的 PointNet++ 換成特征捕捉能力更強(qiáng)的 GCN;
為 up-sample 的多層中的每一層都接上 voting 模塊,整合多個(gè)尺度的特征;
在 proposal 之間也使用 GCN 來增強(qiáng)特征的學(xué)習(xí)能力。
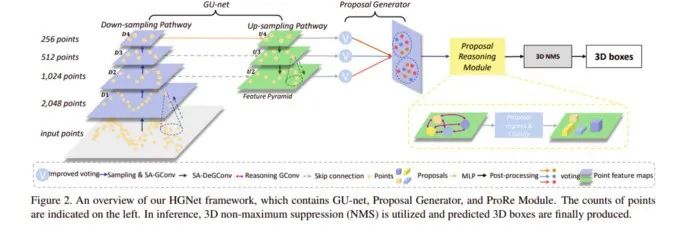
本文提出了 Shape-attentive Graph Convolutions(SA-GConv),并且將這個(gè)卷積同時(shí)用在了 down-sampling pathway 和 up-sampling pathway 中。本文提出了一個(gè) Proposal Reasoning Module,在 proposal 之間學(xué)習(xí)其特征之間的交互。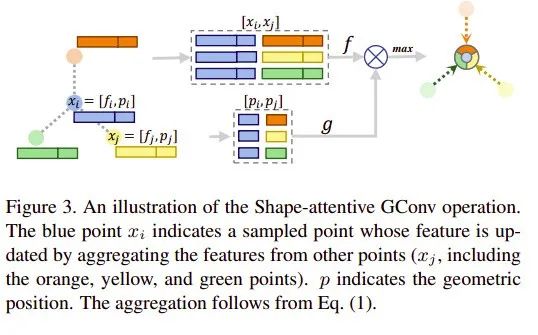
不同模型在 SUN RGB-D V1 數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果如下所示: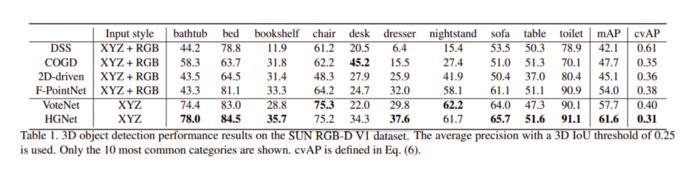
2. HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection
論文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Ye_HVNet_Hybrid_Voxel_Network_for_LiDAR_Based_3D_Object_Detection_CVPR_2020_paper.pdf這篇論文提出了一種基于點(diǎn)云的自動(dòng)駕駛?cè)S目標(biāo)檢測 one-stage 網(wǎng)絡(luò)——混合體素網(wǎng)絡(luò) (Hybrid Voxel Network, HVNet),通過在點(diǎn)級別上混合不同尺度的體素特征編碼器 (VFE) 得到更好的體素特征編碼方法,從而在速度和精度上得到提升。
HVNet 采用的體素特征編碼(VFE)方法包括以下三個(gè)步驟:體素化:將點(diǎn)云指定給二維體素網(wǎng)格;
體素特征提取:計(jì)算網(wǎng)格相關(guān)的點(diǎn)級特征,然后將其輸入到 PointNet 風(fēng)格特征編碼器;
投影:將點(diǎn)級特征聚合為體素級特征,并投影到其原始網(wǎng)格。這就形成了一個(gè)偽圖像特征圖。

該研究提出的 HVNet 架構(gòu)包括:HVFE 混合體素特征提取模塊;2D 卷積模塊;以及檢測模塊,用來輸出最后的預(yù)測結(jié)果。
HVNet 整體架構(gòu)及 HVFE 架構(gòu)參見下圖:
不同模型在 KITTI 數(shù)據(jù)集上獲得的結(jié)果如下表所示: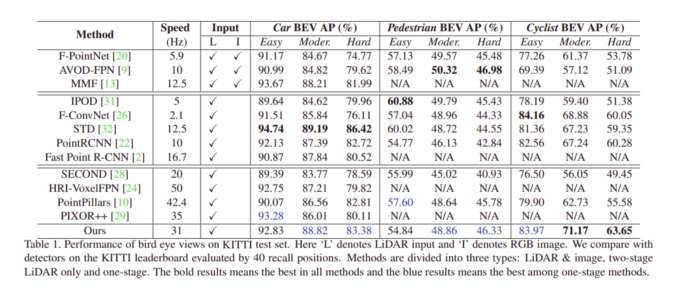
3. Point-GNN: Graph Neural Network for 3D Object Detection in a Point Cloud
基于點(diǎn)云的 3D 目標(biāo)檢測具有非常重要的應(yīng)用價(jià)值,尤其是在自動(dòng)駕駛領(lǐng)域。使用激光雷達(dá)傳感器獲得的 3D 點(diǎn)云數(shù)據(jù)描述了周圍環(huán)境,使得 3D 目標(biāo)檢測能夠比單純使用 RBG 攝像頭提供更多的目標(biāo)信息(不僅有位置信息,還有距離信息)。該研究指出,以往使用 CNN 的方法處理點(diǎn)云數(shù)據(jù)時(shí)往往需要在空間劃分 Grids,會(huì)出現(xiàn)大量的空白矩陣元素,并不適合稀疏點(diǎn)云;近來出現(xiàn)的類似 PointNet 的方法對點(diǎn)云數(shù)據(jù)進(jìn)行分組和采樣,取得了不錯(cuò)的結(jié)果,但計(jì)算成本太大。于是該研究提出一種新型 GNN 網(wǎng)絡(luò)——Point-GNN。Point-GNN 方法主要分為三個(gè)階段,如下圖所示:
以下是不同模型在 KITTI 數(shù)據(jù)集上獲得的結(jié)果: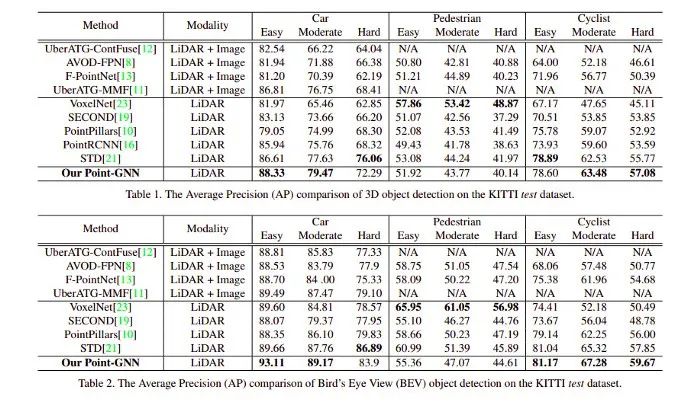
4. Camouflaged Object Detection
這篇論文解決的問題是:如何檢測嵌入在周圍環(huán)境中的物體,即偽裝目標(biāo)檢測(camouflaged object detection,COD)。?此外,該研究還創(chuàng)建了一個(gè)名為 COD10K 的新型數(shù)據(jù)集。它包含 10,000 張圖像,涵蓋許多自然場景中的偽裝物體。該數(shù)據(jù)集具有 78 個(gè)類別,每張圖像均具備類別標(biāo)簽、邊界框、實(shí)例級標(biāo)簽和摳圖級(matting-level)標(biāo)簽。下圖展示了 COD10K 數(shù)據(jù)集中的樣本示例及其難點(diǎn)。

為了解決偽裝目標(biāo)檢測問題,該研究提出了一種叫做搜索識別網(wǎng)絡(luò)(Search Identification Network,SINet)的 COD 框架。該網(wǎng)絡(luò)有兩個(gè)主要模塊:搜索模塊(SM),用于搜索偽裝的物體;
識別模塊(IM),用于檢測該物體。

不同模型在多個(gè)數(shù)據(jù)集上的結(jié)果參見下表:
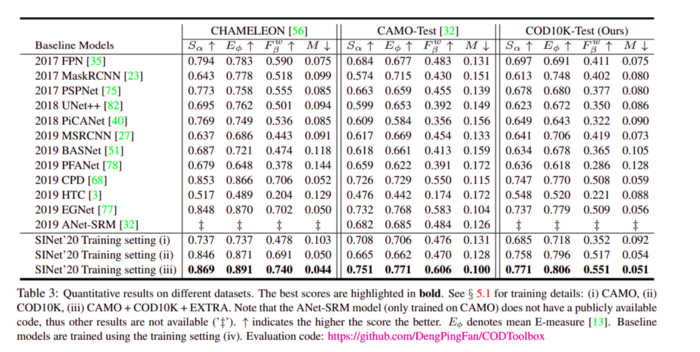
5.?Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector
論文地址:https://openaccess.thecvf.com/content_CVPR_2020/papers/Fan_Few-Shot_Object_Detection_With_Attention-RPN_and_Multi-Relation_Detector_CVPR_2020_paper.pdf傳統(tǒng)的目標(biāo)檢測算法需要大量數(shù)據(jù)標(biāo)注才能訓(xùn)練模型,而數(shù)據(jù)標(biāo)注不但耗費(fèi)人力,可能還會(huì)因?yàn)闃?biāo)注質(zhì)量而影響訓(xùn)練效果。這篇論文提出了一種「小樣本」目標(biāo)檢測網(wǎng)絡(luò),旨在通過少量標(biāo)注數(shù)據(jù)使模型有效檢測到從未見過的目標(biāo)。該方法的核心包括三點(diǎn):Attention-RPN、Multi-Relation Detector 和 Contrastive Training strategy,利用小樣本 support set 和 query set 的相似性來檢測新的目標(biāo),同時(shí)抑制 background 中的錯(cuò)誤檢測。該團(tuán)隊(duì)還貢獻(xiàn)了一個(gè)新的數(shù)據(jù)集,該數(shù)據(jù)集包含 1000 個(gè)類別,且具備高質(zhì)量的標(biāo)注。該研究提出一個(gè)新型注意力網(wǎng)絡(luò),能在 RPN 模塊和檢測器上學(xué)習(xí) support set 和 query set 之間的匹配關(guān)系;下圖中的 weight shared network 有多個(gè)分支,可以分為兩類,一類用于 query set,另一類用于 support set(support set 的分支可以有多個(gè),用來輸入不同的 support 圖像,圖中只畫了一個(gè)),處理 query set 的分支是 Faster RCNN 網(wǎng)絡(luò)。
該研究提出的網(wǎng)絡(luò)架構(gòu)。
作者還提出用 Attention RPN 來過濾掉不屬于 support set 的目標(biāo)。
以下是不同模型在 ImageNet 數(shù)據(jù)集上的實(shí)驗(yàn)結(jié)果:
以下是基于一些數(shù)據(jù)集得到的觀察結(jié)果:

6.?D2Det: Towards High-Quality Object Detection and Instance Segmentation
論文地址:?https://openaccess.thecvf.com/content_CVPR_2020/papers/Cao_D2Det_Towards_High_Quality_Object_Detection_and_Instance_Segmentation_CVPR_2020_paper.pdf?
項(xiàng)目地址:https://github.com/JialeCao001/D2Det
這篇論文提出了一種提高定位精度和分類準(zhǔn)確率的方法 D2Det,以提升目標(biāo)檢測的效果。針對這兩項(xiàng)挑戰(zhàn),該研究分別提出了 dense local regression(DLR)和 discriminative RoI pooling(DRP)兩個(gè)模塊。其中 DLR 與 anchor-free 方法 FCOS 的 detect loss 類似,DRP 則是利用了 deformable convolution 的思想,分別從第一階段和第二階段提取準(zhǔn)確的目標(biāo)特征區(qū)域,進(jìn)而獲得相應(yīng)的性能提升。具體方法流程如下圖所示: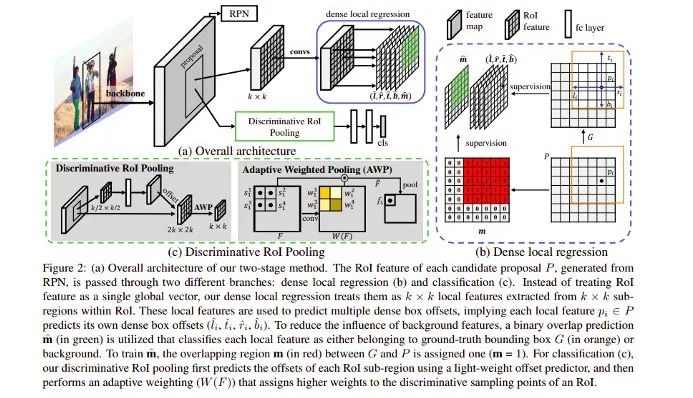
在這兩個(gè)階段中,第一階段采用區(qū)域建議網(wǎng)絡(luò)(RPN),而第二階段采用分類和回歸的方法,分類方法基于池化,局部回歸則用于物體的定位。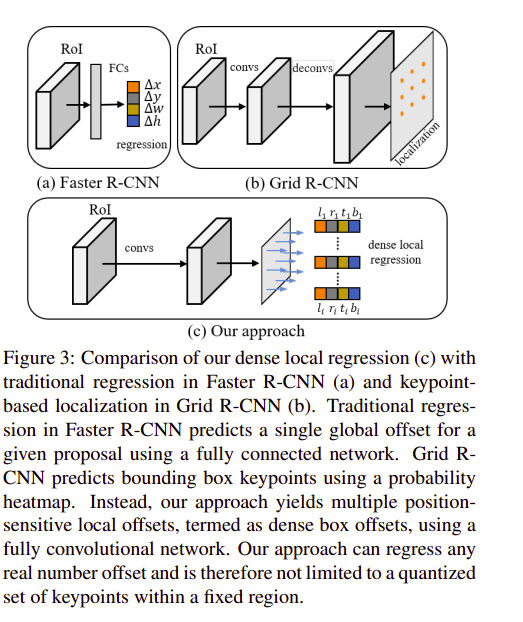
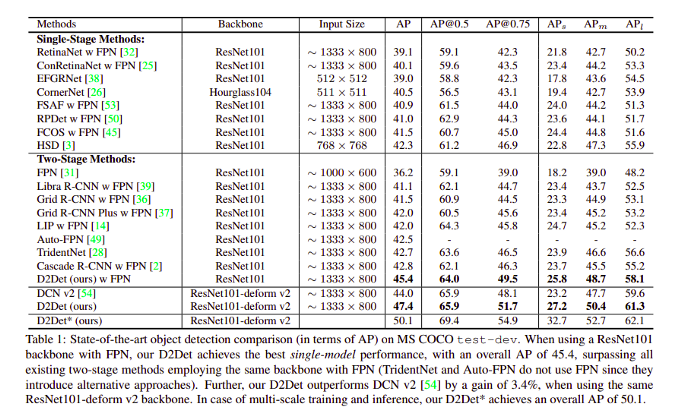
以下是不同模型在 MS COCO 數(shù)據(jù)集上的結(jié)果:
計(jì)算機(jī)視覺頂會(huì) CVPR 2020 提供了很多目標(biāo)檢測等領(lǐng)域的研究論文,如果你想獲取更多論文信息,請點(diǎn)擊以下網(wǎng)址:https://openaccess.thecvf.com/CVPR2020。最后的最后求一波分享!
YOLOv4 trick相關(guān)論文已經(jīng)下載并放在公眾號后臺
關(guān)注“AI算法與圖像處理”,回復(fù) “200714”獲取
請注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
