
視頻目標(biāo)檢測(cè)大盤點(diǎn)

極市導(dǎo)讀
?基于視頻的目標(biāo)檢測(cè)與普通的圖片目標(biāo)檢測(cè)任務(wù)一樣,但視頻的目標(biāo)檢測(cè)有更多的難點(diǎn)和更高的要求。為了便于大家的學(xué)習(xí),本文分點(diǎn)講述了視頻目標(biāo)檢測(cè)的七個(gè)方法,每種方法都附有相關(guān)論文鏈接以及方法的性能結(jié)果。>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺(jué)的最前沿
視頻目標(biāo)識(shí)別是自主駕駛感知、監(jiān)控、可穿戴設(shè)備和物聯(lián)網(wǎng)等應(yīng)用的一項(xiàng)重要任務(wù)。由于圖像模糊、遮擋或不尋常的目標(biāo)姿態(tài),使用視頻數(shù)據(jù)進(jìn)行目標(biāo)識(shí)別比使用靜止圖像更具挑戰(zhàn)性。因?yàn)槟繕?biāo)的外觀可能在某些幀中惡化,通常使用其他幀的特征或檢測(cè)來(lái)增強(qiáng)預(yù)測(cè)效果。解決這一問(wèn)題的方法有很多: 如動(dòng)態(tài)規(guī)劃、跟蹤、循環(huán)神經(jīng)網(wǎng)絡(luò)、有/無(wú)光流的特征聚合以跨幀傳播高層特征。有些方法采用稀疏方式進(jìn)行檢測(cè)或特征聚合,從而大大提高推理速度。主流的多幀無(wú)光流特征聚合和 Seq-NMS 后處理結(jié)合精度最高,但速度較慢(GPU 上小于10 FPS)。在準(zhǔn)確率和速度之間需要權(quán)衡: 通常更快的方法準(zhǔn)確率較低。所以研究兼具準(zhǔn)確率和速度的新方法仍然有很大潛力。
視頻目標(biāo)檢測(cè)的方法
后處理(Post-Processing) 基于跟蹤的方法(Tracking-based Methods) 3D卷積(3D Convolutions) 循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks) 特征傳播方法(Feature Propagation Methods) 基于光流的多幀特征聚合(Multi-frame Feature Aggregation with Optical Flow) 無(wú)光流的多幀特征聚合(Multi-frame Feature Aggregation without Optical Flow)
后處理(Post-Processing)
后處理方法是通用的過(guò)程,可以應(yīng)用于任何目標(biāo)檢測(cè)器的輸出,以改善視頻中的目標(biāo)檢測(cè)。
序列非極大抑制(Seq-NMS)
論文地址: https://arxiv.org/abs/1602.08465
Seq-NMS 基于“軌跡”上其他檢測(cè)通過(guò)動(dòng)態(tài)規(guī)劃對(duì)檢測(cè)置信度進(jìn)行修正。在同一視頻段它使用附近幀高得分的目標(biāo)檢測(cè)來(lái)提高分?jǐn)?shù)較低的檢測(cè)。Seq-NMS 后處理使幀間錯(cuò)誤檢測(cè)或隨機(jī)跳躍檢測(cè)的數(shù)量大大減少,輸出結(jié)果穩(wěn)定,但顯著降低了計(jì)算速度。此外,推理變?yōu)殡x線(該方法需要對(duì)未來(lái)的幀進(jìn)行處理)。性能結(jié)果, FGFA(RFCN,ResNet101):76.3 MAP,1.4 FPS;FGFA(RFCN,ResNet101) + Seq-NMS:78.4 MAP,1.1 FPS。
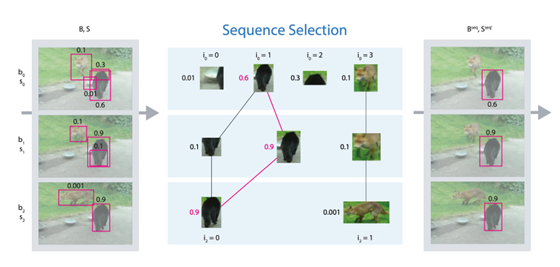
序列框匹配(Seq-Bbox Matching)
論文地址:https://www.researchgate.net/publication/331783655_Improving_Video_Object_Detection_by_Seq-Bbox_Matching
由于相鄰幀是相似的,通常包含一定數(shù)量的運(yùn)動(dòng)目標(biāo),多個(gè)相鄰幀的檢測(cè)結(jié)果被認(rèn)為是同一個(gè)目標(biāo)的多個(gè)檢測(cè)結(jié)果(tubulet)。匹配一個(gè) tubulet 的最后一個(gè)邊界框和另一個(gè) tubulet 的第一個(gè)邊界框。對(duì)同一個(gè) tubulet 的邊界框通過(guò)平均分類得分進(jìn)行重新評(píng)分。Tubelet 級(jí)邊界框鏈接有助于推理漏檢和提高檢測(cè)召回率。當(dāng)稀疏地應(yīng)用于視頻幀時(shí),該方法顯著地改善了目標(biāo)檢測(cè)器的檢測(cè)結(jié)果,同時(shí)提高了速度。性能結(jié)果, YOLOv3: 68.6 MAP,23 FPS;YOLOv3 + 序列框匹配:?78.2/80.9(在線/離線) MAP,38 FPS。
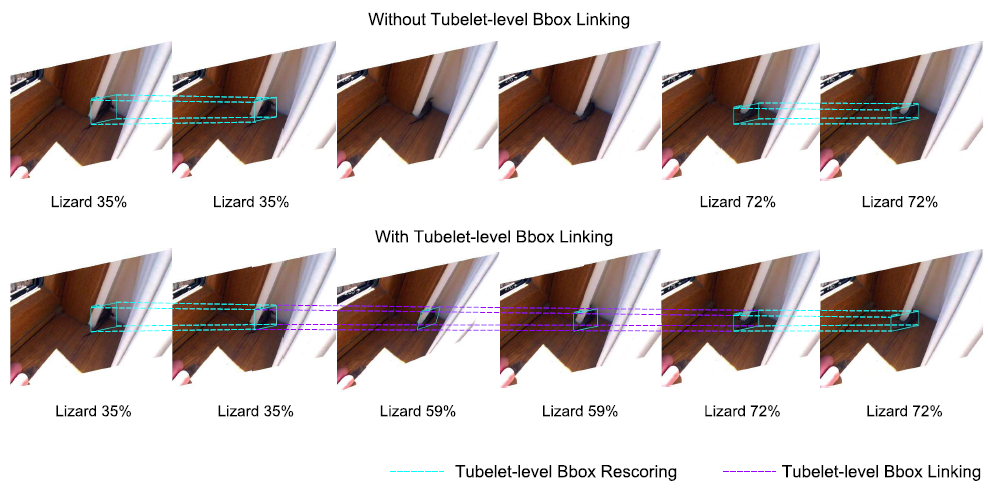
魯棒高效的后處理(REPP / Robust and Efficient Post-Processing)
論文地址:https://arxiv.org/abs/2009.11050
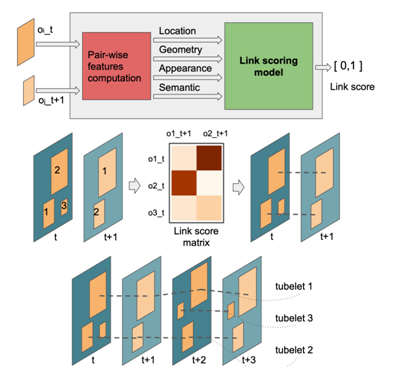
REPP 通過(guò)評(píng)估幀之間的檢測(cè)的相似度來(lái)鏈接檢測(cè),并改進(jìn)它們的分類和定位以抑制假陽(yáng)性和恢復(fù)漏檢。對(duì)于來(lái)自連續(xù)幀(t 和 t + 1)的所有可能的檢測(cè)對(duì),基于它們的位置、幾何、外觀和語(yǔ)義構(gòu)建一組特征。這些特征被用來(lái)預(yù)測(cè)鏈接(相似性)評(píng)分。鏈接在連續(xù)的幀之間建立,tubelet在第一對(duì)幀之間組成,并且只要在下一個(gè)幀中仍然能夠找到相應(yīng)的目標(biāo),tubelet就會(huì)被擴(kuò)展。REPP 計(jì)算開(kāi)銷很小,但是推理變?yōu)殡x線。性能結(jié)果: YOLOv3:68.6 MAP,23 FPS;YOLOv3 + REPP:?75.1 MAP,22 FPS。
基于跟蹤的方法(Tracking-based Methods)
通過(guò)軌跡條件檢測(cè)集成目標(biāo)檢測(cè)和跟蹤(Integrated Object Detection and Tracking with Tracklet-Conditioned Detection)
論文地址:https://arxiv.org/abs/1811.11167
軌跡條件(Tracklet-Conditioned)檢測(cè)網(wǎng)絡(luò)在早期階段將檢測(cè)和跟蹤結(jié)合在一起: 不再簡(jiǎn)單地將檢測(cè)器和跟蹤器分別估計(jì)的兩組邊界框聚合在一起,而是通過(guò)基于目標(biāo)檢測(cè)器的輸出,在先前幀計(jì)算的軌跡上生成一組單獨(dú)的邊界框。這樣,產(chǎn)生的檢測(cè)框既與軌跡一致,又具有高檢測(cè)響應(yīng),而不是像后期集成技術(shù)中只能選兩個(gè)中的一個(gè)。該模型(使用 R-FCN ResNet101 主干)在 imageenet VID 上在線設(shè)置中實(shí)現(xiàn)了83.5 MAP。

3D卷積(3D Convolutions)
帶有 3D 卷積的卷積神經(jīng)網(wǎng)絡(luò)在處理如 MRI 等 3D 圖像時(shí)已經(jīng)被證明是非常有用和卓有成效的。與單幀相比,視頻中目標(biāo)檢測(cè)應(yīng)用 3D 卷積并沒(méi)有明顯性能提升。
循環(huán)神經(jīng)網(wǎng)絡(luò)(Recurrent Neural Networks)
帶有時(shí)間感知特征圖的移動(dòng)視頻目標(biāo)檢測(cè)(Mobile Video Object Detection with Temporally-Aware Feature Maps)
論文地址:http://openaccess.thecvf.com/content_cvpr_2018/papers/Liu_Mobile_Video_Object_CVPR_2018_paper.pdf
該模型將快速的單圖像目標(biāo)檢測(cè)和卷積 LSTM 層結(jié)合起來(lái),創(chuàng)建了一個(gè)交織的循環(huán)卷積結(jié)構(gòu)。一個(gè)高效的瓶頸 LSTM 層相比常規(guī) LSTM 顯著降低了計(jì)算成本。該模型在線運(yùn)行,可在低功耗移動(dòng)設(shè)備和嵌入式設(shè)備上實(shí)時(shí)運(yùn)行,在移動(dòng)設(shè)備上實(shí)現(xiàn)了45.1 MAP,14.6 FPS。
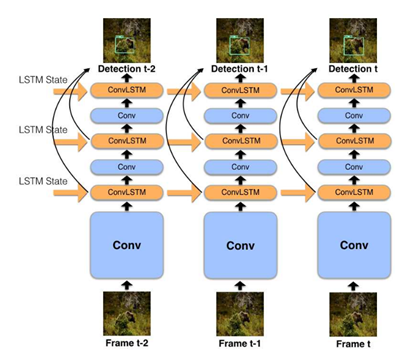
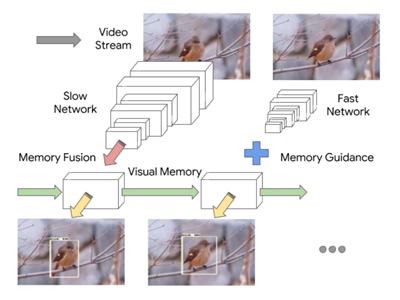
搜尋快和慢: 記憶導(dǎo)向的移動(dòng)視頻目標(biāo)檢測(cè)(Looking Fast and Slow: Memory-Guided Mobile Video Object Detection)
論文地址:https://arxiv.org/pdf/1903.10172.pdf
該模型包含兩個(gè)不同速度和識(shí)別能力的特征提取器,分別運(yùn)行在不同的幀上。這些提取器得到的特征以卷積 LSTM 的形式保持場(chǎng)景的共同視覺(jué)記憶,通過(guò)融合前一幀的上下文和當(dāng)前幀的要點(diǎn)(一種豐富的表示)來(lái)檢測(cè)。記憶和要點(diǎn)的組合包含了決定什么時(shí)候更新記憶所必需的信息。該模型是在線的,在移動(dòng)設(shè)備上以72.3 FPS?運(yùn)行,達(dá)到59.1 MAP。
特征傳播方法(Feature Propagation Methods)
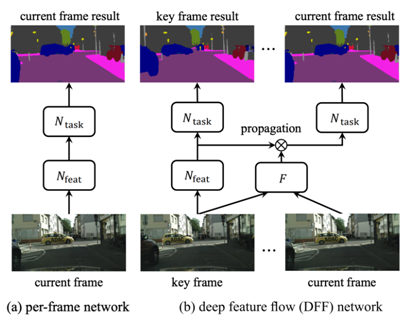
用于視頻識(shí)別的深度特征流(DFF / Deep Feature Flow for Video Recognition)
論文地址:https://arxiv.org/abs/1611.07715
光流(Optical flow)是目前利用視頻目標(biāo)檢測(cè)時(shí)間維度的研究最多的領(lǐng)域。DFF 只在稀疏關(guān)鍵幀上運(yùn)行昂貴的卷積子網(wǎng),并通過(guò)流場(chǎng)將其深度特征圖傳播到其他幀。pipeline 函數(shù)是 n 幀的循環(huán)。第一幀叫做關(guān)鍵幀。這是使用目標(biāo)檢測(cè)器檢測(cè)的幀。在得到下一個(gè) n-1 幀的光流后,下一個(gè) n-1 幀的檢測(cè)就是已知的了,并且周期性重復(fù)。由于流計(jì)算速度相對(duì)較快,DFF 可以顯著提高速度。該模型(使用 R-FCN ResNet101 主干)在 ImageNet VID 上在線模式得到73 MAP,29 FPS。
基于光流的多幀特征聚合(Multi-frame Feature Aggregation with Optical Flow)
提高視頻檢測(cè)精度的一種方法是多幀特征融合。有不同的實(shí)現(xiàn)方法,但所有方法都圍繞著一個(gè)思想: 密集計(jì)算每幀檢測(cè),同時(shí)特征從相鄰幀向當(dāng)前幀變換,加權(quán)平均聚合。因此,當(dāng)前幀將受益于之前幀,以及一些未來(lái)的幀,以獲得更好的檢測(cè)。這種方式可以解決視頻幀的運(yùn)動(dòng)和目標(biāo)裁剪問(wèn)題。
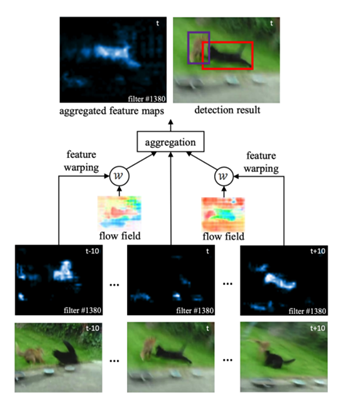
視頻目標(biāo)檢測(cè)基于流引導(dǎo)的特征聚合(FGFA / Flow-Guided Feature Aggregation for Video Object Detection)
論文地址:https://arxiv.org/abs/1703.10025
流引導(dǎo)的特征聚合使用光流聚合附近幀的特征圖,附近幀通過(guò)估計(jì)流對(duì)齊得很好。結(jié)構(gòu)是一個(gè)端到端的框架,它利用了特性層面上的時(shí)間一致性。FGFA(R-FCN ResNet101 主干) 在 ImageNet VID 上在線模式達(dá)到了76.3 MAP,1.4 FPS。
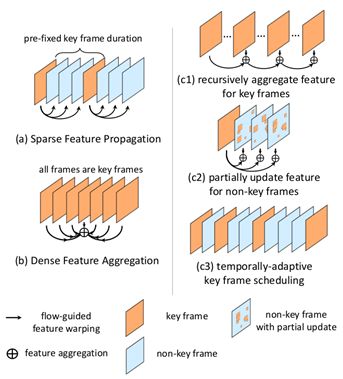
邁向高性能視頻目標(biāo)檢測(cè)(THP / Towards High Performance Video Object Detection)
論文地址:https://arxiv.org/abs/1711.11577
THP 采用統(tǒng)一的方法,基于多幀特征端到端學(xué)習(xí)和交叉幀運(yùn)動(dòng)原則。該算法采用光流和稀疏遞歸特征聚合的方法保持聚合后的特征質(zhì)量。此外,它通過(guò)只在稀疏關(guān)鍵幀上操作來(lái)減少計(jì)算量。在傳播的特征質(zhì)量較差的情況下,采用空間自適應(yīng)部分特征更新算法對(duì)非關(guān)鍵幀進(jìn)行特征重計(jì)算。在端到端訓(xùn)練中學(xué)習(xí)特征質(zhì)量,進(jìn)一步提高識(shí)別準(zhǔn)確率。時(shí)間自適應(yīng)關(guān)鍵幀調(diào)度算法根據(jù)預(yù)測(cè)的特征質(zhì)量預(yù)測(cè)關(guān)鍵幀的使用情況,從而提高關(guān)鍵幀的使用效率。THP(R-FCN Deformable ResNet101 主干) 在ImageNet VID 在線模式達(dá)到了77.8 MAP,22.9 FPS。
無(wú)光流的多幀特征聚合(Multi-frame Feature Aggregation without Optical Flow)
視頻目標(biāo)檢測(cè)記憶增強(qiáng)的全局-本地聚合(MEGA / Memory Enhanced Global-Local Aggregation for Video Object Detection)
論文地址:https://arxiv.org/abs/2003.12063
MEGA 通過(guò)有效地整合全局和局部信息,增強(qiáng)了關(guān)鍵幀的候選框特征。該算法重用了在檢測(cè)前幀過(guò)程中獲得的預(yù)計(jì)算特征,這些特征通過(guò)全局信息增強(qiáng),并緩存在遠(yuǎn)程記憶模塊中。這就是當(dāng)前幀和以前幀之間循環(huán)連接的構(gòu)建方式。MEGA(使用 R-FCN ressnet101 主干)在 ImageNet VID上達(dá)到了82.9 MAP,8.7 FPS;?具有 Seq-NMS 和 R-FCN ResNeXt101 主干的 MEGA 可以達(dá)到85.4 MAP。

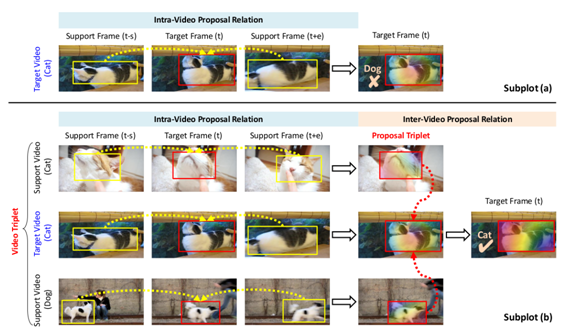
為視頻目標(biāo)檢測(cè)挖掘視頻間提議關(guān)系(HVRNet / Mining Inter-Video Proposal Relations for Video Object Detection)
論文地址:https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/3764_ECCV_2020_paper.php
HVR-Net 通過(guò)在一個(gè)多層次的三元組選擇方案中利用視頻內(nèi)部和視頻間上下文增強(qiáng)視頻目標(biāo)檢測(cè)。根據(jù) CNN 特征的余弦相似度,這個(gè)三元組包括一個(gè)目標(biāo)視頻,同一類別中最不相似的視頻,以及不同類別中最相似的視頻。對(duì)于三元組中每個(gè)視頻,它的采樣幀被輸入到 Faster RCNN 的 RPN 和 ROI 層。這為每幀生成了目標(biāo)提議(proposal)的特征向量,這些特征向量聚合在一起以增強(qiáng)目標(biāo)幀中的提議。視頻內(nèi)部增強(qiáng)的提議主要包含每個(gè)視頻中的目標(biāo)語(yǔ)義,而忽略視頻之間的目標(biāo)變化。為了建立這種變化的模型,根據(jù)內(nèi)部視頻增強(qiáng)的特征,從視頻三元組中選擇難的提議三元組。對(duì)于每個(gè)提議三元組,來(lái)自支持視頻的提議將被聚合,以提高目標(biāo)視頻中提議的質(zhì)量。每個(gè)提議特征進(jìn)一步利用視頻間的依賴性,以解決視頻中的目標(biāo)混淆。HVRNet (使用 R-FCN ResNet101 主干) 在 ImageNet VID上可以達(dá)到83.2 MAP;?擁有 Seq-NMS 和 R-FCN ResNeXt101 主干的 HVRNet 可以得到 state-of-the-art?85.5 MAP。
比較表
mAP @0.5 on Imagenet VID
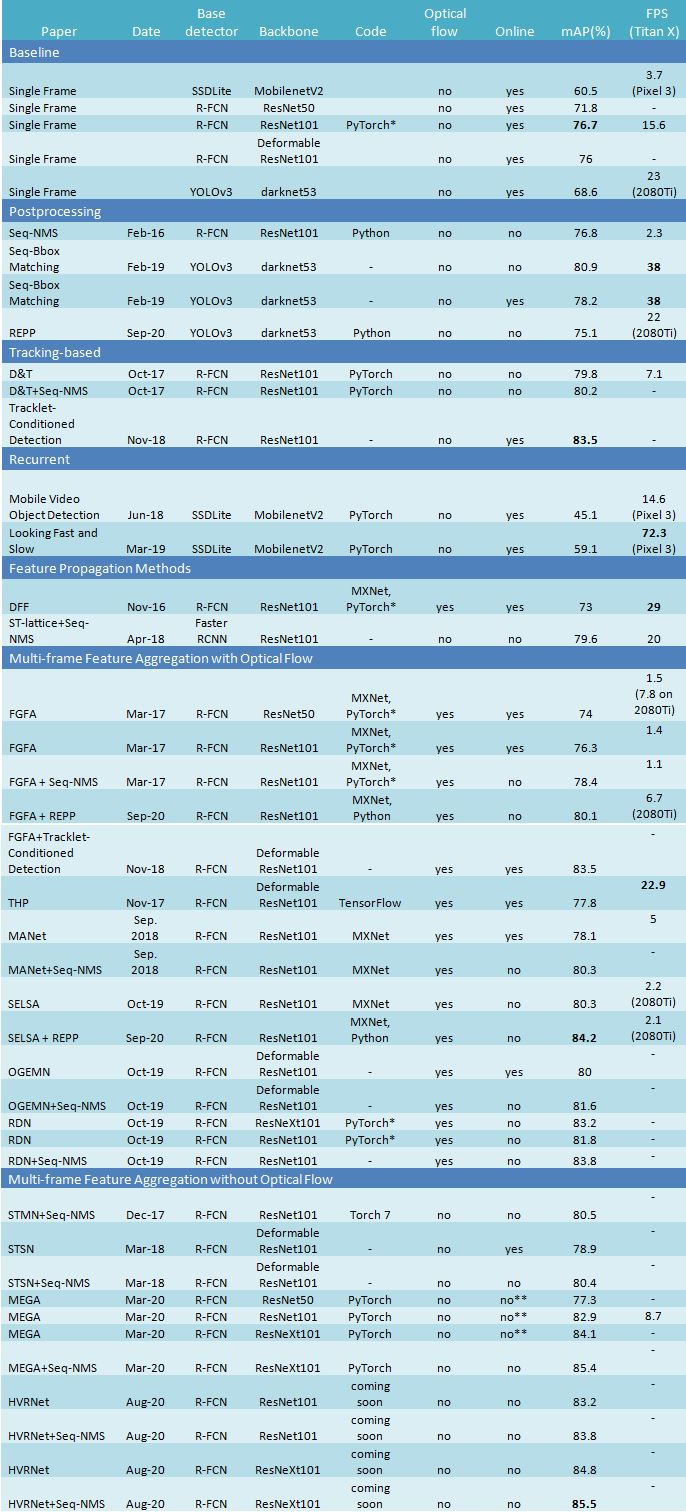
* 在 MEGA 項(xiàng)目?jī)?nèi)的實(shí)現(xiàn)
** 該方法通過(guò)一些小的改動(dòng)可以在線運(yùn)行
參考資料
Seq-NMS: https://arxiv.org/abs/1602.08465 (Python 源碼:https://github.com/lrghust/Seq-NMS) Seq-Bbox Matching: https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&ved=2ahUKEwjWwNWa95_iAhUMyoUKHR-GAJwQFjABegQIBBAC&url=http%3A%2F%2Fwww.insticc.org%2FPrimoris%2FResources%2FPaperPdf.ashx%3FidPaper%3D72600&usg=AOvVaw1dTqzUoybpNRVkCdkA1xg0 REPP: https://arxiv.org/abs/2009.11050 (Python 源碼:https://github.com/AlbertoSabater/Robust-and-efficient-post-processing-for-video-object-detection) D&T: https://arxiv.org/abs/1710.03958 (PyTorch 源碼:https://github.com/Feynman27/pytorch-detect-to-track) Tracklet-Conditioned Detection: https://arxiv.org/abs/1811.11167 Mobile Video Object Detection: https://arxiv.org/abs/1711.06368 (PyTorch 源碼:https://github.com/vikrant7/mobile-vod-bottleneck-lstm) Looking Fast and Slow: https://arxiv.org/abs/1903.10172 (PyTorch 源碼:https://github.com/vikrant7/pytorch-looking-fast-and-slow) ST-lattice: https://arxiv.org/abs/1804.05472 FGFA: https://arxiv.org/abs/1703.10025 (MXNet 源碼:https://github.com/msracver/Flow-Guided-Feature-Aggregation, PyTorch* ?源碼:https://github.com/Scalsol/mega.pytorch) THP: https://arxiv.org/abs/1711.11577 (TensorFlow ?源碼:https://github.com/stanlee321/LightFlow-TensorFlow) MANet: http://openaccess.thecvf.com/content_ECCV_2018/html/Shiyao_Wang_Fully_Motion-Aware_Network_ECCV_2018_paper.html (MXNet 源碼:https://github.com/wangshy31/MANet_for_Video_Object_Detection) SELSA: https://arxiv.org/abs/1907.06390 (MXNet 源碼:https://github.com/happywu/Sequence-Level-Semantics-Aggregation) OGEMN: https://www.semanticscholar.org/paper/Object-Guided-External-Memory-Network-for-Video-Deng-Hua/d998d202fde50839b0bc3bbdc4324e3054b87919 RDN: https://arxiv.org/abs/1908.09511 (PyTorch* ?源碼:https://github.com/Scalsol/mega.pytorch) STMN: https://arxiv.org/abs/1712.06317 (Torch 7 ?源碼:http://fanyix.cs.ucdavis.edu/project/stmn/project.html) STSN: https://arxiv.org/abs/1803.05549 MEGA: https://arxiv.org/abs/2003.12063 (PyTorch ?源碼:https://github.com/Scalsol/mega.pytorch) HVRNet: https://www.ecva.net/papers/eccv_2020/papers_ECCV/html/3764_ECCV_2020_paper.php (即將開(kāi)源: https://github.com/youthHan/HVRNet)
來(lái)源:
https://blog.usejournal.com/the-ultimate-guide-to-video-object-detection-2ecf9459f180
推薦閱讀
