
爬蟲 | urllib入門+糗事百科實戰(zhàn)

Urllib庫是python內(nèi)置的一個爬蟲庫,現(xiàn)在常用的有requests,它是對urllib進行了進一步的封裝,今天先從urllib入手,后續(xù)再聊requests等的使用。根據(jù)我的風格來說,當然是有實際操作大家更容易理解,所以說,本文仍然是從代碼入手,帶你實現(xiàn)第一個爬蟲小栗子。
官方的介紹如下:
urllib is a package that collects several modules for working with URLs:
urllib.requestfor opening and reading URLsurllib.errorcontaining the exceptions raised byurllib.requesturllib.parsefor parsing URLsurllib.robotparserfor parsingrobots.txtfiles
上面的四塊其實很容易理解,分別是請求內(nèi)容、異常處理、URL解析以及robot協(xié)議解析。不過今天不介紹那么多,有疑問的話可以自行查詢相應(yīng)的內(nèi)容,今天的任務(wù)是入門,以及實現(xiàn)一個小爬蟲。
# 導(dǎo)入請求庫
import urllib.request
# 向指定的url地址發(fā)送請求并返回服務(wù)器響應(yīng)的數(shù)據(jù)(文件的對象)
response = urllib.request.urlopen("http://www.baidu.com")
# 讀取文件的全部內(nèi)容,會把讀到的東西賦值給一個字符串變量
data = response.read()簡單三行代碼就得到了我們所要的內(nèi)容,可以查看一下data中的信息,其實這就形成了我們在瀏覽器中看到的內(nèi)容,可以通過瀏覽器頁面F12查看。

response是我們請求百度首頁返回的響應(yīng),可以通過這個響應(yīng)查看這次請求的一些信息。例如:
response.info() 返回當前環(huán)境的一些信息(日期、cookies等)
response.getcode() 返回狀態(tài)碼(200代表正常訪問等)
response.geturl() 返回正在爬取的地址其實獲取到信息,存儲到文件就很方便了,可以參考【python文件操作】,不過在urllib庫中還有一個直接將爬取到的內(nèi)容存到文件的方法。
import urllib.request
urllib.request.urlretrieve("http://www.baidu.com",
filename=r"F:/demo/file.html")
# urlretrieve在執(zhí)行過程中,會產(chǎn)生一些緩存
# 清除緩存
urllib.request.urlcleanup()現(xiàn)在爬蟲發(fā)展的非常快,而爬蟲給網(wǎng)站帶來的壓力也不小,因此,越來越多的網(wǎng)站在研究它的反爬機制。也就是發(fā)現(xiàn)你是一個爬蟲而非人工的訪問,并且對自己的網(wǎng)站造成壓力等,那么就會采取措施,比如禁止你的訪問、封掉你的IP等等。說這些什么意思呢?既然人家不讓爬,那么我們可以偽裝一下,假裝自己是正常訪問。當然這也是不容易的,不過有一些最基本的操作,還是可以輕松理解的。
對于使用python來進行爬蟲,其實是可以直接看到你是一個python爬蟲的,直接告訴人家是個爬蟲,那想禁你還不輕松。因此,首先針對這個問題,可以采用模擬瀏覽器的方式來解決。在發(fā)起請求后,請求頭中包含一個user-agent字段,修改這個內(nèi)容就可以了。
import urllib.request
url = "http://www.baidu.com"
# 模擬請求頭
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36"
}
# 設(shè)置一個請求體
req = urllib.request.Request(url, headers=headers)
# 發(fā)起請求
response = urllib.request.urlopen(req)關(guān)于User-Agent在網(wǎng)上可以找到很多,或者打開自己的瀏覽器,F(xiàn)12->network,隨便點一個網(wǎng)頁找request headers即可。
在爬蟲的過程中難免會遇到請求不到內(nèi)容的情況,當它無法繼續(xù)爬取的時候我們也不能一直和它耗著不是,而且如果是爬蟲期間的某一個地址訪問不到,也不能讓它影響后面的工作,因此,設(shè)置超時是有必要的。操作也很方便,只需要在打開頁面的時候添加個timeout參數(shù)即可。
import urllib.request
# 如果網(wǎng)頁長時間未響應(yīng),系統(tǒng)判斷超時,無法爬取
try:
response = urllib.request.urlopen("http://www.baidu.com", timeout=0.1)
except:
print("time out")主要的HTTP請求有以下幾種,最常用的就是get和post。
GET: 通過url網(wǎng)址傳遞信息,可以直接在url網(wǎng)址上添加要傳遞的信息(不安全) POST: 可以向服務(wù)器提交數(shù)據(jù),是一種比較流行,安全的數(shù)據(jù)傳遞方式
PUT: 請求服務(wù)器存儲一個資源,通常要指定存儲的位置
DELETE: 請求服務(wù)器刪除一個資源
HEAD: 請求獲取對應(yīng)的http報頭信息
OPTIONS: 可以獲取當前url所支持的請求類型
get請求:
特點:把數(shù)據(jù)拼接到請求路徑后面?zhèn)鬟f給服務(wù)器
優(yōu)點:速度快
缺點:承載的數(shù)據(jù)量小,不安全
post請求:
特點:把參數(shù)進行打包,單獨傳輸
優(yōu)點:數(shù)量大,安全(當對服務(wù)器數(shù)據(jù)進行修改時建議使用post)
缺點:速度慢
下面舉個栗子,這就需要用到開始提到的第二個方法parse。
import urllib.request
import urllib.parse # 對請求打包的庫
url = "http://httpbin.org/post"
# 將要發(fā)送的數(shù)據(jù)合成一個字典
data = {
"name": "xiaotian"
}
# 對要發(fā)送的數(shù)據(jù)進行打包
postdata = urllib.parse.urlencode(data).encode("utf-8")
# 請求體
req = urllib.request.Request(url, data=postdata)
# 請求
response = urllib.request.urlopen(req)
print(response.read())
開始寫程序之前,一定要先分析網(wǎng)頁。選取糗事百科的段子來爬一下,網(wǎng)址在這(https://www.qiushibaike.com/text/)。
既然是爬取上面的段子,首先要找到段子對應(yīng)網(wǎng)頁中的什么位置,打開F12(前面一直說F12,其實就是打開網(wǎng)頁的源碼),左上角有個箭頭,可以點擊它,用來快速找到網(wǎng)頁顯示部分與源碼的對應(yīng)。
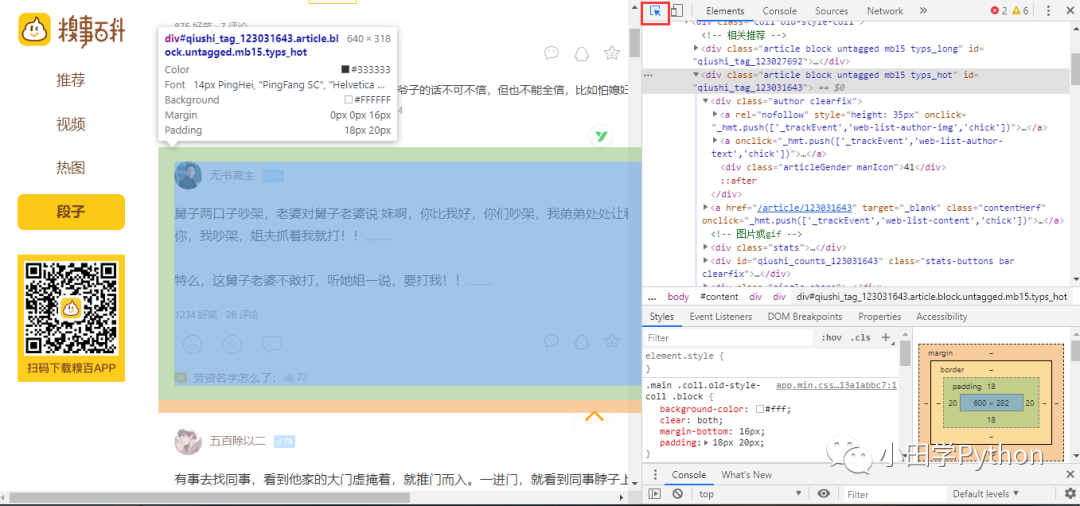
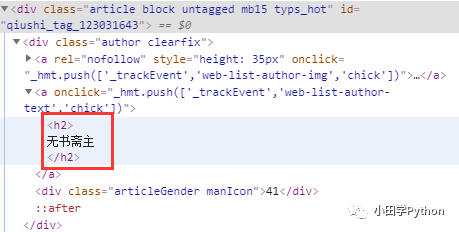
可以看到上方,鼠標所在位置的顏色可以對應(yīng)找到源碼。找到一個段子的源碼,那緊接著就是找我們想要的內(nèi)容,例如發(fā)布段子的用戶名,以及段子的內(nèi)容等。當然,今天的內(nèi)容都是初級的爬蟲,想要的信息都在這樣一個靜態(tài)網(wǎng)頁中,找到如下的內(nèi)容,然后利用正則表達式來提取其中的信息。【正則表達式】

import urllib.request
import re
def jokeCrawler(url):
headers = {
"User-Agent": "Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10"
}
req = urllib.request.Request(url, headers=headers)
response = urllib.request.urlopen(req)
html = response.read().decode("utf-8")
pat = r'<div class="author clearfix">(.*?)<span class="stats-vote"><i class="number">'
re_joke = re.compile(pat, re.S) # re.S 使可以匹配換行
divsList = re_joke.findall(html)
dic = {}
for div in divsList:
# 用戶名
re_u = re.compile(r"<h2>(.*?)</h2>", re.S)
username = re_u.findall(div)
username = username[0].rstrip()
# 段子
re_d = re.compile(r'<div class="content">\n<span>(.*?)</span>', re.S)
duanzi = re_d.findall(div)
duanzi = duanzi[0].strip()
dic[username] = duanzi
return dic
url = "https://www.qiushibaike.com/text/page/1/"
info = jokeCrawler(url)
for k, v in info.items():
print(k + ':\n' + v)
上面我所做的內(nèi)容比較粗糙,可以自行再處理一下正則表達式。這只是爬取了一頁的內(nèi)容,嘗試把URL中的page換個數(shù)字就會發(fā)現(xiàn),可以做到翻頁,假如使用循環(huán),可以爬蟲更多的內(nèi)容,后面就可以自行探索了。