
【機(jī)器學(xué)習(xí)】特征工程:編碼、創(chuàng)造和篩選特征
在機(jī)器學(xué)習(xí)和數(shù)據(jù)科學(xué)領(lǐng)域中,特征工程是提取、轉(zhuǎn)換和選擇原始數(shù)據(jù)以創(chuàng)建更具信息價值的特征的過程。假設(shè)拿到一份數(shù)據(jù)集之后,如何逐步完成特征工程呢?
步驟1:特性類型分析
不同類型的特征包含的信息不同的,首先需要按照賽題字段的說明去對每個字段的類型進(jìn)行區(qū)分。
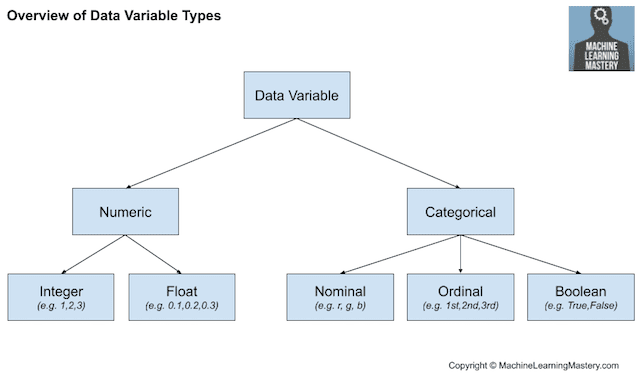
下面是對不同類型的特征進(jìn)行編碼和操作的方法,其中取值特征本身包含的信息較多,因此可以直接考慮進(jìn)行縮放:
-
數(shù)值型特征: -
縮放:將數(shù)值特征縮放到一個范圍,通常使用Min-Max縮放或標(biāo)準(zhǔn)化(z-score)。 -
離散化:將連續(xù)數(shù)值轉(zhuǎn)換為離散類別,例如分箱操作。 -
平滑化:應(yīng)用平滑算法(如指數(shù)平滑)來減少噪聲和波動。 -
派生新特征:通過組合或數(shù)學(xué)運算創(chuàng)建新的數(shù)值型特征。 -
類別型特征: -
標(biāo)簽編碼:將類別映射為整數(shù),常用于樹模型。 -
獨熱編碼:將類別轉(zhuǎn)換成二進(jìn)制向量,適用于線性模型和神經(jīng)網(wǎng)絡(luò)。 -
有序編碼:根據(jù)類別的有序關(guān)系,將其轉(zhuǎn)換成整數(shù)編碼。 -
統(tǒng)計特征:基于類別特征進(jìn)行統(tǒng)計計算,如均值、頻率等。 -
時間型特征: -
提取時間信息:從時間戳中提取年、月、日、小時等信息作為新特征。 -
周期性處理:對于循環(huán)時間特征,可以使用正弦余弦變換將其轉(zhuǎn)換為線性空間。 -
文本型特征: -
詞袋模型:將文本轉(zhuǎn)換為向量表示,如TF-IDF、詞頻等。 -
詞嵌入:使用詞向量將單詞映射到連續(xù)向量空間,如Word2Vec、GloVe。 -
文本長度:記錄文本的長度作為一個特征。 -
圖像型特征: -
預(yù)訓(xùn)練網(wǎng)絡(luò)特征提取:使用預(yù)訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)(如VGG、ResNet)提取圖像特征。 -
圖像直方圖:提取圖像的顏色直方圖作為特征。 -
組合特征: -
特征交叉:將不同特征進(jìn)行交叉組合,創(chuàng)造新的特征。 -
特征合并:將多個特征合并為一個更有意義的特征。
步驟2:找到關(guān)鍵特征
數(shù)據(jù)往往具有大量的特征,而并非所有特征都對目標(biāo)變量有同等重要的影響。為了建立高性能的機(jī)器學(xué)習(xí)模型,我們需要找到關(guān)鍵特征,即對預(yù)測目標(biāo)具有顯著貢獻(xiàn)的特征。

相關(guān)性分析
相關(guān)性是衡量兩個變量之間線性關(guān)系強度的指標(biāo),可以用來發(fā)現(xiàn)特征與目標(biāo)變量之間的關(guān)聯(lián)程度。常用的相關(guān)性計算方法包括皮爾遜相關(guān)系數(shù)和斯皮爾曼等級相關(guān)系數(shù)。通過計算各個特征與目標(biāo)變量之間的相關(guān)性,我們可以找到與目標(biāo)變量強相關(guān)的特征。
樹模型重要性
決策樹和隨機(jī)森林等樹模型可以通過測量特征在樹中分裂中的貢獻(xiàn)度來評估特征的重要性。樹模型重要性的計算方法通常包括特征在樹中分裂的次數(shù)、特征帶來的信息增益或基尼系數(shù)的變化等。
步驟3:對特征進(jìn)行編碼
在將數(shù)據(jù)納入模型之前,還需要對特征進(jìn)行編碼,將原有的特征轉(zhuǎn)換成數(shù)值形式,或者抽取出特征中的信息。
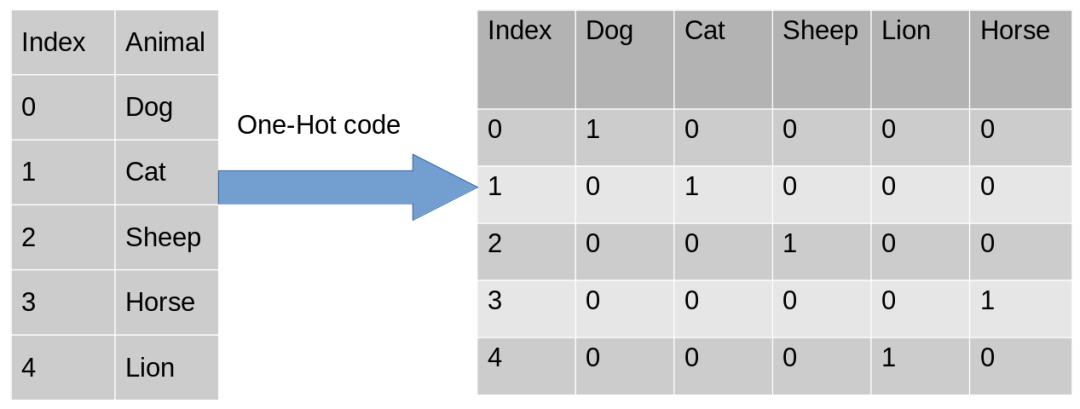
-
特征抽取:某些特征可能含有大量信息,但以原始形式難以表達(dá),特征編碼有助于從中抽取出有用的信息,提高模型的表現(xiàn)。 -
處理類別型數(shù)據(jù):類別型特征常常需要進(jìn)行編碼,以便模型能夠理解并學(xué)習(xí)它們之間的關(guān)系。
類別特征編碼有多種方法可供選擇,常見的包括標(biāo)簽編碼、獨熱編碼、二進(jìn)制編碼等。每種方法都有其優(yōu)勢和限制,因此需要綜合考慮特征的屬性和模型的要求,選擇最適合的編碼方式。在實際應(yīng)用中,我們需要根據(jù)具體情況選擇適合的編碼方法,這需要考慮以下因素:
-
類別特征的性質(zhì): -
若類別特征存在順序關(guān)系,標(biāo)簽編碼可能更合適,以保留類別之間的相對大小關(guān)系。 -
若類別特征之間沒有順序關(guān)系,獨熱編碼或二進(jìn)制編碼可能更為合適,以避免引入錯誤的信息。 -
數(shù)據(jù)集的規(guī)模: -
當(dāng)數(shù)據(jù)集規(guī)模較大時,獨熱編碼可能導(dǎo)致高維度問題,增加計算開銷,可以考慮使用二進(jìn)制編碼或其他降維方法。 -
機(jī)器學(xué)習(xí)算法的要求: -
不同的機(jī)器學(xué)習(xí)算法對特征編碼的要求不同,需要根據(jù)使用的模型類型來選擇合適的編碼方式。
步驟4:構(gòu)建基礎(chǔ)模型
在進(jìn)行特征工程后,下一步是構(gòu)建Baseline(基礎(chǔ)模型),這是機(jī)器學(xué)習(xí)任務(wù)中的重要步驟。Baseline是一個簡單而基礎(chǔ)的模型,用來作為后續(xù)模型優(yōu)化和改進(jìn)的起點。
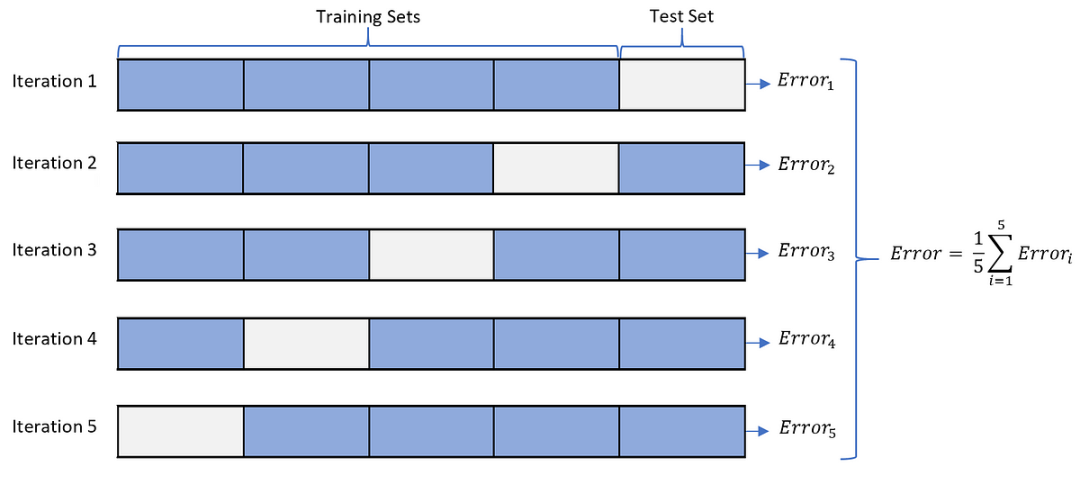
Baseline模型不用過于復(fù)雜,也不需要調(diào)參。只需要能反應(yīng)加入和刪除特征精度有變化即可。
步驟5:構(gòu)造新的特征
在特征工程的過程中,創(chuàng)造性地構(gòu)造新的特征是一個關(guān)鍵步驟。通過構(gòu)造新特征,我們可以進(jìn)一步提取數(shù)據(jù)中的有用信息,增強模型的表達(dá)能力和泛化能力。

-
分組統(tǒng)計特征: -
對數(shù)據(jù)進(jìn)行分組,例如按照類別特征、時間窗口等分組。 -
在每個組內(nèi),計算各種統(tǒng)計量,如平均值、標(biāo)準(zhǔn)差、最大值、最小值等,作為新特征。 -
排序特征: -
對數(shù)據(jù)進(jìn)行排序,例如按照時間順序、數(shù)值大小等排序。 -
可以計算位置特征,如第一個出現(xiàn)、最后一個出現(xiàn),或者計算排序之間的差值等。 -
時間序列特征: -
如果數(shù)據(jù)具有時間性質(zhì),可以提取時間序列特征。 -
如計算滾動平均、滾動標(biāo)準(zhǔn)差、時間差分等。 -
統(tǒng)計特征: -
利用歷史信息計算統(tǒng)計特征,如過去一段時間內(nèi)的均值、方差等。 -
這些統(tǒng)計特征可以反映數(shù)據(jù)的動態(tài)變化和趨勢。 -
組合特征: -
將不同特征進(jìn)行組合,創(chuàng)建新的特征。 -
可以通過加、減、乘、除等數(shù)學(xué)運算進(jìn)行組合。
在創(chuàng)造新特征時,需要注意新特征的含義和對問題的貢獻(xiàn)。新特征應(yīng)該能夠更好地表達(dá)數(shù)據(jù)的特點和模式,同時避免引入噪聲或不必要的信息。理解新特征的意義,有助于我們更好地解釋模型的預(yù)測結(jié)果,并為特征選擇提供指導(dǎo)。
步驟6:特征篩選與驗證
特征篩選是特征工程中的關(guān)鍵步驟之一,它有助于優(yōu)化模型的復(fù)雜度和性能,同時保留對目標(biāo)有意義的有效特征。在特征篩選過程中,我們需要添加新特征并驗證Baseline模型的精度變化,同時注意精度變化是否是隨機(jī)波動引起的。
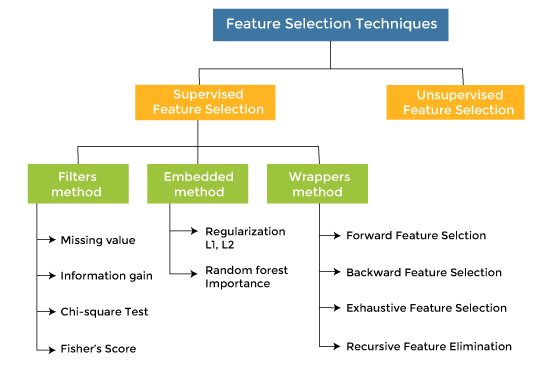
在特征篩選過程中,我們需要注意精度變化是否只是由于隨機(jī)波動導(dǎo)致的。為了排除隨機(jī)性的影響,可以采用以下方法:
-
交叉驗證(Cross-Validation):使用交叉驗證可以降低隨機(jī)性帶來的影響,通過多次實驗取平均值來評估特征的性能變化。 -
統(tǒng)計顯著性檢驗:使用統(tǒng)計顯著性檢驗(如t-test)來判斷特征的添加是否顯著提升了模型性能。
往期精彩回顧
-
適合初學(xué)者入門人工智能的路線及資料下載
-
(圖文+視頻)機(jī)器學(xué)習(xí)入門系列下載
-
機(jī)器學(xué)習(xí)及深度學(xué)習(xí)筆記等資料打印
-
《統(tǒng)計學(xué)習(xí)方法》的代碼復(fù)現(xiàn)專輯
-
交流群
歡迎加入機(jī)器學(xué)習(xí)愛好者微信群一起和同行交流,目前有機(jī)器學(xué)習(xí)交流群、博士群、博士申報交流、CV、NLP等微信群,請掃描下面的微信號加群,備注:”昵稱-學(xué)校/公司-研究方向“,例如:”張小明-浙大-CV“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進(jìn)入相關(guān)微信群。請勿在群內(nèi)發(fā)送廣告,否則會請出群,謝謝理解~(也可以加入機(jī)器學(xué)習(xí)交流qq群772479961)