
大模型RLHF理論詳細講解
知乎鏡像 https://zhuanlan.zhihu.com/p/657490625
寫這篇文章的動機是:
-
在筆者看來RLHF是LLMs智能的關(guān)鍵之一; -
國內(nèi)廠商在這方面投入比較少,目前看起來并沒有很重視; -
大家偏向于認為ChatGPT的RLHF做法最多的線索來源于InstructGPT,但是InstructGPT原文的描述也挺含糊的,很多東西只能靠猜和結(jié)合開源的實現(xiàn)來解讀; -
通常學習強化學習所依賴鏈路比較長,筆者希望以最直觀的方式幫助大家通關(guān)。
筆者會分兩篇文章來介紹,第一篇是理論篇,第二篇是實踐篇。讀者會在第一篇學習到PPO的原理和instrcutGPT中的RLHF做法;在第二篇中學習到目前影響比較大的開源RLHF實現(xiàn)。
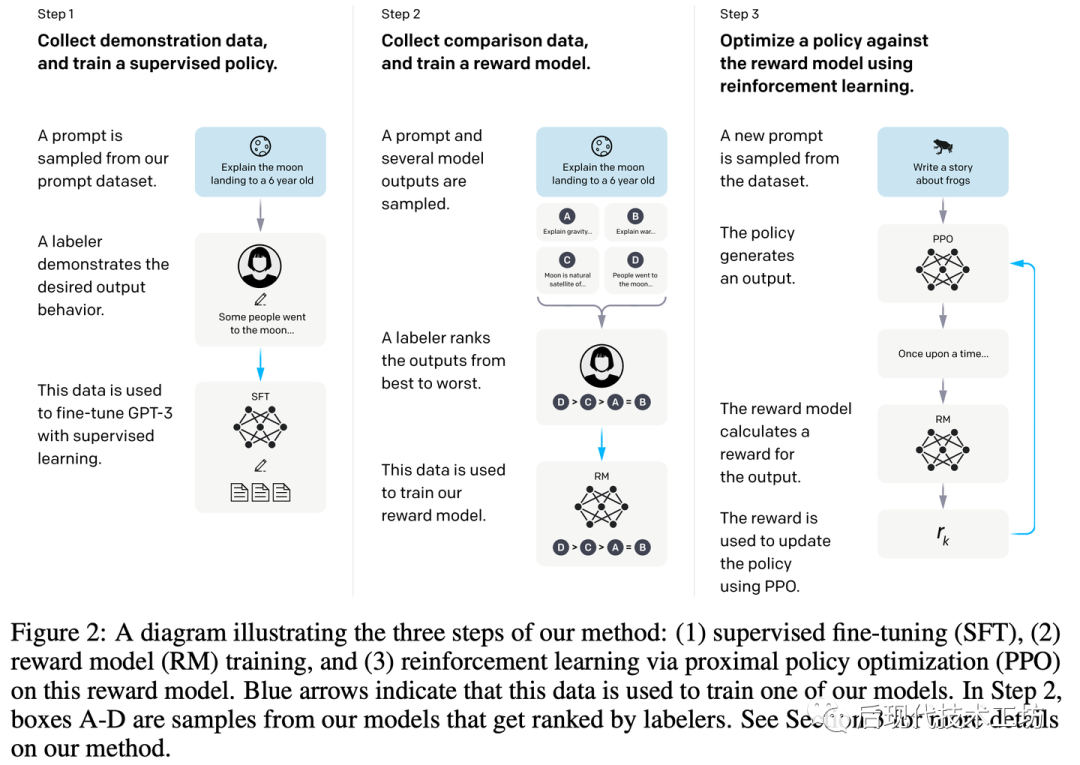
據(jù)公開可獲得的信息來看,ChatGPT需要有大致三個階段的訓練過程,如上圖所示:
-
Pretraining: 在大規(guī)模“無監(jiān)督”的語料上訓練,訓練任務(wù)是預測下一個詞。 -
Supervised Fine-Tuning(SFT):在人類標注上進行微調(diào),所謂人類標注就是人類寫Prompt,人類寫答案。然后語言模型學習模仿人類是如何作答的。這部分通常要求數(shù)據(jù)集多樣性很好,也因為標注成本很高,通常量級很小。 -
Reinforcement Learning with human feedback(RLHF):對于同一個Prompt把模型的多個輸出給人類排序,獲取人類偏好標注。用人類的偏好標注,訓練一個reward model。訓練得到的reward model會作為PPO算法中的reawrd function,來繼續(xù)優(yōu)化SFT得到的模型。
通常來說,第一步最有資源門檻,第三步最有技術(shù)門檻(同時也需要大量的資源),第二步最簡單。所以目前很多廠商是直接拿了開源的第一步的模型,做SFT,或者continue-pretrain(比較小規(guī)模的無監(jiān)督訓練)再SFT。他們PR的時候可能會嘴一句,無需復雜的RLHF,只需做細致的微調(diào)也能達到很好的效果。
后面兩個步驟,通常被視作是人類偏好對齊(alignment),讓模型更好地跟隨人類的指令作回復。而一些研究發(fā)現(xiàn),對齊后的模型是會有對齊稅的現(xiàn)象的(alignment tax),即在通用能力上會有所下降。
因此,不少人是這樣認為的:第一步預訓練得到的模型就已經(jīng)決定了后續(xù)模型的能力上限;后面兩步要做的事情僅僅是在盡可能減少對齊稅的情況下,對齊人類偏好。
這里可以分兩種情況分析:
-
SFT過數(shù)據(jù)太多遍了,導致大模型出現(xiàn)遺忘; -
安全性對齊很多模型能回答的問題,強制不讓回答肯定會對模型能力有所牽制。
在筆者看來,某種意義下RL提供了對LLM的response的Global-level的監(jiān)督,在一些需要答案非常精確的場景上,RL可能可以發(fā)揮出更大的威力。這個看法的依據(jù)也很樸素:
-
比如在coding、數(shù)學推導等場景,只要response在關(guān)鍵的地方犯了一點點錯給人的感覺就是模型不會,但是SFT的loss可能區(qū)分不出來是犯錯了還是只是寫法風格的差異。 -
SFT給定了標準答案,LLM的上限可能會被標注者的水平所限制;RLHF則只給定了人類偏好,得到了一定(有可能是很大)程度的解放,模型有可能探索出更高程度的智能。這一點并不是無中生有的想法,在游戲AI領(lǐng)域有太多的驗證,即在模仿人類玩法(imitation learning)之后,再用RL訓練出來的模型,就是能獲得更高的智能。這里語言模型跟游戲又有多少本質(zhì)的區(qū)別呢。
這里筆者暫時打住,為了不增加讀者的閱讀成本,更多的討論獨開文章系列扯皮。
InstructGPT中的RLHF
這里簡要帶過具體數(shù)據(jù)構(gòu)造和訓練細節(jié),后面會專門有一篇對InstructGPT像素級的解讀。如前文所述,InstructGPT也是包含3階段的訓練,同時我們應該注意到,RLHF這一步訓練,實則包含兩步訓練:
-
訓練Reward Model(RM); -
用Reward Model和SFT Model構(gòu)造Reward Function,基于PPO算法來訓練LLM。
數(shù)據(jù)集
SFT、RM和PPO用到的數(shù)據(jù)集數(shù)據(jù)量如下表所示:

注意,上表統(tǒng)計的是prompts數(shù)量,在RM數(shù)據(jù)中每個prompt,對應會有4~9個responses。在構(gòu)造RM數(shù)據(jù)的時候,作者采集了用戶的prompts,每個prompts包含4~9個模型的輸出,模型的輸出會給標注員進行排序。
訓練Reward Model(RM)
目標: 給pormpt-response pair打分,擬合人類的偏好。
模型: 這InstructGPT的paper中,雖然用了1.3B、6B和175B的GPT-3來做實驗,但是綜合考慮下,只用6B的模型來訓練Reward Model,因為作者發(fā)現(xiàn)用175B的模型會不穩(wěn)定。把最后的unembedding層換成一個輸出為scalar的線性層。這里讀者可能會有點混亂,眾所周知,GPT的模型結(jié)構(gòu)是sequence-in,sequence-out的,怎么變成scalar呢?這里文章似乎也沒提到,根據(jù)筆者的判斷和開源實現(xiàn),推測是直接用最后一個token的輸出接一個linear。
Reward Model的初始化: 6B的GPT-3模型在多個公開數(shù)據(jù)((ARC, BoolQ, CoQA, DROP, MultiNLI, OpenBookQA, QuAC, RACE, and Winogrande)上fintune。不過Paper中提到其實從預訓練模型或者SFT模型開始訓練結(jié)果也差不多。
訓練:以前的做法是,RM每次比較兩個模型輸出的好壞,做法很簡單類似對比學習,兩個樣本對應兩個類別,RM對這兩個樣本分別輸出兩個得分,拼成一個logits向量;人類標注比較好的那個輸出作為label,比如第一個比較好那么label為0,第二個比較好label為1;用cross entropy約束之。
但是作者發(fā)現(xiàn)這么做很容易過擬合;也不高效,因為每比較一次都要重新過一下reward model。因此作者的做法是,在一個batch里面,把每個Prompt對應的所有的模型輸出,都過一遍Reward model,并把所有兩兩組合都比較一遍。比如一個Prompt有K個模型輸出,那么模型則只需要處理K個樣本就可以一氣兒做 次比較。loss的設(shè)計如下:

很直觀,其中, 是prompt, 和 分別是較好和較差的模型response, 是Reward Model的輸出。 在文中似乎沒有解釋,不過根據(jù)公式推斷和開源實現(xiàn),應該是sigmoid函數(shù)。
這里要注意一個細節(jié):在RM訓練完之后,會讓RM的輸出減去一個bias,使得reward score在人類寫的答案上(labeler demonstrations)的平均分為0。這里筆者沒找到具體在什么數(shù)據(jù)上統(tǒng)計的,猜測是在SFT數(shù)據(jù)上做的,如果有讀者知道是怎么做的歡迎指出。
Reinforcement Learning(RL)
直接看需要最大化的目標函數(shù)

其中, 和 分別是正在用RL訓練的語言模型和SFT訓練得到的模型。
上式中,
第一項期望式 是在最大化reward的同時,最小化和SFT模型的per-token KL penalty,可以理解為是一種正則手段,兩者組合成關(guān)于prompt-Responce pair最終的Reward:。在這篇paper中解釋per-token KL penalty的好處如下:
-
充當熵紅利(Entropy bonus),鼓勵policy探索并阻止其坍塌為單一模式。 -
確保策略模型產(chǎn)生的輸出 與 Reward Model在訓練期間看到的輸出 不會相差太大,保證Reward的可靠性。
僅含這一項就是單純使用了PPO。這里也可以看出來,Reward model的能力可能會成為RLHF的瓶頸。
第二項期望式 是可選項,注意到它其實是使用預訓練的數(shù)據(jù)來做跟預訓練同樣的任務(wù)(predict next word),因為這一項的數(shù)據(jù)不是模型生成的其實跟RL是并行的目標。包含這一項的算法稱之為PPO-ptx。
PPO算法
本小節(jié)以最小知識補充為前提,快速介紹PPO,不用犯怵,很簡單而直觀。
通常來說,對于一個強化學習模型,會有一個做動作的策略網(wǎng)絡(luò) ,它根據(jù)自己觀測的狀態(tài)( )做出動作( )跟環(huán)境交互,然后會拿到一個即刻的reward( ), 同時進入到下一個狀態(tài)( );策略網(wǎng)絡(luò)再繼續(xù)觀測狀態(tài) 做下一個動作 ...直到達到最終狀態(tài)。這樣,策略網(wǎng)絡(luò)和環(huán)境的一系列互動后最終會得到一個軌跡(trajectory):。
那么,在語言模型的場景下,策略網(wǎng)絡(luò)就是待微調(diào)的LLM,它所能做的動作就是預測下一個token,它觀測的轉(zhuǎn)狀態(tài)就是預測下一個token時所能觀測到的context(Prompt+這個token前所生成的所有tokens)。reward除了最后一個 等于上文提到的其他的。
好,在LLM的場景中,現(xiàn)在可以統(tǒng)一一下符號: , ,,其中 是prompt, 是第i步蹦的token。看到這,了解PPO的同學基本上就清晰了RLHF具體是怎么做優(yōu)化的了,可以直接跳過下面的科普部分。
因為PPO原文是基于Actor-Critic算法做的,Actor-Critic算法是進階版的Policy Gradient算法。下面我們從policy gradient到Actor-Critic,再到PPO,幫助RL背景比較弱的讀者串一遍。
Policy Gradient(PG)算法
核心要義:用“Reward”作為權(quán)重,最大化策略網(wǎng)絡(luò)所做出的動作的概率。偽代碼核心部分一句話的事:

用策略網(wǎng)絡(luò) 采樣出一個軌跡,然后根據(jù)即刻得到的reward 計算discounted reward ;用 作為權(quán)重,最大化這個軌跡下所采取的動作的概率 ,用梯度上升優(yōu)化之。
雖然在強化學習算法中對每一步都有一個即時的“reward”,但是每一步對后面的可能狀態(tài)都是有影響的。即,后面的動作獲取的即時“reward”都能累計到前面的動作的貢獻。但是直接加上去可能不好,畢竟不是前面的動作直接獲取的reward,但是可以打個折扣再加上去,即乘個小于1的 。
這里面讀者可能會有個問題:可是不好的動作也要最大化概率嗎?這里有必要稍微展開一下:
-
也可以是負的,對負的 那就是最小化動作 的概率,這也是為什么前面提到要對RM的輸出做歸一化的其中一個原因之一。 -
即便 都是正的,但只要充分采樣,同一個狀態(tài)下 相對較小的動作也是會被抑制的,因為同一個狀態(tài)下的動作概率求和等于1,此消彼長,只有權(quán)重最大的動作才會得到獎勵。
可是,比如同一個狀態(tài)下,有兩個動作的 是正的,但是因為動作采樣本來就很稀疏的,我們很可能不幸運采樣到了相對較小的 對應的動作,而沒有采樣到相對較大的。但因為它是正的,這時候當前的機制下,還是會鼓勵這個動作,這樣的話網(wǎng)絡(luò)很容易一直沿著不太好的策略去優(yōu)化。為了解決這個問題,我們引入Actor-Critic算法。
Actor-Critic (AC)算法
核心要義:再增加一個Critic網(wǎng)絡(luò)來構(gòu)造一個Reward baseline,只有獲得的reward比baseline要好才獎勵這個動作,否則抑制它。

Actor指的是策略網(wǎng)絡(luò) ;Critic 目的就是給定一個策略網(wǎng)絡(luò),預估每個狀態(tài) ,策略網(wǎng)絡(luò)所能拿到期望reward 是多少。什么是期望reward,無非就是在狀態(tài) ,對采樣不同的動作 所能獲取的 的平均值嘛。我們要選擇的動作當然是獲取的reward比平均reward要好的動作,不比baseline好的動作就得抑制它。
觀測上面算法2,其實對比PG算法就加了兩行:
-
原來用Reward function來加權(quán),現(xiàn)在用Advantage function來加權(quán)。現(xiàn)在我們把 當作一個baseline方法所能拿到的reward, 用采樣出來的 所拿到的reward 減去 作為最大化當前動作概率的權(quán)重: 。其中 通常被稱作是Advantage function(或Advantage estimator),即優(yōu)勢函數(shù)。 -
拉近 和 的距離,初學者對這個可能會費解。實則很好理解,記住 在做什么,要預估當前策略下 的期望,我只要不管三七二十一,每來一個動作的 都拉近一下距離,其實就是在預估平均值。
更一般地:其實上面用到的 ,它無非是換了皮的 (簡寫成 ),即RL中的重要概念V function:給定策略 在 上的期望reward。那么最后一步 到達的state 通常來講是沒有隨機性的(比如下棋,最后一個state決定贏輸就是固定的reward;LLM,最后一個token生成完,response確定了,reward也就確定了),因此 應該和 相等。
所以我們可以重寫上面的優(yōu)勢函數(shù):
寫成Generalized Advantage Estimation,當 下式等于上式:
其中,是時序差分式(TD error)。
記住這個結(jié)論:這樣我們可以用 優(yōu)化 ,現(xiàn)在我們可以用 來更新策略網(wǎng)絡(luò)了。
PPO 算法
上面提到的算法,有一個最嚴重的弊端是,一個軌跡只用一次就丟掉了。可是,采樣軌跡通常是很耗時的,對應到在LLM場景則需要做推理,眾所周知LLM的推理是比訓練費勁很多的,它需要一個一個地蹦詞。可是直接用之前的策略采樣出來的樣本來優(yōu)化現(xiàn)在的策略網(wǎng)絡(luò)肯定不行,如何合理復用樣本則是PPO要做的事情。
做法巨簡單,大致可以用這個思想來更新:
定義 動作概率比,用 去梯度上升更新策略網(wǎng)絡(luò),注意這里 和 都是只之前的策略網(wǎng)絡(luò) 采樣得到的。這個公式,在筆者看來沒有直觀的解釋,需要一丟丟推導,因為是科普向這里讀者先承認就好了,后面筆者會單開一篇文章再重新梳理一遍。
本質(zhì)上是最大化這個目標函數(shù):

但是如果 和 如果差別太大,就不能用這個式子優(yōu)化了,PPO給出的做法是給 卡閾值,太大或太小就不用這一步的樣本更新了:
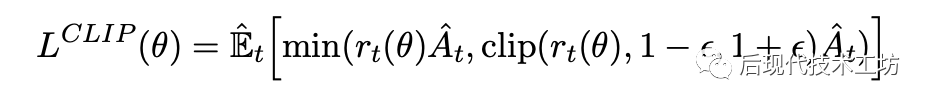
上面的目標函數(shù)可以分類討論進行分析,對優(yōu)勢函數(shù) 大于0和小于0兩種情況分析,這個目標函數(shù)的圖像長這樣:
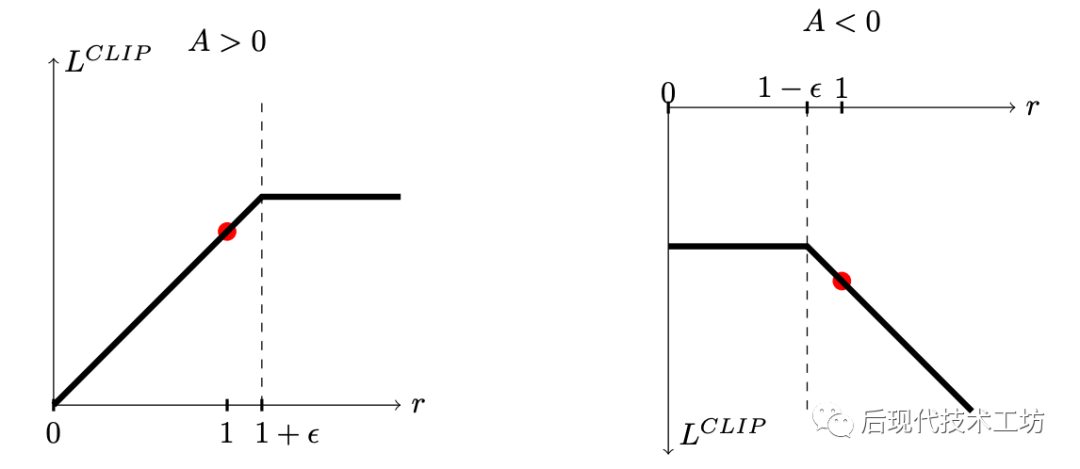
觀測圖像:
-
當 大于0,要提高動作的概率,但是如果概率比之前大比較多了( 是 的 倍),就不提高了
-
當 小于0,要減少動作的概率,但是如果概率比之前小比較多了( 是 的 倍),就不減少了
偽代碼如下:

科普到此結(jié)束,看到這讀者就可以看懂RLHF的代碼。值得注意的是為了減少讀者負擔做了大量的敘述上的簡化,方法上是比較完備的,但是說法上不夠嚴謹。Again,更詳細的強化學習科普會單開一篇文章。
大語言模型的PPO
稍微整理一下,符號和上面的科普部分不一致,不過應該不影響理解
-
現(xiàn)在我們的actor是SFT初始化的LLM
-
為了計算reward,我們需要兩個凍住參數(shù)網(wǎng)絡(luò),一個RM,一個是凍住的SFT模型 用來計算KL散度,參考下面兩式子:其他步的
-
為了執(zhí)行PPO算法,我們需要引入一個估計V值的網(wǎng)絡(luò) ,它初始化來自RM。
所以統(tǒng)共,有4個網(wǎng)絡(luò),兩個訓練的actor 和critic ;兩個用來計算reward的SFT模型 和RM模型。然后actor初始化來自SFT,critic初始化來自RM。
把這四個網(wǎng)絡(luò),結(jié)合reward的構(gòu)造,帶入到上面提到的PPO算法中,整個過程就比較清晰了。盜一下DeepSpeed-Chat的圖,圖解如下:

看到這,相信讀者已經(jīng)可以輕易看懂的DeepSpeed-Chat代碼了。
推薦閱讀