
搞懂大模型的智能基因,RLHF系統(tǒng)設(shè)計(jì)關(guān)鍵問答
RLHF(Reinforcement Learning with Human Feedback,人類反饋強(qiáng)化學(xué)習(xí))雖是熱門概念,并非包治百病的萬用仙丹。本問答探討RLHF的適用范圍、優(yōu)缺點(diǎn)和可能遇到的問題,供RLHF系統(tǒng)設(shè)計(jì)者參考。
目錄
-
RLHF是什么?
-
RLHF 適用于哪些任務(wù)?
-
RLHF 和其他構(gòu)造獎(jiǎng)勵(lì)模型的方法相比有何優(yōu)劣?
-
什么樣的人類反饋才是好反饋?
-
RLHF 算法有哪些類型、各有何優(yōu)缺點(diǎn)?
-
RLHF 采用人類反饋會(huì)帶來哪些局限?
-
如何減小人類反饋帶來的負(fù)面影響?
1RLHF是什么?
強(qiáng)化學(xué)習(xí)利用獎(jiǎng)勵(lì)信號(hào)訓(xùn)練智能體。 有些任務(wù)并沒有自帶能給出獎(jiǎng)勵(lì)信號(hào)的環(huán)境,也沒有現(xiàn)成的生成獎(jiǎng)勵(lì)信號(hào)的方法。 為此,可以搭建獎(jiǎng)勵(lì)模型來提供獎(jiǎng)勵(lì)信號(hào)。 在搭建獎(jiǎng)勵(lì)模型時(shí),可以用數(shù)據(jù)驅(qū)動(dòng)的機(jī)器學(xué)習(xí)方法來訓(xùn)練獎(jiǎng)勵(lì)模型,并且由人類提供數(shù)據(jù)。 我們把這樣的利用人類提供的反饋數(shù)據(jù)來訓(xùn)練獎(jiǎng)勵(lì)模型以用于強(qiáng)化學(xué)習(xí)的系統(tǒng)稱為人類反饋強(qiáng)化學(xué)習(xí),示意圖如下。
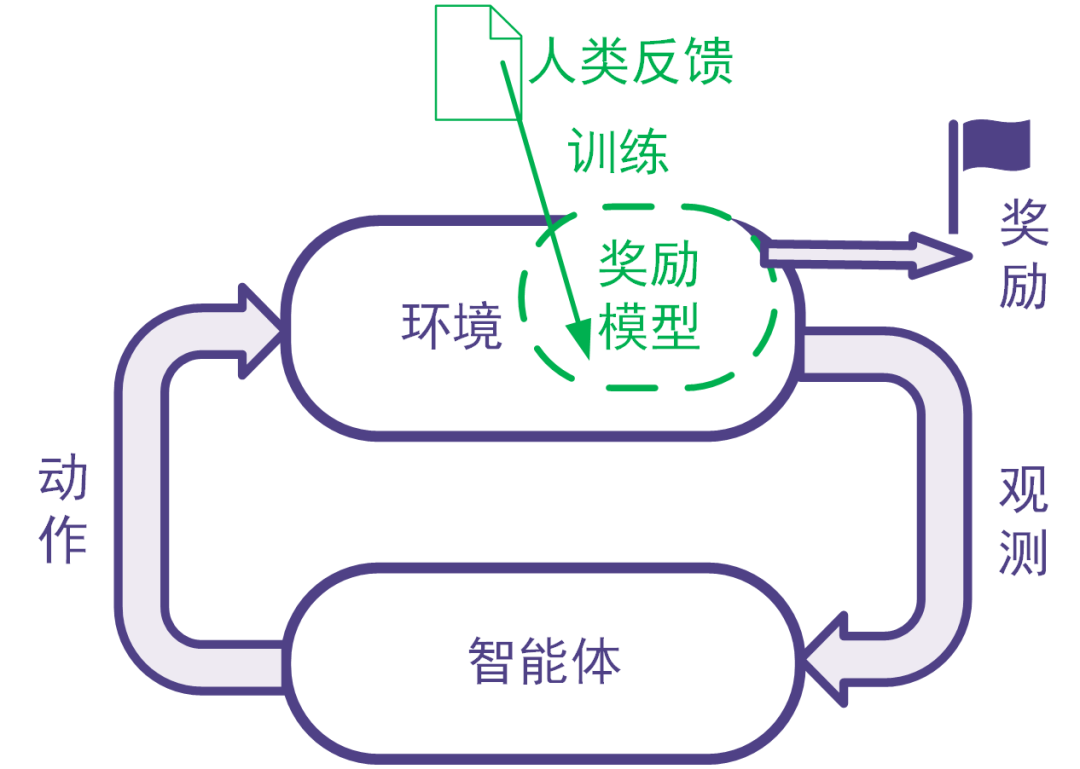
圖: 人類反饋強(qiáng)化學(xué)習(xí):用人類反饋的數(shù)據(jù)訓(xùn)練獎(jiǎng)勵(lì)模型,用獎(jiǎng)勵(lì)模型生成獎(jiǎng)勵(lì)信號(hào)
RLHF適合于同時(shí)滿足下面所有條件的任務(wù):
-
要解決的任務(wù)是一個(gè)強(qiáng)化學(xué)習(xí)任務(wù),但是沒有現(xiàn)成的獎(jiǎng)勵(lì)信號(hào)并且獎(jiǎng)勵(lì)信號(hào)的確定方式事先不知道。為了訓(xùn)練強(qiáng)化學(xué)習(xí)智能體,考慮構(gòu)建獎(jiǎng)勵(lì)模型來得到獎(jiǎng)勵(lì)信號(hào)。
反例:比如電動(dòng)游戲有游戲得分,那樣的游戲程序能夠給獎(jiǎng)勵(lì)信號(hào),那我們直接用游戲程序反饋即可,不需要人類反饋。
反例:某些系統(tǒng)獎(jiǎng)勵(lì)信號(hào)的確定方式是已知的,比如交易系統(tǒng)的獎(jiǎng)勵(lì)信號(hào)可以由賺到的錢完全確定。這時(shí)直接可以用已知的數(shù)學(xué)表達(dá)式確定獎(jiǎng)勵(lì)信號(hào),不需要人工反饋。 -
不采用人類反饋的數(shù)據(jù)難以構(gòu)建合適的獎(jiǎng)勵(lì)模型,而且人類的反饋可以幫助得到合適的獎(jiǎng)勵(lì)模型,并且人類來提供反饋可以在合理的代價(jià)(包括成本代價(jià)、時(shí)間代價(jià)等)內(nèi)得到。 如果用人類反饋得到數(shù)據(jù)與其他方法采集得到數(shù)據(jù)相比不具有優(yōu)勢,那么就沒有必要讓人類來反饋。
獎(jiǎng)勵(lì)模型可以人工指定,也可以通過有監(jiān)督模型、逆強(qiáng)化學(xué)習(xí)等機(jī)器學(xué)習(xí)方法來學(xué)習(xí)。 RLHF 使用機(jī)器學(xué)習(xí)方法學(xué)習(xí)獎(jiǎng)勵(lì)模型,并且在學(xué)習(xí)過程中采用人類給出的反饋。
比較人工指定獎(jiǎng)勵(lì)模型與采用機(jī)器學(xué)習(xí)方法學(xué)習(xí)獎(jiǎng)勵(lì)模型的優(yōu)劣: 這與對(duì)一般的機(jī)器學(xué)習(xí)優(yōu)劣的討論相同。 機(jī)器學(xué)習(xí)方法的優(yōu)點(diǎn)包括不需要太多領(lǐng)域知識(shí)、能夠處理非常復(fù)雜的問題、能夠處理快速大量的高維數(shù)據(jù)、能夠隨著數(shù)據(jù)增大提升精度等等。 機(jī)器學(xué)習(xí)算法的缺陷包括其訓(xùn)練和使用需要數(shù)據(jù)時(shí)間空間電力等資源、模型和輸出的解釋型可能不好、模型可能有缺陷、覆蓋范圍不夠或是被攻擊(比如大模型里的提示詞注入)。
4什么樣的人類反饋才是好的反饋
-
好的反饋需要夠用:反饋數(shù)據(jù)可以用來學(xué)成獎(jiǎng)勵(lì)模型,并且數(shù)據(jù)足夠正確、量足夠大、覆蓋足夠全面,使得獎(jiǎng)勵(lì)模型足夠好,進(jìn)而在后續(xù)的強(qiáng)化學(xué)習(xí)中得到令人滿意的智能體。
這個(gè)部分涉及的評(píng)價(jià)指標(biāo)包括:對(duì)數(shù)據(jù)本身的評(píng)價(jià)指標(biāo)(正確性、數(shù)據(jù)量、覆蓋率、一致性),對(duì)獎(jiǎng)勵(lì)模型及其訓(xùn)練過程的評(píng)價(jià)指標(biāo)、對(duì)強(qiáng)化學(xué)習(xí)訓(xùn)練過程和訓(xùn)練得到的智能體的評(píng)價(jià)指標(biāo)。 -
好的反饋需要是可得的反饋。反饋需要可以在合理的時(shí)間花費(fèi)和金錢花費(fèi)的情況下得到,并且在成本可控的同時(shí)不會(huì)引發(fā)其他風(fēng)險(xiǎn)(如法律上的風(fēng)險(xiǎn))。
涉及的評(píng)價(jià)指標(biāo)包括:數(shù)據(jù)準(zhǔn)備時(shí)間、數(shù)據(jù)準(zhǔn)備涉及的人員數(shù)量、數(shù)據(jù)準(zhǔn)備成本、是否引發(fā)其他風(fēng)險(xiǎn)的判斷。
RLHF算法有以下兩大類:用監(jiān)督學(xué)習(xí)的思路訓(xùn)練獎(jiǎng)勵(lì)模型的RLHF、用逆強(qiáng)化學(xué)習(xí)的思路訓(xùn)練獎(jiǎng)勵(lì)模型的RLHF。
1.在用監(jiān)督學(xué)習(xí)的思路訓(xùn)練獎(jiǎng)勵(lì)模型的RLHF系統(tǒng)中,人類的反饋是獎(jiǎng)勵(lì)信號(hào)或是獎(jiǎng)勵(lì)信號(hào)的衍生量(如獎(jiǎng)勵(lì)信號(hào)的排序)。
直接反饋獎(jiǎng)勵(lì)信號(hào)和反饋獎(jiǎng)勵(lì)信號(hào)衍生量各有優(yōu)缺點(diǎn)。這個(gè)優(yōu)點(diǎn)在于獲得獎(jiǎng)勵(lì)參考值后可以直接把它用作有監(jiān)督學(xué)習(xí)的標(biāo)簽。缺點(diǎn)在于不同人在不同時(shí)候給出的獎(jiǎng)勵(lì)信號(hào)可能不一致,甚至矛盾。反饋獎(jiǎng)勵(lì)信號(hào)的衍生量,比如獎(jiǎng)勵(lì)模型輸入的比較或排序。有些任務(wù)給出評(píng)價(jià)一致的獎(jiǎng)勵(lì)值有困難,但是比較大小容易得多。但是沒有密集程度的信息。在大量類似情況導(dǎo)致某部分獎(jiǎng)勵(lì)對(duì)應(yīng)的樣本過于密集的情況下,甚至可能不收斂。
一般認(rèn)為,采用比較類型的反饋可以得到更好的性能中位數(shù),但是并不能得到更好的性能平均值。
2.在用逆強(qiáng)化學(xué)習(xí)的思路訓(xùn)練獎(jiǎng)勵(lì)模型的RLHF系統(tǒng)中,人類的反饋并不是獎(jiǎng)勵(lì)信號(hào),而是使得獎(jiǎng)勵(lì)更大的獎(jiǎng)勵(lì)模型輸入。 即人類給出了較為正確的數(shù)量、文本、分類、物理動(dòng)作等,告訴獎(jiǎng)勵(lì)模型在這時(shí)候獎(jiǎng)勵(lì)應(yīng)該比較大。這其實(shí)就是逆強(qiáng)化學(xué)習(xí)的思想。
這種方法與用監(jiān)督學(xué)習(xí)訓(xùn)練獎(jiǎng)勵(lì)模型的RLHF相比,其優(yōu)點(diǎn)在于,訓(xùn)練獎(jiǎng)勵(lì)模型的樣本點(diǎn)不再拘泥于系統(tǒng)給出的需要評(píng)判的樣本。因?yàn)橄到y(tǒng)給出的需要評(píng)估獎(jiǎng)勵(lì)的樣本可能具有局限性(因?yàn)橄到y(tǒng)沒有找到最優(yōu)的區(qū)間)。
在系統(tǒng)搭建初期,還可以將用戶提供的參考答案用于把最初的強(qiáng)化學(xué)習(xí)問題轉(zhuǎn)化成模仿學(xué)習(xí)問題。
這類設(shè)計(jì)還可以根據(jù)反饋的類型進(jìn)一步分類,一類是讓人類獨(dú)立給出專家意見, 另一 類是在讓人類在已有數(shù)據(jù)的基礎(chǔ)上進(jìn)行改進(jìn)。 讓人類提供意見就類似于讓人類提供模仿學(xué)習(xí)里的專家策略(當(dāng)然可能略有不同,畢竟獎(jiǎng)勵(lì)模型的輸入不只有動(dòng)作)。讓用戶在已有的參考內(nèi)容上修改可以減少人類每個(gè)標(biāo)注的成本,但是已有的參考內(nèi)容可能會(huì)干擾到人類的獨(dú)立判斷(這個(gè)干擾可能是正面的也可能是負(fù)面的)。
6RLHF采用人類反饋會(huì)帶來哪些局限?
前面已經(jīng)提到,人類反饋可能更費(fèi)時(shí)費(fèi)力,并且不一定能夠保證準(zhǔn)確性和一致性。除此之外,下面幾點(diǎn)會(huì)導(dǎo)致獎(jiǎng)勵(lì)模型不完整不正確,導(dǎo)致后續(xù)強(qiáng)化學(xué)習(xí)訓(xùn)練得到的智能體行為不能令人滿意。
1.提供人類反饋的人群可能有偏見或局限性。
這個(gè)問題和數(shù)理統(tǒng)計(jì)里的對(duì)樣本進(jìn)行抽樣方法可能遇到的問題類型。為RLHF系統(tǒng)提供反饋的人群可能并不是最佳的人群。有的時(shí)候出于成本、可得性等因素,會(huì)選擇人力成本低的團(tuán)隊(duì),但是這樣的團(tuán)隊(duì)可能在專業(yè)度不夠,或是有著不同的法律、道德和宗教觀念,包括歧視性信息。反饋人中可能有惡意者,會(huì)提供有誤導(dǎo)性的反饋。
2.人的決策可能沒有機(jī)器決策那么高明。
在一些問題上,機(jī)器可以比人做的更好,比如對(duì)于象棋圍棋等棋盤游戲,真人就比不過人工智能程序。在一些問題上,人能夠處理的信息沒有數(shù)據(jù)驅(qū)動(dòng)的程序處理的信息全面。比如對(duì)于自動(dòng)駕駛的應(yīng)用,人類只能根據(jù)二維畫面和聲音進(jìn)行決策,而程序能夠處理連續(xù)時(shí)間內(nèi)三維空間的信息。所以在理論上人類反饋的質(zhì)量是不如程序的。
3.沒有將提供反饋的人的特征引入到系統(tǒng)。
每個(gè)人都是獨(dú)一無二的:每個(gè)人有自己的成長環(huán)境、宗教信仰、道德觀念、學(xué)習(xí)和工作經(jīng)歷、知識(shí)儲(chǔ)備等,我們不可能把每個(gè)人的所有特征都引入到系統(tǒng)。在這種情況下,如果忽略不同的人之間在某個(gè)特征維度上的差別,那么就會(huì)損失到許多有效信息,導(dǎo)致獎(jiǎng)勵(lì)模型性能下降。
以大規(guī)模語言模型為例,用戶可以通過提示工程指定模型以某種特定的角色或溝通方式來溝通,比如有時(shí)要求語言模型的輸出文字更有禮貌更客套多奉承套,有時(shí)需要輸出文字內(nèi)容擲地有聲言之有物少客套;有時(shí)要求輸出文字更有創(chuàng)造性,有時(shí)要求輸出文字尊重事實(shí)更嚴(yán)謹(jǐn);有時(shí)要求輸出簡潔扼要,有時(shí)要求輸出詳盡完備提供更多細(xì)節(jié);有時(shí)要求輸出中立客觀僅在純自然科學(xué)范圍內(nèi)討論,有時(shí)要求輸出多考慮人文社會(huì)的環(huán)境背景。而提供反饋數(shù)據(jù)的人的不同身份背景和溝通習(xí)慣可能正好對(duì)應(yīng)于不同情況下的輸出要求。這種情況下,反饋人的特性就非常重要。
4.人性可能導(dǎo)致數(shù)據(jù)集不完美。
比如語言模型可能會(huì)通過拍馬屁、戴高帽等行為獲得高分評(píng)價(jià),但是這樣的高分評(píng)價(jià)可能并沒有真正解決問題,有違系統(tǒng)設(shè)計(jì)的初衷。看似得分很高,但是高得分可能是通過避免爭議性話題或是拍馬屁拍出來的,而不是真正解決了需要解決問題,沒有達(dá)到系統(tǒng)設(shè)計(jì)的初衷。
此外,人類提供反饋還有其他非技術(shù)上面的風(fēng)險(xiǎn),比如泄密等安全性風(fēng)險(xiǎn)、監(jiān)管法律風(fēng)險(xiǎn)等。
7如何降低人類反饋帶來的負(fù)面影響?
針對(duì)人類反饋費(fèi)時(shí)費(fèi)力且可能導(dǎo)致獎(jiǎng)勵(lì)模型不完整不正確的問題,可以在收集人類反饋數(shù)據(jù)的同時(shí)就訓(xùn)練獎(jiǎng)勵(lì)模型、訓(xùn)練智能體,并全面評(píng)估獎(jiǎng)勵(lì)模型和智能體,以便于盡早發(fā)現(xiàn)人類反饋的缺陷。發(fā)現(xiàn)缺陷后,及時(shí)進(jìn)行調(diào)整。
針對(duì)人類反饋中出現(xiàn)的反饋質(zhì)量問題以及錯(cuò)誤反饋,可以對(duì)人類反饋進(jìn)行校驗(yàn)和審計(jì),如引入已知獎(jiǎng)勵(lì)的校驗(yàn)樣本來校驗(yàn)人類反饋的質(zhì)量,或?yàn)橥粯颖径啻嗡魅》答伈⒈容^多次反饋的結(jié)果等。
針對(duì)反饋人的選擇不當(dāng)?shù)膯栴},可以在有效控制人力成本的基礎(chǔ)上,采用科學(xué)的方法選定提供反饋的人。可以參考數(shù)理統(tǒng)計(jì)里的抽樣方法,如分層抽樣、整群抽樣等,使得反饋人群更加合理。
對(duì)于反饋數(shù)據(jù)中未包括反饋人特征導(dǎo)致獎(jiǎng)勵(lì)模型不夠好的問題,可以收集反饋人的特征,并將這些特征用于獎(jiǎng)勵(lì)模型的訓(xùn)練。比如,在大規(guī)模語言模型的訓(xùn)練中可以記錄反饋人的職業(yè)背景(如律師、醫(yī)生等),并在訓(xùn)練獎(jiǎng)勵(lì)模型時(shí)加以考慮。當(dāng)用戶要求智能體像律師一樣工作時(shí),更應(yīng)該利用由律師提供的數(shù)據(jù)學(xué)成的那部分獎(jiǎng)勵(lì)模型來提供獎(jiǎng)勵(lì)信號(hào);當(dāng)用戶要求智能體像醫(yī)生一樣工作時(shí),更應(yīng)該利用由醫(yī)生提供的數(shù)據(jù)學(xué)成的那部分獎(jiǎng)勵(lì)模型來提供獎(jiǎng)勵(lì)信號(hào)。
另外,在整個(gè)系統(tǒng)的實(shí)施過程中,可以征求專業(yè)人士意見,以減小其中法律和安全風(fēng)險(xiǎn)。
本文內(nèi)容摘編自《強(qiáng)化學(xué)習(xí):原理與Python實(shí)戰(zhàn)》,經(jīng)出版方授權(quán)發(fā)布。(ISBN:978-7-111-72891-7)
延伸閱讀

《強(qiáng)化學(xué)習(xí):原理與Python實(shí)戰(zhàn)》
肖智清 著
解密ChatGPT關(guān)鍵技術(shù)PPO和RLHF
理論完備,涵蓋強(qiáng)化學(xué)習(xí)主干理論和常見算法,帶你參透ChatGPT技術(shù)要點(diǎn);
實(shí)戰(zhàn)性強(qiáng),每章都有編程案例,深度強(qiáng)化學(xué)習(xí)算法提供TenorFlow和PyTorch對(duì)照實(shí)現(xiàn);
配套豐富,逐章提供知識(shí)點(diǎn)總結(jié),章后習(xí)題形式豐富多樣。還有Gym源碼解讀、開發(fā)環(huán)境搭建指南、習(xí)題答案等在線資源助力自學(xué)。
參考資料:
肖智清。強(qiáng)化學(xué)習(xí):原理與Python實(shí)戰(zhàn)。機(jī)械工業(yè)出版社。2023.
P. Christiano et. al., Deep reinforcement learning from human preferences. arxiv: 1706.03741.
S. Casper, et. al. Open problems and fundamental limitations of reinforcement learning from human feedback. arxiv: 2307.15217.

-
本文來源:原創(chuàng),圖片來源:原創(chuàng)
-
責(zé)任編輯:王瑩,部門領(lǐng)導(dǎo):盧志堅(jiān)
-
發(fā)布人:白鈺