一、二分查找
二分查找(Binary Search)算法,也叫折半查找算法。O(logn) 非常高效的查找算法。在不存在重復(fù)元素的有序數(shù)組中,查找值等于給定值的元素。
eg:數(shù)組元素 1 3 4 5 7 8 9 10
mid的位置就是(起點(diǎn)下標(biāo)+ 終點(diǎn)下標(biāo))/2下取整 ,我要查找1,先和5比較,然后和3比較。
eg: public int bsearch(int[] a, int n, int value) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = (low + high) / 2;
if (a[mid] == value) {
return mid;
} else if (a[mid] < value) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return -1;
需要著重掌握它的三個(gè)容易出錯(cuò)的地方:終止條件、區(qū)間上下界更新方法、返回值選擇。
小結(jié):二分查找比較好理解,每次一分為二查一半,二分查找算法雖然性能比較優(yōu)秀,但應(yīng)用場(chǎng)景也比較有限。底層必須依賴數(shù)組,并且還要求數(shù)據(jù)是有序的。對(duì)于較小規(guī)模的數(shù)據(jù)查找,我們直接使用順序遍歷就可以了,二分查找的優(yōu)勢(shì)并不明顯。二分查找更適合處理靜態(tài)數(shù)據(jù),也就是沒(méi)有頻繁的數(shù)據(jù)插入、刪除操作。數(shù)據(jù)量太大不能用二分查找。
二、跳表
1、跳表(Skip list):
有序鏈表加多級(jí)索引的結(jié)構(gòu),就是跳表。
2、跳表的時(shí)間空間復(fù)雜度:
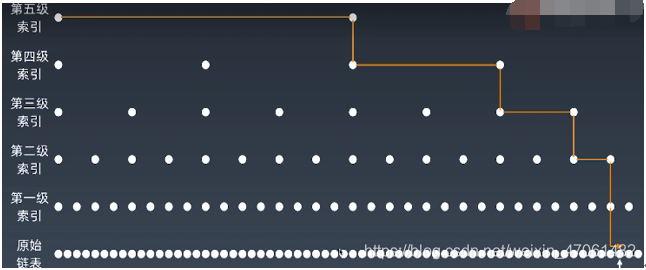
假設(shè)有序鏈表每?jī)蓚€(gè)結(jié)點(diǎn)會(huì)抽出一個(gè)結(jié)點(diǎn)作為上一級(jí)索引的結(jié)點(diǎn),不斷升維度,那第一級(jí)索引的結(jié)點(diǎn)個(gè)數(shù)大約就是 n/2,依次類推 n/2、 n/4、 n/8 、第k級(jí)索引的結(jié)點(diǎn)個(gè)數(shù)就是n/(2k),假設(shè)最高級(jí)的索引有 2 個(gè)結(jié)點(diǎn)。那么 n/(2k)=2,從而求得 k=log2n-1。如果包含原始鏈表這一層,整個(gè)跳表的高度就是 log2n。我們?cè)谔碇胁樵兡硞€(gè)數(shù)據(jù)的時(shí)候,如果每一層都要遍歷 m 個(gè)結(jié)點(diǎn),那在跳表中查詢一個(gè)數(shù)據(jù)的時(shí)間復(fù)雜度就是 O(m*logn)。m為常量級(jí)的數(shù),?所以跳表插入、刪除、查找的時(shí)間復(fù)雜度O(logn) 。?

如上索引節(jié)點(diǎn)的總數(shù)分析,所以?跳表的空間復(fù)雜度是 O(n)?。也就是說(shuō),如果將包含 n 個(gè)結(jié)點(diǎn)的單鏈表構(gòu)造成跳表,我們需要額外再用接近 n 個(gè)結(jié)點(diǎn)的存儲(chǔ)空間。
但是通常實(shí)際應(yīng)用中,原始鏈表中存儲(chǔ)的有可能是很大的對(duì)象,而索引結(jié)點(diǎn)只需要存儲(chǔ)關(guān)鍵值和幾個(gè)指針,并不需要存儲(chǔ)對(duì)象,所以當(dāng)對(duì)象比索引結(jié)點(diǎn)大很多時(shí),那索引占用的額外空間就可以忽略了。
小結(jié):跳表比較優(yōu)秀的動(dòng)態(tài)數(shù)據(jù)結(jié)構(gòu),有序鏈表加多級(jí)索引的結(jié)構(gòu),可以支持快速地插入、刪除、查找操作,時(shí)間復(fù)雜度度都是o(logn),區(qū)間查找效率很高,類似于基于單鏈表實(shí)現(xiàn)了二分查找,在一些地方可以用來(lái)替代平衡樹,如redis的有序集合、levelDB。是一種升維,空間換時(shí)間的思想,空間復(fù)雜度是 O(n)。可以通過(guò)改變索引構(gòu)建策略,有效平衡執(zhí)行效率和內(nèi)存消耗。相比紅黑樹實(shí)現(xiàn)簡(jiǎn)單。
三、散列表(哈希表)
1、散列表
散列表的英文叫“Hash Table”,我們平時(shí)也叫它“哈希表”或者“Hash 表”。散列表用的是數(shù)組支持按照下標(biāo)隨機(jī)訪問(wèn)數(shù)據(jù)的特性,所以散列表其實(shí)就是數(shù)組的一種擴(kuò)展。我們把一些鍵(key)或者關(guān)鍵字轉(zhuǎn)化為數(shù)組下標(biāo)的映射方法就叫作散列函數(shù)(或“Hash 函數(shù)”“哈希函數(shù)”),而散列函數(shù)計(jì)算得到的值就叫作散列值(或“Hash 值”“哈希值”)。
原理:散列表用的就是數(shù)組支持按照下標(biāo)隨機(jī)訪問(wèn)的時(shí)候,時(shí)間復(fù)雜度是 O(1) 的特性。我們通過(guò)散列函數(shù)把元素的鍵值映射為下標(biāo),然后將數(shù)據(jù)存儲(chǔ)在數(shù)組中對(duì)應(yīng)下標(biāo)的位置。當(dāng)我們按照鍵值查詢?cè)貢r(shí),我們用同樣的散列函數(shù),將鍵值轉(zhuǎn)化數(shù)組下標(biāo),從對(duì)應(yīng)的數(shù)組下標(biāo)的位置取數(shù)據(jù)。
2、散列函數(shù)設(shè)計(jì)的基本要求
散列函數(shù)計(jì)算得到的散列值是一個(gè)非負(fù)整數(shù)(好理解,要映射成數(shù)組下標(biāo)嘛);
如果 key1 = key2,那 hash(key1) == hash(key2);
如果 key1 ≠ key2,那 hash(key1) ≠ hash(key2)。
3、散列沖突
再好的散列函數(shù)也無(wú)法避免散列沖突。那究竟該如何解決散列沖突問(wèn)題呢?我們常用的散列沖突解決方法有兩類,開(kāi)放尋址法(open addressing)和鏈表法(chaining)。
1)開(kāi)放尋址法:
線性探測(cè):當(dāng)我們往散列表中插入數(shù)據(jù)時(shí),如果某個(gè)數(shù)據(jù)經(jīng)過(guò)散列函數(shù)散列之后,存儲(chǔ)位置已經(jīng)被占用了,我們就從當(dāng)前位置開(kāi)始,依次往后查找,看是否有空閑位置,直到找到為止。
二次探測(cè):所謂二次探測(cè),跟線性探測(cè)很像,線性探測(cè)每次探測(cè)的步長(zhǎng)是 1,那它探測(cè)的下標(biāo)序列就是 hash(key)+0,hash(key)+1,hash(key)+2……而二次探測(cè)探測(cè)的步長(zhǎng)就變成了原來(lái)的“二次方”,也就是說(shuō),它探測(cè)的下標(biāo)序列就是
hash(key)+0,hash(key)+12,hash(key)+22…
雙重散列:我們使用一組散列函數(shù) hash1(key),hash2(key),hash3(key)……我們先用第一個(gè)散列函數(shù),如果計(jì)算得到的存儲(chǔ)位置已經(jīng)被占用,再用第二個(gè)散列函數(shù),依次類推,直到找到空閑的存儲(chǔ)位置。
散列表跟數(shù)組一樣,不僅支持插入、查找操作,還支持刪除操作。對(duì)于使用線性探測(cè)法解決沖突的散列表,刪除不能單純地把要?jiǎng)h除的元素設(shè)置為空。也是將刪除的元素,特殊標(biāo)記為 deleted。不然會(huì)導(dǎo)致原來(lái)的查找算法失效。當(dāng)線性探測(cè)查找的時(shí)候,遇到標(biāo)記為 deleted 的空間,并不是停下來(lái),而是繼續(xù)往下探測(cè)。
不管采用哪種探測(cè)方法,當(dāng)散列表中空閑位置不多的時(shí)候,散列沖突的概率就會(huì)大大提高。為了盡可能保證散列表的操作效率,一般情況下,我們會(huì)盡可能保證散列表中有一定比例的空閑槽位。我們用裝載因子(load factor)來(lái)表示空位的多少:
`散列表的裝載因子=填入表中的元素個(gè)數(shù)/散列表的長(zhǎng)度`
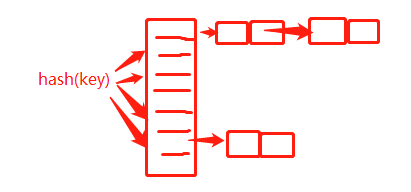
2)鏈表法:
4、散列沖突解決方法優(yōu)勢(shì)和劣勢(shì)
當(dāng)數(shù)據(jù)量比較小、裝載因子小的時(shí)候,適合采用開(kāi)放尋址法。這也是 Java 中的ThreadLocalMap使用開(kāi)放尋址法解決散列沖突的原因。
大部分情況下,鏈表法更加普適。基于鏈表的散列沖突處理方法比較適合存儲(chǔ)大對(duì)象、大數(shù)據(jù)量的散列表,而且,比起開(kāi)放尋址法,它更加靈活,支持更多的優(yōu)化策略,比如紅黑樹、跳表,來(lái)避免散列表時(shí)間復(fù)雜度退化成O(n),抵御散列沖突攻擊。比如HashMap、LinkedHashMap就是使用鏈表法解決散列沖突 。
5、如何設(shè)計(jì)散列函數(shù)
要盡可能讓散列后的值隨機(jī)且均勻分布,這樣會(huì)盡可能減少散列沖突,即便沖突之后,分配到每個(gè)槽內(nèi)的數(shù)據(jù)也比較均勻。
除此之外,散列函數(shù)的設(shè)計(jì)也不能太復(fù)雜,太復(fù)雜就會(huì)太耗時(shí)間,也會(huì)影響到散列表的性能。
常見(jiàn)的散列函數(shù)設(shè)計(jì)方法:直接尋址法、平方取中法、折疊法、隨機(jī)數(shù)法等。
6、裝載因子的閾值和擴(kuò)容
當(dāng)散列表的裝載因子超過(guò)某個(gè)閾值時(shí),就需要進(jìn)行擴(kuò)容。裝載因子閾值需要選擇得當(dāng)。如果太大,會(huì)導(dǎo)致沖突過(guò)多;如果太小,會(huì)導(dǎo)致內(nèi)存浪費(fèi)嚴(yán)重. 通過(guò)設(shè)置裝載因子的閾值來(lái)控制是擴(kuò)容還是縮容,支持動(dòng)態(tài)擴(kuò)容的散列表,插入數(shù)據(jù)的時(shí)間復(fù)雜度使用攤還分析法。
裝載因子閾值的設(shè)置要權(quán)衡時(shí)間、空間復(fù)雜度。如果內(nèi)存空間不緊張,對(duì)執(zhí)行效率要求很高,可以降低負(fù)載因子的閾值;相反,如果內(nèi)存空間緊張,對(duì)執(zhí)行效率要求又不高,可以增加負(fù)載因子的值,甚至可以大于 1。
分批擴(kuò)容:
為了解決一次性擴(kuò)容耗時(shí)過(guò)多的情況,分批完成:
①分批擴(kuò)容的插入操作:當(dāng)有新數(shù)據(jù)要插入時(shí),我們將數(shù)據(jù)插入新的散列表,并且從老的散列表中拿出一個(gè)數(shù)據(jù)放入新散列表。每次插入都重復(fù)上面的過(guò)程。這樣插入操作就變得很快了。
②分批擴(kuò)容的查詢操作:先查新散列表,再查老散列表。
③通過(guò)分批擴(kuò)容的方式,任何情況下,插入一個(gè)數(shù)據(jù)的時(shí)間復(fù)雜度都是O(1)。
小結(jié):散列表支持插入、查找操作,還支持刪除。常用的散列沖突解決方法有兩類,開(kāi)放尋址法和鏈表法。其中采用開(kāi)放尋址法解決沖突時(shí),刪除需特殊注意標(biāo)記,以保證原有查找算法的有效。散列函數(shù)設(shè)計(jì)原則要合適,不能太復(fù)雜,也不能散列沖突太多。裝載因子過(guò)大可能導(dǎo)致沖突頻繁,過(guò)小可能造成空間浪費(fèi)。以及裝載因子過(guò)大時(shí),避免低效擴(kuò)容如何分批擴(kuò)容。
Java 中 LinkedHashMap 、HashMap 就采用了鏈表法解決沖突,ThreadLocalMap 是通過(guò)線性探測(cè)的開(kāi)放尋址法來(lái)解決沖突。
四、哈希函數(shù)
1、哈希函數(shù)
將任意長(zhǎng)度的二進(jìn)制值串映射為固定長(zhǎng)度的二進(jìn)制值串,這個(gè)映射的規(guī)則就是哈希算法,而通過(guò)原始數(shù)據(jù)映射之后得到的二進(jìn)制值串就是哈希值。
2、優(yōu)秀的哈希算法需要滿足的幾點(diǎn)要求:
①單向哈希:
從哈希值不能反向推導(dǎo)出哈希值(所以哈希算法也叫單向哈希算法)。
②篡改無(wú)效:
對(duì)輸入敏感,哪怕原始數(shù)據(jù)只修改一個(gè)Bit,最后得到的哈希值也大不相同。
③散列沖突:
散列沖突的概率要很小,對(duì)于不同的原始數(shù)據(jù),哈希值相同的概率非常小。
④執(zhí)行效率:
哈希算法的執(zhí)行效率要盡量高效,針對(duì)較長(zhǎng)的文本,也能快速計(jì)算哈希值。
3、哈希算法的應(yīng)用
最常見(jiàn)的幾個(gè)應(yīng)用:安全加密、唯一標(biāo)識(shí)、數(shù)據(jù)校驗(yàn)、散列函數(shù)、負(fù)載均衡、數(shù)據(jù)分片、分布式存儲(chǔ)等。例如:
安全加密:
最常用于加密的哈希算法:
MD5 Message-Digest Algorithm,MD5消息摘要算法
SHA:Secure Hash Algorithm,安全散列算法
DES:Data Encryption Standard,數(shù)據(jù)加密標(biāo)準(zhǔn)
AES:Advanced Encryption Standard,高級(jí)加密標(biāo)準(zhǔn)
負(fù)載均衡算法有很多,比如輪詢、隨機(jī)、加權(quán)輪詢等。
鹽
原密碼是123456,如果加鹽,密碼123456加鹽后可能是12ng34qq56zz,再對(duì)加鹽后的密碼進(jìn)行hash后值就與原密碼hash后的值完全不同了。而且加鹽的方式有很多種,可以是在頭部加,可以在尾部加,還可在內(nèi)容中間加,甚至加的鹽還可以是隨機(jī)的。這樣即使用戶使用的是最常用的密碼,黑客拿到密文后破解的難度也很高。也是一種常見(jiàn)的應(yīng)用,防止攻擊字典表的一種方案。