
綜述 | 多模態(tài) LLM,大模型的未來
本文來源 機器之心編輯部
多模態(tài)大型語言模型進展如何? 盤點 26 個當前最佳多模態(tài)大型語言模型。
當前 AI 領域的關注重心正從大型語言模型(LLM)向多模態(tài)轉(zhuǎn)移,于是乎,讓 LLM 具備多模態(tài)能力的多模態(tài)大型語言模型(MM-LLM)就成了一個備受關注的研究主題。
近日,騰訊 AI Lab、京都大學和穆罕默德?本?扎耶德人工智能大學的一個研究團隊發(fā)布了一份綜述報告,全面梳理了 MM-LLM 的近期進展。文中不僅總結(jié)了 MM-LLM 的模型架構(gòu)和訓練流程,而且還梳理了 26 個當前最佳的 MM-LLM。如果你正考慮研究或使用 MM-LLM,不妨考慮從這份報告開始研究,找到最符合你需求的模型。

-
論文標題:MM-LLMs: Recent Advances in MultiModal Large Language Models
-
論文地址:https://arxiv.org/abs/2401.13601
報告概覽
近些年來,多模態(tài)(MM)預訓練研究進展迅速,讓許多下游任務的性能不斷突破到新的邊界。但是,隨著模型和數(shù)據(jù)集規(guī)模不斷擴大,傳統(tǒng)多模態(tài)模型也遭遇了計算成本過高的問題,尤其是當從頭開始訓練時。考慮到多模態(tài)研究位于多種模態(tài)的交叉領域,一種合乎邏輯的方法是充分利用現(xiàn)成的預訓練單模態(tài)基礎模型,尤其是強大的大型語言模型(LLM)。
這一策略的目標是降低多模態(tài)預訓練的計算成本并提升其效率,這樣一來就催生出了一個全新領域:MM-LLM,即多模態(tài)大型語言模型。
MM-LLM 使用 LLM 提供認知功能,讓其處理各種多模態(tài)任務。LLM 能提供多種所需能力,比如穩(wěn)健的語言泛化能力、零樣本遷移能力和上下文學習(ICL)。與此同時,其它模態(tài)的基礎模型卻能提供高質(zhì)量的表征。考慮到不同模態(tài)的基礎模型都是分開預訓練的,因此 MM-LLM 面臨的核心挑戰(zhàn)是如何有效地將 LLM 與其它模態(tài)的模型連接起來以實現(xiàn)協(xié)作推理。
在這個領域內(nèi),人們關注的主要焦點是優(yōu)化提升模態(tài)之間的對齊(alignment)以及讓模型與人類意圖對齊。這方面使用的主要工作流程是多模態(tài)預訓練(MM PT)+ 多模態(tài)指令微調(diào)(MM IT)。
2023 年發(fā)布的 GPT-4 (Vision) 和 Gemini 展現(xiàn)出了出色的多模態(tài)理解和生成能力;由此激發(fā)了人們對 MM-LLM 的研究熱情。
一開始,研究社區(qū)主要關注的是多模態(tài)內(nèi)容理解和文本生成,此類模型包括 (Open) Flamingo、BLIP-2、Kosmos-1、LLaVA/LLaVA-1.5、MiniGPT-4、MultiModal-GPT、VideoChat、Video-LLaMA、IDEFICS、Fuyu-8B、Qwen-Audio。
為了創(chuàng)造出能同時支持多模態(tài)輸入和輸出的 MM-LLM,還有一些研究工作探索了特定模態(tài)的生成,比如 Kosmos-2 和 MiniGPT-5 研究的是圖像生成,SpeechGPT 則聚焦于語音生成。
近期人們關注的重點是模仿類似人類的任意模態(tài)到任意模態(tài)的轉(zhuǎn)換,而這或許是一條通往通用人工智能(AGI)之路。
一些研究的目標是將 LLM 與外部工具合并,以達到近似的任意到任意的多模態(tài)理解和生成;這類研究包括 Visual-ChatGPT、ViperGPT、MM-REACT、HuggingGPT、AudioGPT。
反過來,為了減少級聯(lián)系統(tǒng)中傳播的錯誤,也有一些研究團隊想要打造出端到端式的任意模態(tài) MM-LLM;這類研究包括 NExT-GPT 和 CoDi-2。
圖 1 給出了 MM-LLM 的時間線。

為了促進 MM-LLM 的研究發(fā)展,騰訊 AI Lab、京都大學和穆罕默德?本?扎耶德人工智能大學的這個團隊整理出了這份綜述報告。機器之心整理了該報告的主干部分,尤其是其中對 26 個當前最佳(SOTA)MM-LLM 的介紹。
模型架構(gòu)
這一節(jié),該團隊詳細梳理了一般模型架構(gòu)的五大組件,另外還會介紹每個組件的實現(xiàn)選擇,如圖 2 所示。
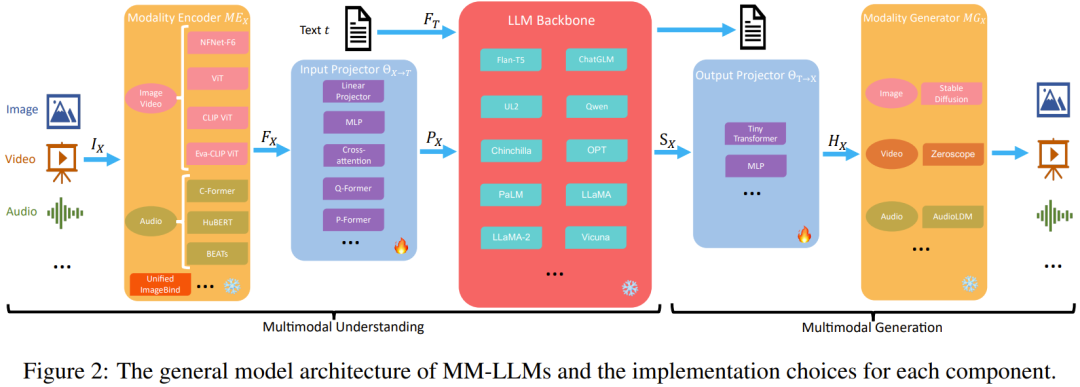
專注于多模態(tài)理解的 MM-LLM 僅包含前三個組件。
在訓練階段,模態(tài)編碼器、LLM 骨干和模態(tài)生成器通常保持在凍結(jié)狀態(tài)。其優(yōu)化的要點是輸入和輸出投影器。由于投影器是輕量級的組件,因此相比于總參數(shù)量,MM-LLM 中可訓練參數(shù)的占比非常小(通常約為 2%)。總參數(shù)量取決于 MM-LLM 中使用的核心 LLM 的規(guī)模。因此,在針對各種多模態(tài)任務訓練 MM-LLM 時,可以取得很高的訓練效率。
模態(tài)編碼器(Modality Encoder/ME):編碼不同模態(tài)的輸入,以得到相應的特征。
輸入投影器(Input Projector):將已編碼的其它模態(tài)的特征與文本特征空間對齊。
LLM 骨干:MM-LLM 使用 LLM 作為核心智能體,因此也繼承了 LLM 的一些重要特性,比如零樣本泛化、少樣本上下文學習、思維鏈(CoT)和指令遵從。LLM 骨干的任務是處理各種模態(tài)的表征,其中涉及到與輸入相關的語義理解、推理和決策。它的輸出包括 (1) 直接的文本輸出,(2) 其它模態(tài)的信號 token(如果有的話)。這些信號 token 可用作引導生成器的指令 —— 是否生成多模態(tài)內(nèi)容,如果是,則指定所要生成的內(nèi)容。
MM-LLM 中常用的 LLM 包括 Flan-T5、ChatGLM、UL2、Qwen、Chinchilla、OPT、PaLM、LLaMA、LLaMA-2、Vicuna。
輸出投影器:將來自 LLM 骨干的信號 token 表征映射成可被后續(xù)模態(tài)生成器理解的特征。
模態(tài)生成器:生成不同對應模態(tài)的輸出。目前的研究工作通常是使用現(xiàn)有的隱擴散模型(LDM),即使用 Stable Diffusion 來合成圖像、使用 Zeroscope 來合成視頻、使用 AudioLDM-2 來合成音頻。
訓練流程
MM-LLM 的訓練流程可以分為兩個主要階段:MM PT(多模態(tài)預訓練)和 MM IT(多模態(tài)指令微調(diào))。
MM PT
在預訓練階段(通常是利用 XText 數(shù)據(jù)集),通過優(yōu)化預定義的目標來訓練輸入和輸出投影器,使其對齊不同的模態(tài)。(有時候也會將參數(shù)高效型微調(diào)(PEFT)技術(shù)用于 LLM 骨干。)
MM IT
MM IT 這種方法需要使用一組指令格式的數(shù)據(jù)集對預訓練的 MM-LLM 進行微調(diào)。通過這個微調(diào)過程,MM-LLM 可以泛化到未曾見過的任務,執(zhí)行新指令,從而增強零樣本性能。
MM IT 包含監(jiān)督式微調(diào)(SFT)和根據(jù)人類反饋的強化學習(RLHF),目標是與人類意圖或偏好對齊并提升 MM-LLM 的交互能力。
SFT 可將預訓練階段的部分數(shù)據(jù)轉(zhuǎn)換成指令感知型的格式。
SFT 之后,RLHF 會對模型進行進一步的微調(diào),這需要有關 MM-LLM 所給響應的反饋信息(比如由人類或 AI 標注的自然語言反饋(NLF))。這個過程采用了一種強化學習算法來有效整合不可微分的 NLF。模型的訓練目標是根據(jù) NLF 生成對應的響應。
現(xiàn)有的 MM-LLM 在 MM PT 和 MM IT 階段使用的數(shù)據(jù)集有很多,但它們都是表 3 和表 4 中數(shù)據(jù)集的子集。
當前最佳的 MM-LLM
該團隊比較了 26 個當前最佳(SOTA)MM-LLM 的架構(gòu)和訓練數(shù)據(jù)集規(guī)模,如表 1 所示。另外他們還簡單總結(jié)了每種模型的核心貢獻和發(fā)展趨勢。

(1) Flamingo:一系列設計用于處理交織融合的視覺數(shù)據(jù)和文本的視覺語言(VL)模型,可輸出自由形式的文本。
(2) BLIP-2:提出了一種能更高效利用資源的框架,其中使用了輕量級的 Q-Former 來連接不同模態(tài),還使用了凍結(jié)的 LLM。使用 LLM,可通過自然語言 prompt 引導 BLIP-2 執(zhí)行零樣本圖像到文本生成。
(3) LLaVA:率先將指令微調(diào)技術(shù)遷移到多模態(tài)領域。為了解決數(shù)據(jù)稀疏性問題,LLaVA 使用 ChatGPT/GPT-4 創(chuàng)建了一個全新的開源多模態(tài)指令遵從數(shù)據(jù)集和一個多模態(tài)指令遵從基準 LLaVA-Bench。
(4) MiniGPT-4:提出了一種經(jīng)過精簡的方法,其中僅訓練一個線性層來對齊預訓練視覺編碼器與 LLM。這種高效方法展現(xiàn)出的能力能媲美 GPT-4。
(5) mPLUG-Owl:提出了一種全新的用于 MM-LLM 的模塊化訓練框架,并整合了視覺上下文。為了評估不同模型在多模態(tài)任務上的性能,該框架還包含一個指示性的評估數(shù)據(jù)集 OwlEval。
(6) X-LLM:擴展到了包括音頻在內(nèi)的多個模態(tài),展現(xiàn)出了強大的可擴展性。利用了 QFormer 的語言可遷移能力,X-LLM 成功在漢藏語系漢語語境中得到了應用。
(7) VideoChat:開創(chuàng)了一種高效的以聊天為中心的 MM-LLM 可用于進行視頻理解對話。這項研究為該領域的未來研究設定了標準,并為學術(shù)界和產(chǎn)業(yè)界提供了協(xié)議。
(8) InstructBLIP:該模型是基于 BLIP-2 模型訓練得到的,在 MM IT 階段僅更新了 Q-Former。通過引入指令感知型的視覺特征提取和對應的指令,該模型可以提取靈活且多樣化的特征。
(9) PandaGPT 是一種開創(chuàng)性的通用模型,有能力理解 6 種不同模態(tài)的指令并遵照行事:文本、圖像 / 視頻、音頻、熱量、深度和慣性測量單位。
(10) PaLIX:其訓練過程使用了混合的視覺語言目標和單模態(tài)目標,包括前綴補全和掩碼 token 補全。研究表明,這種方法可以有效用于下游任務,并在微調(diào)設置中到達了帕累托邊界。
(11) Video-LLaMA:提出了一種多分支跨模態(tài)預訓練框架,讓 LLM 可以在與人類對話的同時處理給定視頻的視覺和音頻內(nèi)容。該框架對齊了視覺與語言以及音頻與語言。
(12) Video-ChatGPT:該模型是專門針對視頻對話任務設計的,可以通過整合時空視覺表征來生成有關視頻的討論。
(13) Shikra:提出了一種簡單但統(tǒng)一的預訓練 MM-LLM,并且專門針對參考對話(Referential Dialogue)任務進行了調(diào)整。參考對話任務涉及到討論圖像中的區(qū)域和目標。該模型表現(xiàn)出了值得稱道的泛化能力,可有效處理未曾見過的情況。
(14) DLP:提出了用于預測理想 prompt 的 P-Former,并在一個單模態(tài)語句的數(shù)據(jù)集上完成了訓練。這表明單模態(tài)訓練可以用于增強多模態(tài)學習。
(15) BuboGPT:為了全面理解多模態(tài)內(nèi)容,該模型在構(gòu)建時學習了一個共享式語義空間。其探索了圖像、文本和音頻等不同模態(tài)之間的細粒度關系。
(16) ChatSpot:提出了一種簡單卻有效的方法,可為 MM-LLM 精細化調(diào)整精確引用指令,從而促進細粒度的交互。通過集成精確引用指令(由圖像級和區(qū)域級指令構(gòu)成),多粒度視覺語言任務描述得以增強。
(17) Qwen-VL:一種支持英語和漢語的多語言 MM-LLM。Qwen-VL 還允許在訓練階段輸入多張圖像,這能提高其理解視覺上下文的能力。
(18) NExT-GPT:這是一種端到端、通用且支持任意模態(tài)到任意模態(tài)的 MM-LLM,支持自由輸入和輸出圖像、視頻、音頻和文本。其采用了一種輕量的對齊策略 —— 在編碼階段使用以 LLM 為中心的對齊,在解碼階段使用指令遵從對齊。
(19) MiniGPT-5:這種 MM-LLM 整合了轉(zhuǎn)化成生成式 voken 的技術(shù),并集成了 Stable Diffusion。它擅長執(zhí)行交織融合了視覺語言輸出的多模態(tài)生成任務。其在訓練階段加入了無分類器指導,以提升生成質(zhì)量。
(20) LLaVA-1.5:該模型基于 LLaVA 框架并進行了簡單的修改,包括使用一種 MLP 投影,引入針對學術(shù)任務調(diào)整過的 VQA 數(shù)據(jù),以及使用響應格式簡單的 prompt。這些調(diào)整讓模型的多模態(tài)理解能力得到了提升。
(21) MiniGPT-v2:這種 MM-LLM 的設計目標是作為多樣化視覺語言多任務學習的一個統(tǒng)一接口。為了打造出能熟練處理多種視覺語言任務的單一模型,每個任務的訓練和推理階段都整合了標識符(identifier)。這有助于明確的任務區(qū)分,并最終提升學習效率。
(22) CogVLM:一種開源 MM-LLM,其通過一種用在注意力和前饋層中的可訓練視覺專家模塊搭建了不同模態(tài)之間的橋梁。這能讓多模態(tài)特征深度融合,同時不會損害在下游 NLP 任務上的性能。
(23) DRESS:提出了一種使用自然語言反饋提升與人類偏好的對齊效果的方法。DRESS 擴展了條件式強化學習算法以整合不可微分的自然語言反饋,并以此訓練模型根據(jù)反饋生成適當?shù)捻憫?/span>
(24) X-InstructBLIP:提出了一種使用指令感知型表征的跨模態(tài)框架,足以擴展用于助力 LLM 處理跨多模態(tài)(包括圖像 / 視頻、音頻和 3D)的多樣化任務。值得注意的是,它不需要特定模態(tài)的預訓練就能做到這一點。
(25) CoDi-2:這是一種多模態(tài)生成模型,可以出色地執(zhí)行多模態(tài)融合的指令遵從、上下文生成以及多輪對話形式的用戶 - 模型交互。它是對 CoDi 的增強,使其可以處理復雜的模態(tài)交織的輸入和指令,以自回歸的方式生成隱含特征。
(26) VILA:該模型在視覺任務上的性能出色,并能在保持純文本能力的同時表現(xiàn)出卓越的推理能力。VILA 之所以性能優(yōu)異,是因為其充分利用了 LLM 的學習能力,使用了圖像 - 文本對的融合屬性并實現(xiàn)了精細的文本數(shù)據(jù)重新混合。
當前 MM-LLM 的發(fā)展趨勢:
(1) 從專注于多模態(tài)理解向特定模態(tài)生成發(fā)展,并進一步向任意模態(tài)到任意模態(tài)轉(zhuǎn)換發(fā)展(比如 MiniGPT-4 → MiniGPT-5 → NExT-GPT)。
(2) 從 MM PT 到 SFT 再到 RLHF,訓練流程持續(xù)不斷優(yōu)化,力求更好地與人類意圖對齊并增強模型的對話互動能力(比如 BLIP-2 → InstructBLIP → DRESS)。
(3) 擁抱多樣化的模態(tài)擴展(比如 BLIP-2 → X-LLM 和 InstructBLIP → X-InstructBLIP)。
(4) 整合質(zhì)量更高的訓練數(shù)據(jù)集(比如 LLaVA → LLaVA-1.5)。
(5) 采用更高效的模型架構(gòu),從 BLIP-2 和 DLP 中復雜的 Q-Former 和 P-Former 輸入投射器模塊到 VILA 中更簡單卻有效的線性投影器。
基準和性能
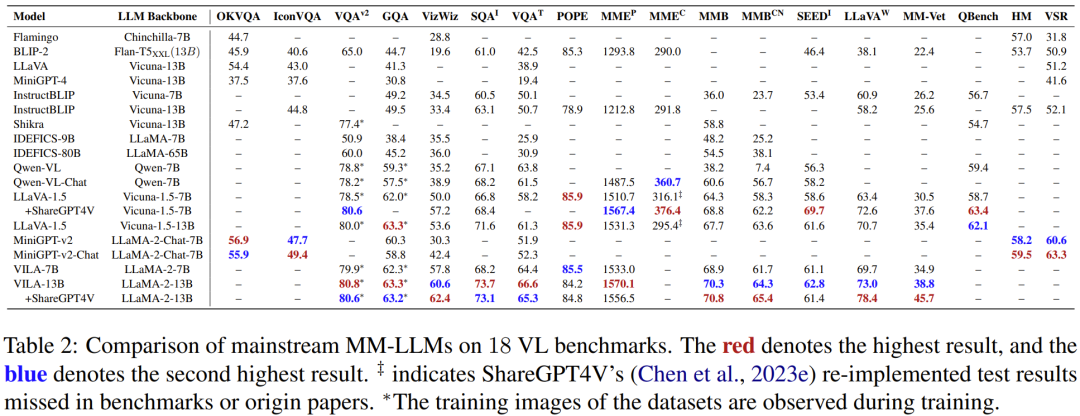
為了全面比較各模型的性能,該團隊編制了一個表格,其中包含從多篇論文中收集的主要 MM-LLM 的數(shù)據(jù),涉及 18 個視覺語言基準,見表 2。
未來方向
該團隊最后討論了 MM-LLM 領域比較有前景的一些未來研究方向:
-
更強大的模型:增強 MM-LLM 的能力,其中主要通過這四個關鍵途徑:擴展模態(tài)、實現(xiàn) LLM 多樣化、提升多模態(tài)指令微調(diào)的數(shù)據(jù)集質(zhì)量、增強多模態(tài)生成能力。
-
難度更大的基準
-
移動 / 輕量級部署
-
具身智能
-
持續(xù)指令微調(diào)
關注公眾號【機器學習與AI生成創(chuàng)作】,更多精彩等你來讀
不是一杯奶茶喝不起,而是我T M直接用來跟進 AIGC+CV視覺 前沿技術(shù),它不香?!
臥剿,6萬字!30個方向130篇!CVPR 2023 最全 AIGC 論文!一口氣讀完
深入淺出stable diffusion:AI作畫技術(shù)背后的潛在擴散模型論文解讀
深入淺出ControlNet,一種可控生成的AIGC繪畫生成算法!
 戳我,查看GAN的系列專輯~! 最新最全100篇匯總!生成擴散模型Diffusion Models ECCV2022 | 生成對抗網(wǎng)絡GAN部分論文匯總
戳我,查看GAN的系列專輯~! 最新最全100篇匯總!生成擴散模型Diffusion Models ECCV2022 | 生成對抗網(wǎng)絡GAN部分論文匯總 CVPR 2022 | 25+方向、最新50篇GAN論文
ICCV 2021 | 35個主題GAN論文匯總
超110篇!CVPR 2021最全GAN論文梳理
超100篇!CVPR 2020最全GAN論文梳理
附下載 |《TensorFlow 2.0 深度學習算法實戰(zhàn)》
《基于深度神經(jīng)網(wǎng)絡的少樣本學習綜述》
《禮記·學記》有云:獨學而無友,則孤陋而寡聞
點擊 跟進 AIGC+CV視覺 前沿技術(shù),真香! ,加入 AI生成創(chuàng)作與計算機視覺 知識星球!