
多模態(tài)機(jī)器學(xué)習(xí)綜述
參考文獻(xiàn):T. Baltru?aitis, C. Ahuja and L. Morency, "Multimodal Machine Learning: A Survey and Taxonomy," in IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI), vol. 41, no. 2, pp. 423-443, 1 Feb. 2019.
【摘要】我們對(duì)世界的體驗(yàn)是多模式的,我們看到物體,聽(tīng)到聲音,感覺(jué)到紋理,聞到氣味和嘗到味道。模態(tài)是指某種事物發(fā)生或經(jīng)歷的方式,并且當(dāng)研究問(wèn)題包括多種這樣的形式時(shí),研究問(wèn)題被描述為多模態(tài)。為了使人工智能在理解我們周?chē)氖澜绶矫嫒〉眠M(jìn)展,它需要能夠一起解釋這種多模信號(hào)。多模式機(jī)器學(xué)習(xí)旨在構(gòu)建可以處理和關(guān)聯(lián)來(lái)自多種模態(tài)信息的模型。這是一個(gè)充滿活力的多學(xué)科領(lǐng)域,具有越來(lái)越重要的意義和非凡的潛力。本文不是關(guān)注特定的多模態(tài)應(yīng)用,而是研究多模態(tài)機(jī)器學(xué)習(xí)本身的最新進(jìn)展。我們超越了典型的早期和晚期融合分類,并確定了多模式機(jī)器學(xué)習(xí)所面臨的更廣泛的挑戰(zhàn),即:表示,翻譯,對(duì)齊,融合和共同學(xué)習(xí)。這種新的分類法將使研究人員能夠更好地了解該領(lǐng)域的狀況,并確定未來(lái)研究的方向。
關(guān)鍵字:多模態(tài) 機(jī)器學(xué)習(xí) 介紹 綜述
1 介紹????
1、我們周?chē)氖澜缬卸喾N模式-我們看到物體,聽(tīng)到聲音,感覺(jué)質(zhì)地,聞到氣味,等等。一般來(lái)說(shuō),模態(tài)是指某物發(fā)生或經(jīng)歷的方式。大多數(shù)人把模態(tài)這個(gè)詞與代表我們主要溝通和感知渠道的感覺(jué)方式聯(lián)系起來(lái),如視覺(jué)和觸覺(jué)。因此,當(dāng)一個(gè)研究問(wèn)題或數(shù)據(jù)集包含多個(gè)這樣的模式時(shí),它就具有多模態(tài)的特征。在本文中,我們主要關(guān)注但不限定三種模式:既可以寫(xiě)也可以說(shuō)的自然語(yǔ)言;通常用圖像或視頻表示的視覺(jué)信號(hào);編碼聲音和副詞信息的聲音信號(hào),如韻律、聲樂(lè)等。
2、為了讓人工智能在了解我們周?chē)氖澜绶矫嫒〉眠M(jìn)展,它需要能夠解釋和推理多模態(tài)信息。多模態(tài)機(jī)器學(xué)習(xí)旨在建立能夠處理和關(guān)聯(lián)來(lái)自多個(gè)模態(tài)的信息的模型。從早期的視聽(tīng)語(yǔ)音識(shí)別研究到最近對(duì)語(yǔ)言和視覺(jué)模型的興趣激增,多模態(tài)機(jī)器學(xué)習(xí)是一個(gè)充滿活力的多學(xué)科領(lǐng)域,并且重要性日益提高,潛力巨大。
3、由于數(shù)據(jù)的異構(gòu)性,多模態(tài)機(jī)器學(xué)習(xí)的研究領(lǐng)域給計(jì)算研究者帶來(lái)了一些獨(dú)特的挑戰(zhàn)。從多模態(tài)信息源中學(xué)習(xí)提供了捕獲模態(tài)之間的對(duì)應(yīng)關(guān)系并獲得對(duì)自然現(xiàn)象深入理解的可能性。本文對(duì)多模態(tài)機(jī)器學(xué)習(xí)的五個(gè)核心技術(shù)挑戰(zhàn)(及其相關(guān)子挑戰(zhàn))進(jìn)行了識(shí)別和探討。
它們是多模態(tài)學(xué)習(xí)的中心,需要處理才能促進(jìn)該領(lǐng)域發(fā)展。我們的綜述超越了典型的早期和晚期融合分割,包括以下五個(gè)挑戰(zhàn):
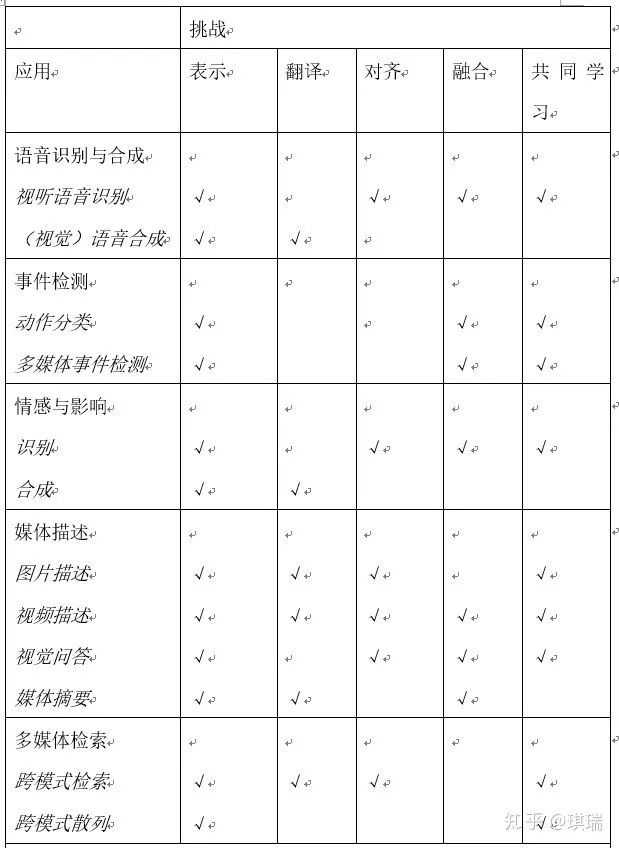
表示:第一個(gè)基本挑戰(zhàn)是學(xué)習(xí)如何以一種利用多種模態(tài)的互補(bǔ)性和冗余性的方式表示和匯總多模式數(shù)據(jù)。多模數(shù)據(jù)的異構(gòu)性使得構(gòu)造這樣的表示方法具有挑戰(zhàn)性。例如,語(yǔ)言通常是象征性的,而音頻和視頻形式將被表示為信號(hào)。
翻譯:第二個(gè)挑戰(zhàn)是如何將數(shù)據(jù)從一種模式轉(zhuǎn)換(映射)到另一種模式。不僅異構(gòu)數(shù)據(jù),而且模式之間的關(guān)系往往是開(kāi)放的或主觀的。例如,有許多正確的方法來(lái)描述一個(gè)圖像,一個(gè)完美的映射可能不存在。
對(duì)齊:第三個(gè)挑戰(zhàn)是確定來(lái)自兩種或兩種以上不同模式的(子)元素之間的直接關(guān)系。例如,我們可能希望將菜譜中的步驟與顯示正在制作的菜肴的視頻對(duì)齊。為了解決這一挑戰(zhàn),我們需要度量不同模式之間的相似性,并處理可能的長(zhǎng)期依賴性和模糊性。
融合:第四個(gè)挑戰(zhàn)是連接來(lái)自兩個(gè)或多個(gè)模式的信息來(lái)執(zhí)行預(yù)測(cè)。例如,在視聽(tīng)語(yǔ)音識(shí)別中,將唇動(dòng)的視覺(jué)描述與語(yǔ)音信號(hào)融合,預(yù)測(cè)語(yǔ)音單詞。來(lái)自不同模式的信息可能具有不同的預(yù)測(cè)能力和噪聲拓?fù)浣Y(jié)構(gòu),其中至少有一種模式可能丟失數(shù)據(jù)。
共同學(xué)習(xí):第五個(gè)挑戰(zhàn)是在模態(tài)、它們的表示和它們的預(yù)測(cè)模型之間傳遞知識(shí)。這一點(diǎn)可以用協(xié)同訓(xùn)練、概念基礎(chǔ)和零樣本學(xué)習(xí)的算法來(lái)舉例說(shuō)明。協(xié)同學(xué)習(xí)探索了從一個(gè)模態(tài)中學(xué)習(xí)知識(shí)如何幫助在不同模態(tài)中訓(xùn)練的計(jì)算模型。當(dāng)其中一種模式的資源有限(例如,注釋數(shù)據(jù))時(shí),這一挑戰(zhàn)尤其重要。
針對(duì)這五個(gè)挑戰(zhàn)中的每一個(gè),我們定義了分類和子類,以幫助構(gòu)建多模態(tài)機(jī)器學(xué)習(xí)這一新興研究領(lǐng)域的最新工作。我們首先討論多模態(tài)機(jī)器學(xué)習(xí)的主要應(yīng)用(第2節(jié)),然后討論多模態(tài)機(jī)器學(xué)習(xí)面臨的五個(gè)核心技術(shù)挑戰(zhàn)的最新發(fā)展:表示(第3節(jié))、翻譯(第4節(jié))、對(duì)齊(第5節(jié))、融合(第6節(jié))和共同學(xué)習(xí)(第7節(jié))。最后,我們將在第8節(jié)進(jìn)行討論。
2 應(yīng)用:歷史視角
1、多模式機(jī)器學(xué)習(xí)可以實(shí)現(xiàn)廣泛的應(yīng)用:從視聽(tīng)語(yǔ)音識(shí)別到圖像描述。在本節(jié)中,我們簡(jiǎn)要介紹了多模應(yīng)用的歷史,從視聽(tīng)語(yǔ)音識(shí)別的開(kāi)始到最近對(duì)語(yǔ)言和視覺(jué)應(yīng)用的新興趣。
2、多模態(tài)研究最早的例子之一是視聽(tīng)語(yǔ)音識(shí)別(audio-visual speech recognition ? avsr)[243]。它的靈感來(lái)自麥格克效應(yīng)(McGurk effect)[138]——在語(yǔ)音感知過(guò)程中聽(tīng)覺(jué)和視覺(jué)之間的相互作用。當(dāng)受試者在觀看一個(gè)人說(shuō)/ga-ga/時(shí)聽(tīng)到音節(jié)/ba-ba/,他們感覺(jué)到第三個(gè)聲音是/da-da/。在給自愿者放映的一部影片中,一個(gè)音節(jié)“ga”在配音時(shí)發(fā)作了“ba”,而自愿者稱聽(tīng)到的音節(jié)是卻是“da”。這樣一來(lái),視聽(tīng)信息聯(lián)手創(chuàng)造出了第三種全新的聲音,這個(gè)過(guò)程現(xiàn)在被叫做“麥格克效應(yīng)”。這是大腦對(duì)于來(lái)自眼睛和耳朵所提供的矛盾信息的努力猜測(cè),這個(gè)理論也證明眼睛(視覺(jué)信息)對(duì)于大腦意識(shí)與知覺(jué)的影響比其他感覺(jué)器官所提供的信息更大。另一項(xiàng)研究發(fā)現(xiàn),視覺(jué)信息的不一致可以改變對(duì)于口語(yǔ)發(fā)音的感知,這表明了麥格克效應(yīng)可能在人們生活中許多外在感知上產(chǎn)生影響。
這些結(jié)果激發(fā)了許多來(lái)自言語(yǔ)社區(qū)的研究者們用視覺(jué)信息來(lái)擴(kuò)展他們的研究方法。考慮到隱藏馬爾可夫模型(hidden Markov model, HMMs)在當(dāng)時(shí)的語(yǔ)音社區(qū)中的突出地位[95],AVSR的許多早期模型基于各種HMM擴(kuò)展[24]、[25]就不足為奇了。雖然目前對(duì)AVSR的研究并不常見(jiàn),但它已經(jīng)引起了深度學(xué)習(xí)界的新興趣[151]。
3、雖然AVSR的原始視覺(jué)是為了提高語(yǔ)音識(shí)別性能(例如,字錯(cuò)誤率),但實(shí)驗(yàn)結(jié)果表明,視覺(jué)信息的主要優(yōu)點(diǎn)提現(xiàn)在當(dāng)語(yǔ)音信號(hào)有噪聲(即,低信噪比)時(shí)[75]、[151]、[243]。換言之,模式之間的相互作用是增補(bǔ)的而不是補(bǔ)充(疊加式而非互補(bǔ)式)。兩種方法都獲得了相同的信息,提高了多模態(tài)模型的魯棒性,但沒(méi)有改善無(wú)噪聲場(chǎng)景下的語(yǔ)音識(shí)別性能。
4、第二種重要的多模態(tài)應(yīng)用來(lái)自多媒體內(nèi)容索引和檢索領(lǐng)域[11],[188]。隨著個(gè)人電腦和互聯(lián)網(wǎng)的發(fā)展,數(shù)字化多媒體內(nèi)容的數(shù)量急劇增加。[2] 雖然早期索引和搜索這些多媒體視頻的方法是基于關(guān)鍵字的[188],但在嘗試直接搜索視覺(jué)和多模態(tài)內(nèi)容時(shí)出現(xiàn)了新的研究問(wèn)題。這導(dǎo)致了多媒體內(nèi)容分析領(lǐng)域的新研究課題,如自動(dòng)鏡頭邊界檢測(cè)[123]和視頻總結(jié)[53]。這些研究項(xiàng)目得到了國(guó)家標(biāo)準(zhǔn)與技術(shù)研究所(National Institute of Standards and Technologies)的Trecvid倡議的支持,該倡議引入了許多高質(zhì)量數(shù)據(jù)集,包括2011年開(kāi)始的多媒體事件檢測(cè)(multimedia event detection MED)任務(wù)[1]。
第三類應(yīng)用是在本世紀(jì)初圍繞多模態(tài)交互的新興領(lǐng)域建立的,目的是了解人類在社會(huì)交互過(guò)程中的多模態(tài)行為。AMI會(huì)議語(yǔ)料庫(kù)是該領(lǐng)域最早收集的具有里程碑意義的數(shù)據(jù)集之一,該語(yǔ)料庫(kù)包含100多個(gè)小時(shí)的會(huì)議視頻記錄,全部完整轉(zhuǎn)錄并標(biāo)注了[33]。另一個(gè)重要的數(shù)據(jù)集是SEMAINE語(yǔ)料庫(kù),它可以研究說(shuō)話者和聽(tīng)者之間的人際動(dòng)態(tài)[139]。該數(shù)據(jù)集是2011年組織的第一次視聽(tīng)情感挑戰(zhàn)(AVEC)的基礎(chǔ)[179]。由于自動(dòng)人臉檢測(cè)、面部標(biāo)志物檢測(cè)和面部表情識(shí)別[46]技術(shù)的強(qiáng)大進(jìn)步,情緒識(shí)別和情感計(jì)算領(lǐng)域在2010年代初蓬勃發(fā)展。AVEC的挑戰(zhàn)在之后每年都會(huì)繼續(xù),隨后的實(shí)例化包括醫(yī)療應(yīng)用程序,如抑郁和焦慮的自動(dòng)評(píng)估[208]。D 'Mello 等[50]對(duì)多模態(tài)情感識(shí)別的最新進(jìn)展進(jìn)行了綜述。他們的元分析顯示,最近關(guān)于多模態(tài)情感識(shí)別的大部分研究表明,當(dāng)使用多個(gè)模態(tài)時(shí),多模態(tài)情感識(shí)別效果有所改善,但這種改善在識(shí)別自然發(fā)生的情感時(shí)有所減弱。
最近,出現(xiàn)了一種強(qiáng)調(diào)語(yǔ)言和視覺(jué)的多模態(tài)應(yīng)用新類別:媒體描述。最具代表性的應(yīng)用程序之一是圖像描述,其中的任務(wù)是生成輸入圖像的文本描述[83]。這是由這種系統(tǒng)幫助視障人士完成日常任務(wù)的能力。媒體描述面臨的主要挑戰(zhàn)是評(píng)價(jià):如何評(píng)價(jià)預(yù)測(cè)描述的質(zhì)量。視覺(jué)問(wèn)答(visual question-answering, VQA)的任務(wù)最近提出,以解決一些評(píng)價(jià)挑戰(zhàn)的[9],其中的目標(biāo)是回答有關(guān)圖像的特定問(wèn)題。
為了將上述的一些應(yīng)用帶到現(xiàn)實(shí)世界中,我們需要解決多模態(tài)機(jī)器學(xué)習(xí)所面臨的一些技術(shù)挑戰(zhàn)。我們?cè)诒?中總結(jié)了上述應(yīng)用領(lǐng)域的相關(guān)技術(shù)挑戰(zhàn)。最重要的挑戰(zhàn)之一是多模態(tài)表示,這是我們下一節(jié)的重點(diǎn)。
3、多模態(tài)表示
以計(jì)算模型可以使用的格式表示原始數(shù)據(jù)一直是機(jī)器學(xué)習(xí)中的一大挑戰(zhàn)。根據(jù)Bengio等人的工作[18],我們可以互換使用術(shù)語(yǔ)“特征”和“表示”,每一個(gè)都指一個(gè)實(shí)體的向量或張量表示,無(wú)論是圖像、音頻樣本、單個(gè)單詞或句子。多模表示是使用來(lái)自多個(gè)這樣的實(shí)體的信息來(lái)表示數(shù)據(jù)的一種表示。表示多種形式存在許多困難:如何組合來(lái)自不同來(lái)源的數(shù)據(jù);如何處理不同級(jí)別的噪聲;以及如何處理丟失的數(shù)據(jù)。以有意義的方式表示數(shù)據(jù)的能力對(duì)于多模式問(wèn)題至關(guān)重要,并且是任何模型的主干。
良好的表示對(duì)于機(jī)器學(xué)習(xí)模型的性能非常重要,這一點(diǎn)在語(yǔ)音識(shí)別和視覺(jué)對(duì)象分類系統(tǒng)的性能最近的飛躍中得到了證明。Bengio等人的[18]識(shí)別了許多良好表示的屬性:平滑性、時(shí)間和空間相干性、稀疏性和自然聚類等。Srivastava和Salakhutdinov[198]確定了多模態(tài)表示的其他理想屬性:表示空間中的相似性應(yīng)該反映出相應(yīng)概念的相似性,即使在沒(méi)有一些模態(tài)的情況下也應(yīng)該很容易得到表示,最后,在給定觀察到的模態(tài)的情況下,應(yīng)該有可能補(bǔ)全缺失的模態(tài)。
單模態(tài)表示的發(fā)展已被廣泛研究[5],[18],[122]。在過(guò)去的十年中,已經(jīng)出現(xiàn)了從手工設(shè)計(jì)的特定應(yīng)用到數(shù)據(jù)驅(qū)動(dòng)的轉(zhuǎn)變。例如,本世紀(jì)初最著名的圖像描述符之一,尺度不變特征變換(SIFT)是人工設(shè)計(jì)的[127],但目前大部分的視覺(jué)描述都是通過(guò)神經(jīng)網(wǎng)絡(luò)(CNN)等神經(jīng)結(jié)構(gòu)從數(shù)據(jù)中學(xué)習(xí)的[109]。類似地,在音頻領(lǐng)域,諸如梅爾頻率倒譜系數(shù)(MFCC)之類的聲學(xué)特征已被語(yǔ)音識(shí)別中的數(shù)據(jù)驅(qū)動(dòng)的深度神經(jīng)網(wǎng)絡(luò)[79]和用于語(yǔ)言分析的遞歸神經(jīng)網(wǎng)絡(luò)所取代[207]。在自然語(yǔ)言處理中,文本特征最初依賴于計(jì)算文檔中的單詞出現(xiàn)次數(shù),但已被利用單詞上下文的數(shù)據(jù)驅(qū)動(dòng)的單詞嵌入(word embeddings)所取代[141]。雖然在單模態(tài)表示方面有大量的工作,但直到最近,大多數(shù)多模態(tài)表示都涉及單模態(tài)的[50]的簡(jiǎn)單連接,但這種情況正在迅速變化。
為了幫助理解工作的廣度,我們提出了兩類多模態(tài)表示:聯(lián)合和協(xié)調(diào)。聯(lián)合表示將單模態(tài)信號(hào)組合到同一個(gè)表示空間中,而協(xié)調(diào)表示單獨(dú)處理單模態(tài)信號(hào),但對(duì)其施加一定的相似性約束,使其達(dá)到我們所說(shuō)的協(xié)調(diào)空間。圖1展示了不同的多模態(tài)表示類型。在數(shù)學(xué)上,聯(lián)合表示為:
xm=f(x1...xn) ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?(1)
其中,多模態(tài)表示xm使用依賴于單模態(tài)表示x1…xn的函數(shù)f(例如,深度神經(jīng)網(wǎng)絡(luò)、受限玻爾茲曼機(jī)或遞歸神經(jīng)網(wǎng)絡(luò))計(jì)算.
協(xié)調(diào)表示如下:f(x1) ~ g(x2) ? ? ? ? ? ? ? ? ? ? ? ? ? (2)
其中每個(gè)模態(tài)都有對(duì)應(yīng)的投影函數(shù)(f和g),將其映射到一個(gè)協(xié)調(diào)的多模態(tài)空間。而投影到每個(gè)形態(tài)的多通道空間是獨(dú)立的,但它們之間產(chǎn)生的結(jié)果空間是協(xié)調(diào)的(表示為~)。這種協(xié)調(diào)的例子包括最小化余弦距離[61],最大化相關(guān)[7],以及在結(jié)果空間之間強(qiáng)制執(zhí)行偏序[212]。
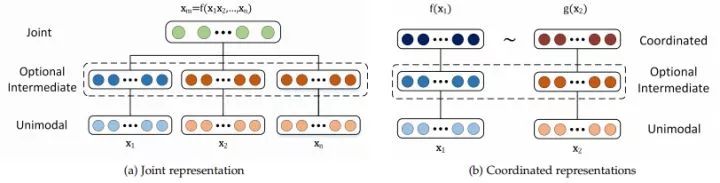
圖一:聯(lián)合表示和協(xié)調(diào)表示的結(jié)構(gòu)。聯(lián)合表示使將關(guān)節(jié)表示投影到同一空間,作為輸入的模式。協(xié)調(diào)表示存在于各自的空間中,但通過(guò)相似性(例如歐幾里得距離)或結(jié)構(gòu)約束(例如部分順序)進(jìn)行協(xié)調(diào)。
3.1 聯(lián)合表示
我們從將單模表示投影到多模空間(方程式1)的聯(lián)合表示開(kāi)始討論。聯(lián)合表示法主要(但不是唯一)用于在訓(xùn)練和推理步驟中同時(shí)存在多模態(tài)數(shù)據(jù)的任務(wù)。聯(lián)合表示的最簡(jiǎn)單示例是單個(gè)模態(tài)特征的串聯(lián)(也稱為早期融合[50])。在本節(jié)中,我們討論了創(chuàng)建聯(lián)合表示的更先進(jìn)的方法,首先是神經(jīng)網(wǎng)絡(luò),然后是圖形模型和循環(huán)神經(jīng)網(wǎng)絡(luò)(代表性工作見(jiàn)表2)。
神經(jīng)網(wǎng)絡(luò)已成為一種非常流行的單模態(tài)數(shù)據(jù)表示方法。它們用于表示視覺(jué)、聲學(xué)和文本數(shù)據(jù),并且越來(lái)越多地用于多模態(tài)領(lǐng)域[151]、[156]和[217]。在本節(jié)中,我們將描述如何使用神經(jīng)網(wǎng)絡(luò)來(lái)構(gòu)建聯(lián)合多模態(tài)表示,如何訓(xùn)練它們,以及它們提供了哪些優(yōu)勢(shì)。
一般來(lái)說(shuō),神經(jīng)網(wǎng)絡(luò)由連續(xù)的內(nèi)積構(gòu)建塊和非線性激活函數(shù)組成。為了使用神經(jīng)網(wǎng)絡(luò)來(lái)表示數(shù)據(jù),首先要訓(xùn)練它執(zhí)行特定的任務(wù)(例如識(shí)別圖像中的對(duì)象)。由于深層神經(jīng)網(wǎng)絡(luò)的多層性,假設(shè)每一層后續(xù)的神經(jīng)網(wǎng)絡(luò)以更抽象的方式來(lái)表示數(shù)據(jù)[18],因此通常使用最后一層或倒數(shù)第二層神經(jīng)網(wǎng)絡(luò)作為一種數(shù)據(jù)表示形式。為了使用神經(jīng)網(wǎng)絡(luò)構(gòu)建一個(gè)多模態(tài)表示,每個(gè)模態(tài)都從幾個(gè)單獨(dú)的神經(jīng)層開(kāi)始,然后是一個(gè)隱藏層,該層將模態(tài)投射到一個(gè)共同空間[9],[145],[156],[227]。
然后,聯(lián)合多模態(tài)表示通過(guò)多個(gè)隱含層本身或直接用于預(yù)測(cè)。這種模型可以進(jìn)行端到端訓(xùn)練——學(xué)習(xí)如何表示數(shù)據(jù)和執(zhí)行特定任務(wù)。在神經(jīng)網(wǎng)絡(luò)中,多模態(tài)表示學(xué)習(xí)與多模態(tài)融合有著密切的關(guān)系。
由于神經(jīng)網(wǎng)絡(luò)需要大量帶標(biāo)簽的訓(xùn)練數(shù)據(jù),因此通常使用自動(dòng)編碼器對(duì)無(wú)監(jiān)督數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練[80]。Ngiam等人提出的模型[151]將使用自動(dòng)編碼器的思想擴(kuò)展到多模域。他們使用堆疊式去噪自動(dòng)編碼器分別表示每個(gè)模態(tài),然后使用另一個(gè)自動(dòng)編碼器層將它們?nèi)诤铣啥嗄B(tài)表示。同樣,Silberer和Lapata[184]提議使用多模自動(dòng)編碼器來(lái)完成語(yǔ)義概念基礎(chǔ)的任務(wù)(見(jiàn)第7.2節(jié))。除了使用重構(gòu)損失訓(xùn)練表示,它們還將一個(gè)術(shù)語(yǔ)引入到使用表示來(lái)預(yù)測(cè)對(duì)象標(biāo)簽的損失函數(shù)中。由于使用AutoEncoder構(gòu)造的表示是通用的,不一定是針對(duì)特定任務(wù)優(yōu)化的,因此通常對(duì)手頭特定任務(wù)的結(jié)果表示進(jìn)行微調(diào)[217]。
基于神經(jīng)網(wǎng)絡(luò)的聯(lián)合表示的主要優(yōu)勢(shì)在于其通常具有優(yōu)越的性能,并且能夠在無(wú)監(jiān)督的情況下對(duì)表示進(jìn)行預(yù)訓(xùn)練。然而,性能的提高取決于可用于訓(xùn)練的數(shù)據(jù)量。缺點(diǎn)之一是模型不能自然地處理丟失的數(shù)據(jù)——盡管有一些方法可以緩解這個(gè)問(wèn)題[151],[217]。最后,深度網(wǎng)絡(luò)往往很難訓(xùn)練[69],但該領(lǐng)域在更好的訓(xùn)練技術(shù)方面正在取得進(jìn)展[196]。
概率圖形模型是另一種通過(guò)使用潛在隨機(jī)變量來(lái)構(gòu)造表示的常用方法[18]。在本節(jié)中,我們將描述如何使用概率圖模型來(lái)表示單模和多模數(shù)據(jù)。基于圖形模型的表示最流行的方法是受限玻爾茲曼機(jī):deep Boltzmann machines (DBM)[176],將restricted Boltzmann machines (RBM)[81]堆疊起來(lái)作為構(gòu)建塊。與神經(jīng)網(wǎng)絡(luò)類似,DBM的每個(gè)連續(xù)層都期望在更高的抽象級(jí)別上表示數(shù)據(jù)。DBMs的吸引力來(lái)自于他們不需要監(jiān)督數(shù)據(jù)進(jìn)行訓(xùn)練的事實(shí)[176]。由于它們是圖形模型,因此數(shù)據(jù)的表示是概率的,但是可以將它們轉(zhuǎn)換為確定性神經(jīng)網(wǎng)絡(luò)——但這就失去了模型的生成方面[176]。
Srivastava和Salakhutdinov[197]的工作引入了多模態(tài)深度信念網(wǎng)絡(luò)作為多模態(tài)表征。Kim等[104]對(duì)每一種模態(tài)都使用了一個(gè)深度信念網(wǎng)絡(luò),然后將其組合成聯(lián)合表征進(jìn)行視聽(tīng)情感識(shí)別。Huang and KingsburyAVSR[86]采用了類似的模型,Wu等[225]基于音頻和骨骼關(guān)節(jié)的手勢(shì)識(shí)別。
Srivastava和Salakhutdinov[198]將多模態(tài)深度信念網(wǎng)絡(luò)擴(kuò)展到了多模態(tài)DBMs中。多模態(tài)DBMs能夠從多種模態(tài)中學(xué)習(xí)聯(lián)合表示,方法是使用隱藏單元的二進(jìn)制層合并兩個(gè)或多個(gè)無(wú)向圖。由于模型的無(wú)向性,它們?cè)试S每個(gè)模態(tài)的低級(jí)表示在聯(lián)合訓(xùn)練后相互影響。Ouyang等[156]探討了多模態(tài)DBMs在多視圖數(shù)據(jù)人體姿態(tài)估計(jì)中的應(yīng)用。他們證明,在單模態(tài)數(shù)據(jù)經(jīng)過(guò)非線性轉(zhuǎn)換后的后期對(duì)數(shù)據(jù)進(jìn)行集成對(duì)模型是有益的。同樣,Suk等[199]利用多模態(tài)DBM表示法從正電子發(fā)射斷層掃描和磁共振成像數(shù)據(jù)中對(duì)阿爾茨海默病進(jìn)行分類。使用多模態(tài)DBMs學(xué)習(xí)多模態(tài)表示的最大優(yōu)點(diǎn)之一是其生成特性,這允許以一種簡(jiǎn)單的方式處理丟失的數(shù)據(jù)——即使整個(gè)模態(tài)丟失,模型也有一種自然的處理方法。它還可以用于在另一種模態(tài)存在的情況下生成一種模態(tài)的樣本,或者從表示中生成兩種模態(tài)的樣本。與自動(dòng)編碼器類似,可以以非監(jiān)督的方式對(duì)表示進(jìn)行訓(xùn)練,從而支持使用未標(biāo)記的數(shù)據(jù)。DBMs的主要缺點(diǎn)是訓(xùn)練困難,計(jì)算成本高,需要使用近似變分訓(xùn)練方法[198]。
順序表示。到目前為止,我們已經(jīng)討論了可以表示固定長(zhǎng)度數(shù)據(jù)的模型,但是,我們通常需要表示不同長(zhǎng)度的序列,例如句子、視頻或音頻流。在本節(jié)中,我們將描述可用于表示此類序列的模型。遞歸神經(jīng)網(wǎng)絡(luò)(RNNs)及其變體,如長(zhǎng)-短時(shí)記憶(LSTMs)網(wǎng)絡(luò)[82],由于在不同任務(wù)的[12]序列建模方面的成功,近年來(lái)受到了廣泛的歡迎[213]。到目前為止,RNNs主要用于表示單模態(tài)的單詞、音頻或圖像序列,在語(yǔ)言領(lǐng)域取得了很大的成功。與傳統(tǒng)神經(jīng)網(wǎng)絡(luò)相似,RNN的隱藏狀態(tài)可以看作是數(shù)據(jù)的一種表示,也就是說(shuō),RNN在時(shí)間步t處的隱藏狀態(tài)可以看作是該時(shí)間步之前序列的總結(jié)。這在RNN編碼器框架中尤為明顯,編碼器的任務(wù)是以解碼器可以重構(gòu)的方式來(lái)表示處于RNN隱藏狀態(tài)的序列[12]。RNN表示的使用并不局限于單模態(tài)域。使用rns構(gòu)造多模態(tài)表示的早期使用來(lái)自Cosi等人在AVSR上的工作。它們還用于表示影響識(shí)別的視聽(tīng)數(shù)據(jù)[37]、[152]和表示多視圖數(shù)據(jù),例如用于人類行為分析的不同視覺(jué)線索[166]。
3.2協(xié)同表示
聯(lián)合多模表示的一種替代方法是協(xié)同表示。我們不是將模態(tài)一起投影到一個(gè)聯(lián)合空間中,而是為每個(gè)模態(tài)學(xué)習(xí)單獨(dú)的表示,但是通過(guò)一個(gè)約束來(lái)協(xié)調(diào)它們。我們從強(qiáng)調(diào)表示之間的相似性的協(xié)調(diào)表示開(kāi)始討論,接著討論在結(jié)果空間上加強(qiáng)結(jié)構(gòu)的協(xié)調(diào)表示(表2中可以看到不同協(xié)調(diào)表示的代表性作品)。相似模型最小化了協(xié)調(diào)空間中模態(tài)之間的距離。例如,這種模型鼓勵(lì)“狗”和“狗”兩個(gè)詞的表示,它們之間的距離小于“狗”和“汽車(chē)”兩個(gè)詞之間的距離[61]。最早的例子之一就是韋斯頓等人的研究。在WSABIE(通過(guò)圖像嵌入的網(wǎng)絡(luò)比例注釋)模型中,為圖像及其注釋構(gòu)建了一個(gè)協(xié)調(diào)的空間。WSABIE從圖像和文本特征構(gòu)造了一個(gè)簡(jiǎn)單的線性映射,這樣相應(yīng)的注釋和圖像表示在它們之間會(huì)比不相關(guān)的注釋和圖像表示有更高的內(nèi)積(更小的余弦距離)。
近年來(lái),神經(jīng)網(wǎng)絡(luò)由于具有學(xué)習(xí)表示的能力,已成為一種常用的構(gòu)造協(xié)調(diào)表示的方法。它們的優(yōu)勢(shì)在于能夠以端到端的方式共同學(xué)習(xí)協(xié)調(diào)的表示。這種協(xié)調(diào)表示的一個(gè)例子是設(shè)計(jì)——深度視覺(jué)語(yǔ)義嵌入[61]。設(shè)計(jì)使用了類似于WSABIE的內(nèi)積和排序損失函數(shù),但使用了更復(fù)雜的圖像和單詞嵌入。Kiros等[105]利用LSTM模型和兩兩排序損失來(lái)協(xié)調(diào)特征空間,將其擴(kuò)展到句子和圖像的協(xié)調(diào)表示。Socher等人[191]處理了相同的任務(wù),但將語(yǔ)言模型擴(kuò)展到依賴樹(shù)RNN以合并組合語(yǔ)義。Pan等人也提出了類似的模型。[159],但使用視頻而不是圖像。Xu等人[231]還使用主題、動(dòng)詞、賓語(yǔ)組合語(yǔ)言模型和深層視頻模型構(gòu)建了視頻和句子之間的協(xié)調(diào)空間。然后將該表示用于跨模式檢索和視頻描述任務(wù)。
雖然上面的模型強(qiáng)制表示之間的相似性,但結(jié)構(gòu)化的協(xié)調(diào)空間模型超越了這一點(diǎn),并且在模態(tài)表示之間強(qiáng)制執(zhí)行額外的約束。強(qiáng)制的結(jié)構(gòu)類型通常基于應(yīng)用程序,對(duì)于散列、跨模態(tài)檢索和圖像標(biāo)題有不同的約束。結(jié)構(gòu)化協(xié)調(diào)空間通常用于跨模式散列-將高維數(shù)據(jù)壓縮為緊湊的二進(jìn)制代碼,并對(duì)類似對(duì)象使用相似的二進(jìn)制代碼[218]。跨模式散列的思想是為跨模式檢索創(chuàng)建這樣的代碼[27]、[93]、[113]。哈希對(duì)產(chǎn)生的多模態(tài)空間施加一定的約束: 1)它必須是一個(gè)n維漢明空間-一個(gè)二進(jìn)制表示,位數(shù)可控;2)來(lái)自不同模態(tài)的同一對(duì)象必須具有相似的散列碼;3)空間必須保持相似性。學(xué)習(xí)如何將數(shù)據(jù)表示為哈希函數(shù),試圖實(shí)現(xiàn)這三個(gè)要求[27][113]。例如,Jiang和Li[92]提出了一種利用端到端可訓(xùn)練的深度學(xué)習(xí)技術(shù)來(lái)學(xué)習(xí)句子描述和相應(yīng)圖像之間這種常見(jiàn)的二進(jìn)制空間的方法。Cao等人對(duì)該方法進(jìn)行了擴(kuò)展,采用了更復(fù)雜的LSTM語(yǔ)句表示,引入了離群點(diǎn)不敏感的逐位邊緣損失和基于相關(guān)性反饋的語(yǔ)義相似約束。同樣,Wang等人[219]構(gòu)建了一個(gè)協(xié)調(diào)的空間,其中具有相似含義的圖像(和句子)彼此更接近。
結(jié)構(gòu)化協(xié)調(diào)表示的另一個(gè)例子來(lái)自圖像和語(yǔ)言的順序嵌入[212],[249]。Vendrov等[212]提出的模型強(qiáng)制執(zhí)行了一個(gè)不對(duì)稱的不相似度量,實(shí)現(xiàn)了多模態(tài)空間中的偏序概念。其思想是捕獲語(yǔ)言和圖像表示的部分順序——在空間上強(qiáng)制執(zhí)行層次結(jié)構(gòu);例如“遛狗的女人”的形象→文本“遛狗的女人”→文本“女人走路”。Young等人[238]也提出了一個(gè)使用符號(hào)圖的類似模型,其中符號(hào)圖用于誘導(dǎo)部分排序。最后,Zhang等人提出了如何利用文本和圖像的結(jié)構(gòu)化表示以一種無(wú)監(jiān)督的方式創(chuàng)建概念分類[249]。
結(jié)構(gòu)協(xié)調(diào)空間的一個(gè)特殊情況是基于正則相關(guān)分析(CCA)的情況[84]。CCA計(jì)算一個(gè)線性投影,該投影最大化了兩個(gè)隨機(jī)變量(在我們的例子中是模態(tài))之間的相關(guān)性,并強(qiáng)制新空間的正交性。CCA模型被廣泛用于跨模態(tài)檢索[76],[106],[169]和視聽(tīng)信號(hào)分析[177],[187]。對(duì)CCA的擴(kuò)展試圖構(gòu)造一個(gè)最大相關(guān)非線性投影[7][116]。核正則相關(guān)分析(Kernel canonical correlation analysis, KCCA)[116]使用復(fù)制核希爾伯特空間進(jìn)行投影。但是,由于該方法是非參數(shù)的,因此它與訓(xùn)練集的大小之間的伸縮性很差,并且與非常大的實(shí)際數(shù)據(jù)集之間存在問(wèn)題。引入了深正則相關(guān)分析(DCCA)[7]作為KCCA的替代方法,解決了可擴(kuò)展性問(wèn)題,并給出了更好的相關(guān)表示空間。類似的通信自動(dòng)編碼器[58]和深度通信RBMS[57]也被提議用于跨模式檢索。
CCA、KCCA和DCCA是無(wú)監(jiān)督的技術(shù),只優(yōu)化表示上的相關(guān)性,因此主要捕獲跨模式共享的內(nèi)容。深層規(guī)范相關(guān)的自動(dòng)編碼器[220]還包括一個(gè)基于自動(dòng)編碼器的數(shù)據(jù)重建術(shù)語(yǔ)。這促使表示也能捕獲模態(tài)特定的信息。語(yǔ)義相關(guān)最大化方法[248]也鼓勵(lì)語(yǔ)義相關(guān)性,同時(shí)保留相關(guān)最大化和由此產(chǎn)生的空間的正交性-這導(dǎo)致了CCA和跨模式散列技術(shù)的結(jié)合。
3.3討論
在本節(jié)中,我們確定了兩種主要的多模態(tài)表示形式——聯(lián)合和協(xié)調(diào)。聯(lián)合表示將多模態(tài)數(shù)據(jù)投射到一個(gè)公共空間中,最適合在推理過(guò)程中出現(xiàn)所有模態(tài)的情況。它們被廣泛用于AVSR、情感和多模手勢(shì)識(shí)別。另一方面,協(xié)調(diào)表示法將每個(gè)模態(tài)投影到一個(gè)單獨(dú)但協(xié)調(diào)的空間中,使其適用于測(cè)試時(shí)只有一個(gè)模態(tài)的應(yīng)用,例如:多模態(tài)檢索和翻譯(第4節(jié))、接地(第7.2節(jié))和零鏡頭學(xué)習(xí)(第7.2節(jié))。最后,雖然聯(lián)合表示用于構(gòu)建兩種以上模態(tài)的表示,但到目前為止,協(xié)調(diào)空間主要限于兩種模態(tài)。
表3:多模態(tài)翻譯研究的分類。對(duì)于每個(gè)類和子類,我們都包含了帶有引用的示例任務(wù)。我們的分類還包括翻譯的方向性:單向(?)和雙向(?)。
4 翻譯(以下部分翻譯的較好)
多模機(jī)器學(xué)習(xí)的很大一部分涉及從一種形式到另一種形式的翻譯(映射)。給定一個(gè)模態(tài)中的實(shí)體,任務(wù)是用不同的模態(tài)生成相同的實(shí)體。例如,給定一個(gè)圖像,我們可能希望生成一個(gè)描述它的句子,或者給定一個(gè)文本描述,生成一個(gè)匹配它的圖像。多模態(tài)翻譯是一個(gè)長(zhǎng)期研究的問(wèn)題,在語(yǔ)音合成[88]、視覺(jué)語(yǔ)音生成[136]、視頻描述[107]、跨模態(tài)檢索[169]等領(lǐng)域都有早期的工作。
近年來(lái),由于計(jì)算機(jī)視覺(jué)和自然語(yǔ)言處理(NLP)社區(qū)[19]的共同努力,以及大型多模態(tài)數(shù)據(jù)集[38]最近的可用性,多模態(tài)翻譯重新引起了人們的興趣[205]。一個(gè)特別受歡迎的問(wèn)題是視覺(jué)場(chǎng)景描述,也稱為圖像[214]和視頻字幕[213],它是許多計(jì)算機(jī)視覺(jué)和NLP問(wèn)題的一個(gè)很好的測(cè)試平臺(tái)。要解決這一問(wèn)題,我們不僅要充分理解視覺(jué)場(chǎng)景,識(shí)別其突出的部分,而且要在語(yǔ)法上正確、全面而簡(jiǎn)潔的描述它的句子。雖然多模態(tài)翻譯的方法非常廣泛,而且通常是模態(tài)特有的,但它們有許多共同的因素。我們將它們分為兩類——基于實(shí)例的和生成的。基于實(shí)例的模型在模式之間轉(zhuǎn)換時(shí)使用字典。
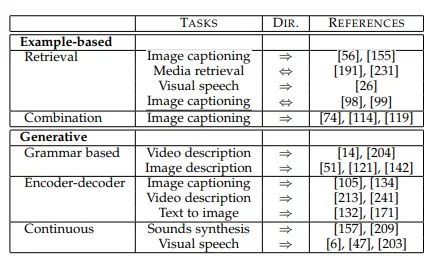
另一方面,生成模型構(gòu)建了一個(gè)能夠產(chǎn)生翻譯的模型。這種區(qū)別類似于非參數(shù)和參數(shù)機(jī)器學(xué)習(xí)方法之間的區(qū)別,如圖2所示,表3總結(jié)了代表性示例。
生成模型可能更具挑戰(zhàn)性,因?yàn)樗鼈冃枰尚盘?hào)或符號(hào)序列(例如句子)的能力。這對(duì)于任何形式來(lái)說(shuō)都是困難的——視覺(jué)的、聽(tīng)覺(jué)的或口頭的,尤其是當(dāng)需要生成時(shí)間上和結(jié)構(gòu)上一致的序列時(shí)。這導(dǎo)致了許多早期的多模態(tài)翻譯系統(tǒng)依賴于基于實(shí)例的翻譯。但是,隨著能夠生成圖像[171]、[210]、聲音[157]、[209]和文本[12]的深度學(xué)習(xí)模型的出現(xiàn),這種情況一直在發(fā)生變化。
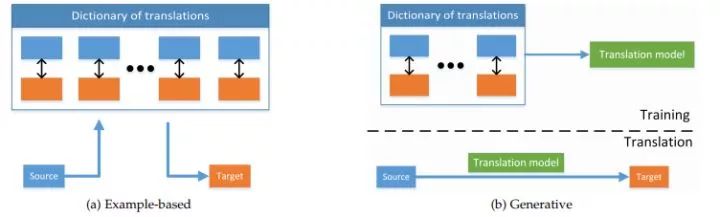
圖2:基于實(shí)例和生成式多模態(tài)翻譯概述。前者從字典中檢索最佳翻譯,而后者首先在字典上訓(xùn)練翻譯模型,然后使用該模型進(jìn)行翻譯。
4.1基于實(shí)例
基于實(shí)例的算法受到訓(xùn)練數(shù)據(jù)字典的限制(見(jiàn)圖2a)。我們確定了這類算法的兩種類型:基于檢索的算法和基于組合的算法。基于檢索的模型直接使用檢索到的轉(zhuǎn)換,而不需要修改它,而基于組合的模型依賴于更復(fù)雜的規(guī)則來(lái)基于大量檢索到的實(shí)例創(chuàng)建轉(zhuǎn)換。
基于檢索的模型可以說(shuō)是多模態(tài)翻譯的最簡(jiǎn)單形式。它們依賴于在字典中找到最接近的樣本,并將其用作翻譯結(jié)果。檢索可以在單模態(tài)空間或中間語(yǔ)義空間進(jìn)行。
給定要翻譯的源模態(tài)實(shí)例,單模態(tài)檢索在字典中查找源空間中最接近的實(shí)例——例如圖像的視覺(jué)特征空間。這種方法已被用于視覺(jué)語(yǔ)音合成,檢索最匹配的音素[26]的視覺(jué)示例。它們也被用于連接文本到語(yǔ)音系統(tǒng)[88]。最近,Ordonez等[155]利用單模態(tài)檢索,利用全局圖像特征檢索標(biāo)題候選,生成圖像描述[155]。Yagcioglu等[232]利用一種基于cnn的圖像表示方法,利用自適應(yīng)鄰域選擇檢索視覺(jué)上相似的圖像。Devlin等人在[49]中證明了一個(gè)簡(jiǎn)單的k近鄰檢索方法與更復(fù)雜的生成方法相比,具有一致標(biāo)題選擇的k近鄰檢索方法能夠獲得具有競(jìng)爭(zhēng)力的翻譯結(jié)果。這種單模態(tài)檢索方法的優(yōu)點(diǎn)是,它們只需要表示我們所使用的單一模態(tài)進(jìn)行檢索。然而,它們通常需要額外的處理步驟,如重新排列檢索到的譯文[135]、[155]、[232]。這表明這種方法的一個(gè)主要問(wèn)題——單模態(tài)空間的相似性并不總是意味著好的翻譯。另一種方法是在檢索過(guò)程中使用中間語(yǔ)義空間進(jìn)行相似性比較。手工語(yǔ)義空間的一個(gè)早期示例是Farhadi等人使用的。它們將句子和圖像映射到一個(gè)空間,這個(gè)空間包含了對(duì)象、動(dòng)作、場(chǎng)景和相關(guān)檢索,然后在該空間中執(zhí)行圖像的標(biāo)題。Socher等[191]學(xué)習(xí)了句子的協(xié)調(diào)表示和CNN視覺(jué)特征(關(guān)于協(xié)調(diào)空間的描述,請(qǐng)參見(jiàn)3.2節(jié)),這與手工制作表示不同。他們使用該模型既可以將文本轉(zhuǎn)換為圖像,也可以將圖像轉(zhuǎn)換為文本。類似地,Xu等[231]使用視頻及其描述的協(xié)調(diào)空間進(jìn)行跨模態(tài)檢索。Jiang和Li[93]以及Cao等人[[32]]使用跨模態(tài)哈希(cross-modal hashing)來(lái)實(shí)現(xiàn)圖像到句子和句子之間的多模態(tài)轉(zhuǎn)換,Hodosh等人[83]使用多模態(tài)KCCA空間進(jìn)行圖像entence檢索。Karpathy等人[99]提出了一種多模態(tài)相似度度量方法,可以在內(nèi)部將圖像片段(視覺(jué)對(duì)象)與句子片段對(duì)齊,而不是在公共空間中對(duì)圖像和句子進(jìn)行全局對(duì)齊(依賴關(guān)系樹(shù))。語(yǔ)義空間中的檢索方法往往比單模態(tài)的檢索方法表現(xiàn)得更好,因?yàn)樗鼈兪窃谝粋€(gè)更有意義的空間中檢索示例,該空間反映了兩種模式,而且通常是為檢索而優(yōu)化的。此外,它們?cè)试S雙向翻譯,這在單模態(tài)方法中不是很直觀。然而,它們需要手工構(gòu)建或?qū)W習(xí)這樣的語(yǔ)義空間,這通常依賴于大型訓(xùn)練字典(成對(duì)樣本的數(shù)據(jù)集)的存在。
基于組合的模型進(jìn)一步采用了基于檢索的方法。它們不只是從字典中檢索示例,而是以一種有意義的方式將它們組合起來(lái),以構(gòu)建更好的翻譯。基于組合的媒體描述方法的出發(fā)點(diǎn)是圖像的句子描述具有共性和簡(jiǎn)單性可以利用的結(jié)構(gòu)。組合規(guī)則通常是手工制定的或基于啟發(fā)式的。Kuznetsova等[114]首先檢索描述視覺(jué)上相似的圖像的短語(yǔ),然后將它們組合起來(lái),使用整數(shù)線性規(guī)劃和一些手工規(guī)則生成查詢圖像的新描述。Gupta等[74]首先找到k個(gè)與源圖像最相似的圖像,然后使用從其標(biāo)題中提取的短語(yǔ)生成一個(gè)目標(biāo)句子。Lebret等[119]使用基于cnn的圖像表示來(lái)推斷描述它的短語(yǔ)。然后使用三元模型將預(yù)測(cè)的短語(yǔ)組合起來(lái)。基于示例的翻譯方法面臨的一個(gè)大問(wèn)題是,模型是整個(gè)詞典——使得模型變大,推理變慢(不過(guò),諸如散列之類的優(yōu)化可以緩解這個(gè)問(wèn)題)。基于實(shí)例的翻譯面臨的另一個(gè)問(wèn)題是,除非任務(wù)簡(jiǎn)單或字典很大,否則期望與源示例相關(guān)的完整和準(zhǔn)確的翻譯總是存在于字典中是不現(xiàn)實(shí)的。這部分由能夠構(gòu)建更復(fù)雜結(jié)構(gòu)的組合模型來(lái)解決。然而,它們只能在一個(gè)方向上執(zhí)行翻譯,而基于語(yǔ)義空間檢索的模型可以同時(shí)執(zhí)行這兩種方式。
4.2生成方法
在給定單模源實(shí)例的情況下,多模翻譯的生成方法構(gòu)造了能夠執(zhí)行多模翻譯的模型。這是一個(gè)具有挑戰(zhàn)性的問(wèn)題,因?yàn)樗枰瑫r(shí)理解源模態(tài)和生成目標(biāo)序列或信號(hào)的能力。正如下面一節(jié)所討論的,由于可能的正確答案空間很大,這也使得這些方法更難評(píng)估。
在這項(xiàng)調(diào)查中,我們關(guān)注三種形式的產(chǎn)生:語(yǔ)言、視覺(jué)和聲音。語(yǔ)言生成已經(jīng)探索了很長(zhǎng)一段時(shí)間[170],最近很多人關(guān)注圖像和視頻描述等任務(wù)[19]。語(yǔ)音和聲音的產(chǎn)生也經(jīng)歷了許多歷史[88]和現(xiàn)代方法[157],[209]。照片般逼真的圖像生成一直沒(méi)有被探索過(guò),并且仍然處于早期階段[132],[171],但是,在生成抽象場(chǎng)景[253]、計(jì)算機(jī)圖形[45]和說(shuō)話的頭部[6]方面,已經(jīng)進(jìn)行了多次嘗試。
我們確定了三大類生成模型:基于語(yǔ)法的、編碼器-解碼器和連續(xù)生成模型。基于語(yǔ)法的模型通過(guò)使用語(yǔ)法限制目標(biāo)域來(lái)簡(jiǎn)化任務(wù),例如,通過(guò)基于
基于語(yǔ)法的模型依賴于預(yù)定義的語(yǔ)法來(lái)生成特定的模態(tài)。它們首先從源模式檢測(cè)高級(jí)概念,例如圖像中的對(duì)象和視頻中的動(dòng)作。然后將這些檢測(cè)與基于預(yù)定義語(yǔ)法的生成過(guò)程結(jié)合在一起,生成目標(biāo)模態(tài)。Kojima等[107]提出了一種利用檢測(cè)到的人的頭和手的位置以及基于規(guī)則的自然語(yǔ)言生成來(lái)描述視頻中人類行為的系統(tǒng),該系統(tǒng)融合了概念和行為的層次結(jié)構(gòu)。Barbu et al.[14]提出了一種視頻描述模型,該模型可以生成這種形式的句子:who did what to whom and where and how they did it。該系統(tǒng)基于手工制作的對(duì)象和事件分類器,并使用了適合任務(wù)的受限語(yǔ)法。Guadarrama等人[73]預(yù)測(cè)
為了描述圖像,Yao等[235]提出使用基于and或圖形的模型,結(jié)合領(lǐng)域特定的詞匯化語(yǔ)法規(guī)則、有針對(duì)性的視覺(jué)表示方案和層次知識(shí)本體。Li等[121]首先檢測(cè)對(duì)象、視覺(jué)屬性和對(duì)象之間的空間關(guān)系。然后在視覺(jué)提取的短語(yǔ)上使用n-gram語(yǔ)言模型生成
大多數(shù)方法都將整個(gè)圖像聯(lián)合起來(lái)表示為一袋視覺(jué)對(duì)象,而不捕獲它們的空間和語(yǔ)義關(guān)系。為了解決這個(gè)問(wèn)題,Elliott等人[51]建議顯式建模對(duì)象的鄰近關(guān)系,以生成圖像描述。
一些基于語(yǔ)法的方法依賴于圖形模型來(lái)生成目標(biāo)模態(tài)。一個(gè)例子是BabyTalk[112],它給出了一個(gè)圖像生成
基于語(yǔ)法的方法的一個(gè)優(yōu)點(diǎn)是,當(dāng)它們使用預(yù)定義模板和受限制的語(yǔ)法時(shí),它們更有可能生成語(yǔ)法上(對(duì)于語(yǔ)言)或邏輯上正確的目標(biāo)實(shí)例。然而,這限制了他們產(chǎn)生公式化,而不是創(chuàng)造性翻譯。此外,基于語(yǔ)法的方法依賴于復(fù)雜的管道進(jìn)行概念檢測(cè),每個(gè)概念都需要單獨(dú)的模型和單獨(dú)的訓(xùn)練數(shù)據(jù)集。
基于端到端訓(xùn)練神經(jīng)網(wǎng)絡(luò)的編碼器-解碼器模型是目前最流行的多模態(tài)翻譯技術(shù)之一。該模型的主要思想是首先將源模態(tài)編碼為矢量表示,然后使用解碼器模塊生成目標(biāo)模態(tài),所有這些都在一個(gè)單通道管道中。雖然該模型首次用于機(jī)器翻譯[97],但已成功用于圖像字幕[134]、[214]和視頻描述[174]、[213]。迄今為止,編碼器模型主要用于生成文本,但也可用于生成圖像[132]、[171]和語(yǔ)音連續(xù)生成[157]、[209]。
編碼器-解碼器模型的第一步是對(duì)源對(duì)象進(jìn)行編碼,這是以特定的方式完成的。常用的聲學(xué)信號(hào)編碼模型包括RNNs[35]和DBNs[79]。對(duì)單詞和句子進(jìn)行編碼的大部分工作使用分布語(yǔ)義[141]和RNNs[12]的變體。圖像通常使用卷積神經(jīng)網(wǎng)絡(luò)(CNN)進(jìn)行編碼[109],[185]。雖然學(xué)習(xí)CNN表示是常見(jiàn)的圖像編碼,但這不是視頻的情況,手工制作的功能仍然普遍使用[174],[204]。雖然可以使用單模態(tài)表示對(duì)源模態(tài)進(jìn)行編碼,但已經(jīng)證明使用協(xié)調(diào)空間(參見(jiàn)3.2節(jié))可以獲得更好的結(jié)果[105]、[159]和[231]。
解碼通常由RNN或LSTM執(zhí)行,使用編碼的表示作為初始隱藏狀態(tài)[54],[132],[214],[215]。對(duì)傳統(tǒng)的LSTM模型提出了一些擴(kuò)展,以幫助完成翻譯任務(wù)。可以使用導(dǎo)向量將圖像輸入中的解緊密耦合[91]。Venugopalan等[213]證明,在將解碼器LSTM微調(diào)為視頻描述之前,對(duì)其進(jìn)行圖像字幕預(yù)處理是有益的。Rohrbach等[174]探討了用于視頻描述任務(wù)的各種LSTM架構(gòu)(單層、多層、分解)和一些訓(xùn)練和正則化技術(shù)的使用。
使用RNN進(jìn)行翻譯生成所面臨的一個(gè)問(wèn)題是,模型必須從圖像、句子或視頻的單個(gè)矢量表示生成描述。在生成長(zhǎng)序列時(shí),這一點(diǎn)尤其困難,因?yàn)檫@些模型往往會(huì)忘記初始輸入。神經(jīng)注意模型(見(jiàn)5.2節(jié))部分解決了這一問(wèn)題,它允許網(wǎng)絡(luò)在生成過(guò)程中聚焦于圖像[230]、句子[12]或視頻[236]的某些部分。
基于生成注意的神經(jīng)網(wǎng)絡(luò)也被用于從句子中生成圖像的任務(wù)[132],盡管其結(jié)果仍遠(yuǎn)未達(dá)到照片真實(shí)感,但顯示出了很大的前景。近年來(lái),利用生成對(duì)抗性網(wǎng)絡(luò)生成圖像的研究取得了很大進(jìn)展[71],該網(wǎng)絡(luò)已被用于替代RNNs從文本生成圖像[171]。
雖然基于神經(jīng)網(wǎng)絡(luò)的編碼器-解碼器系統(tǒng)已經(jīng)取得了很大的成功,但仍然面臨許多問(wèn)題。Devlin等人[49]認(rèn)為,網(wǎng)絡(luò)可能是在記憶訓(xùn)練數(shù)據(jù),而不是學(xué)習(xí)如何理解和生成視覺(jué)場(chǎng)景。
這是基于K-最近鄰模型與基于生成的模型的性能非常相似的觀察結(jié)果。此外,此類模型通常需要大量數(shù)據(jù)進(jìn)行培訓(xùn)。連續(xù)生成模型用于序列轉(zhuǎn)換,并以在線方式在每個(gè)時(shí)間步上生成輸出。這些模型在將序列轉(zhuǎn)換為序列(如文本到語(yǔ)音、語(yǔ)音到文本和視頻到文本)時(shí)非常有用。已經(jīng)為此類建模提出了許多不同的技術(shù)——圖形模型、連續(xù)編碼器-解碼器方法以及各種其他回歸或分類技術(shù)。這些模型需要解決的額外困難是模式之間的時(shí)間一致性要求。
許多早期的序列到序列翻譯工作使用圖形或潛在變量模型。Deena和Galata[47]提出使用共享高斯過(guò)程潛在變量模型進(jìn)行基于音頻的視覺(jué)語(yǔ)音合成。該模型在音頻和視頻特征之間創(chuàng)建了一個(gè)共享的潛在空間,可用于從另一個(gè)特征生成一個(gè)空間,同時(shí)在不同的時(shí)間點(diǎn)增強(qiáng)視覺(jué)語(yǔ)音的時(shí)間一致性。
隱馬爾可夫模型(HMM)也被用于視覺(jué)語(yǔ)音生成[203]和文本語(yǔ)音轉(zhuǎn)換[245]任務(wù)。它們還被擴(kuò)展到使用集群自適應(yīng)訓(xùn)練,以允許對(duì)多個(gè)揚(yáng)聲器、語(yǔ)言和情感進(jìn)行訓(xùn)練,從而在生成語(yǔ)音信號(hào)[244]或視覺(jué)語(yǔ)音參數(shù)[6]時(shí)實(shí)現(xiàn)更大的控制。
編碼器-解碼器模型最近已成為序列到序列建模的流行模式。歐文斯等人。[157]使用LSTM根據(jù)視頻生成雞腿的聲音。雖然他們的模型能夠通過(guò)預(yù)測(cè)CNN視頻特征中的耳蝸圖來(lái)產(chǎn)生聲音,但他們發(fā)現(xiàn),根據(jù)預(yù)測(cè)的耳蝸圖檢索最近的音頻樣本可以獲得最佳結(jié)果。van den Oord等人提出了直接模擬語(yǔ)音和音樂(lè)生成的原始音頻信號(hào)。〔209〕。作者建議使用層次結(jié)構(gòu)的全卷積神經(jīng)網(wǎng)絡(luò),這表明在語(yǔ)音合成任務(wù)上,它比以前的先進(jìn)技術(shù)有了很大的改進(jìn)。RNN也被用于語(yǔ)音到文本翻譯(語(yǔ)音識(shí)別)[72]。最近,基于編碼器-解碼器的連續(xù)方法被證明能夠很好地預(yù)測(cè)語(yǔ)音信號(hào)中的字母,該語(yǔ)音信號(hào)表示為濾波器組光譜[35]——允許更準(zhǔn)確地識(shí)別稀有和詞匯外的單詞。Collobert等人[42]演示如何直接使用原始音頻信號(hào)進(jìn)行語(yǔ)音識(shí)別,無(wú)需音頻功能。許多早期的工作使用圖形模型來(lái)進(jìn)行連續(xù)信號(hào)之間的多模態(tài)轉(zhuǎn)換。然而,這些方法正被基于神經(jīng)網(wǎng)絡(luò)的編碼器-解碼器技術(shù)所取代。特別是它們最近被證明能夠表示和產(chǎn)生復(fù)雜的視覺(jué)和聲學(xué)信號(hào)。
4.3模型評(píng)價(jià)與討論
多模態(tài)翻譯方法面臨的一個(gè)主要挑戰(zhàn)是很難對(duì)其進(jìn)行評(píng)價(jià)。雖然語(yǔ)音識(shí)別等任務(wù)只有一個(gè)正確的翻譯,但語(yǔ)音合成和媒體描述等任務(wù)沒(méi)有。有時(shí),就像在語(yǔ)言翻譯中一樣,多個(gè)答案都是正確的,決定哪個(gè)翻譯更好往往是主觀的。幸運(yùn)的是,在模型評(píng)估中有許多近似的自動(dòng)度量。
通常,評(píng)價(jià)主觀任務(wù)的理想方法是通過(guò)人的判斷。那就是讓一組人評(píng)估每一個(gè)翻譯。這可以在Likert量表上進(jìn)行,在該量表中,每個(gè)翻譯都在一定的維度上進(jìn)行評(píng)估:語(yǔ)音合成的自然度和平均意見(jiàn)分?jǐn)?shù)[209]、[244]、視覺(jué)語(yǔ)音合成的現(xiàn)實(shí)性[6]、[203]以及媒體描述的語(yǔ)法和語(yǔ)義正確性、相關(guān)性、順序和細(xì)節(jié)[38]、[112]、[142]、[213]。另一種選擇是進(jìn)行偏好研究,即向參與者提供兩個(gè)(或多個(gè))翻譯以進(jìn)行偏好比較[203],[244]。然而,雖然用戶研究的結(jié)果將得出最接近人類判斷的評(píng)價(jià),但它們是費(fèi)時(shí)和昂貴的。此外,在構(gòu)建和引導(dǎo)它們時(shí)需要小心,以避免流暢性、年齡、性別和文化偏見(jiàn)。
雖然人類研究是評(píng)估的黃金標(biāo)準(zhǔn),但已經(jīng)為媒體描述的任務(wù)提出了許多自動(dòng)替代方案:BLUE [160]、ROUGE [124]、Meteor [48]和CIDEr[ 211]。這些指標(biāo)直接取自(或基于)機(jī)器翻譯中的工作,并計(jì)算出度量?jī)烧咧g相似性的得分生成的和基本的真實(shí)文本。
然而,它們的使用卻面臨著許多批評(píng)。Elliott和Keller[52]表明,句子水平的單格BLeu與人類判斷的相關(guān)性很弱。Huang等人[87]證明人類判斷與布魯和流星之間的相關(guān)性對(duì)于視覺(jué)故事講述任務(wù)來(lái)說(shuō)非常低。此外,基于人類判斷的方法排序與在MS Coco挑戰(zhàn)[38]中使用自動(dòng)度量的排序不匹配,因?yàn)樵谒卸攘可希写罅克惴▋?yōu)于人類。最后,只有在大量參考翻譯很高的情況下,這些指標(biāo)才能很好地工作[211],這通常是不可用的,尤其是對(duì)于當(dāng)前的視頻描述數(shù)據(jù)集[205]。
這些批評(píng)導(dǎo)致Hodosh等人[83]提出使用檢索作為圖像字幕評(píng)價(jià)的代理,他們認(rèn)為這更好地反映了人類的判斷。基于檢索的系統(tǒng)不是生成標(biāo)題,而是根據(jù)標(biāo)題與圖像的匹配程度對(duì)可用標(biāo)題進(jìn)行排序,然后通過(guò)評(píng)估正確的標(biāo)題是否具有較高的排名來(lái)進(jìn)行評(píng)估。由于許多標(biāo)題生成模型具有生成性,因此它們可以直接用于評(píng)估給定圖像的標(biāo)題的可能性,而且圖像標(biāo)題社區(qū)正在對(duì)這些模型進(jìn)行調(diào)整[99],[105]。視頻字幕社區(qū)也采用了這種基于檢索的評(píng)價(jià)指標(biāo)[175]。
視覺(jué)問(wèn)答(Visual question-answer, VQA)[130]任務(wù)的提出部分是由于圖像字幕評(píng)價(jià)面臨的問(wèn)題。VQA是一項(xiàng)任務(wù),其中給定一個(gè)映像和一個(gè)關(guān)于其內(nèi)容的問(wèn)題,系統(tǒng)必須回答它。由于有了正確的答案,評(píng)估這樣的系統(tǒng)就更容易了。然而,它仍然面臨著某些問(wèn)題和答案的模糊性和問(wèn)題傾向性等問(wèn)題。
我們認(rèn)為,解決評(píng)價(jià)問(wèn)題對(duì)多式翻譯系統(tǒng)的進(jìn)一步成功至關(guān)重要。這樣不僅可以更好地比較各種方法,而且可以優(yōu)化更好的目標(biāo)。
5 對(duì)齊
我們將多模態(tài)對(duì)齊定義為從兩個(gè)或多個(gè)模態(tài)中查找實(shí)例子組件之間的關(guān)系和對(duì)應(yīng)。例如,給定一幅圖像和一個(gè)標(biāo)題,我們希望找到與標(biāo)題的單詞或短語(yǔ)對(duì)應(yīng)的圖像區(qū)域[98]。另一個(gè)例子是,給定一部電影,將其與劇本或書(shū)中它所基于的章節(jié)進(jìn)行比對(duì)[252]。
我們將多模態(tài)對(duì)齊分為隱式對(duì)齊和顯式對(duì)齊兩種類型。在顯式對(duì)齊中,我們顯式地對(duì)在模式之間對(duì)齊子組件感興趣,例如,使用相應(yīng)的教學(xué)視頻對(duì)齊菜譜步驟[131]。隱式對(duì)齊用作另一個(gè)任務(wù)的中間(通常是隱藏)步驟,例如,基于文本描述的圖像檢索可以包括單詞和圖像區(qū)域之間的對(duì)齊步驟[99]。這些方法的概述見(jiàn)表4,并在以下章節(jié)中進(jìn)行了更詳細(xì)的介紹。
5.1顯式對(duì)齊
如果論文的主要建模目標(biāo)是來(lái)自兩個(gè)或多個(gè)模式的實(shí)例子組件之間的對(duì)齊,那么我們將其歸類為執(zhí)行顯式對(duì)齊。顯式對(duì)齊的一個(gè)非常重要的部分是相似性度量。大多數(shù)方法依賴于以不同模式度量子組件之間的相似性作為基本構(gòu)建塊。這些相似性可以手動(dòng)定義,也可以從數(shù)據(jù)中學(xué)習(xí)。
我們確定了兩種處理顯式對(duì)齊的算法——無(wú)監(jiān)督算法和(弱)監(jiān)督算法。第一種類型不使用直接對(duì)齊標(biāo)簽(即來(lái)自不同模式的實(shí)例之間的通信。第二種類型可以訪問(wèn)這些(有時(shí)是弱)標(biāo)簽。
無(wú)監(jiān)督的多模式校準(zhǔn)解決了模式校準(zhǔn)而無(wú)需任何直接校準(zhǔn)標(biāo)簽。大多數(shù)方法都是從早期的統(tǒng)計(jì)機(jī)器翻譯校準(zhǔn)工作[28]和基因組序列[3],[111]中得到啟發(fā)的。為了使任務(wù)更簡(jiǎn)單,這些方法假定了對(duì)對(duì)齊的某些約束,例如序列的時(shí)間順序或模式之間存在相似性度量。
Dynamic time warping (DTW) [3],[111]是一種被廣泛用于多視圖時(shí)間序列對(duì)齊的動(dòng)態(tài)規(guī)劃方法。DTW測(cè)量?jī)蓚€(gè)序列之間的相似性,并通過(guò)時(shí)間扭曲(插入幀)找到它們之間的最優(yōu)匹配。它要求兩個(gè)序列中的時(shí)間步驟具有可比性,并要求它們之間的相似性度量。DTW可以通過(guò)手工繪制模態(tài)之間的相似性度量直接用于多模態(tài)校準(zhǔn);例如Anguera等人[8]在字形和音素之間使用手工定義的相似性;以及Tapaswi等人[201]根據(jù)相同字符的外觀定義視覺(jué)場(chǎng)景和句子之間的相似性[201]以對(duì)齊電視節(jié)目和情節(jié)概要。類似DTW的動(dòng)態(tài)編程方法也被用于文本到語(yǔ)音[77]和視頻[202]的多模式對(duì)齊。由于原始的DTW公式需要預(yù)先定義模態(tài)之間的相似性度量,因此使用正則相關(guān)分析(canonical correlation analysis, CCA)對(duì)其進(jìn)行擴(kuò)展,將模態(tài)映射到一個(gè)協(xié)調(diào)空間。這允許(通過(guò)DTW)對(duì)齊和(通過(guò)CCA)在不同的模態(tài)流之間以無(wú)監(jiān)督的方式聯(lián)合學(xué)習(xí)映射[180]、[250]、[251]。基于CCA的DTW模型能夠找到線性變換下的多模態(tài)數(shù)據(jù)對(duì)齊,但不能建立非線性關(guān)系的模型。深度規(guī)范時(shí)間翹曲方法[206]已經(jīng)解決了這一問(wèn)題,它可以看作是深度CCA和DTW的一種推廣。
各種圖形模型也已流行于無(wú)監(jiān)督的多模序列排列。Yu和Ballard的早期作品[239]使用生成圖形模型將圖像中的視覺(jué)對(duì)象與口語(yǔ)對(duì)齊。庫(kù)爾等人[44]也采用了類似的方法,將電影快照和場(chǎng)景與相應(yīng)的劇本對(duì)齊。Malmaud等。[131]使用系數(shù)化的hmm將食譜與烹飪視頻對(duì)齊,而noulas等人[154]使用動(dòng)態(tài)貝葉斯網(wǎng)絡(luò)將揚(yáng)聲器與視頻對(duì)齊。Naim等人。[147]使用分層HMM模型將句子與幀對(duì)齊,并使用改進(jìn)的IBM[28]算法對(duì)單詞和對(duì)象進(jìn)行對(duì)齊,從而將句子與相應(yīng)的視頻幀進(jìn)行匹配[15]。然后將該模型擴(kuò)展到使用潛條件隨機(jī)字段進(jìn)行對(duì)齊[146],并將動(dòng)詞對(duì)齊與名詞和對(duì)象之外的動(dòng)作結(jié)合起來(lái)[195]。
用于對(duì)齊的DTW和圖形模型方法都允許對(duì)對(duì)齊進(jìn)行限制,例如時(shí)間一致性、時(shí)間無(wú)大跳躍和單調(diào)性。雖然DTW擴(kuò)展允許共同學(xué)習(xí)相似性度量和對(duì)齊,但基于圖形模型的方法需要專家知識(shí)來(lái)構(gòu)造[44],[239]。
監(jiān)督對(duì)齊方法依賴于標(biāo)記對(duì)齊的實(shí)例。它們用于訓(xùn)練用于對(duì)齊模式的相似性度量。
許多有監(jiān)督序列對(duì)齊技術(shù)都是從無(wú)監(jiān)督序列對(duì)齊技術(shù)中獲得靈感的。Bojanowski等人[22],[23]提出了一種類似于canonical time warping的方法,但也將其擴(kuò)展到利用現(xiàn)有(弱)監(jiān)督對(duì)齊數(shù)據(jù)進(jìn)行模型訓(xùn)練。Plummer等[161]利用CCA在圖像區(qū)域和短語(yǔ)之間尋找一個(gè)協(xié)調(diào)的空間進(jìn)行對(duì)齊。Gebru等[65]對(duì)高斯混合模型進(jìn)行訓(xùn)練,將半監(jiān)督聚類與無(wú)監(jiān)督的隱變量圖形模型進(jìn)行聚類,將音頻信道中的揚(yáng)聲器與視頻中的位置進(jìn)行對(duì)齊。Kong等[108]訓(xùn)練了馬爾可夫隨機(jī)場(chǎng)將三維場(chǎng)景中的對(duì)象與文本描述中的名詞和代詞進(jìn)行對(duì)齊。
基于深度學(xué)習(xí)的方法越來(lái)越流行于顯式對(duì)齊(特別是用于度量相似性),這是因?yàn)樽罱谡Z(yǔ)言和視覺(jué)社區(qū)中出現(xiàn)了對(duì)齊的數(shù)據(jù)集[133]和[161]。Zhu等。[252]通過(guò)培訓(xùn)CNN來(lái)測(cè)量場(chǎng)景和文本之間的相似性,使書(shū)籍與相應(yīng)的電影/劇本保持一致。毛等人。[133]使用LSTM語(yǔ)言模型和CNN視覺(jué)模型來(lái)評(píng)估引用表達(dá)式和圖像中對(duì)象之間匹配的質(zhì)量。Yu等人[242]將該模型擴(kuò)展到包括相對(duì)外觀以及上下文信息,以便更好地消除同一類型對(duì)象之間的歧義。最后,Hu等人[85]使用基于LSTM的評(píng)分函數(shù)查找圖像區(qū)域及其描述之間的相似性。
5.2隱對(duì)齊
與顯式對(duì)齊相反,隱式對(duì)齊用作另一個(gè)任務(wù)的中間(通常是隱藏)步驟。這使得在許多任務(wù)中,包括語(yǔ)音識(shí)別、機(jī)器翻譯、媒體描述和視覺(jué)問(wèn)答,可以獲得更好的性能。這類模型不顯式地對(duì)齊數(shù)據(jù),也不依賴于監(jiān)督對(duì)齊示例,而是學(xué)習(xí)如何在模型培訓(xùn)期間對(duì)數(shù)據(jù)進(jìn)行隱式對(duì)齊。我們確定了兩種類型的隱式對(duì)齊模型:早期基于圖形模型的工作和更現(xiàn)代的神經(jīng)網(wǎng)絡(luò)方法。
圖形模型已經(jīng)看到了一些早期的工作,用于更好地對(duì)齊機(jī)器翻譯語(yǔ)言之間的單詞[216]和語(yǔ)音音素與其轉(zhuǎn)錄的對(duì)齊[186]。但是,它們需要手動(dòng)構(gòu)造模式之間的映射,例如,將電話映射到聲學(xué)特性的生成電話模型[186]。構(gòu)建這樣的模型需要培訓(xùn)數(shù)據(jù)或人類專業(yè)知識(shí)來(lái)手動(dòng)定義它們。
神經(jīng)網(wǎng)絡(luò)轉(zhuǎn)換(第4節(jié))是一個(gè)建模任務(wù)的例子,如果將對(duì)齊作為潛在的中間步驟執(zhí)行,那么該任務(wù)通常可以得到改進(jìn)。如前所述,神經(jīng)網(wǎng)絡(luò)是解決這一翻譯問(wèn)題的常用方法,可以使用編碼器-解碼器模型,也可以通過(guò)跨模態(tài)檢索。當(dāng)翻譯在沒(méi)有隱式對(duì)齊的情況下執(zhí)行時(shí),它最終會(huì)給編碼器模塊帶來(lái)很大的負(fù)擔(dān),使其能夠使用單個(gè)矢量表示正確地總結(jié)整個(gè)圖像、句子或視頻。
解決這一問(wèn)題的一種非常流行的方法是通過(guò)關(guān)注[12],它允許解碼器將焦點(diǎn)放在源實(shí)例的子組件上。這與在傳統(tǒng)編碼器-解碼器模型中將所有源子組件一起編碼形成對(duì)比。注意模塊將告訴解碼器看起來(lái)更有針對(duì)性的子組件的源代碼翻譯領(lǐng)域的一個(gè)圖像[230],單詞句子的[12],段音頻序列[35],[39],一個(gè)視頻幀和地區(qū)[236],[241],甚至部分指令[140]。例如,在圖像字幕而不是使用CNN對(duì)整個(gè)圖像進(jìn)行編碼時(shí),注意力機(jī)制將允許解碼器(通常是RNN)在生成每個(gè)連續(xù)單詞時(shí)聚焦圖像的特定部分[230]。注意力模塊,它學(xué)習(xí)圖像的哪個(gè)部分要聚焦,通常是一個(gè)淺層的神經(jīng)網(wǎng)絡(luò),與目標(biāo)任務(wù)(如翻譯)一起進(jìn)行端到端的訓(xùn)練。
注意力模型也被成功地應(yīng)用于答題任務(wù)中,因?yàn)樗试S將問(wèn)題中的單詞與信息源的子組件(如文本[228]、圖像[62]或視頻序列[246])進(jìn)行對(duì)齊。這既可以在回答問(wèn)題時(shí)提供更好的性能,也可以帶來(lái)更好的模型可解釋性[4]。尤其是不同類型的注意力模型其中包括分層[128]、層疊[234]和情景記憶注意[228]。
Karpathy等人提出了另一種將圖像與標(biāo)題對(duì)齊以進(jìn)行跨模式檢索的神經(jīng)替代方法。〔98〕,〔99〕。他們提出的模型使用圖像區(qū)域和詞表示之間的點(diǎn)積相似度度量將句子片段與圖像區(qū)域?qū)R,雖然它不使用注意,但通過(guò)訓(xùn)練檢索模型間接學(xué)習(xí)的相似度度量,提取出形式之間潛在的對(duì)齊。
5.3討論
多模態(tài)對(duì)齊面臨許多困難:1)具有顯式標(biāo)注對(duì)齊的數(shù)據(jù)集較少;2)兩種模式之間的相似度指標(biāo)難以設(shè)計(jì);3)可能存在多種可能的對(duì)齊方式,一種模式中的元素不一定在另一種模式中都有對(duì)應(yīng)關(guān)系。早期關(guān)于多模對(duì)準(zhǔn)的工作主要集中在以無(wú)監(jiān)督的方式使用圖形模型和動(dòng)態(tài)編程技術(shù)。
它依賴于手工定義的模式之間相似性的度量,或者在無(wú)監(jiān)督的情況下學(xué)習(xí)它們。隨著最近標(biāo)簽訓(xùn)練數(shù)據(jù)的可用性,監(jiān)督學(xué)習(xí)模式之間的相似性已經(jīng)成為可能。然而,無(wú)監(jiān)督的技術(shù)學(xué)習(xí)聯(lián)合起來(lái)對(duì)齊、轉(zhuǎn)換或融合數(shù)據(jù)也變得流行起來(lái)。
6 融合
多模態(tài)融合是多模態(tài)機(jī)器學(xué)習(xí)中最早提出的課題之一,以往的研究主要側(cè)重于早期、晚期和混合融合方法[50][247]。在技術(shù)術(shù)語(yǔ)中,多模態(tài)融合是將來(lái)自多種模態(tài)的信息集成在一起,并以預(yù)測(cè)結(jié)果為目標(biāo)的概念:通過(guò)分類來(lái)預(yù)測(cè)一個(gè)類別(例如,快樂(lè)vs.悲傷),或者通過(guò)回歸來(lái)預(yù)測(cè)一個(gè)連續(xù)值(例如,情緒的積極性)。這是25年前工作的多模態(tài)機(jī)器學(xué)習(xí)中研究最多的方面之一[243]。
對(duì)多模態(tài)融合的興趣來(lái)自于它能提供的三個(gè)主要好處。首先,能夠訪問(wèn)觀察同一現(xiàn)象的多種模式,可能會(huì)使預(yù)測(cè)更加可靠。
AVSR社區(qū)尤其探索和利用了這一點(diǎn)[163]。其次,能夠訪問(wèn)多種模式可能允許我們捕獲互補(bǔ)的信息——一些在單獨(dú)的模式中不可見(jiàn)的信息。第三,當(dāng)其中一種模態(tài)缺失時(shí),多模態(tài)系統(tǒng)仍然可以運(yùn)行,例如,當(dāng)一個(gè)人不講[50]時(shí),從視覺(jué)信號(hào)中識(shí)別情緒。
多模態(tài)融合有著非常廣泛的應(yīng)用,包括視聽(tīng)語(yǔ)音識(shí)別(AVSR)[163]、多模態(tài)情感識(shí)別[192]、醫(yī)學(xué)圖像分析[89]和多媒體事件檢測(cè)[117]。關(guān)于這個(gè)主題有很多評(píng)論[11]、[163]、[188],〔247〕。它們中的大多數(shù)集中在針對(duì)特定任務(wù)的多模式融合上,例如多媒體分析、信息檢索或情感識(shí)別。相反,我們專注于機(jī)器學(xué)習(xí)方法本身以及與這些方法相關(guān)的技術(shù)挑戰(zhàn)。
雖然之前的一些研究使用多模態(tài)融合這一術(shù)語(yǔ)來(lái)包含所有的多模態(tài)算法,但在本文的研究中,我們將在預(yù)測(cè)后期進(jìn)行多模態(tài)融合的方法歸為融合類,目的是預(yù)測(cè)結(jié)果度量。在最近的工作中,多模態(tài)表示和融合之間的界限已經(jīng)變得模糊,例如深度神經(jīng)網(wǎng)絡(luò),其中表示學(xué)習(xí)與分類或回歸目標(biāo)交織在一起。正如我們將在本節(jié)中描述的那樣,這條線對(duì)于其他方法(如圖形模型和基于內(nèi)核的方法)更加清晰。
我們將多模態(tài)融合分為兩大類:不直接依賴于特定機(jī)器學(xué)習(xí)方法的模型不可知方法(第6.1節(jié));以及在構(gòu)建中顯式處理融合的基于模型的方法(第6.2節(jié)),例如基于內(nèi)核的方法
方法,圖形模型和神經(jīng)網(wǎng)絡(luò)。這些方法的概述見(jiàn)表5。
6.1模型不可知論方法
歷史上,絕大多數(shù)多模融合都是用模型不可知論方法完成的[50]。這種方法可以分為早期(即基于特征)、晚期(即基于決策)和混合融合[11]。早期融合在提取特征后立即集成特征(通常只需將其表示連接起來(lái))。另一方面,后期融合在每種模式做出決定(例如分類或回歸)后執(zhí)行集成。最后,混合融合結(jié)合了早期融合的輸出和單個(gè)單模態(tài)預(yù)測(cè)因子。模型不可知方法的一個(gè)優(yōu)點(diǎn)是,它們幾乎可以使用任何單模態(tài)分類器或回歸器來(lái)實(shí)現(xiàn)。
早期融合可以看作是多模態(tài)研究人員進(jìn)行多模態(tài)表示學(xué)習(xí)的初步嘗試,因?yàn)樗梢詫W(xué)習(xí)利用每種模態(tài)的低層特征之間的相關(guān)性和相互作用。此外,它只需要單個(gè)模型的訓(xùn)練,這使得訓(xùn)練管道比后期和混合融合更容易。
相比之下,延遲融合使用單模態(tài)決策值,并使用平均[181]、投票方案[144]、基于信道噪聲[163]和信號(hào)方差[53]的加權(quán)等融合機(jī)制將其融合,或者使用學(xué)習(xí)模型[68]、[168]。它允許對(duì)每個(gè)模態(tài)使用不同的模型,因?yàn)椴煌念A(yù)測(cè)器可以更好地為每個(gè)單獨(dú)的模態(tài)建模,從而提供更多的靈活性。此外,當(dāng)13種模式中的一種或多種缺失時(shí),可以更容易地進(jìn)行預(yù)測(cè),甚至可以在沒(méi)有并行數(shù)據(jù)可用時(shí)進(jìn)行培訓(xùn)。然而,晚期融合忽略了模式之間的低水平相互作用。
混合融合試圖在公共框架中利用上述兩種方法的優(yōu)點(diǎn)。它已成功地用于多模態(tài)揚(yáng)聲器識(shí)別[226]和多媒體事件檢測(cè)(MED)[117]。
6.2基于模型的方法
雖然使用單模態(tài)機(jī)器學(xué)習(xí)方法很容易實(shí)現(xiàn)模型不可知的方法,但是它們最終使用的技術(shù)不是設(shè)計(jì)用來(lái)處理多模態(tài)數(shù)據(jù)的。在本節(jié)中,我們將描述用于執(zhí)行多模態(tài)融合的三種方法:基于內(nèi)核的方法、圖形模型和神經(jīng)網(wǎng)絡(luò)。
多核學(xué)習(xí)(multi kernel learning, MKL)方法是對(duì)內(nèi)核支持向量機(jī)(kernel support vector machines, SVM)的擴(kuò)展,它允許對(duì)數(shù)據(jù)的不同模式/視圖使用不同的內(nèi)核[70]。由于內(nèi)核可以看作是數(shù)據(jù)點(diǎn)之間的相似函數(shù),MKL中特定于模式的內(nèi)核可以更好地融合異構(gòu)數(shù)據(jù)。
MKL方法是一種特別流行的融合視覺(jué)描述符用于對(duì)象檢測(cè)[31]的方法[66],直到最近才被用于任務(wù)的深度學(xué)習(xí)方法所取代[109]。它們也被用于多模態(tài)情感識(shí)別[36],[90],[182],多模態(tài)情緒分析[162]和多媒體事件檢測(cè)(MED)[237]。此外,McFee和Lanckriet[137]提出使用MKL從聲學(xué)、語(yǔ)義和社會(huì)視角數(shù)據(jù)對(duì)音樂(lè)藝術(shù)家進(jìn)行相似性排序。最后,Liu等[125]在阿爾茨海默病分類中使用MKL進(jìn)行多模態(tài)融合。它們的廣泛適用性證明了這些方法在不同領(lǐng)域和不同模式中的優(yōu)勢(shì)。
除了內(nèi)核選擇的靈活性之外,MKL的優(yōu)點(diǎn)是損失函數(shù)是凸函數(shù),允許使用標(biāo)準(zhǔn)優(yōu)化包和全局最優(yōu)解進(jìn)行模型訓(xùn)練[70]。此外,mkl可以用于執(zhí)行回歸和分類。mkl的一個(gè)主要缺點(diǎn)是在測(cè)試期間依賴于訓(xùn)練數(shù)據(jù)(支持向量),從而導(dǎo)致推理緩慢和內(nèi)存占用大。
圖形模型是多模態(tài)融合的另一種常用方法。在本節(jié)中,我們概述了使用淺層圖形模型進(jìn)行多模態(tài)融合的工作。深度圖形模型的描述,如深度信念網(wǎng)絡(luò),可以在3.1節(jié)中找到。大多數(shù)圖形模型可分為兩大類:生成-建模聯(lián)合概率;或判別-建模條件概率[200]。最早使用圖形模型進(jìn)行多模態(tài)融合的方法包括生成模型,如耦合[149]和階乘隱馬爾可夫模型[67]以及動(dòng)態(tài)貝葉斯網(wǎng)絡(luò)[64]。最近提出的多流HMM方法提出了AVSR模式的動(dòng)態(tài)加權(quán)[75]。
可論證的是,生成模型的受歡迎程度不如條件隨機(jī)場(chǎng)(CRF)等判別模型[115],條件隨機(jī)場(chǎng)犧牲了聯(lián)合概率的建模來(lái)獲得預(yù)測(cè)能力。CRF模型通過(guò)結(jié)合圖像描述的視覺(jué)和文本信息來(lái)更好地分割圖像[60]。CRF模型已經(jīng)擴(kuò)展到使用隱藏的條件隨機(jī)字段來(lái)模擬潛在狀態(tài)[165],并已應(yīng)用于多模態(tài)會(huì)議分割[173]。潛在變量判別圖形模型的其他多模態(tài)應(yīng)用包括多視圖隱藏CRF[194]和潛在變量模型[193]。最近Jiang等[93]展示了多模態(tài)隱藏條件隨機(jī)域在多媒體分類任務(wù)中的優(yōu)勢(shì)。雖然大多數(shù)的圖形模型都是以分類為目的的,但CRF模型已經(jīng)擴(kuò)展到連續(xù)版本進(jìn)行回歸[164],并應(yīng)用于多模態(tài)設(shè)置[13]進(jìn)行聲像情感識(shí)別。
圖形化模型的優(yōu)點(diǎn)是能夠方便地利用數(shù)據(jù)的空間和時(shí)間結(jié)構(gòu),使其在時(shí)間建模任務(wù)(如AVSR和多模態(tài)影響識(shí)別)中特別受歡迎。它們還允許將人類的專家知識(shí)構(gòu)建到模型中。并經(jīng)常導(dǎo)致可解釋的模型。
神經(jīng)網(wǎng)絡(luò)在多模態(tài)融合中得到了廣泛的應(yīng)用[151]。使用神經(jīng)網(wǎng)絡(luò)進(jìn)行多模態(tài)融合的最早例子來(lái)自AVSR的研究[163]。
如今,它們被用來(lái)融合信息,用于視覺(jué)和媒體的問(wèn)答[63]、[130]、[229]、手勢(shì)識(shí)別[150]、情感分析[96]、[153]和視頻描述生成[94]。雖然使用的模式、架構(gòu)和優(yōu)化技術(shù)可能有所不同,但在神經(jīng)網(wǎng)絡(luò)的聯(lián)合隱藏層中融合信息的總體思想是相同的。
神經(jīng)網(wǎng)絡(luò)也被用于融合時(shí)間多模態(tài)信息通過(guò)使用RNNs和LSTMs。較早的此類應(yīng)用之一是使用雙向LSTM進(jìn)行視聽(tīng)情緒分類[224]。最近,Wollmer等人[223]使用–lstm模型進(jìn)行連續(xù)多模態(tài)情緒識(shí)別,顯示了其優(yōu)于圖形模型和SVM。同樣,Nicolaou等人[152]使用LSTMS進(jìn)行持續(xù)情緒預(yù)測(cè)。他們提出的方法使用一個(gè)lstm來(lái)融合模態(tài)特定(音頻和面部表情)lstms的結(jié)果。接近形態(tài)融合通過(guò)遞歸神經(jīng)網(wǎng)絡(luò)被用于各種圖像字幕任務(wù),例如模型包括:神經(jīng)圖像字幕[214],CNN是使用一種LSTM語(yǔ)言解碼圖像表示模型,gLSTM[91]包含了圖像數(shù)據(jù)的句子一起解碼在每一個(gè)時(shí)間步融合視覺(jué)和句子中的數(shù)據(jù)聯(lián)合表示。最近的一個(gè)例子是Rajagopalan等人提出的多視圖LSTM (mvc -LSTM)模型[166]。MV-LSTM模型通過(guò)顯式地建模特定于模態(tài)和跨模態(tài)的交互,允許靈活地融合LSTM框架中的模態(tài)。深度神經(jīng)網(wǎng)絡(luò)方法在數(shù)據(jù)融合方面的一大優(yōu)勢(shì)是能夠從大量數(shù)據(jù)中學(xué)習(xí)。其次,最近的神經(jīng)結(jié)構(gòu)允許對(duì)多模態(tài)表示組件和融合組件進(jìn)行端到端訓(xùn)練。最后,與基于非神經(jīng)網(wǎng)絡(luò)的系統(tǒng)相比,它們表現(xiàn)出了良好的性能,并且能夠?qū)W習(xí)其他方法所面臨的復(fù)雜決策邊界。
神經(jīng)網(wǎng)絡(luò)方法的主要缺點(diǎn)是缺乏可解釋性。很難判斷這種預(yù)測(cè)依賴于什么,以及哪種模式或特征起著重要作用。此外,神經(jīng)網(wǎng)絡(luò)需要大的訓(xùn)練數(shù)據(jù)集才能成功。
6.3討論
多模態(tài)融合是一個(gè)被廣泛研究的課題,提出了許多方法來(lái)解決它,包括模型不可知方法、圖形模型、多核學(xué)習(xí)和各種類型的神經(jīng)網(wǎng)絡(luò)。每種方法都有自己的優(yōu)點(diǎn)和缺點(diǎn),有些方法更適合于較小的數(shù)據(jù)集,有些方法在嘈雜的環(huán)境中性能更好。
最近,神經(jīng)網(wǎng)絡(luò)已經(jīng)成為處理多模態(tài)融合的一種非常流行的方法,然而圖形模型和多核學(xué)習(xí)仍在使用,特別是在訓(xùn)練數(shù)據(jù)有限或模型可解釋性很重要的任務(wù)中。
盡管取得了這些進(jìn)展,多模態(tài)融合仍然面臨以下挑戰(zhàn):1)信號(hào)可能不是時(shí)間對(duì)齊的(可能是密集連續(xù)信號(hào)和稀疏事件);2)難以建立利用補(bǔ)充信息而不僅僅是補(bǔ)充信息的模型;3)每種模態(tài)可能在不同的時(shí)間點(diǎn)表現(xiàn)出不同的類型和不同程度的噪聲。
7 協(xié)同學(xué)習(xí)
分類法中的最后一個(gè)多模態(tài)挑戰(zhàn)是協(xié)同學(xué)習(xí)——通過(guò)從另一個(gè)(資源豐富的)模態(tài)中獲取知識(shí)來(lái)幫助(資源貧乏的)模態(tài)建模。當(dāng)其中一種模式的資源有限時(shí)(缺少帶注釋的數(shù)據(jù)、有噪聲的輸入和不可靠的標(biāo)簽),它尤其重要。我們稱這種挑戰(zhàn)為共同學(xué)習(xí),因?yàn)榇蠖鄶?shù)情況下,輔助模式只在模型訓(xùn)練中使用,在測(cè)試期間不使用。我們根據(jù)培訓(xùn)資源確定了三種類型的共同學(xué)習(xí)方法:并行、非并行和混合。并行數(shù)據(jù)方法需要訓(xùn)練數(shù)據(jù)集,其中來(lái)自一種模式的觀察直接鏈接到來(lái)自其他模式的觀察。換句話說(shuō),當(dāng)多模態(tài)觀測(cè)來(lái)自相同的實(shí)例時(shí),例如在視聽(tīng)語(yǔ)音數(shù)據(jù)集中,其中的視頻和演講樣本來(lái)自同一個(gè)演講者。相反,非并行數(shù)據(jù)方法不需要在不同模式的觀測(cè)之間建立直接聯(lián)系。這些方法通常通過(guò)在類別上使用重疊來(lái)實(shí)現(xiàn)共同學(xué)習(xí)。例如,在零鏡頭學(xué)習(xí)中,傳統(tǒng)的視覺(jué)對(duì)象識(shí)別數(shù)據(jù)集通過(guò)維基百科的第二個(gè)純文本數(shù)據(jù)集進(jìn)行擴(kuò)展,以提高視覺(jué)對(duì)象識(shí)別的通用性。在混合數(shù)據(jù)設(shè)置中,模式通過(guò)共享模式或數(shù)據(jù)集進(jìn)行橋接。共同學(xué)習(xí)方法的概述可以是
見(jiàn)表6,數(shù)據(jù)并行性總結(jié)見(jiàn)圖3。
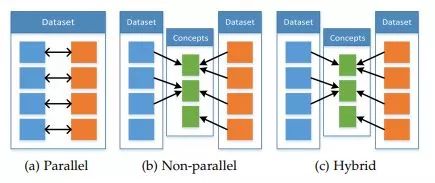
圖3:用于共同學(xué)習(xí)的數(shù)據(jù)并行性類型:并行模式來(lái)自相同的數(shù)據(jù)集,實(shí)例之間存在直接對(duì)應(yīng)關(guān)系;非并行模式來(lái)自不同的數(shù)據(jù)集,沒(méi)有重疊的實(shí)例,但在一般類別或概念上有重疊;混合——實(shí)例或概念通過(guò)第三種模式或數(shù)據(jù)集進(jìn)行橋接。
7.1平行數(shù)據(jù)
在并行數(shù)據(jù)共同學(xué)習(xí)中,兩種模式共享一組實(shí)例——帶有相應(yīng)視頻、圖像及其句子描述的音頻記錄。這允許兩種算法利用這些數(shù)據(jù)來(lái)更好地建模模式:聯(lián)合訓(xùn)練和表示學(xué)習(xí)。
協(xié)同訓(xùn)練是在多模態(tài)問(wèn)題[21]中只有少量的標(biāo)記樣本時(shí),生成更多標(biāo)記樣本的過(guò)程。基本算法在每個(gè)模態(tài)中構(gòu)建弱分類器,以便為未標(biāo)記的數(shù)據(jù)彼此引導(dǎo)標(biāo)簽。研究表明,在Blum和Mitchell的開(kāi)創(chuàng)性工作[21]中,人們發(fā)現(xiàn)了更多基于網(wǎng)頁(yè)本身和超鏈接的網(wǎng)頁(yè)分類培訓(xùn)樣本。根據(jù)定義,該任務(wù)需要并行數(shù)據(jù),因?yàn)樗蕾囉诙嗄B(tài)樣本的重疊。
聯(lián)合訓(xùn)練已用于統(tǒng)計(jì)分析[178]以構(gòu)建更好的視覺(jué)檢測(cè)器[120]和視聽(tīng)語(yǔ)音識(shí)別[40]。它還可以通過(guò)過(guò)濾不可靠的樣本[41]來(lái)處理兩種模式之間的不一致。雖然聯(lián)合訓(xùn)練是一種生成更多標(biāo)記數(shù)據(jù)的強(qiáng)大方法,但它也會(huì)導(dǎo)致訓(xùn)練樣本偏置,導(dǎo)致過(guò)擬合。轉(zhuǎn)移學(xué)習(xí)是利用并行數(shù)據(jù)協(xié)同學(xué)習(xí)的另一種方法。多模表示學(xué)習(xí)(第3.1節(jié))方法,如多模深Boltzmann機(jī)器[198]和多模自動(dòng)編碼器[151]將信息從一種形式的表示轉(zhuǎn)移到另一種形式的表示。這不僅會(huì)導(dǎo)致多模態(tài)表示,而且會(huì)導(dǎo)致更好的單模態(tài)表示,在測(cè)試期間只使用一種模態(tài)[151]。Moon等[143]展示了如何將信息從語(yǔ)音識(shí)別神經(jīng)網(wǎng)絡(luò)(基于音頻)傳輸?shù)酱阶x神經(jīng)網(wǎng)絡(luò)(基于圖像),從而獲得更好的視覺(jué)表征,并建立了一個(gè)在測(cè)試期間無(wú)需音頻信息即可進(jìn)行唇讀的模型。同樣,Arora和Livescu[10]利用CCA在聲學(xué)和發(fā)音(嘴唇、舌頭和下巴的位置)數(shù)據(jù)上構(gòu)建了更好的聲學(xué)特征。他們只在CCA構(gòu)建期間使用發(fā)音數(shù)據(jù),在測(cè)試期間只使用產(chǎn)生的聲學(xué)(單模態(tài))表示。
7.2非并行數(shù)據(jù)
依賴于非并行數(shù)據(jù)的方法不需要模式具有共享實(shí)例,而只需要共享類別或概念。非并行協(xié)同學(xué)習(xí)方法在學(xué)習(xí)表示時(shí)可以提供幫助,允許更好地理解語(yǔ)義概念,甚至可以執(zhí)行不可見(jiàn)的對(duì)象識(shí)別。
遷移學(xué)習(xí)也可以在非并行數(shù)據(jù)上進(jìn)行,并允許通過(guò)將信息從使用數(shù)據(jù)豐富或干凈的模式構(gòu)建的表示傳輸?shù)綌?shù)據(jù)稀缺或嘈雜的模式來(lái)學(xué)習(xí)更好的表示。這種類型的傳輸學(xué)習(xí)通常是通過(guò)使用協(xié)調(diào)的多模態(tài)表示來(lái)實(shí)現(xiàn)的(見(jiàn)第3.2節(jié))。例如,F(xiàn)rome等人[61]通過(guò)將CNN視覺(jué)特征與在單獨(dú)大數(shù)據(jù)集上訓(xùn)練的Word2vec文本特征相協(xié)調(diào),使用文本改善圖像分類的視覺(jué)表示[141]。以這種方式訓(xùn)練出來(lái)的視覺(jué)表現(xiàn)形式會(huì)導(dǎo)致更有意義的錯(cuò)誤——將物體誤認(rèn)為同類物體[61]。Mahasseni和Todorovic[129]演示了如何使用基于3D骨骼數(shù)據(jù)的LSTM自動(dòng)編碼器,通過(guò)增強(qiáng)其隱藏狀態(tài)之間的相似性,來(lái)規(guī)范基于LSTM的彩色視頻。這種方法能夠改進(jìn)原始的LSTM,并在動(dòng)作識(shí)別中實(shí)現(xiàn)最先進(jìn)的性能。
概念基礎(chǔ)是指學(xué)習(xí)語(yǔ)義意義或概念,不僅僅是基于語(yǔ)言,還包括視覺(jué)、聽(tīng)覺(jué)、甚至是嗅覺(jué)[16]等附加形式。雖然大多數(shù)概念學(xué)習(xí)方法都是純語(yǔ)言為基礎(chǔ)的,但人類對(duì)意義的表征不僅是我們語(yǔ)言暴露的產(chǎn)物,而且也是通過(guò)我們的感覺(jué)運(yùn)動(dòng)經(jīng)驗(yàn)和感知系統(tǒng)[17]而建立起來(lái)的[126]。人類的語(yǔ)義知識(shí)在很大程度上依賴于感知信息[126],許多概念是建立在感知系統(tǒng)的基礎(chǔ)上的,并非純粹的符號(hào)[17]。這意味著單純從文本信息中學(xué)習(xí)語(yǔ)義意義可能不是最優(yōu)的,并會(huì)激發(fā)使用視覺(jué)或聽(tīng)覺(jué)線索來(lái)為我們的語(yǔ)言表征奠定基礎(chǔ)。
從工作由馮和Lapata[59],接地通常是由之間找到一個(gè)共同的潛在空間表征[59],[183](并行數(shù)據(jù)集的情況下)或通過(guò)學(xué)習(xí)單峰表示分開(kāi),然后導(dǎo)致一個(gè)多通道連接[29],[101],[172],[181](對(duì)于非并行數(shù)據(jù))。一旦構(gòu)建了多模態(tài)表示,它就可以用于純語(yǔ)言任務(wù)。Shutova et al.[181]和Bruni et al.[29]使用扎根表征對(duì)隱喻和字面語(yǔ)言進(jìn)行了更好的分類。這種表示法也有助于衡量概念上的相似性和關(guān)聯(lián)性——確定兩個(gè)詞在語(yǔ)義上或概念上是如何相關(guān)的[30]、[101]、[183]或行為[172]。此外,概念不僅可以使用視覺(jué)信號(hào),還可以使用聲學(xué)信號(hào),這使得概念在與聽(tīng)覺(jué)相關(guān)的單詞上有更好的表現(xiàn)[103],對(duì)于與嗅覺(jué)相關(guān)的單詞甚至可以使用嗅覺(jué)信號(hào)[102]。最后,多模對(duì)齊和概念性接地之間有很多重疊,因?yàn)閷⒁曈X(jué)場(chǎng)景與其描述對(duì)齊會(huì)導(dǎo)致更好的文本或視覺(jué)表示[108]、[161]、[172]、[240]。
概念基礎(chǔ)已被發(fā)現(xiàn)是一種有效的方法,以提高性能的一些任務(wù)。它還表明,語(yǔ)言和視覺(jué)(或音頻)是互補(bǔ)的信息源,將它們組合在多模態(tài)模型中通常可以提高性能。但是,必須小心,因?yàn)榻拥夭⒉豢偸悄軒?lái)更好的性能[102],[103],并且只有當(dāng)接地與任務(wù)相關(guān)時(shí)才有意義-例如,使用圖像進(jìn)行接地以獲得視覺(jué)相關(guān)概念。
零距離學(xué)習(xí)(Zero shot learning, ZSL)指在沒(méi)有明確看到任何例子的情況下識(shí)別概念。例如,在沒(méi)有見(jiàn)過(guò)(標(biāo)記的)貓的圖像的情況下對(duì)圖像中的貓進(jìn)行分類。這是一個(gè)需要解決的重要問(wèn)題,例如在許多任務(wù)中,如可視化對(duì)象分類:為每一個(gè)感興趣的可想象對(duì)象提供培訓(xùn)示例是非常昂貴的。
ZSL主要有兩種類型——單模態(tài)和多模態(tài)。單模態(tài)ZSL查看對(duì)象的組成部分或?qū)傩裕缬糜谧R(shí)別未聽(tīng)過(guò)的單詞的音素,或用于預(yù)測(cè)未見(jiàn)的可視類[55]的視覺(jué)屬性,如顏色、大小和形狀。多模zsl通過(guò)第二模態(tài)的幫助識(shí)別主模態(tài)中的對(duì)象——在第二模態(tài)中,對(duì)象已經(jīng)被看到。根據(jù)定義,zsl的多模式版本是一個(gè)面臨非并行數(shù)據(jù)的問(wèn)題,因?yàn)樗?jiàn)類的重疊在模式之間是不同的。Socher等[190]將圖像特征映射到概念詞空間,能夠?qū)梢?jiàn)和不可見(jiàn)的概念進(jìn)行分類。然后,看不見(jiàn)的概念可以分配給一個(gè)接近視覺(jué)表示的單詞——這是通過(guò)在一個(gè)單獨(dú)的數(shù)據(jù)集上訓(xùn)練語(yǔ)義空間來(lái)實(shí)現(xiàn)的,該數(shù)據(jù)集看到了更多的概念。而不是學(xué)習(xí)從視覺(jué)到概念空間的映射,F(xiàn)rome等[61]學(xué)習(xí)概念之間的協(xié)調(diào)多模態(tài)表示以及支持ZSL的圖像。Palatucci等人[158]根據(jù)功能磁共振圖像對(duì)人們正在思考的單詞進(jìn)行預(yù)測(cè),他們展示了如何通過(guò)中間語(yǔ)義空間預(yù)測(cè)看不見(jiàn)的單詞。Lazaridou等人[118]提出了一種通過(guò)神經(jīng)網(wǎng)絡(luò)將提取的視覺(jué)特征向量映射到基于文本的向量的快速映射方法。
7.3混合數(shù)據(jù)
在混合數(shù)據(jù)設(shè)置中,兩個(gè)非并行模式由共享模式或數(shù)據(jù)集橋接(見(jiàn)圖3c)。最值得注意的例子是橋接相關(guān)神經(jīng)網(wǎng)絡(luò)[167],它使用一個(gè)中心模態(tài)來(lái)學(xué)習(xí)存在非并行數(shù)據(jù)的協(xié)調(diào)多模態(tài)表示。例如,在多語(yǔ)言圖像標(biāo)題的情況下,圖像模式在任何語(yǔ)言中總是與至少一個(gè)標(biāo)題配對(duì)。這些方法也被用來(lái)連接那些可能沒(méi)有并行語(yǔ)料庫(kù)但可以訪問(wèn)共享的樞軸語(yǔ)言的語(yǔ)言,例如機(jī)器翻譯[148]、[167]和文檔音譯[100]。
有些方法不使用單獨(dú)的模式進(jìn)行橋接,而是依賴于來(lái)自類似或相關(guān)任務(wù)的大型數(shù)據(jù)集的存在,從而在僅包含有限注釋數(shù)據(jù)的任務(wù)中獲得更好的性能。Socher和Fei-Fei[189]利用大文本語(yǔ)料庫(kù)的存在來(lái)指導(dǎo)圖像分割。而Hendricks等[78]采用單獨(dú)訓(xùn)練的視覺(jué)模型和語(yǔ)言模型,可以得到更好的圖像和視頻描述系統(tǒng),但數(shù)據(jù)有限。
7.4討論
多模態(tài)聯(lián)合學(xué)習(xí)允許一種模態(tài)影響另一種模態(tài)的訓(xùn)練,利用跨模態(tài)的互補(bǔ)信息。需要注意的是,聯(lián)合學(xué)習(xí)是獨(dú)立于任務(wù)的,可以用于創(chuàng)建更好的融合、轉(zhuǎn)換和對(duì)齊模型。以協(xié)同訓(xùn)練、多模態(tài)表示學(xué)習(xí)、概念基礎(chǔ)和零鏡頭學(xué)習(xí)(zero shot learning, ZSL)等算法為例,在視覺(jué)分類、動(dòng)作識(shí)別、視聽(tīng)語(yǔ)音識(shí)別和語(yǔ)義相似度估計(jì)等領(lǐng)域得到了廣泛的應(yīng)用。
8 總結(jié)
作為綜述的一部分,我們介紹了多模式機(jī)器學(xué)習(xí)的分類法:表示、翻譯、融合、對(duì)齊和共同學(xué)習(xí)。其中一些,如融合,已經(jīng)研究了很長(zhǎng)時(shí)間,但最近對(duì)表示和翻譯的興趣導(dǎo)致了大量新的多模態(tài)算法和令人興奮的多模態(tài)應(yīng)用。我們相信,我們的分類法將有助于編目未來(lái)的研究論文,并更好地理解多模機(jī)器學(xué)習(xí)所面臨的遺留問(wèn)題。
——The ?End——

