
[源碼解析] 模型并行分布式訓(xùn)練 Megatron (1) --- 論文&基礎(chǔ)
0x00 摘要0x01 Introduction1.1 問題1.2 數(shù)據(jù)并行1.3 模型并行1.3.1 通信1.3.2 張量并行1.3.3 流水線并行1.4 技術(shù)組合1.5 指導(dǎo)原則0x02 張量模型并行(Tensor Model Parallelism)2.1 原理2.1.1 行并行(Row Parallelism)2.1.2 列并行(Column Parallelism)2.2 Model Parallel Transformers2.2.1 Transformer2.2.2 切分 Transformer2.2.3 切分MLP2.2.4 切分self attention2.2.5 通信2.2.6 小結(jié)0x03 并行配置3.1 符號說明3.2 Tensor and Pipeline Model Parallelism3.3 Data and Model Parallelism3.3.1 Pipeline Model Parallelism.3.3.2 Data and Tensor Model Parallelism.3.4 Microbatch Size3.5 對比3.5.1 Tensor versus Pipeline Parallelism.3.5.2 Pipeline versus Data Parallelism.3.5.3 Tensor versus Data Parallelism.0x04 結(jié)論0xFF 參考
0x00 摘要
NVIDIA Megatron 是一個基于 PyTorch 的分布式訓(xùn)練框架,用來訓(xùn)練超大Transformer語言模型,其通過綜合應(yīng)用了數(shù)據(jù)并行,Tensor并行和Pipeline并行來復(fù)現(xiàn) GPT3,值得我們深入分析其背后機理。
本系列大概有6~7篇文章,通過論文和源碼和大家一起學習研究。
本文把 Megatron 的兩篇論文/一篇官方PPT 選取部分內(nèi)容,糅合在一起進行翻譯分析,希望大家可以通過本文對 Megatron 思路有一個基本了解。
0x01 Introduction
1.1 問題
在NLP領(lǐng)域之中,大模型可以帶來更精準強大的語義理解和推理能力,所以隨著規(guī)模計算的普及和數(shù)據(jù)集的增大,使得模型的參數(shù)數(shù)量也以指數(shù)級的速度增長。訓(xùn)練這樣大的模型非常具有挑戰(zhàn)性,具體原因如下:
(a) 對顯存的挑戰(zhàn)。即使是最大的GPU的主內(nèi)存也不可能適合這些模型的參數(shù),比如一個175B的GPT-3模型需要(175B * 4bytes)就是700GB模型參數(shù)空間,從而梯度也是700G,優(yōu)化器狀態(tài)是1400G,一共2.8TB。
(b) 對計算的挑戰(zhàn)。即使我們能夠把模型放進單個GPU中(例如,通過在主機和設(shè)備內(nèi)存之間交換參數(shù)),但是其所需的大量計算操作會導(dǎo)致漫長訓(xùn)練時間(例如,使用單個V100 NVIDIA GPU來訓(xùn)練1750億個參數(shù)的GPT-3需要大約288年)。如何計算可以參見 2104.04473的附錄 FLOATING-POINT OPERATIONS。
(c) 對計算的挑戰(zhàn)。不同并行策略對應(yīng)的通信模式和通信量不同。
數(shù)據(jù)并行:通信發(fā)生在后向傳播的梯度規(guī)約all-reduce操作,通信量是每個GPU之上模型的大小。
模型并行:我們在下面會詳述。
這就需要采用并行化來加速。使用硬件加速器來橫向擴展(scale out)深度神經(jīng)網(wǎng)絡(luò)訓(xùn)練主要有兩種模式:數(shù)據(jù)并行,模型并行。
1.2 數(shù)據(jù)并行
數(shù)據(jù)并行模式會在每個worker之上復(fù)制一份模型,這樣每個worker都有一個完整模型的副本。輸入數(shù)據(jù)集是分片的,一個訓(xùn)練的小批量數(shù)據(jù)將在多個worker之間分割;worker定期匯總它們的梯度,以確保所有worker看到一個一致的權(quán)重版本。對于無法放進單個worker的大型模型,人們可以在模型之中較小的分片上使用數(shù)據(jù)并行。
數(shù)據(jù)并行擴展通常效果很好,但有兩個限制:
a)超過某一個點之后,每個GPU的batch size變得太小,這降低了GPU的利用率,增加了通信成本;
b)可使用的最大設(shè)備數(shù)就是batch size,著限制了可用于訓(xùn)練的加速器數(shù)量。
1.3 模型并行
人們會使用一些內(nèi)存管理技術(shù),如激活檢查點(activation checkpointing)來克服數(shù)據(jù)并行的這種限制,也會使用模型并行來對模型進行分區(qū)來解決這兩個挑戰(zhàn),使得權(quán)重及其關(guān)聯(lián)的優(yōu)化器狀態(tài)不需要同時駐留在處理器上。
模型并行模式會讓一個模型的內(nèi)存和計算分布在多個worker之間,以此來解決一個模型在一張卡上無法容納的問題,其解決方法是把模型放到多個設(shè)備之上。
模型并行分為兩種:流水線并行和張量并行,就是把模型切分的方式。
流水線并行(pipeline model parallel)是把模型不同的層放到不同設(shè)備之上,比如前面幾層放到一個設(shè)備之上,中間幾層放到另外一個設(shè)備上,最后幾層放到第三個設(shè)備之上。
張量并行則是層內(nèi)分割,把某一個層做切分,放置到不同設(shè)備之上,也可以理解為把矩陣運算分配到不同的設(shè)備之上,比如把某個矩陣乘法切分成為多個矩陣乘法放到不同設(shè)備之上。
具體如下圖,上面是層間并行(流水線并行),縱向切一刀,前面三層給第一個GPU,后面三層給第二個GPU。下面是層內(nèi)并行(tensor并行),橫向切一刀,每個張量分成兩塊,分到不同GPU之上。

或者從另一個角度看看,兩種切分同時存在,是正交和互補的(orthogonal and complimentary)。

圖來自:GTC 2020: Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
1.3.1 通信
我們接下來看看模型并行的通信狀況。
張量并行:通信發(fā)生在每層的前向傳播和后向傳播過程之中,通信類型是all-reduce,不但單次通信數(shù)據(jù)量大,并且通信頻繁。
流水線并行:通信在流水線階段相鄰的切分點之上,通信類型是P2P通信,單詞通信數(shù)據(jù)量較少但是比較頻繁,而且因為流水線的特點,會產(chǎn)生GPU空閑時間,這里稱為流水線氣泡(Bubble)。
比如下圖之中,上方是原始流水線,下面是模型并行,中間給出了 Bubble 位置。

因為張量并行一般都在同一個機器之上,所以通過 NVLink 來進行加速,對于流水線并行,一般通過 Infiniband 交換機進行連接。

圖來自 Megatron 論文。
1.3.2 張量并行
有些工作在張量(層內(nèi))模型并行化( tensor (intra-layer) model parallelism)做出了一些嘗試,即每個transformer 層內(nèi)的矩陣乘法被分割到多個GPU上,雖然這種方法在NVIDIA DGX A100服務(wù)器(有8個80GB-A100 GPU)上對規(guī)模不超過200億個參數(shù)的模型效果很好,但對更大的模型就會出現(xiàn)問題。因為較大的模型需要在多個多GPU服務(wù)器上分割,這導(dǎo)致了兩個問題。
(a) 張量并行所需的all-reduce通信需要通過服務(wù)器間的鏈接,這比多GPU服務(wù)器內(nèi)的高帶寬NVLink要慢;
(b) 高度的模型并行會產(chǎn)生很多小矩陣乘法(GEMMs),這可能會降低GPU的利用率。
1.3.3 流水線并行
流水線模型并行化是另一項支持大型模型訓(xùn)練的技術(shù)。在流水線并行之中,一個模型的各層會在多個GPU上做切分。一個批次(batch)被分割成較小的微批(microbatches),并在這些微批上進行流水線式執(zhí)行。
通過流水線并行,一個模型的層被分散到多個設(shè)備上。當用于具有相同transformer塊重復(fù)的模型時,每個設(shè)備可以被分配相同數(shù)量的transformer層。Megatron不考慮更多的非對稱模型架構(gòu),在這種架構(gòu)下,層的分配到流水線階段是比較困難的。在流水線模型并行中,訓(xùn)練會在一個設(shè)備上執(zhí)行一組操作,然后將輸出傳遞到流水線中下一個設(shè)備,下一個設(shè)備將執(zhí)行另一組不同操作。
原生(naive)流水線會有這樣的問題:一個輸入在后向傳遞中看到的權(quán)重更新并不是其前向傳遞中所對應(yīng)的。所以,流水線方案需要確保輸入在前向和后向傳播中看到一致的權(quán)重版本,以實現(xiàn)明確的同步權(quán)重更新語義。
模型的層可以用各種方式分配給worker,并且對于輸入的前向計算和后向計算使用不同的schedule。層的分配策略和調(diào)度策略導(dǎo)致了不同的性能權(quán)衡。無論哪種調(diào)度策略,為了保持嚴格的優(yōu)化器語義,優(yōu)化器操作步驟(step)需要跨設(shè)備同步,這樣,在每個批次結(jié)束時需要進行流水線刷新來完成微批執(zhí)行操作(同時沒有新的微批被注入)。Megatron引入了定期流水線刷新。
在每個批次的開始和結(jié)束時,設(shè)備是空閑的。我們把這個空閑時間稱為流水線bubble,并希望它盡可能的小。根據(jù)注入流水線的微批數(shù)量,多達50%的時間可能被用于刷新流水線。微批數(shù)量與流水線深度(size)的比例越大,流水線刷新所花費的時間就越少。因此,為了實現(xiàn)高效率,通常需要較大的batch size。
一些方法將參數(shù)服務(wù)器與流水線并行使用。然而,這些都存在不一致的問題。TensorFlow的GPipe框架通過使用同步梯度下降克服了這種不一致性問題。然而,這種方法需要額外的邏輯來處理這些通信和計算操作流水線,并且會遇到降低效率的流水線氣泡,或者對優(yōu)化器本身的更改會影響準確性。
某些異步和bounded-staleness方法,如PipeMare、PipeDream和PipeDream-2BW完全取消了刷新,但這樣會放松了權(quán)重更新語義。Megatron會在未來的工作中考慮這些方案。
1.4 技術(shù)組合
用戶可以使用各種技術(shù)來訓(xùn)練他們的大型模型,每種技術(shù)都有不同的權(quán)衡。此外,這些技術(shù)也可以被結(jié)合起來使用。然而,結(jié)合這些技術(shù)會導(dǎo)致復(fù)雜的相互作用,對于系統(tǒng)拓撲是個極大的挑戰(zhàn),不僅要對模型做合理切割(依據(jù)算法特點),還需要做軟硬件一體的系統(tǒng)架構(gòu)設(shè)計,需要仔細推理以獲得良好的性能。因此以下問題就特別重要:
應(yīng)該如何組合并行技術(shù),以便在保留嚴格的優(yōu)化器語義的同時,在給定的batch size下最大限度地提高大型模型的訓(xùn)練吞吐量?
Megatron-LM 開發(fā)人員展示了一個如何結(jié)合流水線、張量和數(shù)據(jù)并行,名為PTD-P的技術(shù),這項技術(shù)將以良好的計算性能(峰值設(shè)備吞吐量的52%)在1000個GPU上訓(xùn)練大型語言模型。PTD-P利用跨多GPU服務(wù)器的流水線并行、多GPU服務(wù)器內(nèi)的張量并行和數(shù)據(jù)并行的組合,在同一服務(wù)器和跨服務(wù)器的GPU之間具有高帶寬鏈接的優(yōu)化集群環(huán)境中訓(xùn)練具有一萬億個參數(shù)的模型,并具有優(yōu)雅的擴展性。

要實現(xiàn)這種規(guī)模化的吞吐量,需要在多個方面進行創(chuàng)新和精心設(shè)計:
高效的核(kernel)實現(xiàn),這使大部分計算操作是計算綁定(compute-bound)而不是內(nèi)存綁定(memory-bound。
在設(shè)備上對計算圖進行智能分割,以減少通過網(wǎng)絡(luò)發(fā)送的字節(jié)數(shù),同時也限制設(shè)備的空閑時間。
實施特定領(lǐng)域的通信優(yōu)化和使用高速硬件(比如最先進的GPU,并且同一服務(wù)器內(nèi)和不同服務(wù)器GPU之間使用高帶寬鏈接)。
1.5 指導(dǎo)原則
Megatron 開發(fā)者研究了各種組合之間如何影響吞吐量,基于這些研究得出來分布式訓(xùn)練的一些指導(dǎo)原則:
不同的并行模式以復(fù)雜的方式互相作用:并行化策略影響通信量、核的計算效率,以及worker因流水線刷新(流水線氣泡)而等待的空閑時間。例如,張量模型并行在多GPU服務(wù)器中是有效的,但大模型必須采用流水線模型并行。
用于流水線并行的schdule對通信量、流水線氣泡大小和用于存儲激活的內(nèi)存都有影響。Megatron 提出了一個新的交錯schdule,與以前提出的schdule相比,它可以在稍微提高內(nèi)存占用的基礎(chǔ)上提高多達10%的吞吐量。
超參數(shù)的值,如microbatch size,對memory footprint、在worker上執(zhí)行的核效果和流水線bubble大小有影響。
分布式訓(xùn)練是通信密集型的。使用較慢的節(jié)點間連接或更多的通信密集型分區(qū)會阻礙性能。
0x02 張量模型并行(Tensor Model Parallelism)
2.1 原理
我們用 GEMM 來看看如何進行模型并行,這里要進行的是 XA = Y,對于模型來說,X 是輸入,A是權(quán)重,Y是輸出。從數(shù)學原理上來看,對于linear層就是把矩陣分塊進行計算,然后把結(jié)果合并,對于非linear層則不做額外設(shè)計。
2.1.1 行并行(Row Parallelism)
我們先看看Row Parallelism,就是把 A 按照行分割成兩部分。為了保證運算,同時我們也把 X 按照列來分割為兩部分,這里 的最后一個維度等于 最前的一個維度,理論上是: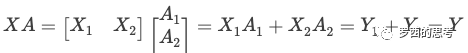
所以,和 就可以放到第一個 GPU 之上計算, 和 可以放到第二個 GPU 之上,然后把結(jié)果相加。

我們接下來進行計算。第一步是把圖上橫向紅色箭頭和縱向箭頭進行點積,得到Y(jié)中的綠色。

第三步,計算出來一個新的綠色。

第四步,計算了輸出的一行。

第五步,繼續(xù)執(zhí)行,得出了一個 。

第六步,得出了藍色的 ,此時,可以把 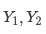 加起來,得到最終的輸出 Y。
加起來,得到最終的輸出 Y。

2.1.2 列并行(Column Parallelism)
我們接下來看看另外一種并行方式Column Parallelism,就是把 A按照列來分割。

最終計算結(jié)果如下:

圖來自:GTC 2020: Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
2.2 Model Parallel Transformers
這里Transformer的模型并行,特指層內(nèi)切分,即 Tensor Model Parallel。
2.2.1 Transformer
自從2018年Google的Attention論文推出之后,近年的模型架構(gòu)都是在 Transformer基礎(chǔ)之上完成,模型有多少層,就意味著模型有多少個Transformer塊,所以語言模型的計算量主要是Transformer的計算,而Transformer本質(zhì)上就是大量的矩陣計算,適合GPU并行操作。
Transformers層由一個Masked Multi Self Attention和Feed Forward兩部分構(gòu)成,F(xiàn)eed Forward 部分是一個MLP網(wǎng)絡(luò),由多個全連接層構(gòu)成,每個全連接層是由矩陣乘操作和GeLU激活層或者Dropout構(gòu)成。
Megatron 的 Feed Forward 是一個兩層多層感知器(MLP),第一層是從 H變成4H,第二層是從 4H 變回到 H,所以Transformer具體架構(gòu)如下,紫色塊對應(yīng)于全連接層。每個藍色塊表示一個被復(fù)制N次的transformer層,紅色的 x L 代表此藍色復(fù)制 L 次。

2.2.2 切分 Transformer
分布式張量計算是一種正交且更通用的方法,它將張量操作劃分到多個設(shè)備上,以加速計算或增加模型大小。FlexFlow是一個進行這種并行計算的深度學習框架,并且提供了一種選擇最佳并行化策略的方法。最近,Mesh TensorFlow引入了一種語言,用于指定TensorFlow中的一般分布式張量計算。用戶在語言中指定并行維度,并使用適當?shù)募显Z編譯生成一個計算圖。我們采用了Mesh TensorFlow的相似見解,并利用transformer's attention heads 的計算并行性來并行化Transformer模型。然而,Megatron沒有實現(xiàn)模型并行性的框架和編譯器,而是對現(xiàn)有的PyTorch transformer實現(xiàn)進行了一些有針對性的修改。Megatron的方法很簡單,不需要任何新的編譯器或代碼重寫,只是通過插入一些簡單的原語來完全實現(xiàn),
Megatron就是要把 Masked Multi Self Attention 和Feed Forward 都進行切分以并行化,利用Transformers網(wǎng)絡(luò)的結(jié)構(gòu),通過添加一些同步原語來創(chuàng)建一個簡單的模型并行實現(xiàn)。
2.2.3 切分MLP
我們從MLP塊開始。MLP 塊的第一部分是GEMM,后面是GeLU:
并行化GEMM的一個選項是沿行方向分割權(quán)重矩陣A,沿列切分輸入X:
分區(qū)的結(jié)果就變成  ,括號之中的兩項,每一個都可以在一個獨立的GPU之上完成,然后通過 all-reduce 操作完成求和操縱。既然 GeLU 是一個非線性函數(shù),那么就有
,括號之中的兩項,每一個都可以在一個獨立的GPU之上完成,然后通過 all-reduce 操作完成求和操縱。既然 GeLU 是一個非線性函數(shù),那么就有  ,所以這種方案需要在 GeLU 函數(shù)之前加上一個同步點。這個同步點讓不同GPU之間交換信息。
,所以這種方案需要在 GeLU 函數(shù)之前加上一個同步點。這個同步點讓不同GPU之間交換信息。
另一個選項是沿列拆分A,得到  。該分區(qū)允許GeLU非線性獨立應(yīng)用于每個分區(qū)GEMM的輸出:
。該分區(qū)允許GeLU非線性獨立應(yīng)用于每個分區(qū)GEMM的輸出: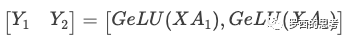
這個方法更好,因為它刪除了同步點,直接把兩個 GeLU 的輸出拼接在一起就行。因此,我們以這種列并行方式劃分第一個GEMM,并沿其行分割第二個GEMM,以便它直接獲取GeLU層的輸出,而不需要任何其他通信(比如 all-reduce 就不需要了),如圖所示。

上圖第一個是 GeLU 操作,第二個是 Dropout操作,具體邏輯如下:
MLP的整個輸入 X 通過 f 放置到每一塊 GPU 之上。
對于第一個全連接層:
使用列分割,把權(quán)重矩陣切分到兩塊 GPU 之上,得到 。
在每一塊 GPU 之上進行矩陣乘法得到第一個全連接層的輸出 和 。
對于第二個全連接層:
使用行切分,把權(quán)重矩陣切分到兩個 GPU 之上,得到 。
前面輸出 和 正好滿足需求,直接可以和 B 的相關(guān)部分()做相關(guān)計算,不需要通信或者其他操作,就得到了
 。分別位于兩個GPU之上。
。分別位于兩個GPU之上。- 通過 g 做 all-reduce(這是一個同步點),再通過 dropout 得到了最終的輸出 Z。
然后在GPU之上,第二個GEMM的輸出在傳遞到dropout層之前進行規(guī)約。這種方法將MLP塊中的兩個GEMM跨GPU進行拆分,并且只需要在前向過程中進行一次 all-reduce 操作(g 操作符)和在后向過程中進行一次 all-reduce 操作(f 操作符)。這兩個操作符是彼此共軛體,只需幾行代碼就可以在PyTorch中實現(xiàn)。作為示例,f 運算符的實現(xiàn)如下所示:

f算子的實現(xiàn)。g類似于f,在后向函數(shù)中使用identity,在前向函數(shù)中使用all-reduce。
2.2.4 切分self attention
如下圖所示。
首先,對于自我注意力塊,Megatron 利用了多頭注意力操作中固有的并行性,以列并行方式對與鍵(K)、查詢(Q)和值(V)相關(guān)聯(lián)的GEMM進行分區(qū),從而在一個GPU上本地完成與每個注意力頭對應(yīng)的矩陣乘法。這使我們能夠在GPU中分割每個attention head參數(shù)和工作負載,每個GPU得到了部分輸出。
其次,對于后續(xù)的全連接層,因為每個GPU之上有了部分輸出,所以對于權(quán)重矩陣B就按行切分,與輸入的
進行直接計算,然后通過 g 之中的 all-reduce 操作和Dropout 得到最終結(jié)果 Z。

圖:具有模型并行性的transformer塊。f和g是共軛的。f在前向傳播中使用一個identity運算符,在后向傳播之中使用了all reduce,而g在前向傳播之中使用了all reduce,在后向傳播中使用了identity運算符。
2.2.5 通信
來自線性層(在 self attention 層之后)輸出的后續(xù)GEMM會沿著其行實施并行化,并直接獲取并行注意力層的輸出,而不需要GPU之間的通信。這種用于MLP和自我注意層的方法融合了兩個GEMM組,消除了中間的同步點,并導(dǎo)致更好的伸縮性。這使我們能夠在一個簡單的transformer層中執(zhí)行所有GEMM,只需在正向路徑中使用兩個all-reduce,在反向路徑中使用兩個all-reduce(見下圖)。

圖:transformer層中的通信操作。在一個單模型并行transformer層的正向和反向傳播中總共有4個通信操作。
Transformer語言模型輸出了一個嵌入,其維數(shù)為隱藏大小(H)乘以詞匯量大小(v)。由于現(xiàn)代語言模型的詞匯量約為數(shù)萬個(例如,GPT-2使用的詞匯量為50257),因此將嵌入GEMM的輸出并行化是非常有益的。然而,在transformer語言模型中,想讓輸出嵌入層與輸入嵌入層共享權(quán)重,需要對兩者進行修改。
我們沿著詞匯表維度  (按列)對輸入嵌入權(quán)重矩陣進行并行化。因為每個分區(qū)現(xiàn)在只包含嵌入表的一部分,所以在輸入嵌入之后需要一個all-reduce(g操作符)。對于輸出嵌入,一種方法是執(zhí)行并行
(按列)對輸入嵌入權(quán)重矩陣進行并行化。因為每個分區(qū)現(xiàn)在只包含嵌入表的一部分,所以在輸入嵌入之后需要一個all-reduce(g操作符)。對于輸出嵌入,一種方法是執(zhí)行并行  以獲得logit,然后添加一個all-gather
以獲得logit,然后添加一個all-gather  ,并將結(jié)果發(fā)送到交叉熵損失函數(shù)。但是,在這種情況下,由于詞匯表的很大,all-gather 將傳遞 個元素(b是batch size,s是序列長度)。為了減小通信規(guī)模,我們將并行
,并將結(jié)果發(fā)送到交叉熵損失函數(shù)。但是,在這種情況下,由于詞匯表的很大,all-gather 將傳遞 個元素(b是batch size,s是序列長度)。為了減小通信規(guī)模,我們將并行 的輸出與交叉熵損失進行融合,從而將維數(shù)降低到。
的輸出與交叉熵損失進行融合,從而將維數(shù)降低到。
2.2.6 小結(jié)
我們的模型并行方法旨在減少通信和控制GPU計算范圍的。我們不是讓一個GPU計算dropout、layer normalization或 residual connection,并將結(jié)果廣播給其他GPU,而是選擇跨GPU復(fù)制計算。
模型并行性與數(shù)據(jù)并行性是正交的,因此我們可以同時使用二者在來訓(xùn)練大型模型。下圖顯示了一組用于混合模型并行和數(shù)據(jù)并行性的GPU。
一個模型需要占據(jù)8張卡,模型被復(fù)制了64分,一共啟動了512個即成。
模型并行。同一服務(wù)器內(nèi)的多個GPU形成模型并行組(model parallel group),例如圖中的GPU 1到8,并包含分布在這些GPU上的模型實例。其余的GPU可能位于同一臺服務(wù)器內(nèi),也可能位于其他服務(wù)器中,它們運行其他模型并行組。每個模型并行組內(nèi)的GPU執(zhí)行組內(nèi)所有GPU之間的all-reduce。
數(shù)據(jù)并行。在每個模型并行組中具有相同位置的GPU(例如圖中的GPU 1,9,…,505)形成數(shù)據(jù)并行組(data parallel group),即,具有相同模型參數(shù)的進程被分配到同一個數(shù)據(jù)并行組之中。對于數(shù)據(jù)并行,每個all-reduce操作在每個模型并行組中一個GPU之上執(zhí)行。
所有通信都是通過pytorch調(diào)用NCCL來實現(xiàn)的。
在反向傳播過程中,我們并行運行多個梯度all-reduce操作,以規(guī)約每個不同數(shù)據(jù)并行組中的權(quán)重梯度。所需GPU的總數(shù)是模型和數(shù)據(jù)并行組數(shù)量的乘積。

混合模型和數(shù)據(jù)并行的GPU分組,8路模型并行和64路數(shù)據(jù)并行。
0x03 并行配置
我們接著看如何混合使用各種并行。
3.1 符號說明
以下是本文余下使用的符號說明。

3.2 Tensor and Pipeline Model Parallelism
張量和流水線模型并行性都可以用于在多個GPU上劃分模型的參數(shù)。如前所述,將流水線并行性與周期性刷新一起使用會產(chǎn)生大小為  的流水線氣泡。讓我們假設(shè)?? = 1(數(shù)據(jù)并行大小),因此 ?? · ?? = ??。在此情況下,流水線氣泡大小是:
的流水線氣泡。讓我們假設(shè)?? = 1(數(shù)據(jù)并行大小),因此 ?? · ?? = ??。在此情況下,流水線氣泡大小是:

假如我們固定??, ??, 和?? (?? = ??/(?? · ??) 也固定下來),當 ?? 增加時,流水線氣泡會相應(yīng)減小。
不同GPU之間通信量也受?? 和?? 的影響。管道模型并行具有更便宜的點對點通信。另一方面,張量模型并行性使用更消耗帶寬的all-reduce通信(向前和向后傳遞中各有兩個all-reduce操作)。
使用流水線并行,在每對連續(xù)設(shè)備(向前或向后傳播)之間為每個微批次執(zhí)行的通信總量為????h,?? 是序列長度,h是隱藏大小(hidden size)。
使用張量模型并行,每個層前向傳播和后向傳播中,總大小????h的張量需要在 ?? 個模型副本之中 all-reduce 兩次。
因此,我們看到張量模型并行性增加了設(shè)備之間的通信量。因此,當 ?? 大于單個節(jié)點中的GPU數(shù)量時,在較慢的節(jié)點間鏈路上執(zhí)行張量模型并行是不合算的。
因此得到:
結(jié)論#1:當考慮不同形式的模型并行時,當使用??-GPU服務(wù)器,通常應(yīng)該把張量模型并行度控制在 ?? 之內(nèi),然后使用流水線并行來跨服務(wù)器擴展到更大的模型。

3.3 Data and Model Parallelism
然后考慮數(shù)據(jù)并行和模型并行。
3.3.1 Pipeline Model Parallelism.
我們給定 ?? = 1 (tensor-model-parallel size),那么每個流水線的微批次數(shù)目是  ,這里
,這里 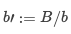 。給定 GPU 數(shù)目為 n,流水線階段的數(shù)目是 ?? = ??/(?? · ??) = ??/??,流水線氣泡大小是:
。給定 GPU 數(shù)目為 n,流水線階段的數(shù)目是 ?? = ??/(?? · ??) = ??/??,流水線氣泡大小是:
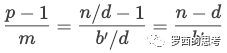
當 ?? 變大,?? ? ?? 變小,因此流水線氣泡變小。因為模型訓(xùn)練需要的內(nèi)存占用可能大于單個加速器的內(nèi)存容量,所以不可能增加?? 一直到??。而數(shù)據(jù)并行性所需的all-reduce通信不會隨著更高的數(shù)據(jù)并行度而增加。
我們還可以分析 batch size ?? 增加帶來的影響。對于給定的并行配置,如批大小?? 增加,??′ = ??/?? 增加,(?? ? ??)/??′ 會相應(yīng)減少,從而增加吞吐量。數(shù)據(jù)并行所需的all-reduce也變得更少,從而進一步提高了吞吐量。
3.3.2 Data and Tensor Model Parallelism.
使用張量模型并行,每個微批次都需要執(zhí)行all-reduce通信。這在多GPU服務(wù)器之間可能非常昂貴。另一方面,數(shù)據(jù)并行性對于每個批次只需執(zhí)行一次 all-reduce。此外,使用張量模型并行,每個模型并行rank在每個模型層中只執(zhí)行計算的子集,因此對于不夠大的層,現(xiàn)代GPU可能無法以最高效率執(zhí)行這些子矩陣計算。
結(jié)論#2:當使用數(shù)據(jù)和模型并行時,總的模型并行大小應(yīng)該為?? = ?? · ?? ,這樣模型參數(shù)和中間元數(shù)據(jù)可以放入GPU內(nèi)存。數(shù)據(jù)并行性可用于將訓(xùn)練擴展到更多GPU。

3.4 Microbatch Size
微批尺寸 ?? 的選擇也影響到模型訓(xùn)練的吞吐量。例如,在單個GPU上,如果微批尺寸較大,每個GPU的吞吐量最多可增加1.3倍。現(xiàn)在,在定并行配置(??,??,??)和批量大小??下,我們想確定最佳微批尺寸??。
無論微批大小如何,數(shù)據(jù)并行通信量將是相同的。鑒于函數(shù) 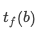 和
和  將微批大小映射到單個微批的前向和后向計算時間,在忽略通信成本的條件下,計算一個batch的總時間為(如前,定義??′為??/??)。
將微批大小映射到單個微批的前向和后向計算時間,在忽略通信成本的條件下,計算一個batch的總時間為(如前,定義??′為??/??)。
因此,微批的大小既影響操作的算術(shù)強度,也影響管道 bubble 大小(通過影響??)。
經(jīng)驗之談#3: 最佳微批尺寸??取決于模型的吞吐量和內(nèi)存占用特性,以及管道深度??、數(shù)據(jù)并行尺寸??和批尺寸??。

3.5 對比
我們接下來看看各種并行機制的對比。
3.5.1 Tensor versus Pipeline Parallelism.
我們觀察到,張量模型的并行性在節(jié)點(DGX A100服務(wù)器)內(nèi)是最好的,因為它會減少通信量。另一方面,流水線模型并行使用更便宜的點對點通信,可以跨節(jié)點執(zhí)行,而不會限制整個計算。然而,流水線并行性會在流水線氣泡中花費大量時間,因此,應(yīng)限制流水線級的總數(shù),以便流水線中的microbatches數(shù)量是流水線深度的合理倍數(shù)。因此,當張量并行大小等于單個節(jié)點中的GPU數(shù)量(8個,DGX A100個節(jié)點)時會達到峰值性能。這一結(jié)果表明,單獨使用張量模型并行性(Megatron V1)和流水線模型并行性(PipeDream)都無法與這兩種技術(shù)結(jié)合使用的性能相匹配。
3.5.2 Pipeline versus Data Parallelism.
通過實驗發(fā)現(xiàn),對于每個batch size,吞吐量隨著流水線并行規(guī)模的增加而降低。流水線模型并行應(yīng)該主要用于支持不適合單個 worker 的大型模型訓(xùn)練,數(shù)據(jù)并行應(yīng)該用于擴大訓(xùn)練規(guī)模。
3.5.3 Tensor versus Data Parallelism.
接下來看看數(shù)據(jù)和張量模型的并行性對性能的影響。在較大的批處理量和微批處理量為1的情況下,數(shù)據(jù)并行通信并不頻繁;張量模型并行需要對批處理中的每個微批進行all-to-all通信。這種all-to-all的通信與張量模型并行主義的通信主導(dǎo)了端到端的訓(xùn)練時間,特別是當通信需要在多GPU節(jié)點上進行時。此外,隨著張量模型并行規(guī)模的增加,我們在每個GPU上執(zhí)行較小的矩陣乘法,降低了每個GPU的利用率。
我們應(yīng)該注意到,盡管數(shù)據(jù)并行可以帶來高效的擴展,但我們不能單獨使用數(shù)據(jù)并行來處理訓(xùn)練批量有限的大型模型,因為a)內(nèi)存容量不足,b)數(shù)據(jù)并行的擴展限制(例如,GPT-3的訓(xùn)練批量為1536。因此,數(shù)據(jù)并行性只支持并行到1536個GPU;然而,大約有10000個GPU用來訓(xùn)練這個模型)。
0x04 結(jié)論
Megatron使用了PTD-P(節(jié)點間流水線并行、節(jié)點內(nèi)張量并行和數(shù)據(jù)并行)在訓(xùn)練具有萬億參數(shù)的大型模型時候達到了高聚合吞吐量(502 petaFLOP/s)。
Tensor模型并行被用于intra-node transformer 層,這樣在HGX based系統(tǒng)上高效運行。
Pipeline 模型并行被用于inter-node transformer 層,其可以有效利用集群中多網(wǎng)卡設(shè)計。
數(shù)據(jù)并行則在前兩者基礎(chǔ)之上進行加持,使得訓(xùn)練可以擴展到更大規(guī)模和更快的速度。
0xFF 參考
[細讀經(jīng)典]Megatron論文和代碼詳細分析(2)
[細讀經(jīng)典]Megatron論文和代碼詳細分析(1)
Megatron-LM源碼閱讀(一)
Megatron-LM源碼閱讀(二)
megatron學習總結(jié)
GTC 2020: Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
www.DeepL.com/Translator
https://developer.nvidia.com/gtc/2020/slides/s21496-megatron-lm-training-multi-billion-parameter-language-models-using-model-parallelism.pdf
NVIDIA Megatron:超大Transformer語言模型的分布式訓(xùn)練框架 (一)
NVIDIA Megatron:超大Transformer語言模型的分布式訓(xùn)練框架 (二)