
PyTorch 源碼解讀之分布式訓(xùn)練了解一下?

極市導(dǎo)讀
本文由淺入深講解 torch.distributed 這一并行計(jì)算包的概念,實(shí)現(xiàn)細(xì)節(jié)和應(yīng)用方式,并帶大家快速入門 PyTorch 分布式訓(xùn)練。 >>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
0 前言
由于大規(guī)模機(jī)器學(xué)習(xí)的廣泛普及,超大型深度學(xué)習(xí)模型的提出,聯(lián)邦學(xué)習(xí)等分布式學(xué)習(xí)方法的快速發(fā)展,分布式機(jī)器學(xué)習(xí)模型訓(xùn)練與部署技術(shù)已經(jīng)日益成為研究者和開發(fā)者的必備技術(shù)。PyTorch 作為應(yīng)用最為廣泛的深度學(xué)習(xí)框架,也發(fā)展出了一套分布式學(xué)習(xí)的解決方法。本文由淺入深講解 torch.distributed 這一并行計(jì)算包的概念,實(shí)現(xiàn)細(xì)節(jié)和應(yīng)用方式,并帶大家快速入門 PyTorch 分布式訓(xùn)練。
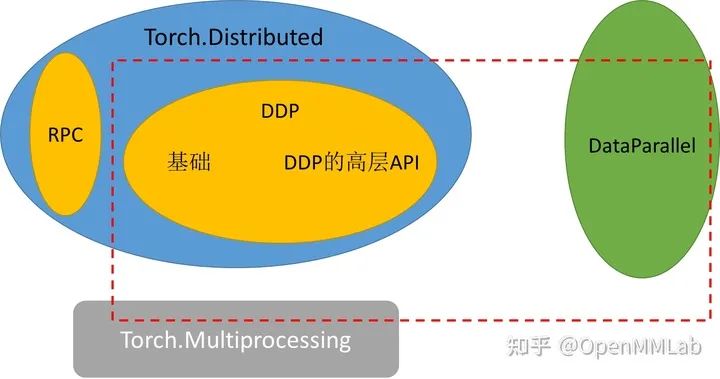
1 Torch.distributed 概念與定義
定義:首先我們提供 Torch.distributed 的官方定義
torch.distributed 包為運(yùn)行在一臺(tái)或多臺(tái)機(jī)器上的多個(gè)計(jì)算節(jié)點(diǎn)之間的 PyTorch 提供支持多進(jìn)程并行性通信的原語。他能輕松地并行化在跨進(jìn)程和機(jī)器集群的計(jì)算。 torch.nn.parallel.DistributedDataParalle(DDP) 是建立在此功能的基礎(chǔ)上,以提供同步的分布式訓(xùn)練作為任何 PyTorch 模型的包裝器。
可以注意到的是,torch.distributed 的核心功能是進(jìn)行多進(jìn)程級(jí)別的通信(而非多線程),以此達(dá)到多卡多機(jī)分布式訓(xùn)練的目的。這與基于 DataParrallel 的多線程訓(xùn)練有明顯區(qū)別。
通信方式:torch.distributed 的底層通信主要使用 Collective Communication (c10d) library 來支持跨組內(nèi)的進(jìn)程發(fā)送張量,并主要支持兩種類型的通信 API:
collective communication APIs: Distributed Data-Parallel Training (DDP) P2P communication APIs: RPC-Based Distributed Training (RPC)
這兩種通信 API 在 PyTorch 中分別對(duì)應(yīng)了兩種分布式訓(xùn)練方式:Distributed Data-Parallel Training (DDP) 和 RPC-Based Distributed Training (RPC)。本文著重探討 Distributed Data-Parallel Training (DDP) 的通信方式和 API
基礎(chǔ)概念: 下面介紹一些 torch.distributed 中的關(guān)鍵概念以供參考。這些概念在編寫程序時(shí)至關(guān)重要
Group(進(jìn)程組)是我們所有進(jìn)程的子集。 Backend(后端)進(jìn)程通信庫。PyTorch 支持 NCCL,GLOO,MPI。本文不展開講幾種通信后端的區(qū)別,感興趣的同學(xué)可以參考官方文檔 world_size(世界大小)在進(jìn)程組中的進(jìn)程數(shù)。 Rank(秩)分配給分布式進(jìn)程組中每個(gè)進(jìn)程的唯一標(biāo)識(shí)符。它們始終是從 0 到 world_size 的連續(xù)整數(shù)。
2 Torch.distributed 實(shí)例
例子 1:初始化
"""run.py:"""#!/usr/bin/env pythonimport osimport torchimport torch.distributed as distfrom torch.multiprocessing import Processdef run(rank, size):""" Distributed function to be implemented later. """passdef init_process(rank, size, fn, backend='gloo'):""" Initialize the distributed environment. """os.environ['MASTER_ADDR'] = '127.0.0.1'os.environ['MASTER_PORT'] = '29500'dist.init_process_group(backend, rank=rank, world_size=size)fn(rank, size)if __name__ == "__main__":size = 2processes = []for rank in range(size):p = Process(target=init_process, args=(rank, size, run))p.start()processes.append(p)for p in processes:p.join()
本段程序執(zhí)行了下面三件事
創(chuàng)建了兩個(gè)進(jìn)程 分別加入一個(gè)進(jìn)程組 分別運(yùn)行 run 函數(shù)。此時(shí) run 是一個(gè)空白函數(shù),之后的例子會(huì)擴(kuò)充這個(gè)函數(shù)的內(nèi)容并在函數(shù)內(nèi)完成多進(jìn)程的通信操作。
例子 2:點(diǎn)對(duì)點(diǎn)通信
最簡單的多進(jìn)程通信方式是點(diǎn)對(duì)點(diǎn)通信。信息從一個(gè)進(jìn)程被發(fā)送到另一個(gè)進(jìn)程。
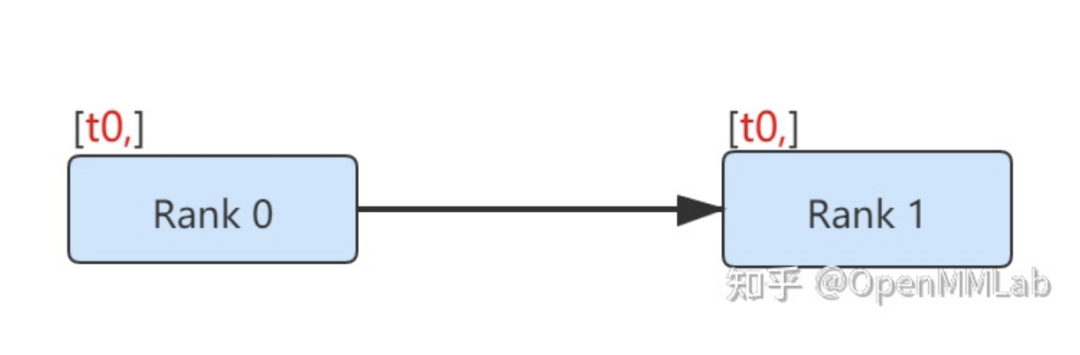
def run(rank, size):tensor = torch.zeros(1)if rank == 0:tensor += 1# Send the tensor to process 1dist.send(tensor=tensor, dst=1)else:# Receive tensor from process 0dist.recv(tensor=tensor, src=0)print('Rank ', rank, ' has data ', tensor[0])
在上面的示例中,兩個(gè)進(jìn)程都從 tensor(0) 開始,然后進(jìn)程 0 遞增張量并將其發(fā)送到進(jìn)程 1,以便它們都以 tensor(1) 結(jié)尾。請(qǐng)注意,進(jìn)程 1 需要分配內(nèi)存以存儲(chǔ)它將接收的數(shù)據(jù)。
另請(qǐng)注意,send / recv 被阻塞:兩個(gè)過程都停止,直到通信完成。我們還有另外一種無阻塞的通信方式,請(qǐng)看下例
"""Non-blocking point-to-point communication."""def run(rank, size):tensor = torch.zeros(1)req = Noneif rank == 0:tensor += 1# Send the tensor to process 1req = dist.isend(tensor=tensor, dst=1)print('Rank 0 started sending')else:# Receive tensor from process 0req = dist.irecv(tensor=tensor, src=0)print('Rank 1 started receiving')req.wait()print('Rank ', rank, ' has data ', tensor[0])
我們通過調(diào)用 wait 函數(shù)以使自己在子進(jìn)程執(zhí)行過程中保持休眠狀態(tài)。由于我們不知道何時(shí)將數(shù)據(jù)傳遞給其他進(jìn)程,因此在 req.wait() 完成之前,我們既不應(yīng)該修改發(fā)送的張量也不應(yīng)該訪問接收的張量以防止不確定的寫入。
例子 3:進(jìn)程組間通信
與點(diǎn)對(duì)點(diǎn)通信相反,集合允許跨組中所有進(jìn)程的通信模式。例如,為了獲得所有過程中所有張量的總和,我們可以使用 dist.all_reduce(tensor, op, group) 函數(shù)進(jìn)行組間通信
""" All-Reduce example."""def run(rank, size):""" Simple point-to-point communication. """group = dist.new_group([0, 1])tensor = torch.ones(1)dist.all_reduce(tensor, op=dist.reduce_op.SUM, group=group)print('Rank ', rank, ' has data ', tensor[0])
這段代碼首先將進(jìn)程 0 和 1 組成進(jìn)程組,然后將各自進(jìn)程中 tensor(1) 相加。由于我們需要組中所有張量的總和,因此我們將 dist.reduce_op.SUM 用作化簡運(yùn)算符。一般來說,任何可交換的數(shù)學(xué)運(yùn)算都可以用作運(yùn)算符。PyTorch 開箱即用,帶有 4 個(gè)這樣的運(yùn)算符,它們都在元素級(jí)運(yùn)行:
dist.reduce_op.SUM dist.reduce_op.PRODUCT dist.reduce_op.MAX dist.reduce_op.MIN
除了 dist.all_reduce(tensor, op, group) 之外,PyTorch 中目前共有 6 種組間通信方式
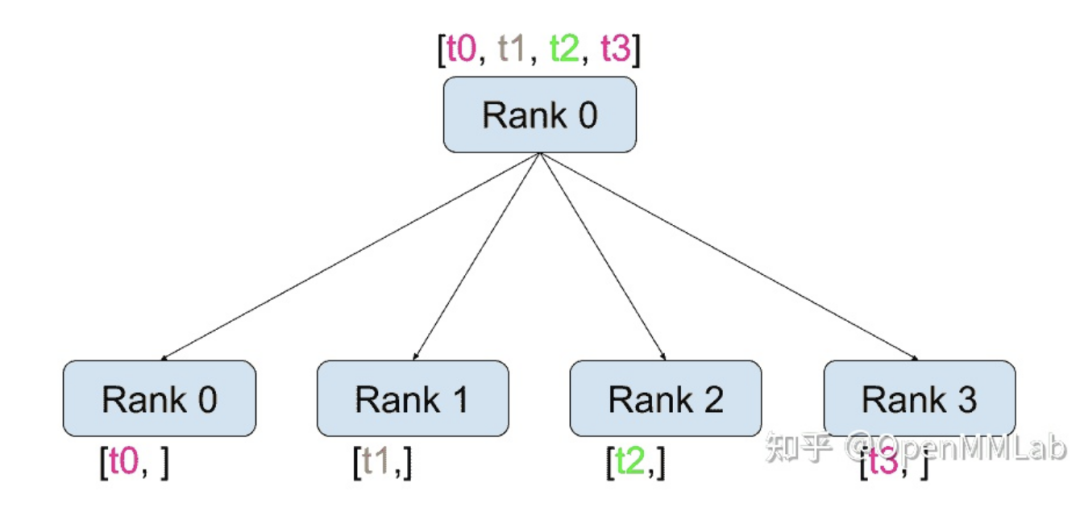
distributed.scatter(tensor, scatter_list=None, src=0, group=None, async_op=False):將張量 scatter_list[i] 復(fù)制第 i 個(gè)進(jìn)程的過程。例如,在實(shí)現(xiàn)分布式訓(xùn)練時(shí),我們將數(shù)據(jù)分成四份并分別發(fā)送到不同的機(jī)子上計(jì)算梯度。scatter 函數(shù)可以用來將信息從 src 進(jìn)程發(fā)送到其他進(jìn)程上。
| tensor | 發(fā)送的數(shù)據(jù) |
| scatter_list | 存儲(chǔ)發(fā)送數(shù)據(jù)的列表(只需在 src 進(jìn)程中指定) |
| dst | 發(fā)送進(jìn)程的rank |
| group | 指定進(jìn)程組 |
| async_op | 該 op 是否是異步操作 |
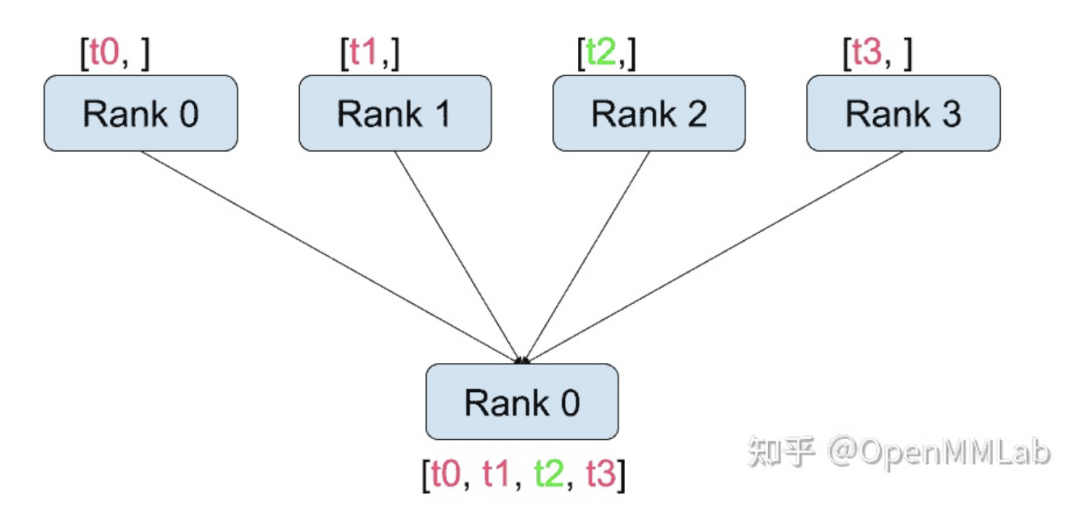
distributed.gather(tensor, gather_list=None, dst=0, group=None, async_op=False):從 dst 中的所有進(jìn)程復(fù)制 tensor。例如,在實(shí)現(xiàn)分布式訓(xùn)練時(shí),不同進(jìn)程計(jì)算得到的梯度需要匯總到一個(gè)進(jìn)程,并計(jì)算平均值以獲得統(tǒng)一的梯度。gather 函數(shù)可以將信息從別的進(jìn)程匯總到 dst 進(jìn)程。
| tensor | 接受的數(shù)據(jù) |
| gather_list | 存儲(chǔ)接受數(shù)據(jù)的列表(只需在dst進(jìn)程中指定) |
| dst | 匯總進(jìn)程的rank |
| group | 指定進(jìn)程組 |
| async_op | 該op是否是異步操作 |
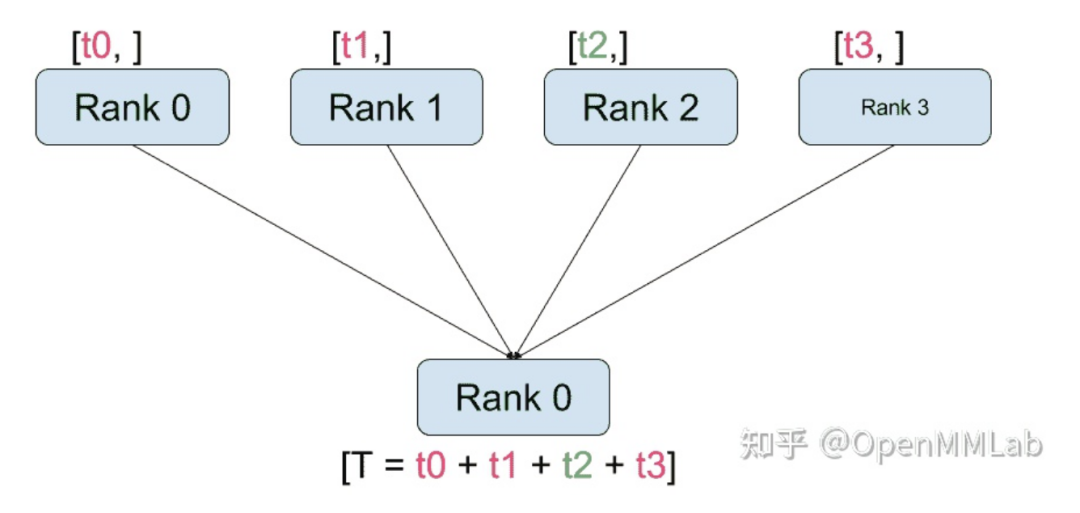
distributed.reduce(tensor, dst, op, group):將 op 應(yīng)用于所有 tensor,并將結(jié)果存儲(chǔ)在 dst 中。
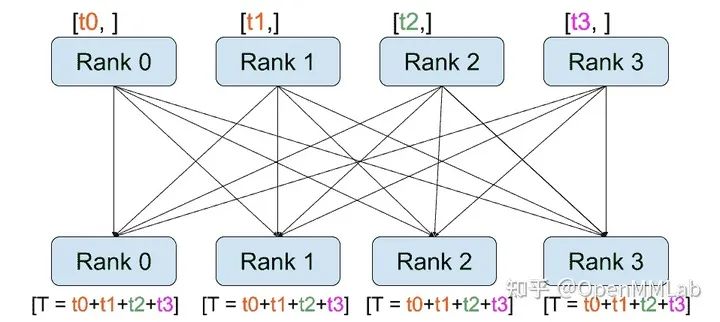
distributed.all_reduce(tensor, op, group):與 reduce 相同,但是結(jié)果存儲(chǔ)在所有進(jìn)程中。
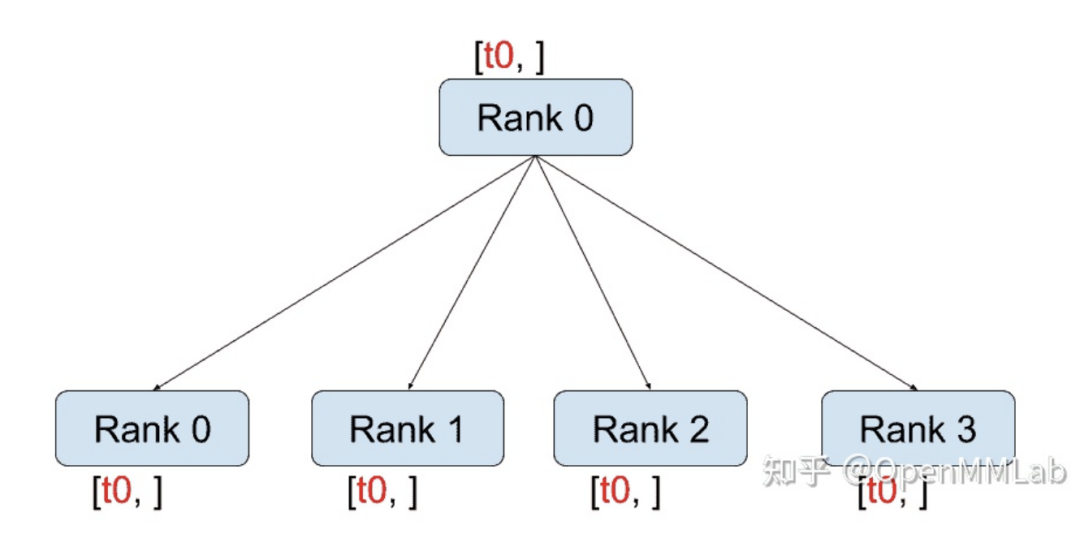
distributed.broadcast(tensor, src, group):將tensor從src復(fù)制到所有其他進(jìn)程。
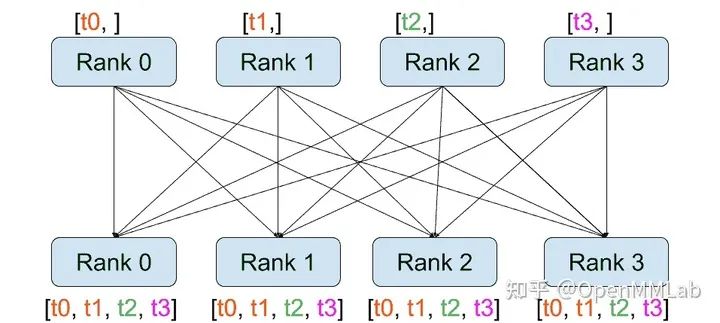
distributed.all_gather(tensor_list, tensor, group):將所有進(jìn)程中的 tensor 從所有進(jìn)程復(fù)制到 tensor_list
例子 4:分布式梯度下降
分布式梯度下降腳本將允許所有進(jìn)程在其數(shù)據(jù) batch 上計(jì)算其模型的梯度,然后平均其梯度。為了在更改進(jìn)程數(shù)時(shí)確保相似的收斂結(jié)果,我們首先必須對(duì)數(shù)據(jù)集進(jìn)行分區(qū)。
""" Dataset partitioning helper """class Partition(object):def __init__(self, data, index):self.data = dataself.index = indexdef __len__(self):return len(self.index)def __getitem__(self, index):data_idx = self.index[index]return self.data[data_idx]class DataPartitioner(object):def __init__(self, data, sizes=[0.7, 0.2, 0.1], seed=1234):self.data = dataself.partitions = []rng = Random()rng.seed(seed)data_len = len(data)indexes = [x for x in range(0, data_len)]rng.shuffle(indexes)for frac in sizes:part_len = int(frac * data_len)self.partitions.append(indexes[0:part_len])indexes = indexes[part_len:]def use(self, partition):return Partition(self.data, self.partitions[partition])
使用上面的代碼片段,我們現(xiàn)在可以使用以下幾行簡單地對(duì)任何數(shù)據(jù)集進(jìn)行分區(qū)
""" Partitioning MNIST """def partition_dataset():dataset = datasets.MNIST('./data', train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))]))size = dist.get_world_size()bsz = 128 / float(size)partition_sizes = [1.0 / size for _ in range(size)]partition = DataPartitioner(dataset, partition_sizes)partition = partition.use(dist.get_rank())train_set = torch.utils.data.DataLoader(partition,batch_size=bsz,shuffle=True)return train_set, bsz
假設(shè)我們有 2 個(gè)進(jìn)程,則每個(gè)進(jìn)程的 train_set 為 60000/2 = 30000 個(gè)樣本。我們還將 batch 大小除以進(jìn)程數(shù),以使整體 batch 大小保持為 128。
現(xiàn)在,我們可以編寫通常的向前-向后優(yōu)化訓(xùn)練代碼,并添加一個(gè)函數(shù)調(diào)用以平均模型的梯度。
""" Distributed Synchronous SGD Example """def run(rank, size):torch.manual_seed(1234)train_set, bsz = partition_dataset()model = Net()optimizer = optim.SGD(model.parameters(),lr=0.01, momentum=0.5)num_batches = ceil(len(train_set.dataset) / float(bsz))for epoch in range(10):epoch_loss = 0.0for data, target in train_set:optimizer.zero_grad()output = model(data)loss = F.nll_loss(output, target)epoch_loss += loss.item()loss.backward()average_gradients(model)optimizer.step()print('Rank ', dist.get_rank(), ', epoch ',epoch, ': ', epoch_loss / num_batches)
仍然需要執(zhí)行 average_gradients(model) 函數(shù),該函數(shù)只需要一個(gè)模型并計(jì)算在所有 rank 上梯度的平均值。
""" Gradient averaging. """def average_gradients(model):size = float(dist.get_world_size())for param in model.parameters():dist.all_reduce(param.grad.data, op=dist.reduce_op.SUM)param.grad.data /= size
3 PyTorch 并行/分布式訓(xùn)練
在掌握 torch.distributed 的基礎(chǔ)的前提下,我們可以根據(jù)自身機(jī)器和任務(wù)的具體情況使用不同的分布式或并行訓(xùn)練方式:
如果數(shù)據(jù)和模型可以放在一個(gè) GPU 中,并且不關(guān)心訓(xùn)練速度,請(qǐng)使用單設(shè)備訓(xùn)練。 如果單個(gè)服務(wù)器上有多個(gè) GPU,并且您希望更改較少的代碼來加快訓(xùn)練速度,請(qǐng)使用單機(jī)多 GPU DataParallel。 如果單個(gè)服務(wù)器上有多個(gè) GPU,且您希望進(jìn)一步添加代碼并加快訓(xùn)練速度,請(qǐng)使用單機(jī)多 GPU DistributedDataParallel。 如果應(yīng)用程序需要跨多個(gè)服務(wù)器,請(qǐng)使用多機(jī) DistributedDataParallel 和啟動(dòng)腳本。 如果預(yù)計(jì)會(huì)出現(xiàn)錯(cuò)誤(例如,OOM),或者在訓(xùn)練期間資源可以動(dòng)態(tài)加入和離開,請(qǐng)使用 torch.elastic 進(jìn)行分布式訓(xùn)練。
3.1 DataParallel
class torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)DataParallel 自動(dòng)分割您的數(shù)據(jù),并將作業(yè)訂單發(fā)送到多個(gè) GPU 上的多個(gè)模型。每個(gè)模型完成工作后,DataParallel 會(huì)收集并合并結(jié)果,然后再將結(jié)果返回給您。DataParallel 將相同的模型復(fù)制到所有 GPU,其中每個(gè) GPU 消耗輸入數(shù)據(jù)的不同分區(qū)。在使用此方法時(shí),batch 理大小應(yīng)大于使用的 GPU 數(shù)量。我們需要注意的是,DataParallel 是通過多線程的方式進(jìn)行的并行訓(xùn)練,所以并沒有使用 torch.distributed 里的線程通信 API。的其運(yùn)行過程如下圖所示
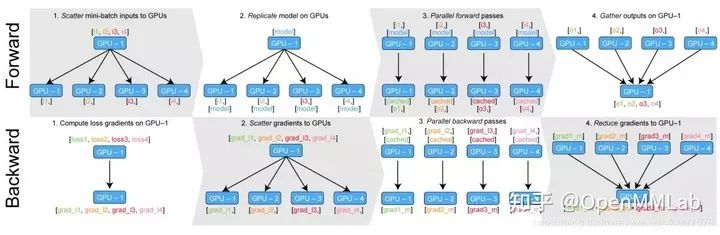
例子 5 DataParallel
創(chuàng)建 dump 數(shù)據(jù)集和定義模型
class RandomDataset(Dataset):def __init__(self, size, length):self.len = lengthself.data = torch.randn(length, size)def __getitem__(self, index):return self.data[index]def __len__(self):return self.lenrand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),batch_size=batch_size, shuffle=True)class Model(nn.Module):# Our modeldef __init__(self, input_size, output_size):super(Model, self).__init__()self.fc = nn.Linear(input_size, output_size)def forward(self, input):output = self.fc(input)print("\tIn Model: input size", input.size(),"output size", output.size())return output
定義模型,放入設(shè)備并用 DataParallel 對(duì)象進(jìn)行包裝
model = Model(input_size, output_size)if torch.cuda.device_count() > 1:print("Let's use", torch.cuda.device_count(), "GPUs!")# dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUsmodel = nn.DataParallel(model)model.to(device)
運(yùn)行模型并輸出
for data in rand_loader:input = data.to(device)output = model(input): input size", input.size(),output.size())In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2])Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2])In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2])Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
我們可以看到,在模型中,數(shù)據(jù)是按照batch大小的維度被均勻分成多份。在輸出后,多塊 GPU 上的數(shù)據(jù)進(jìn)行合并。
3.2 DistributedDataParallel
當(dāng)我們了解了 DataParallel 后,下面開始介紹一種基于 torch.distributed 中進(jìn)程通信函數(shù)包裝的高層 API
CLASS torch.nn.parallel.DistributedDataParallel(module, device_ids=None, output_device=None, dim=0, broadcast_buffers=True, process_group=None, bucket_cap_mb=**25**, find_unused_parameters=False, check_reduction=False, gradient_as_bucket_view=False)既然 DataParallel 可以進(jìn)行并行的模型訓(xùn)練,那么為什么還需要提出 DistributedDataParallel呢?這里我們就需要知道兩種方法的實(shí)現(xiàn)原理與區(qū)別:
如果模型太大而無法容納在單個(gè) GPU 上,則必須使用模型并行將其拆分到多個(gè) GPU 中。DistributedDataParallel 可以與模型并行一起使用;但 DataParallel 因?yàn)楸仨殞⒛P头湃雴螇K GPU 中,所以難以完成大型模型的訓(xùn)練。 DataParallel 是單進(jìn)程,多線程的并行訓(xùn)練方式,并且只能在單臺(tái)機(jī)器上運(yùn)行,而DistributedDataParallel 是多進(jìn)程,并且適用于單機(jī)和多機(jī)訓(xùn)練。DistributedDataParallel 還預(yù)先復(fù)制模型,而不是在每次迭代時(shí)復(fù)制模型,并避免了全局解釋器鎖定。 如果您的兩個(gè)數(shù)據(jù)都太大而無法容納在一臺(tái)計(jì)算機(jī)和上,而您的模型又太大了以至于無法安裝在單個(gè) GPU 上,則可以將模型并行(跨多個(gè) GPU 拆分單個(gè)模型)與 DistributedDataParallel 結(jié)合使用。在這種情況下,每個(gè) DistributedDataParallel 進(jìn)程都可以并行使用模型,而所有進(jìn)程都將并行使用數(shù)據(jù)。
例子 6 DistributedDataParallel
首先我們需要?jiǎng)?chuàng)建一系列進(jìn)程,其中需要用到 torch.multiprocessing 中的函數(shù)
torch.multiprocessing.spawn(fn, args=(), nprocs=1, join=True, daemon=False, start_method='spawn')該函數(shù)使用 args 作為參數(shù)列表運(yùn)行函數(shù)fn,并創(chuàng)建 nprocs 個(gè)進(jìn)程。
如果其中一個(gè)進(jìn)程以非零退出狀態(tài)退出,則其余進(jìn)程將被殺死,并引發(fā)異常,以終止原因。如果子進(jìn)程中捕獲到異常,則將其轉(zhuǎn)發(fā)并將其回溯包括在父進(jìn)程中引發(fā)的異常中。
該函數(shù)會(huì)通過 fn(i,args) 的形式被調(diào)用,其中i是進(jìn)程索引,而 args 是傳遞的參數(shù)元組。
基于創(chuàng)建的的進(jìn)程,我們初始化進(jìn)程組
import osimport tempfileimport torchimport torch.distributed as distimport torch.nn as nnimport torch.optim as optimimport torch.multiprocessing as mpfrom torch.nn.parallel import DistributedDataParallel as DDPdef setup(rank, world_size):os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '12355'# initialize the process groupdist.init_process_group("gloo", rank=rank, world_size=world_size)# Explicitly setting seed to make sure that models created in two processes# start from same random weights and biases.torch.manual_seed(42)def cleanup():dist.destroy_process_group()
這里我們使用到了
torch.distributed.init_process_group(backend, init_method=None, timeout=datetime.timedelta(0, 1800), world_size=-1, rank=-1, store=None, group_name='')這個(gè) API 來初始化默認(rèn)的分布式進(jìn)程組,這還將初始化分布式程序包。
該函數(shù)有兩種主要的調(diào)用方式:
明確指定 store,rank 和 world_size。 指定 init_method(URL 字符串),它指示在何處/如何發(fā)現(xiàn)對(duì)等方。(可選)指定 rank 和 world_size,或在 URL 中編碼所有必需的參數(shù)并忽略它們。
現(xiàn)在,讓我們創(chuàng)建一個(gè) toy model,將其與 DDP 封裝在一起,并提供一些虛擬輸入數(shù)據(jù)。請(qǐng)注意,由于 DDP 將 0 級(jí)進(jìn)程中的模型狀態(tài)廣播到 DDP 構(gòu)造函數(shù)中的所有其他進(jìn)程,因此無需擔(dān)心不同的 DDP 進(jìn)程從不同的模型參數(shù)初始值開始。
class ToyModel(nn.Module):def __init__(self):super(ToyModel, self).__init__()self.net1 = nn.Linear(10, 10)self.relu = nn.ReLU()self.net2 = nn.Linear(10, 5)def forward(self, x):return self.net2(self.relu(self.net1(x)))def demo_basic(rank, world_size):setup(rank, world_size)# Assume we have 8 GPU in total# setup devices for this process, rank 1 uses GPUs [0, 1, 2, 3] and# rank 2 uses GPUs [4, 5, 6, 7].n = torch.cuda.device_count() // world_sizedevice_ids = list(range(rank * n, (rank + 1) * n))# create model and move it to device_ids[0]model = ToyModel().to(device_ids[0])# output_device defaults to device_ids[0]ddp_model = DDP(model, device_ids=device_ids)loss_fn = nn.MSELoss()optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)optimizer.zero_grad()outputs = ddp_model(torch.randn(20, 10))labels = torch.randn(20, 5).to(device_ids[0])loss_fn(outputs, labels).backward()optimizer.step()cleanup()def run_demo(demo_fn, world_size):mp.spawn(demo_fn,args=(world_size,),nprocs=world_size,join=True)if __name__ == "__main__":run_demo(demo_basic, 2)
例子 7 將 DDP 與模型并行性結(jié)合
DDP 還可以與多 GPU 模型一起使用,但是不支持進(jìn)程內(nèi)的復(fù)制。您需要為每個(gè)模型副本創(chuàng)建一個(gè)進(jìn)程,與每個(gè)進(jìn)程的多個(gè)模型副本相比,通常可以提高性能。當(dāng)訓(xùn)練具有大量數(shù)據(jù)的大型模型時(shí),DDP 包裝多 GPU 模型特別有用。使用此功能時(shí),需要小心地實(shí)現(xiàn)多 GPU 模型,以避免使用硬編碼的設(shè)備,因?yàn)闀?huì)將不同的模型副本放置到不同的設(shè)備上。
例如,下面這個(gè)模型顯式的將不同的模塊放置在不同的 GPU 上
class ToyMpModel(nn.Module):def __init__(self, dev0, dev1):super(ToyMpModel, self).__init__()self.dev0 = dev0self.dev1 = dev1self.net1 = torch.nn.Linear(10, 10).to(dev0)self.relu = torch.nn.ReLU()self.net2 = torch.nn.Linear(10, 5).to(dev1)def forward(self, x):x = x.to(self.dev0)x = self.relu(self.net1(x))x = x.to(self.dev1)return self.net2(x)
將多 GPU 模型傳遞給 DDP 時(shí),不得設(shè)置 device_ids 和 output_device。輸入和輸出數(shù)據(jù)將通過應(yīng)用程序或模型 forward() 方法放置在適當(dāng)?shù)脑O(shè)備中。
def demo_model_parallel(rank, world_size):world_size)# setup mp_model and devices for this processdev0 = rank * 2dev1 = rank * 2 + 1mp_model = ToyMpModel(dev0, dev1)ddp_mp_model = DDP(mp_model)loss_fn = nn.MSELoss()optimizer = optim.SGD(ddp_mp_model.parameters(), lr=0.001)optimizer.zero_grad()# outputs will be on dev1outputs = ddp_mp_model(torch.randn(20, 10))labels = torch.randn(20, 5).to(dev1)labels).backward()optimizer.step()cleanup()if __name__ == "__main__":4)
例子 8 保存和加載檢查點(diǎn)
使用 DDP 時(shí),一種優(yōu)化方法是僅在一個(gè)進(jìn)程中保存模型,然后將其加載到所有進(jìn)程中,從而減少寫開銷。
def demo_checkpoint(rank, world_size):world_size)# setup devices for this process, rank 1 uses GPUs [0, 1, 2, 3] and# rank 2 uses GPUs [4, 5, 6, 7].n = torch.cuda.device_count() // world_sizedevice_ids = list(range(rank * n, (rank + 1) * n))model = ToyModel().to(device_ids[0])# output_device defaults to device_ids[0]ddp_model = DDP(model, device_ids=device_ids)loss_fn = nn.MSELoss()optimizer = optim.SGD(ddp_model.parameters(), lr=0.001)CHECKPOINT_PATH = tempfile.gettempdir() + "/model.checkpoint"if rank == 0:# All processes should see same parameters as they all start from same# random parameters and gradients are synchronized in backward passes.# Therefore, saving it in one process is sufficient.CHECKPOINT_PATH)# Use a barrier() to make sure that process 1 loads the model after process# 0 saves it.dist.barrier()# configure map_location properlyrank0_devices = [x - rank * len(device_ids) for x in device_ids]device_pairs = zip(rank0_devices, device_ids)map_location = {'cuda:%d' % x: 'cuda:%d' % y for x, y in device_pairs}ddp_model.load_state_dict(map_location=map_location))optimizer.zero_grad()outputs = ddp_model(torch.randn(20, 10))labels = torch.randn(20, 5).to(device_ids[0])loss_fn = nn.MSELoss()labels).backward()optimizer.step()# Use a barrier() to make sure that all processes have finished reading the# checkpointdist.barrier()if rank == 0:os.remove(CHECKPOINT_PATH)cleanup()
4 總結(jié)
本文講解了 torch.distributed 這一并行計(jì)算包的概念,實(shí)現(xiàn)細(xì)節(jié)和應(yīng)用方式,并帶大家快速入門 PyTorch 分布式訓(xùn)練。我們著重分析了 DataParallel 和 DistributedDataParallel 兩種并行訓(xùn)練 API 的使用方法和原理異同
參考資料
https://pytorch.org/docs/stable/distributed.html
https://pytorch.apachecn.org/docs/1.7/59.html
如果覺得有用,就請(qǐng)分享到朋友圈吧!
公眾號(hào)后臺(tái)回復(fù)“長尾”獲取長尾特征學(xué)習(xí)資源~

# CV技術(shù)社群邀請(qǐng)函 #
備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測(cè)-深圳)
即可申請(qǐng)加入極市目標(biāo)檢測(cè)/圖像分割/工業(yè)檢測(cè)/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對(duì)接、求職內(nèi)推、算法競(jìng)賽、干貨資訊匯總、與 10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動(dòng)交流~
