
還重構(gòu)?就你那代碼只能鏟了重寫!
點擊關(guān)注公眾號,Java干貨及時送達
一、前言
我們不一樣,就你沒對象!對,你是面向過程編程的!
我說的,絕大多數(shù)碼農(nóng)沒日沒夜被需求憋著肝出來的代碼,無論有多么的吭哧癟肚,都不可能有重構(gòu),只有重新寫。為什么?因為重新寫所花的時間成本,遠比重構(gòu)一份已經(jīng)爛成團的代碼,要節(jié)省時間。但誰又不敢保證重寫完的代碼,就比之前能好多少,況且還要承擔(dān)著重寫后的代碼事故風(fēng)險和幾乎體現(xiàn)不出來的業(yè)務(wù)價值!
雖然代碼是給機器運行的,但同樣也是給人看的,并且隨著每次需求的迭代、變更、升級,都需要研發(fā)人員對同一份代碼進行多次開發(fā)和上線,那么這里就會涉及到可維護、易擴展、好交接的特點。
而那些不合理分層實現(xiàn)代碼邏輯、不寫代碼注釋、不按規(guī)范提交、不做格式化、命名隨意甚至把 queryBatch 寫成 queryBitch 的,都會造成后續(xù)代碼沒法重構(gòu)的問題。那么接下來我們就分別介紹下,開發(fā)好能重構(gòu)的代碼,都要怎么干!
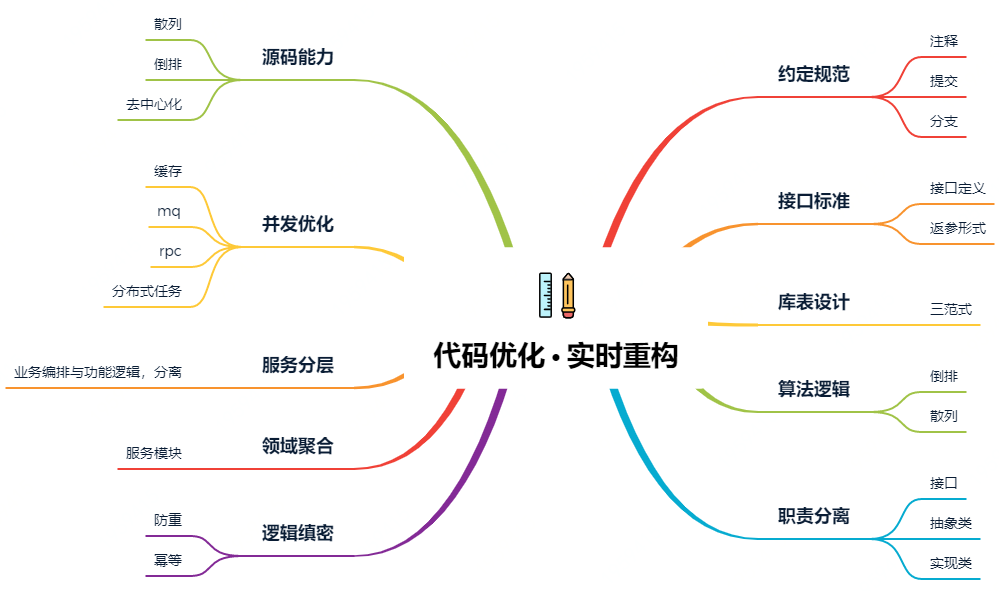
二、代碼優(yōu)化
1. 約定規(guī)范
# 提交:主要 type
feat: 增加新功能
fix: 修復(fù)bug
# 提交:特殊 type
docs: 只改動了文檔相關(guān)的內(nèi)容
style: 不影響代碼含義的改動,例如去掉空格、改變縮進、增刪分號
build: 構(gòu)造工具的或者外部依賴的改動,例如webpack,npm
refactor: 代碼重構(gòu)時使用
revert: 執(zhí)行g(shù)it revert打印的message
# 提交:暫不使用type
test: 添加測試或者修改現(xiàn)有測試
perf: 提高性能的改動
ci: 與CI(持續(xù)集成服務(wù))有關(guān)的改動
chore: 不修改src或者test的其余修改,例如構(gòu)建過程或輔助工具的變動
# 注釋:類注釋配置
/**
* @description:
* @author: ${USER}
* @date: ${DATE}
*/
分支:開發(fā)前提前約定好拉分支的規(guī)范,比如 日期_用戶_用途,210905_xfg_updateRuleLogic提交: 作者,type: desc如:小傅哥,fix:更新規(guī)則邏輯問題參考Commit message 規(guī)范注釋:包括類注釋、方法注釋、屬性注釋,在 IDEA 中可以設(shè)置類注釋的頭信息 Editor -> File and Code Templates -> File Header推薦下載安裝 IDEA P3C 插件Alibaba Java Coding Guidelines,統(tǒng)一標(biāo)準(zhǔn)化編碼方式。
2. 接口標(biāo)準(zhǔn)
在編寫 RPC 接口的時候,返回的結(jié)果中一定要包含明確的Code碼和Info描述,否則使用方很難知道這個接口是否調(diào)用成功還是異常,以及是什么情況的異常。
定義 Result
public class Result implements java.io.Serializable {
private static final long serialVersionUID = 752386055478765987L;
/** 返回結(jié)果碼 */
private String code;
/** 返回結(jié)果信息 */
private String info;
public Result() {
}
public Result(String code, String info) {
this.code = code;
this.info = info;
}
public static Result buildSuccessResult() {
Result result = new Result();
result.setCode(Constants.ResponseCode.SUCCESS.getCode());
result.setInfo(Constants.ResponseCode.SUCCESS.getInfo());
return result;
}
// ...get/set
}
返回結(jié)果包裝:繼承
public class RuleResult extends Result {
private String ruleId;
private String ruleDesc;
public RuleResult(String code, String info) {
super(code, info);
}
// ...get/set
}
// 使用
public RuleResult execRule(DecisionMatter request) {
return new RuleResult(Constants.ResponseCode.SUCCESS.getCode(), Constants.ResponseCode.SUCCESS.getInfo());
}
返回結(jié)果包裝:泛型
public class ResultData<T> implements Serializable {
private Result result;
private T data;
public ResultData(Result result, T data) {
this.result = result;
this.data = data;
}
// ...get/set
}
// 使用
public ResultData<Rule> execRule(DecisionMatter request) {
return new ResultData<Rule>(Result.buildSuccessResult(), new Rule());
}
兩種接口返回結(jié)果的包裝定義,都可以規(guī)范返回結(jié)果。在這樣的方式包裝后,使用方就可以用統(tǒng)一的方式來判斷 Code碼并做出相應(yīng)的處理。
3. 庫表設(shè)計
三范式:是數(shù)據(jù)庫的規(guī)范化的內(nèi)容,所謂的數(shù)據(jù)庫三范式通俗的講就是設(shè)計數(shù)據(jù)庫表所應(yīng)該遵守的一套規(guī)范,如果不遵守就會造成設(shè)計的數(shù)據(jù)庫不規(guī)范,出現(xiàn)數(shù)據(jù)庫字段冗余,數(shù)據(jù)的查詢,插入等操作等問題。
數(shù)據(jù)庫不僅僅只有三范式(1NF/2NF/3NF),還有BCNF、4NF、5NF…,不過在實際的數(shù)據(jù)庫設(shè)計時,遵守前三個范式就足夠了。再向下就會造成設(shè)計的數(shù)據(jù)庫產(chǎn)生過多不必要的約束。
0NF

第零范式是指沒有使用任何范式,數(shù)據(jù)存放冗余大量表字段,而且這樣的表結(jié)構(gòu)非常難以維護。
1NF

第一范式是在第零范式冗余字段上的改進,把重復(fù)字段抽離出來,設(shè)計成一個冗余數(shù)據(jù)較少便于存儲和讀取的表結(jié)構(gòu)。 同時在第一范式中也指出,表中的所有字段都應(yīng)該是原子的、不可再分割的,例如:你不能把公司雇員表的部門名稱和職責(zé)存放到一個字段。需要確保每列保持原子性
2NF

滿足1NF后,要求表中的列,都必須依賴主鍵,確保每個列都和主鍵列之間聯(lián)系,而不能間接聯(lián)系,也就是一個表只能描述一件事情。需要確保表中的每列都和主鍵相關(guān)。
3NF
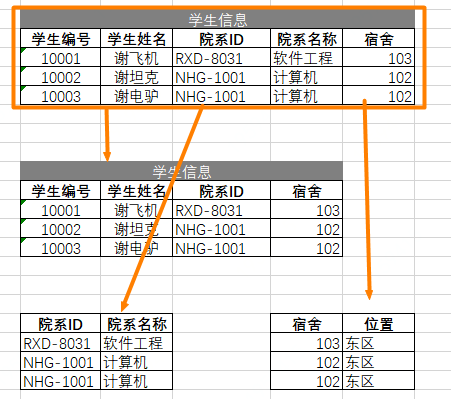
不能存在依賴關(guān)系,學(xué)號、姓名,到院系,院系到宿舍,需要確保每列都和主鍵列直接相關(guān),而不是間接相關(guān)。
反三范式
三大范式是設(shè)計數(shù)據(jù)庫表結(jié)構(gòu)的規(guī)則約束,但是在實際開發(fā)中允許局部變通:
有時候為了便于查詢,會在如訂單表冗余上當(dāng)時用戶的快照信息,比如用戶下單時候的一些設(shè)置信息。 單列列表數(shù)據(jù)匯總到總表中一個數(shù)量值,便于查詢的時候可以避免列表匯總操作。 可以在設(shè)計表的時候冗余一些字段,避免因業(yè)務(wù)發(fā)展情況多變,考慮不周導(dǎo)致該表繁瑣的問題。
4. 算法邏輯
通常在我們實際的業(yè)務(wù)功能邏輯開發(fā)中,為了能滿足一些高并發(fā)的場景,是不可能對數(shù)據(jù)庫表上鎖扣減庫存、也不能直接for循環(huán)大量輪訓(xùn)操作的,通常需要考慮??在這樣場景怎么去中心化以及降低時間復(fù)雜度。
秒殺:去中心化
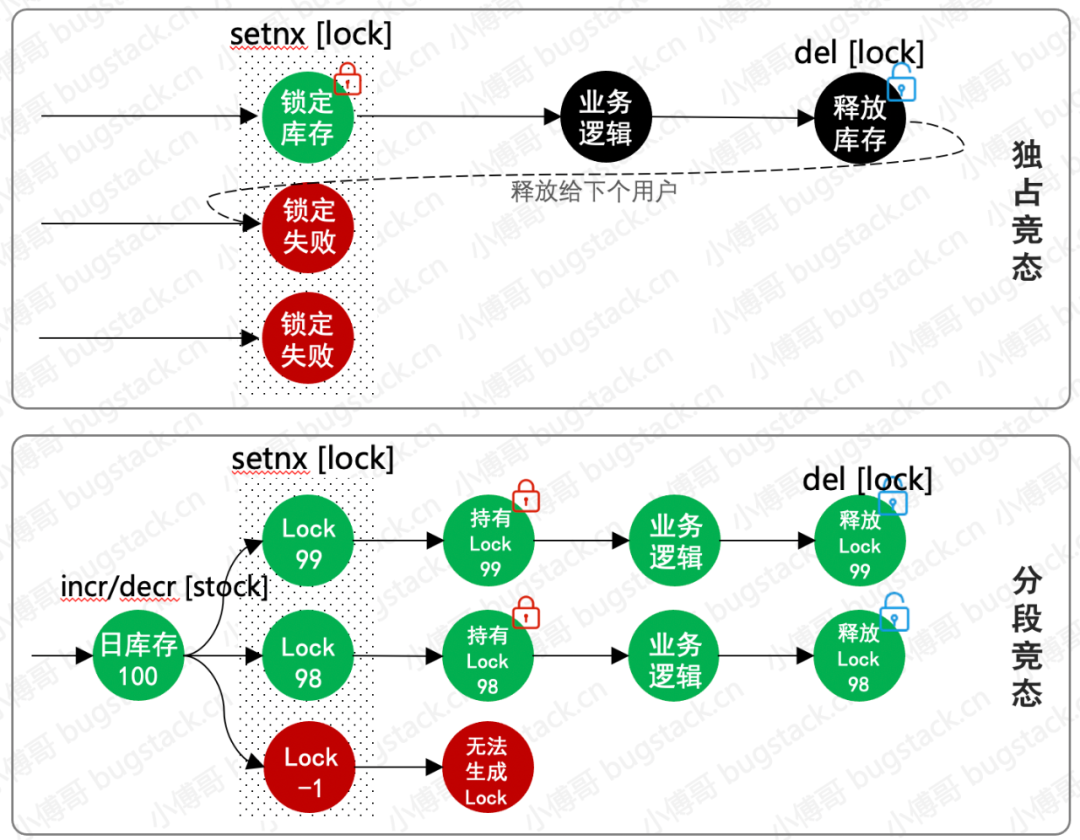
背景:這個一個商品活動秒殺的實現(xiàn)方案,最開始的設(shè)計是基于一個活動號ID進行鎖定,秒殺時鎖定這個ID,用戶購買完后就進行釋放。但在大量用戶搶購時,出現(xiàn)了秒殺分布式 獨占鎖后的業(yè)務(wù)邏輯處理中發(fā)生異常,釋放鎖失敗。導(dǎo)致所有的用戶都不能再拿到鎖,也就造成了有商品但不能下單的問題。優(yōu)化:優(yōu)化獨占競態(tài)為分段靜態(tài),將活動ID+庫存編號作為動態(tài)鎖標(biāo)識。當(dāng)前秒殺的用戶如果發(fā)生鎖失敗那么后面的用戶可以繼續(xù)秒殺不受影響。而失敗的鎖會有worker進行補償恢復(fù),那么最終會避免超賣以及不能售賣。
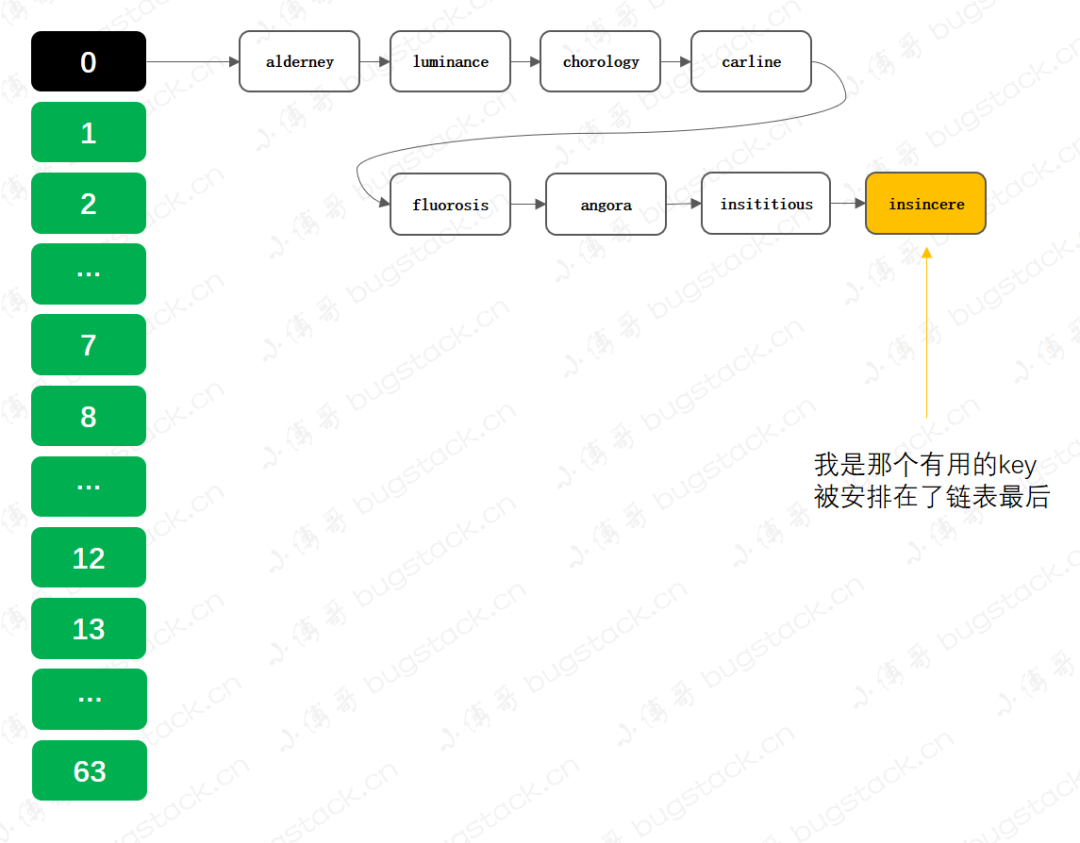
算法:反面教材
@Test
public void test_idx_hashMap() {
Map<String, String> map = new HashMap<>(64);
map.put("alderney", "未實現(xiàn)服務(wù)");
map.put("luminance", "未實現(xiàn)服務(wù)");
map.put("chorology", "未實現(xiàn)服務(wù)");
map.put("carline", "未實現(xiàn)服務(wù)");
map.put("fluorosis", "未實現(xiàn)服務(wù)");
map.put("angora", "未實現(xiàn)服務(wù)");
map.put("insititious", "未實現(xiàn)服務(wù)");
map.put("insincere", "已實現(xiàn)服務(wù)");
long startTime = System.currentTimeMillis();
for (int i = 0; i < 100000000; i++) {
map.get("insincere");
}
System.out.println("耗時(initialCapacity):" + (System.currentTimeMillis() - startTime));
}
背景:HashMap 數(shù)據(jù)獲取時間復(fù)雜度在 O(1) -> O(logn) -> O(n),但經(jīng)過特殊操作,可以把這個時間復(fù)雜度,拉到O(n) 操作:這是一個定義 HashMap存放業(yè)務(wù)實現(xiàn)key,通過key調(diào)用服務(wù)的功能。但這里的key,只有insincere有用,其他的都是未實現(xiàn)服務(wù)。那你看到有啥問題了嗎?這點代碼乍一看沒什么問題,看明白了就是代碼里下砒霜!它的目的就一個,要讓所有的key成一個鏈表放到HashMap中,而且把有用的key放到鏈表的最后,增加get時的耗時! 首先, new HashMap<>(64);為啥默認(rèn)初始化64個長度?因為默認(rèn)長度是8,插入元素時,當(dāng)鏈表長度為8時候會進行擴容和鏈表樹化判斷,此時就會把原有的key散列了,不能讓所有key構(gòu)成一個時間復(fù)雜度較高的鏈表。其次,所有的 key都是刻意選出來的,因為他們在HashMap計算下標(biāo)時,下標(biāo)值都為0,idx =(size - 1) & (key.hashCode() ^ (key.hashCode() >>> 16)),這樣就能讓所有key都散列到同一個位置進行碰撞。而且單詞insincere的意思是;不誠懇的、不真誠的!最后,前7個key其實都是廢 key,不起任何作用,只有最后一個 key 有服務(wù)。那么這樣就可以在HashMap中建出來很多這樣耗時的碰撞鏈表,當(dāng)然要滿足0.75的負(fù)載因子,不要讓HashMap擴容。
其實很多算法包括:散列、倒排、負(fù)載等,都是可以用到很多實際的業(yè)務(wù)場景中的,包括:人群過濾、抽獎邏輯、數(shù)據(jù)路由等等方面,這些功能的使用可以降低時間復(fù)雜度,提升系統(tǒng)的性能,降低接口響應(yīng)時常。
5. 職責(zé)分離
為了可以讓程序的邏輯實現(xiàn)更具有擴展性,通常我們都需要使用設(shè)計模式來處理各個場景的代碼實現(xiàn)結(jié)構(gòu)。而設(shè)計模式的使用在代碼開發(fā)中的體現(xiàn)也主要為接口的定義、抽象類的包裝和繼承類的實現(xiàn)。通過這樣的方式來隔離各個功能領(lǐng)域的開發(fā),以此保障每次需求擴展時可以更加靈活的添加,而不至于讓代碼因需求迭代而變得更加混亂。
案例
public interface IRuleExec {
void doRuleExec(String req);
}
public class RuleConfig {
protected Map<String, String> configGroup = new ConcurrentHashMap<>();
static {
// ...
}
}
public class RuleDataSupport extends RuleConfig{
protected String queryRuleConfig(String ruleId){
return "xxx";
}
}
public abstract class AbstractRuleBase extends RuleDataSupport implements IRuleExec{
@Override
public void doRuleExec(String req) {
// 1. 查詢配置
String ruleConfig = super.queryRuleConfig("10001");
// 2. 校驗信息
checkRuleConfig(ruleConfig);
// 3. 執(zhí)行規(guī)則{含業(yè)務(wù)邏輯,交給業(yè)務(wù)自己處理}
this.doLogic(configGroup.get(ruleConfig));
}
/**
* 執(zhí)行規(guī)則{含業(yè)務(wù)邏輯,交給業(yè)務(wù)自己處理}
*/
protected abstract void doLogic(String req);
private void checkRuleConfig(String ruleConfig) {
// ... 校驗配置
}
}
public class RuleExec extends AbstractRuleBase {
@Override
protected void doLogic(String req) {
// 封裝自身業(yè)務(wù)邏輯
}
}
類圖
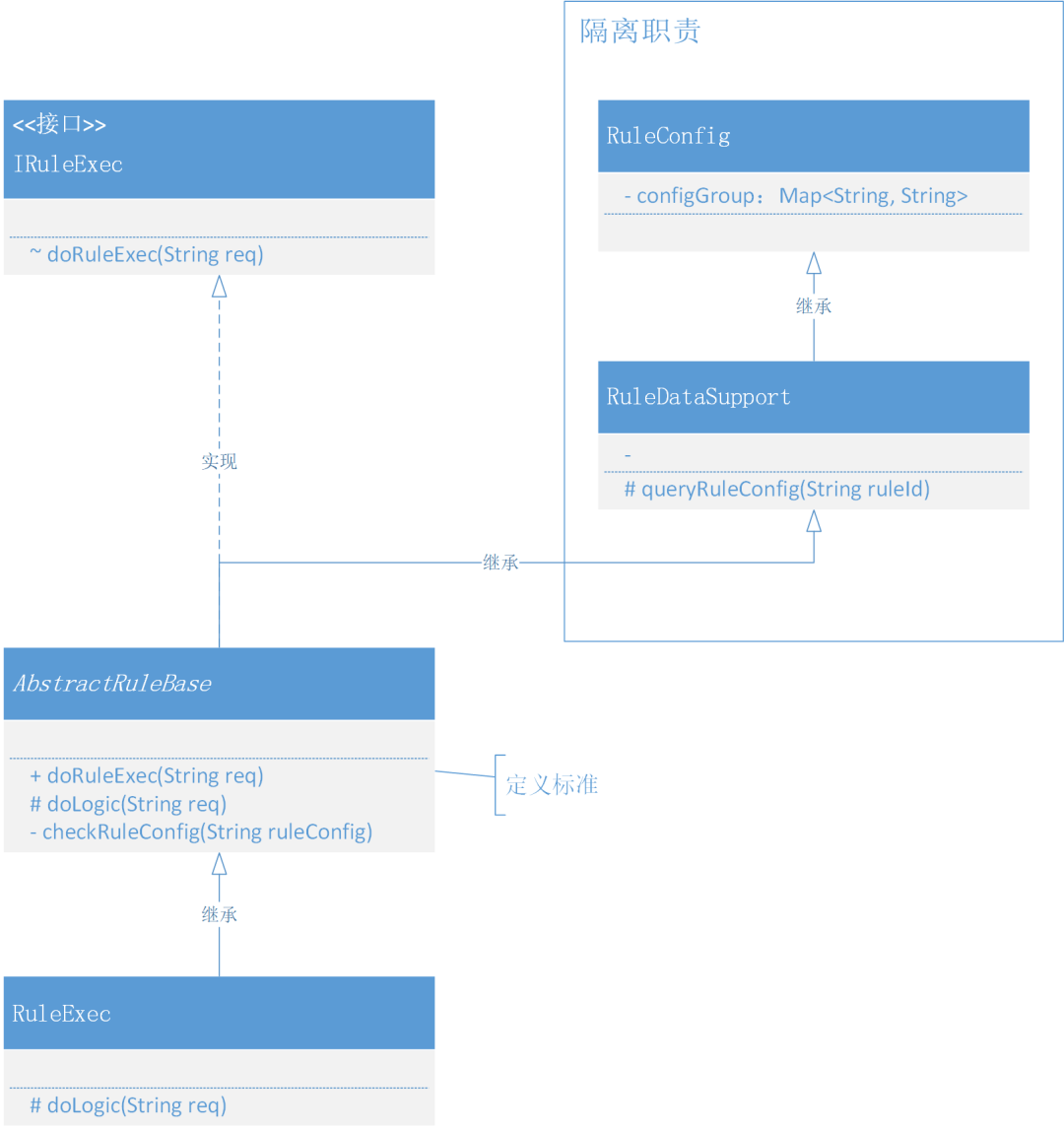
這是一種模版模式結(jié)構(gòu)的定義,使用到了接口實現(xiàn)、抽象類繼承,同時可以看到在 AbstractRuleBase抽象類中,是負(fù)責(zé)完成整個邏輯調(diào)用的定義,并且這個抽象類把一些通用的配置和數(shù)據(jù)使用單獨隔離出去,而公用的簡單方法放到自身實現(xiàn),最后是關(guān)于抽象方法的定義和調(diào)用,而業(yè)務(wù)類RuleExec就可以按需實現(xiàn)自己的邏輯功能了。
6. 邏輯縝密
你的代碼出過線上事故嗎?為什么出的事故,是樹上有十只鳥開一槍還剩幾只的問題嗎?比如:槍是無聲的嗎、鳥聾嗎、有懷孕的嗎、有綁在樹上的鳥嗎、邊上的樹還有鳥嗎、鳥害怕槍聲嗎、有殘疾的鳥嗎、打鳥的人眼睛花不花,... ...
實際上你的線上事故基本回圍繞在:數(shù)據(jù)庫連接和慢查詢、服務(wù)器負(fù)載和宕機、異常邏輯兜底、接口冪等性、數(shù)據(jù)防重性、MQ消費速度、RPC響應(yīng)時常、工具類使用錯誤等等。
下面舉個例子:用戶積分多支付,造成批量客訴。
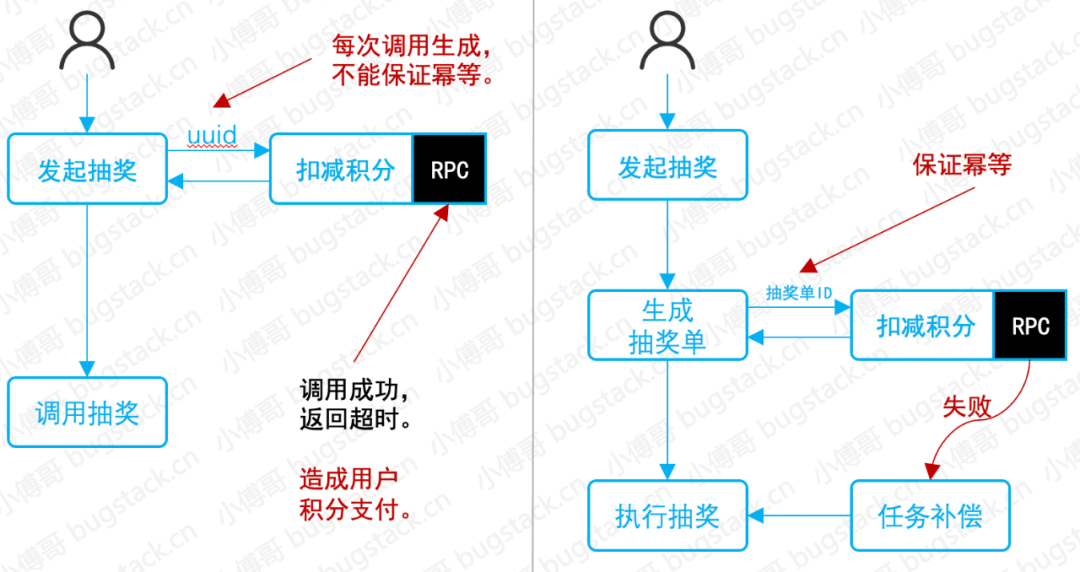
背景:這個產(chǎn)品功能的背景可能很大一部分研發(fā)都參與開發(fā)過,簡單說就是滿足用戶使用積分抽獎的一個需求。上圖左側(cè)就是研發(fā)最開始設(shè)計的流程,通過RPC接口扣減用戶積分,扣減成功后進行抽獎。但由于當(dāng)天RPC服務(wù)不穩(wěn)定,造成RPC實際調(diào)用成功,但返回超時失敗。而調(diào)用RPC接口的uuid是每次自動生成的,不具備調(diào)用冪等性。所以造成了用戶積分多支付現(xiàn)象。 處理:事故后修改抽獎流程,先生成待抽獎的抽獎單,由抽獎單ID調(diào)用RPC接口,保證接口冪等性。在RPC接口失敗時由定時任務(wù)補償?shù)姆绞綀?zhí)行抽獎。流程整改后發(fā)現(xiàn),補償任務(wù)每周發(fā)生1~3次,那么也就是證明了RPC接口確實有可用率問題,同時也說明很久之前就有流程問題,但由于用戶客訴較少,所以沒有反饋。
7. 領(lǐng)域聚合
不夠抽象、不能寫死、不好擴展,是不是總是你的代碼,每次都像一錘子買賣,完全是寫死的、綁定的,根本沒有一點縫隙讓新的需求擴展進去。
為什么呢,因為很多研發(fā)寫出來的代碼都不具有領(lǐng)域聚合的特點,當(dāng)然這并不一定非得是在DDD的結(jié)構(gòu)下,哪怕是在MVC的分層里,也一樣可以寫出很多好的聚合邏輯,把功能實現(xiàn)和業(yè)務(wù)的調(diào)用分離開。
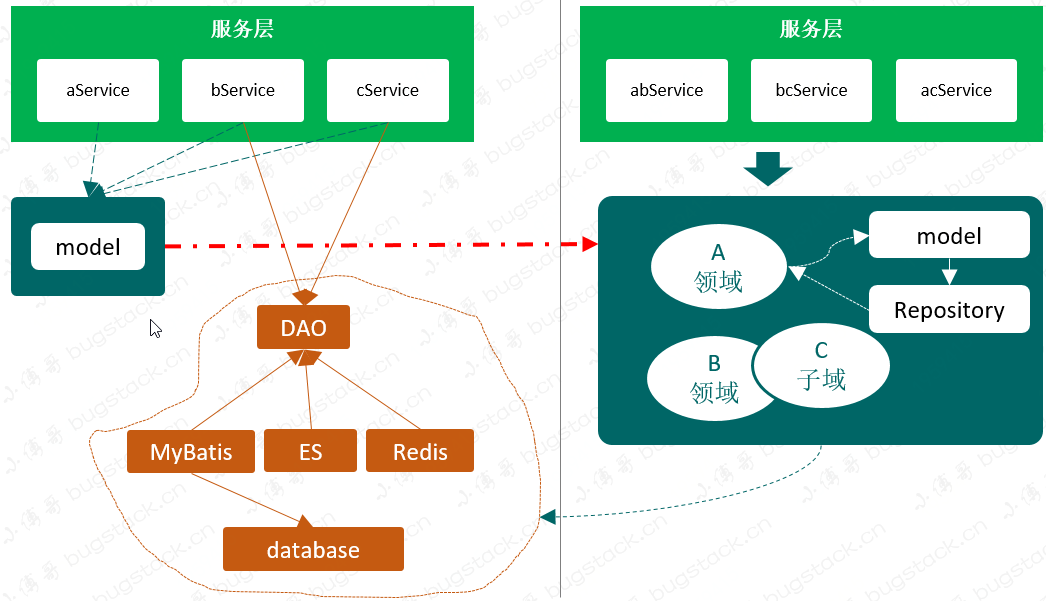
依靠領(lǐng)域驅(qū)動設(shè)計的設(shè)計思想,通過事件風(fēng)暴建立領(lǐng)域模型,合理劃分領(lǐng)域邏輯和物理邊界,建立領(lǐng)域?qū)ο蠹胺?wù)矩陣和服務(wù)架構(gòu)圖,定義符合DDD分層架構(gòu)思想的代碼結(jié)構(gòu)模型,保證業(yè)務(wù)模型與代碼模型的一致性。通過上述設(shè)計思想、方法和過程,指導(dǎo)團隊按照DDD設(shè)計思想完成微服務(wù)設(shè)計和開發(fā)。 拒絕泥球小單體、拒絕污染功能與服務(wù)、拒絕一加功能排期一個月 架構(gòu)出高可用極易符合互聯(lián)網(wǎng)高速迭代的應(yīng)用服務(wù) 物料化、組裝化、可編排的服務(wù),提高人效
8. 服務(wù)分層
如果你想讓你的系統(tǒng)工程代碼可以支撐絕對多數(shù)的業(yè)務(wù)需求,并且能沉淀下來可以服用的功能,那么基本你就需要在做代碼開發(fā)實現(xiàn)的時候,抽離出技術(shù)組件、功能領(lǐng)域和業(yè)務(wù)邏輯這樣幾個分層,不要把頻繁變化的業(yè)務(wù)邏輯寫入到各個功能領(lǐng)域中,應(yīng)該讓功能領(lǐng)域更具有獨立性,可以被業(yè)務(wù)層串聯(lián)、編排、組合實現(xiàn)不同業(yè)務(wù)需求。這樣你的功能領(lǐng)域才能被逐步沉淀下來,也更易于每次需求都 擴展。
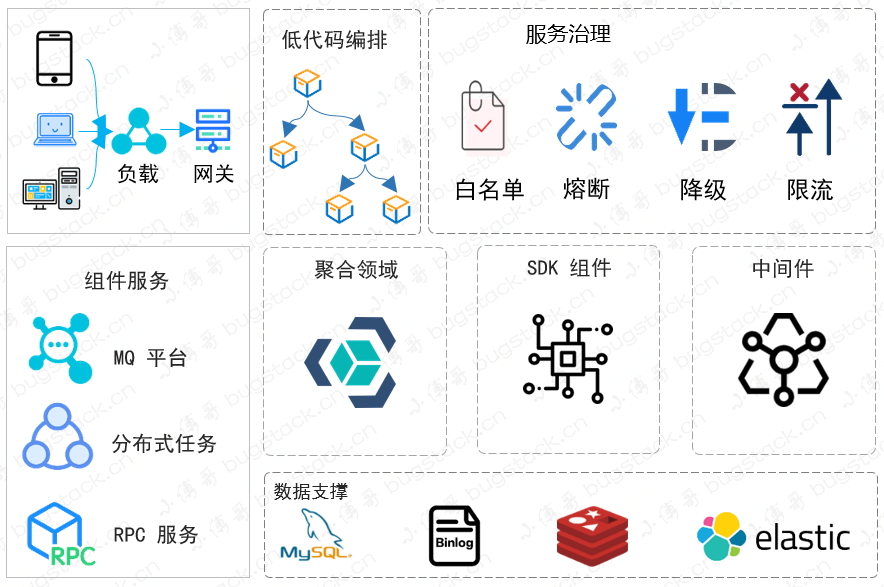
這是一個簡化的分層邏輯結(jié)構(gòu),有聚合的領(lǐng)域、SDK組件、中間件和代碼編排,并提供一些通用共性凝練出的服務(wù)治理功能。通過這樣的分層和各個層級的實現(xiàn)方式,就可以更加靈活的承接需求了。
9. 并發(fā)優(yōu)化
在分布式場景開發(fā)系統(tǒng),要盡可能運用上分布式的能力,從程序設(shè)計上盡可能的去避免一些集中的、分布式事物的、數(shù)據(jù)庫加鎖的,因為這些方式的使用都可能在某些極端情況下,造成系統(tǒng)的負(fù)載的超標(biāo),從而引發(fā)事故。
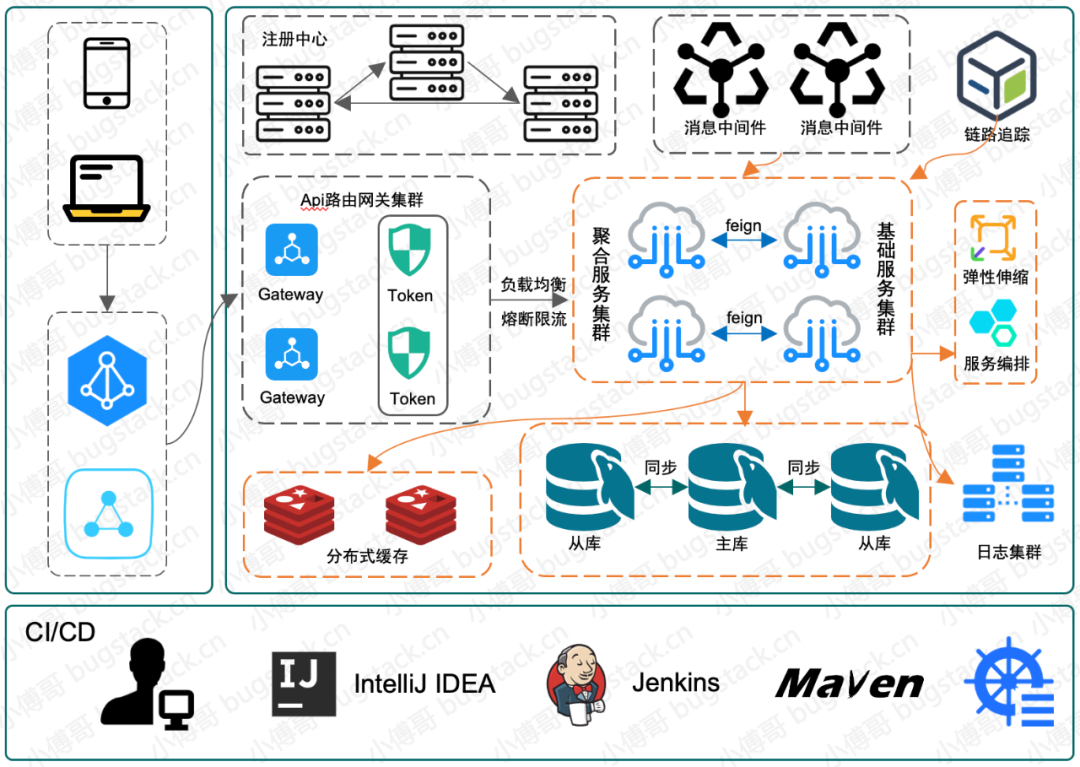
所以通常情況下更需要做去集中化處理,使用MQ消除峰,降低耦合,讓數(shù)據(jù)可以最終一致性,也更要考慮在 Redis 下的使用,減少對數(shù)據(jù)庫的大量鎖處理。 合理的運用MQ、RPC、分布式任務(wù)、Redis、分庫分表以及分布式事務(wù)只有這樣的操作你才可能讓自己的程序代碼可以支撐起更大的業(yè)務(wù)體量。
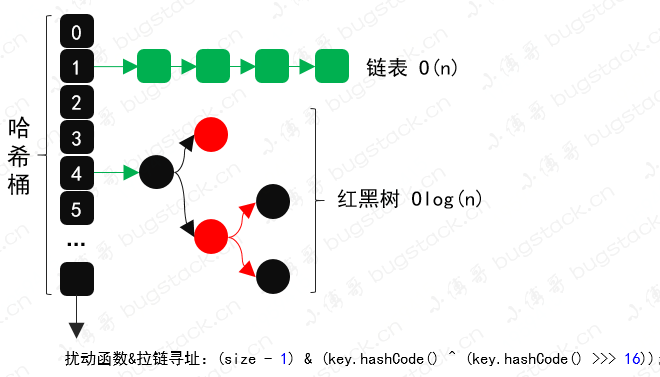
10. 源碼能力
你有了解過 HashMap 的拉鏈尋址數(shù)據(jù)結(jié)構(gòu)嗎、知道哈希散列和擾動函數(shù)嗎、懂得怎么結(jié)合Spring動態(tài)切換數(shù)據(jù)源嗎、AOP 是怎么實現(xiàn)以及使用的、MyBatis 是怎么和 Spring 結(jié)合交管Bean對象的,等等。看似都是些面試的八股文,但在實際的開發(fā)中其實是可以解決很多問題的。
@Around("aopPoint() && @annotation(dbRouter)")
public Object doRouter(ProceedingJoinPoint jp, DBRouter dbRouter) throws Throwable {
String dbKey = dbRouter.key();
if (StringUtils.isBlank(dbKey)) throw new RuntimeException("annotation DBRouter key is null!");
// 計算路由
String dbKeyAttr = getAttrValue(dbKey, jp.getArgs());
int size = dbRouterConfig.getDbCount() * dbRouterConfig.getTbCount();
// 擾動函數(shù)
int idx = (size - 1) & (dbKeyAttr.hashCode() ^ (dbKeyAttr.hashCode() >>> 16));
// 庫表索引
int dbIdx = idx / dbRouterConfig.getTbCount() + 1;
int tbIdx = idx - dbRouterConfig.getTbCount() * (dbIdx - 1);
// 設(shè)置到 ThreadLocal
DBContextHolder.setDBKey(String.format("%02d", dbIdx));
DBContextHolder.setTBKey(String.format("%02d", tbIdx));
logger.info("數(shù)據(jù)庫路由 method:{} dbIdx:{} tbIdx:{}", getMethod(jp).getName(), dbIdx, tbIdx);
// 返回結(jié)果
try {
return jp.proceed();
} finally {
DBContextHolder.clearDBKey();
DBContextHolder.clearTBKey();
}
}
這是 HashMap 哈希桶數(shù)組 + 鏈表 + 紅黑樹的數(shù)據(jù)結(jié)構(gòu),通過擾動函數(shù) (size - 1) & (key.hashCode() ^ (key.hashCode() >>> 16));解決數(shù)據(jù)碰撞嚴(yán)重的問題。但其實這樣的散列算法、尋址方式都可以運用到數(shù)據(jù)庫路由的設(shè)計實現(xiàn)中,還有整個數(shù)組+鏈表的方式其實庫+表的方式也有類似之處。 數(shù)據(jù)庫路由簡化的核心邏輯實現(xiàn)代碼如上,首先我們提取了庫表乘積的數(shù)量,把它當(dāng)成 HashMap 一樣的長度進行使用。 當(dāng) idx 計算完總長度上的一個索引位置后,還需要把這個位置折算到庫表中,看看總體長度的索引因為落到哪個庫哪個表。 最后是把這個計算的索引信息存放到 ThreadLocal 中,用于傳遞在方法調(diào)用過程中可以提取到索引信息。
三、總結(jié)
講道理,你幾乎不太可能把一堆已經(jīng)爛的不行的代碼,通過重構(gòu)的方式把他處理干凈。細了說,你要改變代碼結(jié)構(gòu)分層、屬性對象整合、調(diào)用邏輯封裝,但任何一步的操作都可能會對原有的接口定義和調(diào)用造成風(fēng)險影響,而且外部現(xiàn)有調(diào)用你的接口還需要隨著你的改動而升級,可能你會想著在包裝一層,但這一層包裝仍需要較大的時間成本和幾乎沒有價值的適配。 所以我們在實際開發(fā)中,如果能讓這些代碼具有重構(gòu)的可能,幾乎就是要實時重構(gòu),每當(dāng)你在添加新的功能、新的邏輯、修復(fù)異常時,就要考慮是否可以通過代碼結(jié)構(gòu)、實現(xiàn)方式、設(shè)計模式等手段的使用,改變不合理的功能實現(xiàn)。每一次,一點的優(yōu)化和改變,也不會有那么難。 當(dāng)你在接需求的時候,認(rèn)真思考承接這樣的業(yè)務(wù)訴求,都需要建設(shè)怎樣的數(shù)據(jù)結(jié)構(gòu)、算法邏輯、設(shè)計模式、領(lǐng)域聚合、服務(wù)編排、系統(tǒng)架構(gòu)等,才能更合理的搭建出良好的具有易維護、可擴展的系統(tǒng)服務(wù)。如果你對這些還沒有什么感覺,可以閱讀 設(shè)計模式 和 手寫Spring,這些內(nèi)容可以幫助你提升不少的編程邏輯設(shè)計。
往 期 推 薦
3、在 IntelliJ IDEA 中這樣使用 Git,賊方便了!
點分享
點收藏
點點贊
點在看




