
20個高頻Spark熱門技術(shù)點,你學(xué)廢了嗎?
? ? ? ? 關(guān)于大數(shù)據(jù)面試中對Spark的知識考查不需本菌多解釋什么了吧~本篇博客,博主為大家分享20個Spark熱門技術(shù)點,希望想去大廠的同學(xué),一定要把下面的20個知識點看完。
1、Spark有幾種部署方式?(重點)
????????Spark支持3種集群管理器(Cluster Manager),分別為:
??????? 1. Standalone:獨立模式,Spark原生的簡單集群管理器,自帶完整的服務(wù),可單獨部署到一個集群中,無需依賴任何其他資源管理系統(tǒng),使用Standalone可以很方便地搭建一個集群;
??????? 2. Apache Mesos:一個強大的分布式資源管理框架,它允許多種不同的框架部署在其上,包括yarn;
??????? 3. Hadoop YARN:統(tǒng)一的資源管理機制,在上面可以運行多套計算框架,如map reduce、storm等,根據(jù)driver在集群中的位置不同,分為yarn client和yarn cluster
????????實際上,除了上述這些通用的集群管理器外,Spark內(nèi)部也提供了一些方便用戶測試和學(xué)習(xí)的簡單集群部署模式。由于在實際工廠環(huán)境下使用的絕大多數(shù)的集群管理器是Hadoop YARN,因此我們關(guān)注的重點是Hadoop YARN模式下的Spark集群部署。
??????? Spark的運行模式取決于傳遞給SparkContext的MASTER環(huán)境變量的值,個別模式還需要輔助的程序接口來配合使用,目前支持的Master字符串及URL包括:
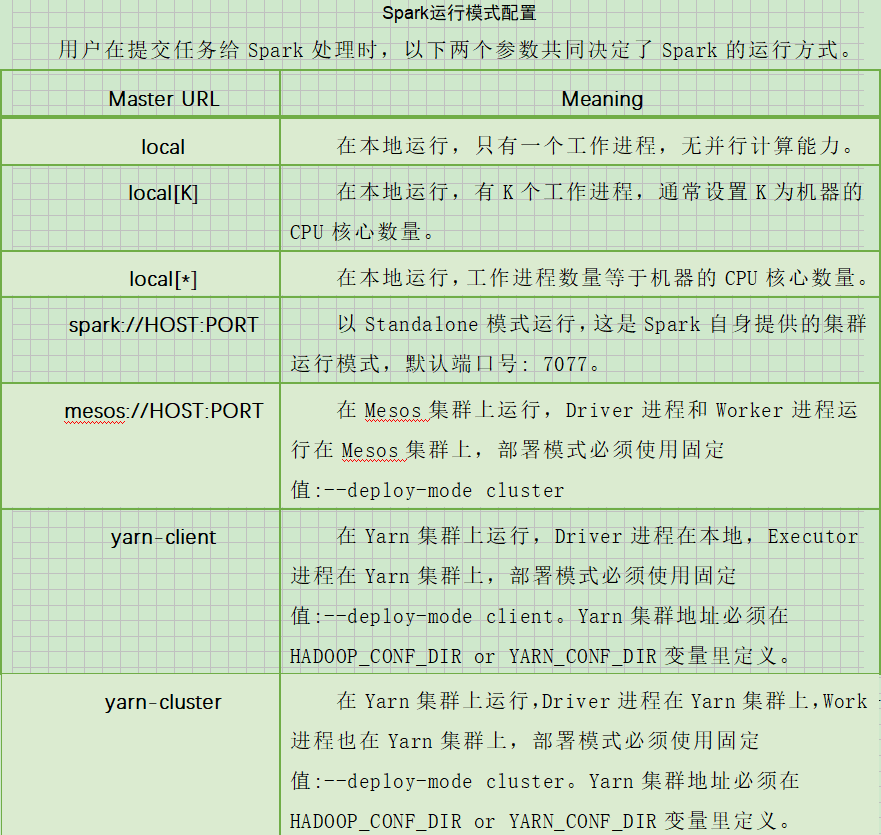
– master MASTER_URL :決定了Spark任務(wù)提交給哪種集群處理。
– deploy-mode DEPLOY_MODE:決定了Driver的運行方式,可選值為Client 或者 Cluster。
2、Spark提交作業(yè)參數(shù)(重點)
此處來源的網(wǎng)址為:https://blog.csdn.net/gamer_gyt/article/details/79135118
1)在提交任務(wù)時的幾個重要參數(shù)
executor-cores?——?每個executor使用的內(nèi)核數(shù),默認為1,官方建議2-5個,企業(yè)是4個
num-executors?——??啟動executors的數(shù)量,默認為2
executor-memory?——??executor內(nèi)存大小,默認1G
driver-cores?——??driver使用內(nèi)核數(shù),默認為1
driver-memory?——??driver內(nèi)存大小,默認512M
2)給出一個提交任務(wù)的樣式
spark-submit?\
??--master?local[5]??\
??--driver-cores?2???\
??--driver-memory?8g?\
??--executor-cores?4?\
??--num-executors?7?\
??--executor-memory?8g?\
??--class?PackageName.ClassName?XXXX.jar?\
??--name?"Spark?Job?Name"?\
??InputPath??????\
??OutputPath
官網(wǎng)參數(shù)配置:http://spark.apache.org/docs/latest/configuration.html
????????
3、簡述Spark on yarn的作業(yè)提交流程(重點)
YARN Client模式
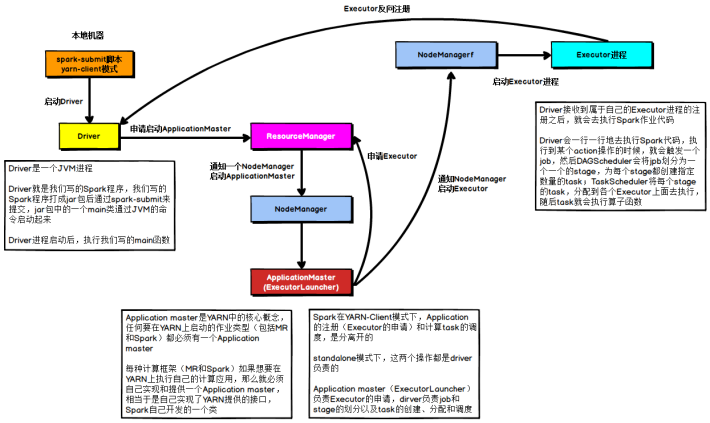 ????????在YARN Client模式下,Driver在任務(wù)提交的本地機器上運行,Driver啟動后會和ResourceManager通訊申請啟動ApplicationMaster,隨后ResourceManager分配container,在合適的NodeManager上啟動ApplicationMaster,此時的ApplicationMaster的功能相當(dāng)于一個ExecutorLaucher,只負責(zé)向ResourceManager申請Executor內(nèi)存。
????????在YARN Client模式下,Driver在任務(wù)提交的本地機器上運行,Driver啟動后會和ResourceManager通訊申請啟動ApplicationMaster,隨后ResourceManager分配container,在合適的NodeManager上啟動ApplicationMaster,此時的ApplicationMaster的功能相當(dāng)于一個ExecutorLaucher,只負責(zé)向ResourceManager申請Executor內(nèi)存。
??????? ResourceManager接到ApplicationMaster的資源申請后會分配container,然后ApplicationMaster在資源分配指定的NodeManager上啟動Executor進程,Executor進程啟動后會向Driver反向注冊,Executor全部注冊完成后Driver開始執(zhí)行main函數(shù),之后執(zhí)行到Action算子時,觸發(fā)一個job,并根據(jù)寬依賴開始劃分stage,每個stage生成對應(yīng)的taskSet,之后將task分發(fā)到各個Executor上執(zhí)行。
YARN Cluster模式
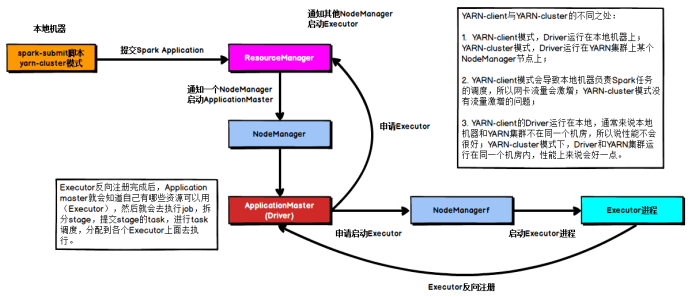
????????在YARN Cluster模式下,任務(wù)提交后會和ResourceManager通訊申請啟動ApplicationMaster,隨后ResourceManager分配container,在合適的NodeManager上啟動ApplicationMaster,此時的ApplicationMaster就是Driver。
??????? Driver啟動后向ResourceManager申請Executor內(nèi)存,ResourceManager接到ApplicationMaster的資源申請后會分配container,然后在合適的NodeManager上啟動Executor進程,Executor進程啟動后會向Driver反向注冊,Executor全部注冊完成后Driver開始執(zhí)行main函數(shù),之后執(zhí)行到Action算子時,觸發(fā)一個job,并根據(jù)寬依賴開始劃分stage,每個stage生成對應(yīng)的taskSet,之后將task分發(fā)到各個Executor上執(zhí)行。????????
4、請列舉Spark的transformation算子(不少于5個)(重點)
1)map
2)flatMap?
3)filter?
4)groupByKey?
5)reduceByKey?
6)sortByKey
????????
5、請列舉Spark的action算子(不少于5個)(重點)
1)reduce:
2)collect:?
3)first:
4)take:
5)aggregate:
6)countByKey:
7)foreach:
8)saveAsTextFile:????????
6、簡述Spark的兩種核心Shuffle(重點)
????????spark的Shuffle有Hash Shuffle和Sort Shuffle兩種。
????????在Spark 1.2以前,默認的shuffle計算引擎是HashShuffleManager。
????????HashShuffleManager有著一個非常嚴重的弊端,就是會產(chǎn)生大量的中間磁盤文件,進而由大量的磁盤IO操作影響了性能。因此在Spark 1.2以后的版本中,默認的ShuffleManager改成了SortShuffleManager。
????????SortShuffleManager相較于HashShuffleManager來說,有了一定的改進。主要就在于,每個Task在進行shuffle操作時,雖然也會產(chǎn)生較多的臨時磁盤文件,但是最后會將所有的臨時文件合并(merge)成一個磁盤文件,因此每個Task就只有一個磁盤文件。在下一個stage的shuffle read task拉取自己的數(shù)據(jù)時,只要根據(jù)索引讀取每個磁盤文件中的部分數(shù)據(jù)即可。
????????未經(jīng)優(yōu)化的HashShuffle: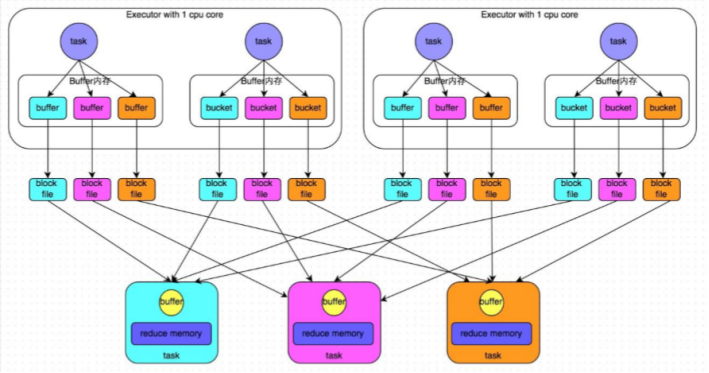 ????????上游的stage的task對相同的key執(zhí)行hash算法,從而將相同的key都寫入到一個磁盤文件中,而每一個磁盤文件都只屬于下游stage的一個task。在將數(shù)據(jù)寫入磁盤之前,會先將數(shù)據(jù)寫入到內(nèi)存緩沖,當(dāng)內(nèi)存緩沖填滿之后,才會溢寫到磁盤文件中。但是這種策略的不足在于,下游有幾個task,上游的每一個task都就都需要創(chuàng)建幾個臨時文件,每個文件中只存儲key取hash之后相同的數(shù)據(jù),導(dǎo)致了當(dāng)下游的task任務(wù)過多的時候,上游會堆積大量的小文件。
????????上游的stage的task對相同的key執(zhí)行hash算法,從而將相同的key都寫入到一個磁盤文件中,而每一個磁盤文件都只屬于下游stage的一個task。在將數(shù)據(jù)寫入磁盤之前,會先將數(shù)據(jù)寫入到內(nèi)存緩沖,當(dāng)內(nèi)存緩沖填滿之后,才會溢寫到磁盤文件中。但是這種策略的不足在于,下游有幾個task,上游的每一個task都就都需要創(chuàng)建幾個臨時文件,每個文件中只存儲key取hash之后相同的數(shù)據(jù),導(dǎo)致了當(dāng)下游的task任務(wù)過多的時候,上游會堆積大量的小文件。
????????優(yōu)化后的HashShuffle: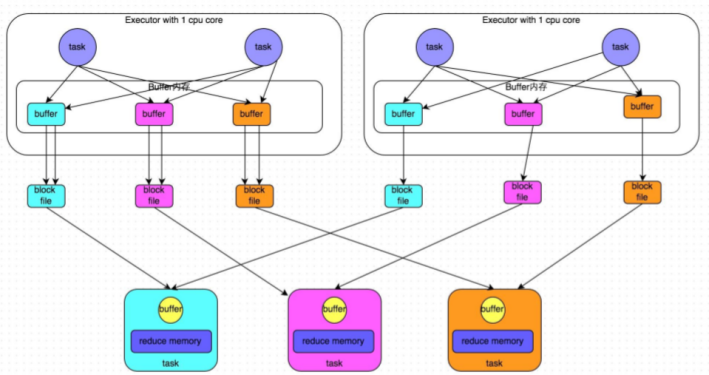 ????????在shuffle write過程中,上游stage的task就不是為下游stage的每個task創(chuàng)建一個磁盤文件了。此時會出現(xiàn)shuffleFileGroup的概念,每個shuffleFileGroup會對應(yīng)一批磁盤文件,磁盤文件的數(shù)量與下游stage的task數(shù)量是相同的。一個Executor上有多少個CPU core,就可以并行執(zhí)行多少個task。而第一批并行執(zhí)行的每個task都會創(chuàng)建一個shuffleFileGroup,并將數(shù)據(jù)寫入對應(yīng)的磁盤文件內(nèi)。當(dāng)Executor的CPU core執(zhí)行完一批task,接著執(zhí)行下一批task時,下一批task就會復(fù)用之前已有的shuffleFileGroup,包括其中的磁盤文件。也就是說,此時task會將數(shù)據(jù)寫入已有的磁盤文件中,而不會寫入新的磁盤文件中。因此,consolidate機制允許不同的task復(fù)用同一批磁盤文件,這樣就可以有效將多個task的磁盤文件進行一定程度上的合并,從而大幅度減少磁盤文件的數(shù)量,進而提升shuffle write的性能。
????????在shuffle write過程中,上游stage的task就不是為下游stage的每個task創(chuàng)建一個磁盤文件了。此時會出現(xiàn)shuffleFileGroup的概念,每個shuffleFileGroup會對應(yīng)一批磁盤文件,磁盤文件的數(shù)量與下游stage的task數(shù)量是相同的。一個Executor上有多少個CPU core,就可以并行執(zhí)行多少個task。而第一批并行執(zhí)行的每個task都會創(chuàng)建一個shuffleFileGroup,并將數(shù)據(jù)寫入對應(yīng)的磁盤文件內(nèi)。當(dāng)Executor的CPU core執(zhí)行完一批task,接著執(zhí)行下一批task時,下一批task就會復(fù)用之前已有的shuffleFileGroup,包括其中的磁盤文件。也就是說,此時task會將數(shù)據(jù)寫入已有的磁盤文件中,而不會寫入新的磁盤文件中。因此,consolidate機制允許不同的task復(fù)用同一批磁盤文件,這樣就可以有效將多個task的磁盤文件進行一定程度上的合并,從而大幅度減少磁盤文件的數(shù)量,進而提升shuffle write的性能。
????????注意:如果想使用優(yōu)化之后的ShuffleManager,需要將:spark.shuffle.consolidateFiles調(diào)整為true。(當(dāng)然,默認是開啟的)
????????總結(jié):
未經(jīng)優(yōu)化:上游的task數(shù)量:m ? , 下游的task數(shù)量:n ? ?, 上游的executor數(shù)量:k (m>=k) ? , 總共的磁盤文件:mn
優(yōu)化之后:上游的task數(shù)量:m ? ?, 下游的task數(shù)量:n ? , 上游的executor數(shù)量:k (m>=k) ? , 總共的磁盤文件:kn
????????普通的SortShuffle:
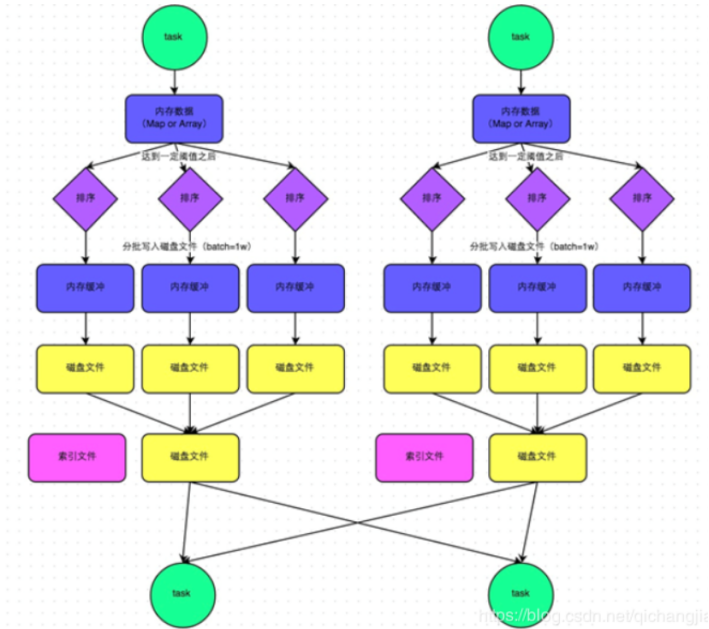 ????????在普通模式下,數(shù)據(jù)會先寫入一個內(nèi)存數(shù)據(jù)結(jié)構(gòu)中,此時根據(jù)不同的shuffle算子,可以選用不同的數(shù)據(jù)結(jié)構(gòu)。如果是由聚合操作的shuffle算子,就是用map的數(shù)據(jù)結(jié)構(gòu)(邊聚合邊寫入內(nèi)存),如果是join的算子,就使用array的數(shù)據(jù)結(jié)構(gòu)(直接寫入內(nèi)存)。接著,每寫一條數(shù)據(jù)進入內(nèi)存數(shù)據(jù)結(jié)構(gòu)之后,就會判斷是否達到了某個臨界值,如果達到了臨界值的話,就會嘗試的將內(nèi)存數(shù)據(jù)結(jié)構(gòu)中的數(shù)據(jù)溢寫到磁盤,然后清空內(nèi)存數(shù)據(jù)結(jié)構(gòu)。
????????在普通模式下,數(shù)據(jù)會先寫入一個內(nèi)存數(shù)據(jù)結(jié)構(gòu)中,此時根據(jù)不同的shuffle算子,可以選用不同的數(shù)據(jù)結(jié)構(gòu)。如果是由聚合操作的shuffle算子,就是用map的數(shù)據(jù)結(jié)構(gòu)(邊聚合邊寫入內(nèi)存),如果是join的算子,就使用array的數(shù)據(jù)結(jié)構(gòu)(直接寫入內(nèi)存)。接著,每寫一條數(shù)據(jù)進入內(nèi)存數(shù)據(jù)結(jié)構(gòu)之后,就會判斷是否達到了某個臨界值,如果達到了臨界值的話,就會嘗試的將內(nèi)存數(shù)據(jù)結(jié)構(gòu)中的數(shù)據(jù)溢寫到磁盤,然后清空內(nèi)存數(shù)據(jù)結(jié)構(gòu)。
????????在溢寫到磁盤文件之前,會先根據(jù)key對內(nèi)存數(shù)據(jù)結(jié)構(gòu)中已有的數(shù)據(jù)進行排序,排序之后,會分批將數(shù)據(jù)寫入磁盤文件。默認的batch數(shù)量是10000條,也就是說,排序好的數(shù)據(jù),會以每批次1萬條數(shù)據(jù)的形式分批寫入磁盤文件,寫入磁盤文件是通過Java的BufferedOutputStream實現(xiàn)的。BufferedOutputStream是Java的緩沖輸出流,首先會將數(shù)據(jù)緩沖在內(nèi)存中,當(dāng)內(nèi)存緩沖滿溢之后再一次寫入磁盤文件中,這樣可以減少磁盤IO次數(shù),提升性能。
????????此時task將所有數(shù)據(jù)寫入內(nèi)存數(shù)據(jù)結(jié)構(gòu)的過程中,會發(fā)生多次磁盤溢寫,會產(chǎn)生多個臨時文件,最后會將之前所有的臨時文件都進行合并,最后會合并成為一個大文件。最終只剩下兩個文件,一個是合并之后的數(shù)據(jù)文件,一個是索引文件(標(biāo)識了下游各個task的數(shù)據(jù)在文件中的start offset與end offset)。最終再由下游的task根據(jù)索引文件讀取相應(yīng)的數(shù)據(jù)文件。
????????SortShuffle - bypass運行機制 :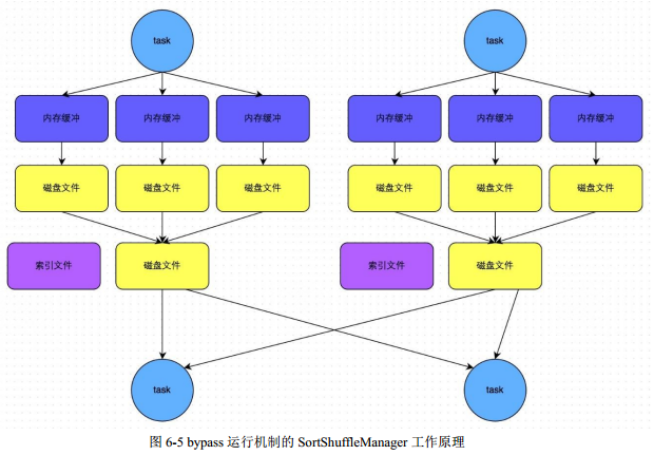 ????????此時上游stage的task會為每個下游stage的task都創(chuàng)建一個臨時磁盤文件,并將數(shù)據(jù)按key進行hash然后根據(jù)key的hash值,將key寫入對應(yīng)的磁盤文件之中。當(dāng)然,寫入磁盤文件時也是先寫入內(nèi)存緩沖,緩沖寫滿之后再溢寫到磁盤文件的。最后,同樣會將所有臨時磁盤文件都合并成一個磁盤文件,并創(chuàng)建一個單獨的索引文件。
????????此時上游stage的task會為每個下游stage的task都創(chuàng)建一個臨時磁盤文件,并將數(shù)據(jù)按key進行hash然后根據(jù)key的hash值,將key寫入對應(yīng)的磁盤文件之中。當(dāng)然,寫入磁盤文件時也是先寫入內(nèi)存緩沖,緩沖寫滿之后再溢寫到磁盤文件的。最后,同樣會將所有臨時磁盤文件都合并成一個磁盤文件,并創(chuàng)建一個單獨的索引文件。
????????自己的理解:bypass的就是不排序,還是用hash去為key分磁盤文件,分完之后再合并,形成一個索引文件和一個合并后的key hash文件。省掉了排序的性能。
??????? bypass機制與普通SortShuffleManager運行機制的不同在于:
??????? a、磁盤寫機制不同;???????
? ? ? ? b、不會進行排序。
????????也就是說,啟用該機制的最大好處在于,shuffle write過程中,不需要進行數(shù)據(jù)的排序操作,也就節(jié)省掉了這部分的性能開銷。
觸發(fā)bypass機制的條件:shuffle map task的數(shù)量小于 spark.shuffle.sort.bypassMergeThreshold 參數(shù)的值(默認200)或者不是聚合類的shuffle算子(比如groupByKey)
7、簡述SparkSQL中RDD、DataFrame、DataSet三者的區(qū)別與聯(lián)系?(重點)
????????RDD
彈性分布式數(shù)據(jù)集;不可變、可分區(qū)、元素可以并行計算的集合。
優(yōu)點:
RDD編譯時類型安全:編譯時能檢查出類型錯誤; 面向?qū)ο蟮木幊田L(fēng)格:直接通過類名點的方式操作數(shù)據(jù)。
缺點:
序列化和反序列化的性能開銷很大,大量的網(wǎng)絡(luò)傳輸; 構(gòu)建對象占用了大量的heap堆內(nèi)存,導(dǎo)致頻繁的GC(程序進行GC時,所有任務(wù)都是暫停)
DataFrame
RDD為基礎(chǔ)的分布式數(shù)據(jù)集
優(yōu)點:
DataFrame帶有元數(shù)據(jù)schema,每一列都帶有名稱和類型。 DataFrame引入了off-heap,構(gòu)建對象直接使用操作系統(tǒng)的內(nèi)存,不會導(dǎo)致頻繁GC。 DataFrame可以從很多數(shù)據(jù)源構(gòu)建; DataFrame把內(nèi)部元素看成Row對象,表示一行行的數(shù)據(jù)。 DataFrame=RDD+schema
缺點:
編譯時類型不安全; 不具有面向?qū)ο缶幊痰娘L(fēng)格。
Dataset
包含了DataFrame的功能,Spark2.0中兩者統(tǒng)一,DataFrame表示為DataSet[Row],即DataSet的子集。
優(yōu)點:
DataSet可以在編譯時檢查類型; 并且是面向?qū)ο蟮木幊探涌?/section>
??????? DataSet 結(jié)合了 RDD 和 DataFrame 的優(yōu)點,并帶來的一個新的概念 Encoder。當(dāng)序列化數(shù)據(jù)時,Encoder 產(chǎn)生字節(jié)碼與 off-heap 進行交互,能夠達到按需訪問數(shù)據(jù)的效果,而不用反序列化整個對象。
三者之間的轉(zhuǎn)換: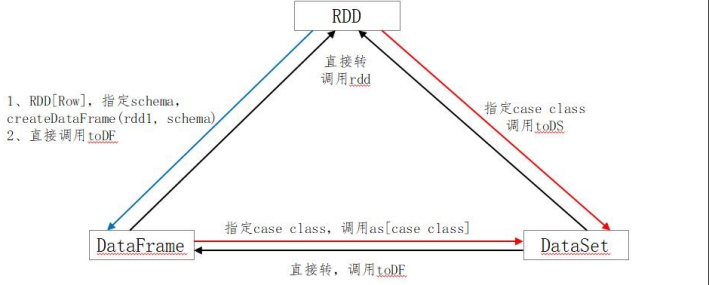
????????
8、Repartition和Coalesce關(guān)系與區(qū)別(重點)
1)關(guān)系:
????????兩者都是用來改變RDD的partition數(shù)量的,repartition底層調(diào)用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
2)區(qū)別:
????????repartition一定會發(fā)生shuffle,coalesce根據(jù)傳入的參數(shù)來判斷是否發(fā)生shuffle
????????一般情況下增大rdd的partition數(shù)量使用repartition,減少partition數(shù)量時使用coalesce
????????
9、Spark中cache默認緩存級別是什么?(重點)
????????DataFrame的cache默認采用 MEMORY_AND_DISK 這和RDD 的默認方式不一樣。RDD的cache默認采用MEMORY_ONLY

10、SparkSQL中join操作與left join操作的區(qū)別?(重點)
??????? join和sql中的inner join操作很相似,返回結(jié)果是前面一個集合和后面一個集合中匹配成功的,過濾掉關(guān)聯(lián)不上的。
??????? leftJoin類似于SQL中的左外關(guān)聯(lián)left outer join,返回結(jié)果以第一個RDD為主,關(guān)聯(lián)不上的記錄為空。
????????部分場景下可以使用left semi join替代left join:
????????因為 left semi join 是 in(keySet) 的關(guān)系,遇到右表重復(fù)記錄,左表會跳過,性能更高,而 left join 則會一直遍歷。但是left semi join 中最后 select 的結(jié)果中只許出現(xiàn)左表中的列名,因為右表只有 join key 參與關(guān)聯(lián)計算了。
11、Spark常用算子reduceByKey與groupByKey的區(qū)別,哪一種更具優(yōu)勢?(重點)
????????reduceByKey:按照key進行聚合,在shuffle之前有combine(預(yù)聚合)操作,返回結(jié)果是RDD[k,v]。
????????groupByKey:按照key進行分組,直接進行shuffle。
????????開發(fā)指導(dǎo):reduceByKey比groupByKey,建議使用。但是需要注意是否會影響業(yè)務(wù)邏輯。
12、Spark Shuffle默認并行度是多少?(重點)
????????參數(shù)spark.sql.shuffle.partitions 決定 默認并行度200
13、簡述Spark中共享變量(廣播變量和累加器)。(重點)
????????Spark為此提供了兩種共享變量,一種是Broadcast Variable(廣播變量),另一種是Accumulator(累加變量)。Broadcast Variable會將使用到的變量,僅僅為每個節(jié)點拷貝一份,更大的用處是優(yōu)化性能,減少網(wǎng)絡(luò)傳輸以及內(nèi)存消耗。Accumulator則可以讓多個task共同操作一份變量,主要可以進行累加操作。
??????? Spark提供的Broadcast Variable,是只讀的。并且在每個節(jié)點上只會有一份副本,而不會為每個task都拷貝一份副本。因此其最大作用,就是減少變量到各個節(jié)點的網(wǎng)絡(luò)傳輸消耗,以及在各個節(jié)點上的內(nèi)存消耗。此外,spark自己內(nèi)部也使用了高效的廣播算法來減少網(wǎng)絡(luò)消耗。可以通過調(diào)用SparkContext的broadcast()方法,來針對某個變量創(chuàng)建廣播變量。然后在算子的函數(shù)內(nèi),使用到廣播變量時,每個節(jié)點只會拷貝一份副本了。每個節(jié)點可以使用廣播變量的value()方法獲取值。記住,廣播變量,是只讀的。
14、SparkStreaming有哪幾種方式消費Kafka中的數(shù)據(jù),它們之間的區(qū)別是什么?(重點)
一、基于Receiver的方式
????????這種方式使用Receiver來獲取數(shù)據(jù)。Receiver是使用Kafka的高層次Consumer API來實現(xiàn)的。receiver從Kafka中獲取的數(shù)據(jù)都是存儲在Spark Executor的內(nèi)存中的(如果突然數(shù)據(jù)暴增,大量batch堆積,很容易出現(xiàn)內(nèi)存溢出的問題),然后Spark Streaming啟動的job會去處理那些數(shù)據(jù)。
????????然而,在默認的配置下,這種方式可能會因為底層的失敗而丟失數(shù)據(jù)。如果要啟用高可靠機制,讓數(shù)據(jù)零丟失,就必須啟用Spark Streaming的預(yù)寫日志機制(Write Ahead Log,WAL)。該機制會同步地將接收到的Kafka數(shù)據(jù)寫入分布式文件系統(tǒng)(比如HDFS)上的預(yù)寫日志中。所以,即使底層節(jié)點出現(xiàn)了失敗,也可以使用預(yù)寫日志中的數(shù)據(jù)進行恢復(fù)。
二、基于Direct的方式
????????這種新的不基于Receiver的直接方式,是在Spark 1.3中引入的,從而能夠確保更加健壯的機制。替代掉使用Receiver來接收數(shù)據(jù)后,這種方式會周期性地查詢Kafka,來獲得每個topic+partition的最新的offset,從而定義每個batch的offset的范圍。當(dāng)處理數(shù)據(jù)的job啟動時,就會使用Kafka的簡單consumer api來獲取Kafka指定offset范圍的數(shù)據(jù)。
優(yōu)點如下:
簡化并行讀取: ?如果要讀取多個partition,不需要創(chuàng)建多個輸入DStream然后對它們進行union操作。Spark會創(chuàng)建跟Kafka partition一樣多的RDD partition,并且會并行從Kafka中讀取數(shù)據(jù)。所以在Kafka partition和RDD partition之間,有一個一對一的映射關(guān)系。
高性能: 如果要保證零數(shù)據(jù)丟失,在基于receiver的方式中,需要開啟WAL機制。這種方式其實效率低下,因為數(shù)據(jù)實際上被復(fù)制了兩份,Kafka自己本身就有高可靠的機制,會對數(shù)據(jù)復(fù)制一份,而這里又會復(fù)制一份到WAL中。而基于direct的方式,不依賴Receiver,不需要開啟WAL機制,只要Kafka中作了數(shù)據(jù)的復(fù)制,那么就可以通過Kafka的副本進行恢復(fù)。
三、對比:
????????基于receiver的方式,是使用Kafka的高階API來在ZooKeeper中保存消費過的offset的。這是消費Kafka數(shù)據(jù)的傳統(tǒng)方式。這種方式配合著WAL機制可以保證數(shù)據(jù)零丟失的高可靠性,但是卻無法保證數(shù)據(jù)被處理一次且僅一次,可能會處理兩次。因為Spark和ZooKeeper之間可能是不同步的。
????????基于direct的方式,使用kafka的簡單api,Spark Streaming自己就負責(zé)追蹤消費的offset,并保存在checkpoint中。Spark自己一定是同步的,因此可以保證數(shù)據(jù)是消費一次且僅消費一次。
????????在實際生產(chǎn)環(huán)境中大都用Direct方式
15、請簡述一下SparkStreaming的窗口函數(shù)中窗口寬度和滑動距離的關(guān)系?(重點)

16、Spark通用運行流程概述?(重點)
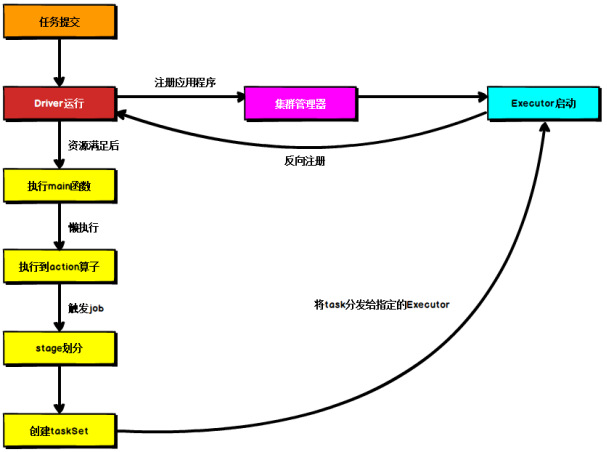
????????不論Spark以何種模式進行部署,任務(wù)提交后,都會先啟動Driver進程,隨后Driver進程向集群管理器注冊應(yīng)用程序,之后集群管理器根據(jù)此任務(wù)的配置文件分配Executor并啟動,當(dāng)Driver所需的資源全部滿足后,Driver開始執(zhí)行main函數(shù),Spark查詢?yōu)閼袌?zhí)行,當(dāng)執(zhí)行到action算子時開始反向推算,根據(jù)寬依賴進行stage的劃分,隨后每一個stage對應(yīng)一個taskset,taskset中有多個task,根據(jù)本地化原則,task會被分發(fā)到指定的Executor去執(zhí)行,在任務(wù)執(zhí)行的過程中,Executor也會不斷與Driver進行通信,報告任務(wù)運行情況。
17、Standalone模式運行機制
??????? Standalone集群有四個重要組成部分,分別是:
??????? 1)Driver:是一個進程,我們編寫的Spark應(yīng)用程序就運行在Driver上,由Driver進程執(zhí)行;
??????? 2)Master(RM):是一個進程,主要負責(zé)資源的調(diào)度和分配,并進行集群的監(jiān)控等職責(zé);
??????? 3)Worker(NM):是一個進程,一個Worker運行在集群中的一臺服務(wù)器上,主要負責(zé)兩個職責(zé),一個是用自己的內(nèi)存存儲RDD的某個或某些partition;另一個是啟動其他進程和線程(Executor),對RDD上的partition進行并行的處理和計算。
??????? 4)Executor:是一個進程,一個Worker上可以運行多個Executor,Executor通過啟動多個線程(task)來執(zhí)行對RDD的partition進行并行計算,也就是執(zhí)行我們對RDD定義的例如map、flatMap、reduce等算子操作。
Standalone Client模式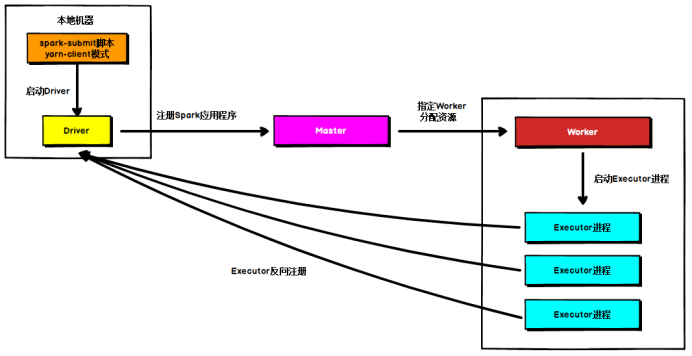 ????????在Standalone Client模式下,Driver在任務(wù)提交的本地機器上運行,Driver啟動后向Master注冊應(yīng)用程序,Master根據(jù)submit腳本的資源需求找到內(nèi)部資源至少可以啟動一個Executor的所有Worker,然后在這些Worker之間分配Executor,Worker上的Executor啟動后會向Driver反向注冊,所有的Executor注冊完成后,Driver開始執(zhí)行main函數(shù),之后執(zhí)行到Action算子時,開始劃分stage,每個stage生成對應(yīng)的taskSet,之后將task分發(fā)到各個Executor上執(zhí)行。
????????在Standalone Client模式下,Driver在任務(wù)提交的本地機器上運行,Driver啟動后向Master注冊應(yīng)用程序,Master根據(jù)submit腳本的資源需求找到內(nèi)部資源至少可以啟動一個Executor的所有Worker,然后在這些Worker之間分配Executor,Worker上的Executor啟動后會向Driver反向注冊,所有的Executor注冊完成后,Driver開始執(zhí)行main函數(shù),之后執(zhí)行到Action算子時,開始劃分stage,每個stage生成對應(yīng)的taskSet,之后將task分發(fā)到各個Executor上執(zhí)行。
Standalone Cluster模式
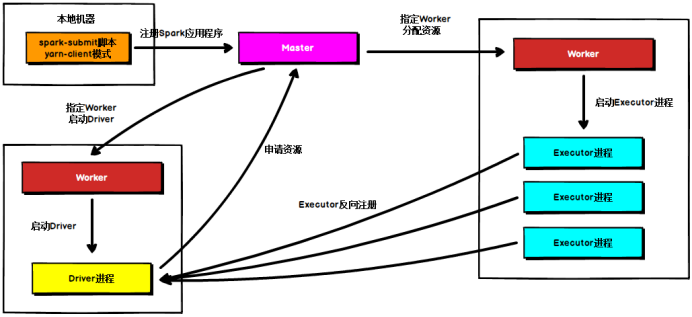 ????????在Standalone Cluster模式下,任務(wù)提交后,Master會找到一個Worker啟動Driver進程, Driver啟動后向Master注冊應(yīng)用程序,Master根據(jù)submit腳本的資源需求找到內(nèi)部資源至少可以啟動一個Executor的所有Worker,然后在這些Worker之間分配Executor,Worker上的Executor啟動后會向Driver反向注冊,所有的Executor注冊完成后,Driver開始執(zhí)行main函數(shù),之后執(zhí)行到Action算子時,開始劃分stage,每個stage生成對應(yīng)的taskSet,之后將task分發(fā)到各個Executor上執(zhí)行。
????????在Standalone Cluster模式下,任務(wù)提交后,Master會找到一個Worker啟動Driver進程, Driver啟動后向Master注冊應(yīng)用程序,Master根據(jù)submit腳本的資源需求找到內(nèi)部資源至少可以啟動一個Executor的所有Worker,然后在這些Worker之間分配Executor,Worker上的Executor啟動后會向Driver反向注冊,所有的Executor注冊完成后,Driver開始執(zhí)行main函數(shù),之后執(zhí)行到Action算子時,開始劃分stage,每個stage生成對應(yīng)的taskSet,之后將task分發(fā)到各個Executor上執(zhí)行。
????????注意,Standalone的兩種模式下(client/Cluster),Master在接到Driver注冊Spark應(yīng)用程序的請求后,會獲取其所管理的剩余資源能夠啟動一個Executor的所有Worker,然后在這些Worker之間分發(fā)Executor,此時的分發(fā)只考慮Worker上的資源是否足夠使用,直到當(dāng)前應(yīng)用程序所需的所有Executor都分配完畢,Executor反向注冊完畢后,Driver開始執(zhí)行main程序。
18、簡述一下Spark 內(nèi)存管理?(了解)
????????在執(zhí)行Spark 的應(yīng)用程序時,Spark 集群會啟動 Driver 和 Executor 兩種 JVM 進程,前者為主控進程,負責(zé)創(chuàng)建 Spark 上下文,提交 Spark 作業(yè)(Job),并將作業(yè)轉(zhuǎn)化為計算任務(wù)(Task),在各個 Executor 進程間協(xié)調(diào)任務(wù)的調(diào)度,后者負責(zé)在工作節(jié)點上執(zhí)行具體的計算任務(wù),并將結(jié)果返回給 Driver,同時為需要持久化的 RDD 提供存儲功能。由于 Driver 的內(nèi)存管理相對來說較為簡單,本節(jié)主要對 Executor 的內(nèi)存管理進行分析,下文中的 Spark 內(nèi)存均特指 Executor 的內(nèi)存。
堆內(nèi)和堆外內(nèi)存規(guī)劃
????????作為一個 JVM 進程,Executor 的內(nèi)存管理建立在 JVM 的內(nèi)存管理之上,Spark 對 JVM 的堆內(nèi)(On-heap)空間進行了更為詳細的分配,以充分利用內(nèi)存。同時,Spark 引入了堆外(Off-heap)內(nèi)存,使之可以直接在工作節(jié)點的系統(tǒng)內(nèi)存中開辟空間,進一步優(yōu)化了內(nèi)存的使用。
????????堆內(nèi)內(nèi)存受到JVM統(tǒng)一管理,堆外內(nèi)存是直接向操作系統(tǒng)進行內(nèi)存的申請和釋放。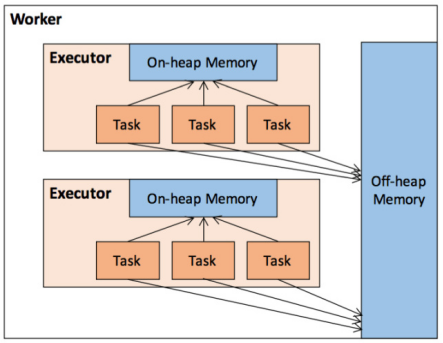
????????1.堆內(nèi)內(nèi)存
????????堆內(nèi)內(nèi)存的大小,由 Spark 應(yīng)用程序啟動時的 –executor-memory 或 spark.executor.memory 參數(shù)配置。Executor 內(nèi)運行的并發(fā)任務(wù)共享 JVM 堆內(nèi)內(nèi)存,這些任務(wù)在緩存 RDD 數(shù)據(jù)和廣播(Broadcast)數(shù)據(jù)時占用的內(nèi)存被規(guī)劃為存儲(Storage)內(nèi)存,而這些任務(wù)在執(zhí)行 Shuffle 時占用的內(nèi)存被規(guī)劃為執(zhí)行(Execution)內(nèi)存,剩余的部分不做特殊規(guī)劃,那些 Spark 內(nèi)部的對象實例,或者用戶定義的 Spark 應(yīng)用程序中的對象實例,均占用剩余的空間。不同的管理模式下,這三部分占用的空間大小各不相同。
????????Spark 對堆內(nèi)內(nèi)存的管理是一種邏輯上的"規(guī)劃式"的管理,因為對象實例占用內(nèi)存的申請和釋放都由 JVM 完成,Spark 只能在申請后和釋放前記錄這些內(nèi)存,我們來看其具體流程:
????????申請內(nèi)存流程如下:
??????? 1.Spark 在代碼中 new 一個對象實例;?????
? ? ???? 2.JVM 從堆內(nèi)內(nèi)存分配空間,創(chuàng)建對象并返回對象引用;?
? ?? ? ? ?3.Spark 保存該對象的引用,記錄該對象占用的內(nèi)存
????????釋放內(nèi)存流程如下:
??????? 1. Spark記錄該對象釋放的內(nèi)存,刪除該對象的引用;?????
? ? ? ? ?2. 等待JVM的垃圾回收機制釋放該對象占用的堆內(nèi)內(nèi)存。
????????我們知道,JVM 的對象可以以序列化的方式存儲,序列化的過程是將對象轉(zhuǎn)換為二進制字節(jié)流,本質(zhì)上可以理解為將非連續(xù)空間的鏈式存儲轉(zhuǎn)化為連續(xù)空間或塊存儲,在訪問時則需要進行序列化的逆過程——反序列化,將字節(jié)流轉(zhuǎn)化為對象,序列化的方式可以節(jié)省存儲空間,但增加了存儲和讀取時候的計算開銷。
????????對于 Spark 中序列化的對象,由于是字節(jié)流的形式,其占用的內(nèi)存大小可直接計算,而對于非序列化的對象,其占用的內(nèi)存是通過周期性地采樣近似估算而得,即并不是每次新增的數(shù)據(jù)項都會計算一次占用的內(nèi)存大小,這種方法降低了時間開銷但是有可能誤差較大,導(dǎo)致某一時刻的實際內(nèi)存有可能遠遠超出預(yù)期。此外,在被 Spark 標(biāo)記為釋放的對象實例,很有可能在實際上并沒有被 JVM 回收,導(dǎo)致實際可用的內(nèi)存小于 Spark 記錄的可用內(nèi)存。所以 Spark 并不能準確記錄實際可用的堆內(nèi)內(nèi)存,從而也就無法完全避免內(nèi)存溢出(OOM, Out of Memory)的異常。
????????雖然不能精準控制堆內(nèi)內(nèi)存的申請和釋放,但 Spark 通過對存儲內(nèi)存和執(zhí)行內(nèi)存各自獨立的規(guī)劃管理,可以決定是否要在存儲內(nèi)存里緩存新的 RDD,以及是否為新的任務(wù)分配執(zhí)行內(nèi)存,在一定程度上可以提升內(nèi)存的利用率,減少異常的出現(xiàn)。
????????2.堆外內(nèi)存
????????為了進一步優(yōu)化內(nèi)存的使用以及提高 Shuffle 時排序的效率,Spark 引入了堆外(Off-heap)內(nèi)存,使之可以直接在工作節(jié)點的系統(tǒng)內(nèi)存中開辟空間,存儲經(jīng)過序列化的二進制數(shù)據(jù)。
????????堆外內(nèi)存意味著把內(nèi)存對象分配在Java虛擬機的堆以外的內(nèi)存,這些內(nèi)存直接受操作系統(tǒng)管理(而不是虛擬機)。這樣做的結(jié)果就是能保持一個較小的堆,以減少垃圾收集對應(yīng)用的影響。
????????利用 JDK Unsafe API(從 Spark 2.0 開始,在管理堆外的存儲內(nèi)存時不再基于 Tachyon,而是與堆外的執(zhí)行內(nèi)存一樣,基于 JDK Unsafe API 實現(xiàn)),Spark 可以直接操作系統(tǒng)堆外內(nèi)存,減少了不必要的內(nèi)存開銷,以及頻繁的 GC 掃描和回收,提升了處理性能。堆外內(nèi)存可以被精確地申請和釋放(堆外內(nèi)存之所以能夠被精確的申請和釋放,是由于內(nèi)存的申請和釋放不再通過JVM機制,而是直接向操作系統(tǒng)申請,JVM對于內(nèi)存的清理是無法準確指定時間點的,因此無法實現(xiàn)精確的釋放),而且序列化的數(shù)據(jù)占用的空間可以被精確計算,所以相比堆內(nèi)內(nèi)存來說降低了管理的難度,也降低了誤差。
????????在默認情況下堆外內(nèi)存并不啟用,可通過配置 spark.memory.offHeap.enabled 參數(shù)啟用,并由 spark.memory.offHeap.size 參數(shù)設(shè)定堆外空間的大小。除了沒有 other 空間,堆外內(nèi)存與堆內(nèi)內(nèi)存的劃分方式相同,所有運行中的并發(fā)任務(wù)共享存儲內(nèi)存和執(zhí)行內(nèi)存。
19、Transformation和action的區(qū)別
????????1、transformation是得到一個新的RDD,方式很多,比如從數(shù)據(jù)源生成一個新的RDD,從RDD生成一個新的RDD
????????2、action是得到一個值,或者一個結(jié)果(直接將RDDcache到內(nèi)存中)所有的transformation都是采用的懶策略,就是如果只是將transformation提交是不會執(zhí)行計算的,計算只有在action被提交的時候才被觸發(fā)。
20、Map和 FlatMap區(qū)別 對結(jié)果集的影響有什么不同
??????? map的作用很容易理解就是對rdd之中的元素進行逐一進行函數(shù)操作映射為另外一個rdd。
??????? flatMap的操作是將函數(shù)應(yīng)用于rdd之中的每一個元素,將返回的迭代器的所有內(nèi)容構(gòu)成新的rdd。通常用來切分單詞。
??????? Spark 中 map函數(shù)會對每一條輸入進行指定的操作,然后為每一條輸入返回一個對象。而flatMap函數(shù)則是兩個操作的集合——正是“先映射后扁平化”
小結(jié)
????????本篇博客的分享就到這里,因為Spark無論是在大數(shù)據(jù)領(lǐng)域還是在面試環(huán)節(jié)過程中,都占非常重要的一環(huán)。所以大家一定不能掉以輕心!
? ? ?
--end--
掃描下方二維碼 添加好友,備注【交流】 可私聊交流,也可進資源豐富學(xué)習(xí)群