“字節(jié)序”是個(gè)鬼

原文出處: https://zhuanlan.zhihu.com/p/21388517
論順序的重要性
做飯的故事
今天女朋友加班,機(jī)智的她早已在昨晚準(zhǔn)備好食材,回家只需下鍋便可。誰知開會(huì)就是個(gè)無底洞,到了B1,還有B2,無窮匱也。
辛苦如她,為了能讓她一回家就吃上熱騰騰的飯菜,我準(zhǔn)備親自下廚,奉獻(xiàn)出我的第一次。食材都已備好,我相信沒有那么難,估摸著應(yīng)該和我習(xí)以為常的流程處理差不多,開火 | 加食材 | 上配料 | 翻炒 | 出鍋,啊哈,想想還有點(diǎn)小激動(dòng)。
今天的晚飯是西紅柿炒雞蛋和胡蘿卜炒肉,實(shí)際操作才發(fā)現(xiàn),又遇到了一個(gè)大坑……
食材是這樣的:
案板1號(hào)(西紅柿炒雞蛋的食材),從左向右依次放著:西紅柿、雞蛋、蔥
案板2號(hào)(胡蘿卜炒肉的食材),從左向右依次放著:蒜、胡蘿卜絲、肉
食材在案板上整齊劃一依次排開,我是先放西紅柿呢,還是先放雞蛋呢,還是先放蔥呢?簡(jiǎn)單溝通后得知,案板上的食材是按順序放好的,我只需要按順序下鍋即可。聽著電視哼著90年代的老歌,三下五除二,兩道菜如期完成。
聞著怪味,我知道第一次就這么失敗了。
等她回家,一番檢討后,才知道是順序放錯(cuò)了。每道菜都應(yīng)該是從右往左依次放食材,即蔥->雞蛋->西紅柿。這是逗我的么!?一般人所理解的按默認(rèn)順序不應(yīng)該是從左往右嘛!
朋友們,到底應(yīng)該是從左往右還是從右往左?
剝雞蛋的故事
《格列佛游記》中記載了兩個(gè)征戰(zhàn)的強(qiáng)國(guó),你不會(huì)想到的是,他們打仗竟然和剝雞蛋的姿勢(shì)有關(guān)。
很多人認(rèn)為,剝雞蛋時(shí)應(yīng)該打破雞蛋較大的一端,這群人被稱作“大端(Big endian)派”。可是當(dāng)今皇帝的祖父小時(shí)候吃雞蛋的時(shí)候碰巧將一個(gè)手指弄破了。所以,他的父親(當(dāng)時(shí)的皇帝)就下令剝雞蛋必須打破雞蛋較小的一端,違令者重罰,由此產(chǎn)生了“小端(Little endian)派”。
老百姓們對(duì)這項(xiàng)命令極其反感,由此引發(fā)了6次叛亂,其中一個(gè)皇帝送了命,另一個(gè)丟了王位。據(jù)估計(jì),先后幾次有11000人情愿受死也不肯去打破雞蛋較小的一端!
看到?jīng)]有,僅僅是剝雞蛋就能產(chǎn)生這么大的分歧,“大端”和“小端”有這么重要嘛!
字節(jié)序
字節(jié)
字節(jié)(Byte)作為計(jì)算機(jī)世界的計(jì)量單位,和大家手中的人民幣多少多少“元”一個(gè)意思。反正,到了計(jì)算機(jī)的世界,說字節(jié)就對(duì)了,使用人家的基本計(jì)量單位,這是入鄉(xiāng)隨俗。
比如,一個(gè)電影是1G個(gè)字節(jié)(1GB),一首歌是10M個(gè)字節(jié)(10MB),一張圖片是1K個(gè)字節(jié)(1KB)。
字節(jié)序
一元錢可以干嘛?啥也干不了,公交都不夠坐的。一個(gè)字節(jié)可以干嘛?至少可以存一個(gè)字符。
當(dāng)數(shù)據(jù)太大,一個(gè)字節(jié)存不下的時(shí)候,我們就得使用多個(gè)字節(jié)了。比如,我有兩個(gè)分別需要4個(gè)字節(jié)存儲(chǔ)的整數(shù),為了方便說明,使用16進(jìn)制表示這兩個(gè)數(shù),即0x12345678和0x11223344。有的人采用以下方式存儲(chǔ)這個(gè)兩個(gè)數(shù)字:

這個(gè)方案看起來不錯(cuò),但是,又有人采用了以下方式:
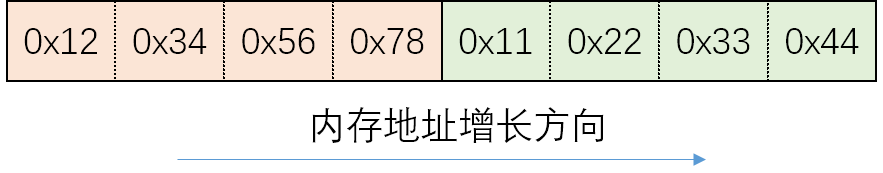
蒙圈了吧,到底該用哪一種方式來存!兩種方案雖有不同,但也有共識(shí),即依次存儲(chǔ)每一個(gè)數(shù)字,即先存0x12345678,再存0x11223344。大家的分歧在于,對(duì)于某一個(gè)要表示的值,因?yàn)橹荒芤粋€(gè)字節(jié)一個(gè)字節(jié)的存嘛,我是把值的低位存到低地址,還是把值的高位存到低地址。前者使用的是“小端(Little endian)”字節(jié)序,即先存低位的那一端(兩個(gè)數(shù)字的最低位分別是0x78、0x44),如上圖中的第一個(gè)圖;后者使用的是“大端(Big endian)”字節(jié)序,即先存高位的那一端(兩個(gè)數(shù)字的最高位分別是0x12、0x11),如上圖中的第二個(gè)圖。
由此也引發(fā)了計(jì)算機(jī)界的大端與小端之爭(zhēng),不同的CPU廠商并沒有達(dá)成一致:
x86,MOS Technology 6502,Z80,VAX,PDP-11等處理器為L(zhǎng)ittle endian。 Motorola 6800,Motorola 68000,PowerPC 970,System/370,SPARC(除V9外)等處理器為Big endian。 ARM, PowerPC (除PowerPC 970外), DEC Alpha, SPARC V9, MIPS, PA-RISC and IA64的字節(jié)序是可配置的。
大端也好,小端也罷,就權(quán)當(dāng)是個(gè)人愛好吧,只要你不影響別人就行,對(duì)不?
網(wǎng)絡(luò)字節(jié)序
前面的大端和小端都是在說計(jì)算機(jī)自己,也被稱作主機(jī)字節(jié)序。其實(shí),只要自己能夠自圓其說是沒啥問題的。問題是,網(wǎng)絡(luò)的出現(xiàn)使得計(jì)算機(jī)可以通信了。通信,就意味著相處,相處必須得有共同語言啊,得說普通話,要不然就容易會(huì)錯(cuò)意,下了一個(gè)小時(shí)的小電影發(fā)現(xiàn)打不開,理解錯(cuò)誤了!
但是每個(gè)計(jì)算機(jī)都有自己的主機(jī)字節(jié)序啊,還都不依不饒,堅(jiān)持做自己,怎么辦?
TCP/IP協(xié)議隆重出場(chǎng),RFC1700規(guī)定使用“大端”字節(jié)序?yàn)榫W(wǎng)絡(luò)字節(jié)序,其他不使用大端的計(jì)算機(jī)要注意了,發(fā)送數(shù)據(jù)的時(shí)候必須要將自己的主機(jī)字節(jié)序轉(zhuǎn)換為網(wǎng)絡(luò)字節(jié)序(即“大端”字節(jié)序),接收到的數(shù)據(jù)再轉(zhuǎn)換為自己的主機(jī)字節(jié)序。這樣就與CPU、操作系統(tǒng)無關(guān)了,實(shí)現(xiàn)了網(wǎng)絡(luò)通信的標(biāo)準(zhǔn)化。突然覺得,TCP/IP協(xié)議好任性啊有木有!
為了程序的兼容,你會(huì)看到,程序員們每次發(fā)送和接受數(shù)據(jù)都要進(jìn)行轉(zhuǎn)換,這樣做的目的是保證代碼在任何計(jì)算機(jī)上執(zhí)行時(shí)都能達(dá)到預(yù)期的效果。
這么常用的操作,BSD Socket提供了封裝好的轉(zhuǎn)換接口,方便程序員使用。包括從主機(jī)字節(jié)序到網(wǎng)絡(luò)字節(jié)序的轉(zhuǎn)換函數(shù):htons、htonl;從網(wǎng)絡(luò)字節(jié)序到主機(jī)字節(jié)序的轉(zhuǎn)換函數(shù):ntohs、ntohl。當(dāng)然,有了上面的理論基礎(chǔ),也可以編寫自己的轉(zhuǎn)換函數(shù)。
下面的一段代碼可以用來判斷計(jì)算機(jī)是大端的還是小端的,判斷的思路是確定一個(gè)多字節(jié)的值(下面使用的是4字節(jié)的整數(shù)),將其寫入內(nèi)存(即賦值給一個(gè)變量),然后用指針取其首地址所對(duì)應(yīng)的字節(jié)(即低地址的一個(gè)字節(jié)),判斷該字節(jié)存放的是高位還是低位,高位說明是Big endian,低位說明是Little endian。
#include <stdio.h>
int main ()
{
unsigned int x = 0x12345678;
char *c = (char*)&x;
if (*c == 0x78) {
printf("Little endian");
} else {
printf("Big endian");
}
return 0;
}
身邊的字節(jié)序
字符編碼方式UTF-16、UTF-32同樣面臨字節(jié)序的問題,因?yàn)樗麄兎謩e使用2個(gè)字節(jié)和4個(gè)字節(jié)編碼Unicode字符,一旦某個(gè)值用多個(gè)字節(jié)表示,就必須要考慮存儲(chǔ)的順序了。于是,采用了最簡(jiǎn)單粗暴的方式,給文件頭部寫幾個(gè)字符,用來表示是大端呢還是小端:
頭部的字符 編碼 字節(jié)序 FF FE UTF-16/UCS-2 Little endian FE FF UTF-16/UCS-2 Big endian FF FE 00 00 UTF-32/UCS-4 Little endian 00 00 FE FF UTF-32/UCS-4 Big-endian
這里不得不提一下UTF-8啊,明明人家是單個(gè)字節(jié)的,不存在什么字節(jié)序的問題。微軟為了統(tǒng)一UTF-X,硬生生給他的頭部也加了幾個(gè)字符!是的,這幾個(gè)字符就是BOM(Byte Order Mark),這就是Windows下的UTF-8。
相信很多人都被UTF-8的BOM給坑過,多了這個(gè)BOM的UTF-8文件,會(huì)導(dǎo)致很多問題啊。比如,寫的Shell腳本,內(nèi)容為#!/usr/bin/env bash,在UTF-8有BOM和UTF-8無BOM的編碼下,對(duì)應(yīng)的16進(jìn)制為:
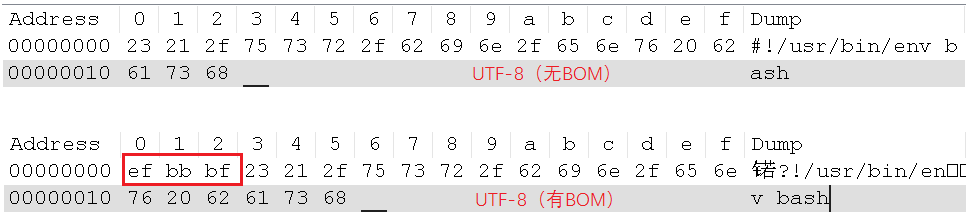
所以,有BOM的話,Shell解釋器就報(bào)錯(cuò)啦。原因在于,解釋器希望遇到#!/usr/bin/env bash,而使用UTF-8有BOM進(jìn)行編碼的內(nèi)容會(huì)多了3個(gè)字節(jié)的EF BB BF。
對(duì)于UTF-8和UTF-8無BOM兩種編碼格式,我們更多的使用UTF-8無BOM。