
用 SHAP 可視化解釋機(jī)器學(xué)習(xí)模型實(shí)用指南
大家好,我是云朵君!
導(dǎo)讀:?SHAP 是 Python 開發(fā)的一個(gè)"模型解釋"包,是一種博弈論方法來解釋任何機(jī)器學(xué)習(xí)模型的輸出。本文重點(diǎn)介紹 11 種 shap 可視化圖形來解釋任何機(jī)器學(xué)習(xí)模型的使用方法。具體理論并不在本次內(nèi)容內(nèi),需要了解模型理論的小伙伴,可參見文末參考文獻(xiàn)。本文因篇幅限制,分為上下兩篇,本篇介紹?shap 可視化特征重要性及特征效果。
??點(diǎn)擊關(guān)注|設(shè)為星標(biāo)|干貨速遞??
SHAP(Shapley Additive exPlanations)?使用來自博弈論及其相關(guān)擴(kuò)展的經(jīng)典 Shapley value將最佳信用分配與局部解釋聯(lián)系起來,是一種基于游戲理論上最優(yōu)的 Shapley value來解釋個(gè)體預(yù)測的方法。
從博弈論的角度,把數(shù)據(jù)集中的每一個(gè)特征變量當(dāng)成一個(gè)玩家,用該數(shù)據(jù)集去訓(xùn)練模型得到預(yù)測的結(jié)果,可以看成眾多玩家合作完成一個(gè)項(xiàng)目的收益。Shapley value 通過考慮各個(gè)玩家做出的貢獻(xiàn),來公平的分配合作的收益。
數(shù)據(jù)集
標(biāo)準(zhǔn)的 UCI 成人收入數(shù)據(jù)集。
import?shap
X,y?=?shap.datasets.adult()
X_display,?y_display?=?shap.datasets.adult(display=True)

創(chuàng)建 Explainer 并計(jì)算 SHAP 值
在SHAP中進(jìn)行模型解釋需要先創(chuàng)建一個(gè)?explainer,SHAP 支持很多類型的explainer(例如 deep, gradient, kernel, linear, tree, sampling),本文使用支持常用的XGB、LGB、CatBoost 等樹集成算法的 tree 為例。
- deep:用于計(jì)算深度學(xué)習(xí)模型,基于DeepLIFT算法
- gradient:用于深度學(xué)習(xí)模型,綜合了SHAP、集成梯度、和SmoothGrad等思想,形成單一期望值方程
- kernel:模型無關(guān),適用于任何模型
- linear:適用于特征獨(dú)立不相關(guān)的線性模型
- tree:適用于樹模型和基于樹模型的集成算法
- sampling :基于特征獨(dú)立性假設(shè),當(dāng)你想使用的后臺(tái)數(shù)據(jù)集很大時(shí),kenel的一個(gè)很好的替代方案
explainer?=?shap.TreeExplainer(model)??
然后計(jì)算shap_values值,計(jì)算非常簡單,直接利用上面得到的解釋器解釋訓(xùn)練樣本X,這里有兩種形式:
輸出 numpy.array 數(shù)組
shap_values?=?explainer.shap_values(X)?

輸出 shap.Explanation 對(duì)象
shap_values2?=?explainer(X)?

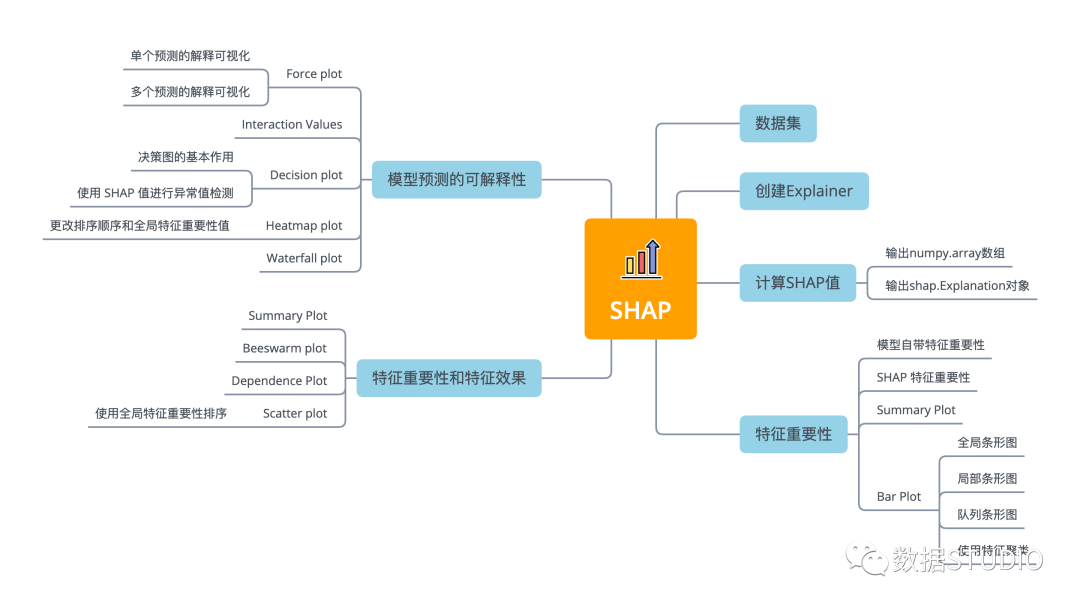
模型自帶特征重要性
關(guān)于模型解釋性,除了線性模型和決策樹這種天生就有很好解釋性的模型以外,sklean/ xgboost 中有很多模型都有 importance 這一接口,可以查看特征的重要性。
model?=?xgboost.XGBClassifier(eval_metric='mlogloss').fit(X,?y)
xgboost.plot_importance(model,height?=?.5,?
????????????????????????max_num_features=10,
????????????????????????show_values?=?False)
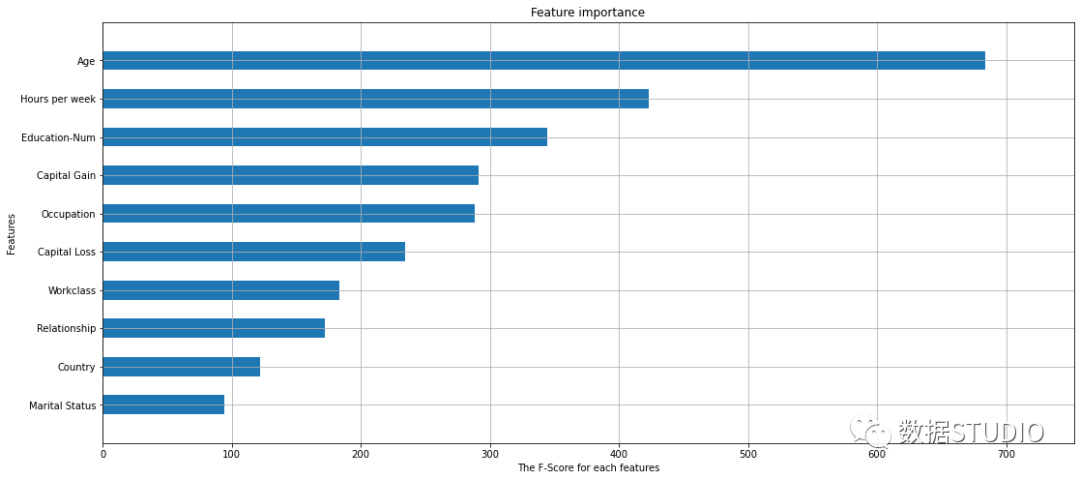
SHAP 特征重要性
Summary Plot
將 SHAP 值矩陣傳遞給條形圖函數(shù)會(huì)創(chuàng)建一個(gè)全局特征重要性圖,其中每個(gè)特征的全局重要性被視為該特征在所有給定樣本中的平均絕對(duì)值。
shap.summary_plot(shap_values,?X_display,?
??????????????????plot_type="bar")
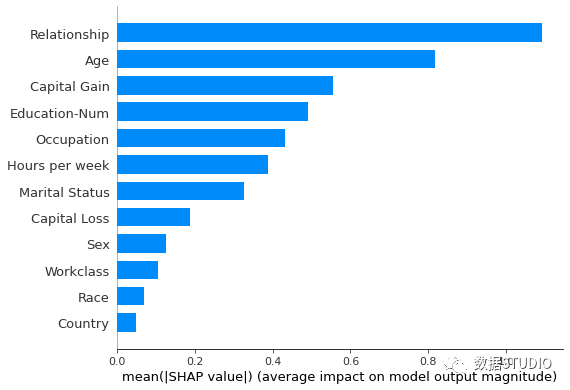
在上面兩圖中,可以看到由 SHAP value 計(jì)算的特征重要性與使用 scikit-learn / xgboost計(jì)算的特征重要性之間的比較,它們看起來非常相似,但它們并不相同。
Bar plot
全局條形圖
特征重要性的條形圖還有另一種繪制方法。
shap.plots.bar(shap_values2)
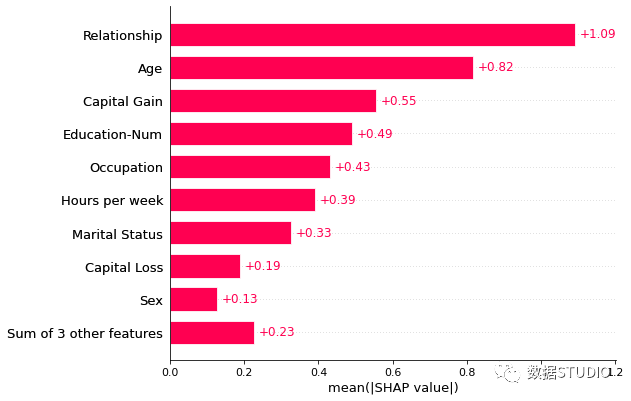
同一個(gè)
shap_values,不同的計(jì)算summary_plot中的shap_values是
numpy.array數(shù)組
plots.bar中的shap_values是shap.Explanation對(duì)象
當(dāng)然shap.plots.bar()還可以按照需求修改參數(shù),繪制不同的條形圖。如通過max_display參數(shù)進(jìn)行控制條形圖最多顯示條形樹數(shù)。
局部條形圖
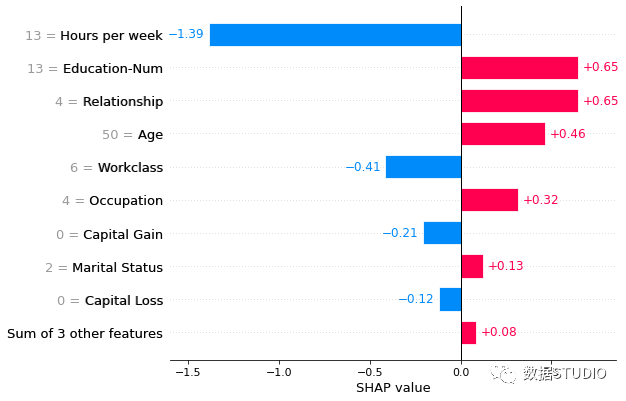
將一行 SHAP 值傳遞給條形圖函數(shù)會(huì)創(chuàng)建一個(gè)局部特征重要性圖,其中條形是每個(gè)特征的 SHAP 值。其中特征值是否顯示,是通過參數(shù)show_data控制,默認(rèn)?'auto'?特征值以灰色顯示在特征名稱的左側(cè)。
shap.plots.bar(shap_values2[1],?show_data=True)
隊(duì)列條形圖
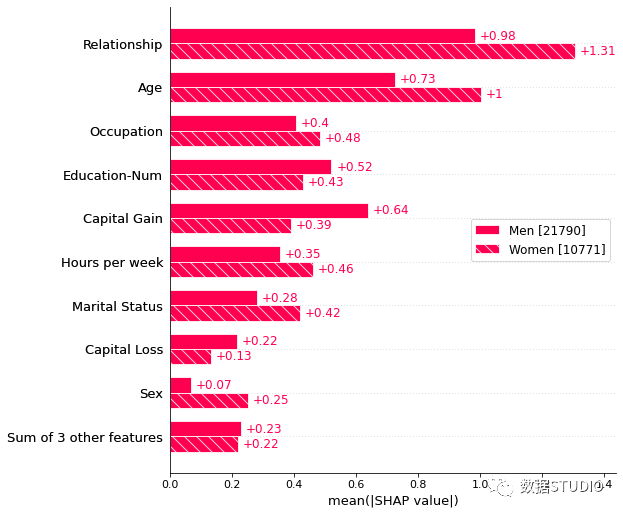
傳遞解釋對(duì)象的字典將為解釋對(duì)象表示的每個(gè)群組創(chuàng)建一個(gè)多條形圖,其中包含一個(gè)條形類型。下面我們使用它來分別繪制男性和女性特征重要性的全局摘要。
sex?=?["Women"?if?shap_values2[i,"Sex"].data?==?0?
???????else?"Men"?for?i?in?range(shap_values2.shape[0])]
shap.plots.bar(shap_values2.cohorts(sex).abs.mean(0))
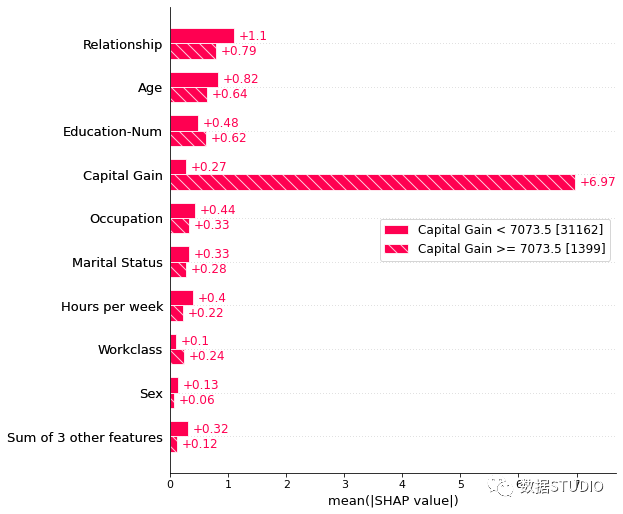
隊(duì)列條形圖還有另一個(gè)比較有意思的繪圖,他使用 Explanation 對(duì)象的自動(dòng)群組功能來使用決策樹創(chuàng)建一個(gè)群組。調(diào)用Explanation.cohorts(N)將創(chuàng)建 N 個(gè)隊(duì)列,使用 sklearn DecisionTreeRegressor 最佳地分離實(shí)例的 SHAP 值。
例如將其用于成人人口普查數(shù)據(jù),則看到低資本收益與高資本收益之間的明顯區(qū)別。括號(hào)中的數(shù)字是每個(gè)隊(duì)列中的實(shí)例數(shù)。
v?=?shap_values2.cohorts(2).abs.mean(0)
shap.plots.bar(v)
使用特征聚類
很多時(shí)候數(shù)據(jù)集中的特征存在冗余。這意味著模型可以使用任一特征并仍然獲得相同的準(zhǔn)確性。可以通過計(jì)算特征之間的相關(guān)矩陣,或使用聚類方法來找到這些特征。
在 SHAP 中通過模型損失比較來測量特征冗余。即使用shap.utils.hclust方法,并通過訓(xùn)練 XGBoost 模型來預(yù)測每對(duì)輸入特征的結(jié)果來構(gòu)建特征的層次聚類。與從無監(jiān)督方法(如相關(guān)性)中獲得的特征冗余相比。對(duì)典型的結(jié)構(gòu)化數(shù)據(jù)集進(jìn)行特征冗余度量,會(huì)更加準(zhǔn)確。
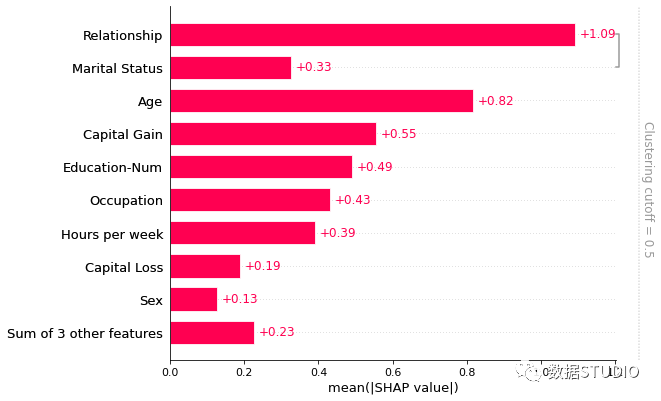
計(jì)算聚類并傳遞給條形圖,就可以同時(shí)可視化特征冗余結(jié)構(gòu)和特征重要性。默認(rèn)只會(huì)顯示距離 < 0.5 的聚類部分。假設(shè)聚類中的距離大致在 0 和 1 之間縮放,其中 0 距離表示特征完全冗余,1 表示它們完全獨(dú)立。
在下圖中,我們看到只有關(guān)系和婚姻狀況有超過 50% 的冗余,因此它們是條形圖中分組的唯一特征:
clustering?=?shap.utils.hclust(X,?y)?
shap.plots.bar(shap_values2,?
???????????????clustering=clustering,
???????????????clustering_cutoff=0.5)
Summary Plot
上面使用 Summary Plot 方法并設(shè)置參數(shù)plot_type="bar"繪制典型的特征重要性條形圖,而他默認(rèn)繪制 Summary_plot 圖,他是結(jié)合了特征重要性和特征效果,取代了條形圖。
Summary_plot 為每一個(gè)樣本繪制其每個(gè)特征的 Shapley value,它說明哪些特征最重要,以及它們對(duì)數(shù)據(jù)集的影響范圍。
y 軸上的位置由特征確定,x 軸上的位置由每 Shapley value 確定。顏色表示特征值(紅色高,藍(lán)色低),顏色使我們能夠匹配特征值的變化如何影響風(fēng)險(xiǎn)的變化。重疊點(diǎn)在 y 軸方向抖動(dòng),因此我們可以了解每個(gè)特征的 Shapley value分布,并且這些特征是根據(jù)它們的重要性排序的。
shap.summary_plot(shap_values,?X)
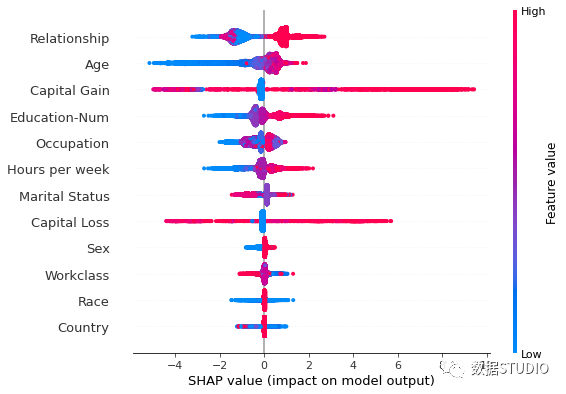
Beeswarm plot
同條形圖一樣?shap?也提供了另一個(gè)接口plots.beeswarm蜂群圖。
蜂群圖旨在顯示數(shù)據(jù)集中的 TOP 特征如何影響模型輸出的信息密集摘要。給定解釋的每個(gè)實(shí)例由每個(gè)特征流上的一個(gè)點(diǎn)表示。點(diǎn)的 x 位置由該特征的 SHAP 值 (?shap_values.value[instance,feature]) 確定,并且點(diǎn)沿每個(gè)特征行“堆積”以顯示密度。顏色用于顯示特征的原始值 (?shap_values.data[instance,feature])。
在下圖中,我們可以看到平均而言年齡是最重要的特征,與年輕(藍(lán)色)人相比,收入超過 5 萬美元的可能性較小。
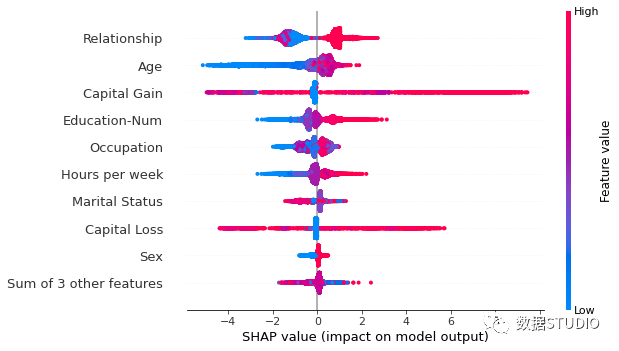
同樣可以使用max_display參數(shù)調(diào)整最多顯示行數(shù)。
默認(rèn)使用每個(gè)特征的 SHAP 值的平均絕對(duì)值shap_values.abs.mean(0)?對(duì)特征排序。然而,這個(gè)順序更強(qiáng)調(diào)廣泛的平均影響,而不是罕見但高強(qiáng)度的影響。如果我們想找到對(duì)個(gè)人影響較大的特征,可以按最大絕對(duì)值排序。
shap.plots.beeswarm(shap_values2,?
????????????????????order=shap_values.abs.max(0))
另外,在繪圖之前,就對(duì) shap_values 取絕對(duì)值,得到與條形圖類似的圖形,但比條形圖具有更豐富的平行線,因?yàn)闂l形圖只是繪制蜂群圖中點(diǎn)的平均值。
#?蜂群圖
shap.plots.beeswarm(shap_values2.abs,?
????????????????????color="shap_red")
#?條形圖
shap.plots.bar(shap_values2.abs.mean(0))
還可以自定義顏色,默認(rèn)使用shap.plots.colors.red_blue顏色圖。
import?matplotlib.pyplot?as?plt
shap.plots.beeswarm(shap_values,?
????????????????????color=plt.get_cmap("cool"))
在?Summary_plot?圖中,首先看到了特征值與對(duì)預(yù)測的影響之間關(guān)系的跡象,但是要查看這種關(guān)系的確切形式,還必須查看?SHAP Dependence Plot?圖。
Dependence Plot
SHAP Partial dependence plot (PDP or PD plot)?依賴圖顯示了一個(gè)或兩個(gè)特征對(duì)機(jī)器學(xué)習(xí)模型的預(yù)測結(jié)果的邊際效應(yīng),它可以顯示目標(biāo)和特征之間的關(guān)系是線性的、單調(diào)的還是更復(fù)雜的。他們在許多樣本中繪制了一個(gè)特征的值與該特征的?SHAP?值。
PDP?是一種全局方法:該方法考慮所有實(shí)例并給出關(guān)于特征與預(yù)測結(jié)果的全局關(guān)系。PDP?的一個(gè)假設(shè)是第一個(gè)特征與第二個(gè)特征不相關(guān)。如果違反此假設(shè),則?PDP?計(jì)算的平均值將包括極不可能甚至不可能的數(shù)據(jù)點(diǎn)。
為了顯示哪個(gè)特征可能會(huì)驅(qū)動(dòng)這些交互效應(yīng),可以通過第二個(gè)特征為我們的年齡依賴性散點(diǎn)圖著色(默認(rèn)第二個(gè)特征是自動(dòng)選擇的,嘗試挑選出與?Age?交互作用最強(qiáng)的特征列)。也可以通過參數(shù)interaction_index設(shè)置交互項(xiàng)。如果另一個(gè)特征與正在繪制的特征之間存在交互作用,它將顯示為不同的垂直著色模式。
shap.dependence_plot('Age',?shap_values,?X,?
?????????????????????display_features=X_display,
?????????????????????interaction_index='Capital?Gain')
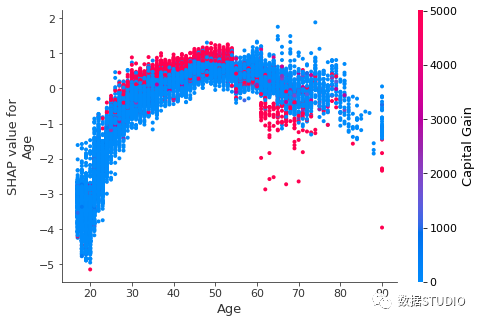
Dependence plot?是一個(gè)散點(diǎn)圖,顯示單個(gè)特征對(duì)整個(gè)數(shù)據(jù)集的影響。
- 每個(gè)點(diǎn)都是來自數(shù)據(jù)集的單個(gè)預(yù)測(行)。
- x 軸是數(shù)據(jù)集中的實(shí)際值。(來自 X 矩陣,存儲(chǔ)在 中
shap_values.data)。 - y 軸是該特征的 SHAP 值(存儲(chǔ)在 中
shap_values.values),它表示該特征值對(duì)該預(yù)測的模型輸出的改變程度。
Scatter plot
同樣,散點(diǎn)圖繪圖依賴圖,這與上面?dependence_plot?繪制基本一樣。
在顯示方面有些許不同,plots scatter?圖底部的淺灰色區(qū)域是顯示數(shù)據(jù)值分布的直方圖。
在交互顏色方面。dependence_plot?默認(rèn)而散點(diǎn)圖則需要將整個(gè)?Explanation?對(duì)象傳遞給?color?參數(shù)。
另外,有時(shí)候在輸入模型之前是字符串,為輸入到模型,需要將其設(shè)置為分類編碼,此時(shí)繪圖,并不能很直觀地顯示內(nèi)容。此時(shí)可以將.display_data?Explanation 對(duì)象的屬性設(shè)置為我們希望在圖中顯示的原始數(shù)據(jù)類型。
shap_values2.display_data?=?X_display.values
shap.plots.scatter(shap_values2[:,?"Age"],?
???????????????????color=shap_values2[:,"Workclass"])
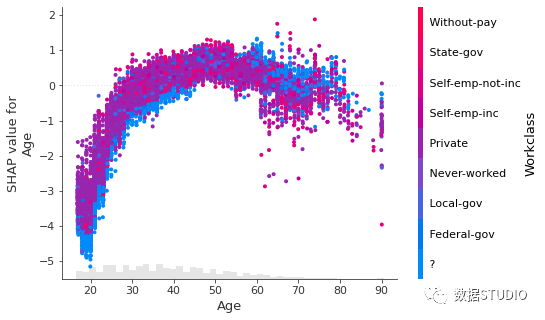
使用全局特征重要性排序
在只想繪制最重要的特征,卻不知道其特征名或索引,此時(shí)可以使用 Explanation 對(duì)象的點(diǎn)鏈功能來計(jì)算全局特征重要性的度量,按該度量(降序)排序,然后挑選出頂部特征。
#?平均絕對(duì)均值的特征
ind_mean?=?shap_values2.abs.mean(0).argsort[-1]
#?平均絕對(duì)值最大的特征
ind_max?=?shap_values.abs.max(0).argsort[-1]
#?95%?絕對(duì)值對(duì)特征進(jìn)行排序
ind_perc?=?shap_values.abs.percentile(95,?0).argsort[-1]
shap.plots.scatter(shap_values2[:,?ind_mean])
另外還可以自定義圖形屬性,詳情可參加官方文檔。敬請(qǐng)期待下篇。
參考文章??
[1] https://shap.readthedocs.io/en/latest/index.html
[2] https://www.bilibili.com/read/cv11622011