
【機器學(xué)習(xí)】SHAP- 機器學(xué)習(xí)模型解釋可視化工具
SHAP 是機器學(xué)習(xí)模型解釋可視化工具。在此示例中,使用 SHAP 計算使用 Python 和 scikit-learn 的神經(jīng)網(wǎng)絡(luò)的特征影響 。對于這個例子,使用 scikit-learn 的 糖尿病數(shù)據(jù)集,它是一個回歸數(shù)據(jù)集。首先安裝shap庫。
!pip?install?shap
然后,讓導(dǎo)入庫。
import?shap
from?sklearn.preprocessing?import?StandardScaler
from?sklearn.neural_network?import?MLPRegressor
from?sklearn.pipeline?import?make_pipeline
from?sklearn.datasets?import?load_diabetes
from?sklearn.model_selection?import?train_test_split
現(xiàn)在可以加載的數(shù)據(jù)集和特征名稱,這將在以后有用。
X,y?=?load_diabetes(return_X_y=True)
features?=?load_diabetes()['feature_names']
現(xiàn)在可以將數(shù)據(jù)集拆分為訓(xùn)練和測試。
X_train,?X_test,?y_train,?y_test?=?train_test_split(X,?y,?test_size=0.33,?random_state=42)
現(xiàn)在必須創(chuàng)建的模型。由于談?wù)摰氖巧窠?jīng)網(wǎng)絡(luò),必須提前對特征進行縮放。對于此示例,我將使用標(biāo)準(zhǔn)縮放器。該模型本身是一個前饋神經(jīng)網(wǎng)絡(luò),在隱藏層有 5 個神經(jīng)元,10000 個 epoch 和一個具有自適應(yīng)學(xué)習(xí)率的邏輯激活函數(shù)。在現(xiàn)實生活中,您將在設(shè)置這些值之前適當(dāng)?shù)貎?yōu)化這些超參數(shù)。
model?=?make_pipeline(
????StandardScaler(),
????MLPRegressor(hidden_layer_sizes=(5,),activation='logistic',???max_iter=10000,learning_rate='invscaling',random_state=0)
)
現(xiàn)在可以擬合的模型。
model.fit(X_train,y_train)
現(xiàn)在是 SHAP 部分。首先,需要創(chuàng)建一個名為explainer的對象。它是在輸入中接受模型的預(yù)測方法和訓(xùn)練數(shù)據(jù)集的對象。為了使 SHAP 模型與模型無關(guān),它圍繞訓(xùn)練數(shù)據(jù)集的點執(zhí)行擾動,并計算這種擾動對模型的影響。這是一種重采樣技術(shù),其樣本數(shù)量稍后設(shè)置。這種方法與另一種稱為 LIME 的著名方法有關(guān),該方法已被證明是原始 SHAP 方法的一個特例。結(jié)果是對 SHAP 值的統(tǒng)計估計。
所以,首先讓定義解釋器對象。
explainer?=?shap.KernelExplainer(model.predict,X_train)
現(xiàn)在可以計算形狀值。請記住,它們是通過對訓(xùn)練數(shù)據(jù)集重新采樣并計算對這些擾動的影響來計算的,因此必須定義適當(dāng)數(shù)量的樣本。對于此示例,我將使用 100 個樣本。
然后,在測試數(shù)據(jù)集上計算影響。
shap_values?=?explainer.shap_values(X_test,nsamples=100)
出現(xiàn)一個漂亮的進度條并顯示計算的進度,這可能很慢。
最后,得到一個 (n_samples,n_features) numpy 數(shù)組。每個元素都是該記錄的該特征的 shap 值。請記住,形狀值是針對每個特征和每個記錄計算的。
現(xiàn)在可以繪制“summary_plot”。
shap.summary_plot(shap_values,X_test,feature_names=features)
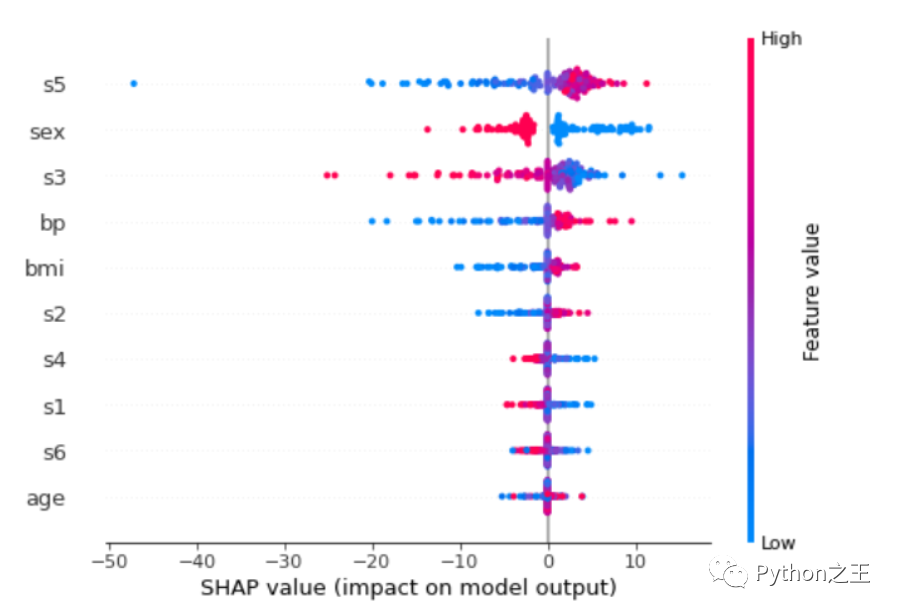
每行的每個點都是測試數(shù)據(jù)集的記錄。這些特征從最重要的一個到不太重要的排序。可以看到s5是最重要的特征。該特征的值越高,對目標(biāo)的影響越積極。該值越低,貢獻越負。
更深入地了解特定記錄,可以繪制的一個非常有用的圖稱為force_plot
shap.initjs()
shap.force_plot(explainer.expected_value,?shap_values[0,:]?,X_test[0,:],feature_names=features)

113.90 是預(yù)測值。基值是目標(biāo)變量在所有記錄中的平均值。每個條帶都顯示了其特征在將目標(biāo)變量的值推得更遠或更接近基值方面的影響。紅色條紋表明它們的特征將價值推向更高的價值。藍色條紋表明它們的特征將值推向較低的值。條紋越寬,貢獻越高(絕對值)。這些貢獻的總和將目標(biāo)變量的值從花瓶值推到最終的預(yù)測值。
對于這個特定的記錄,bmi、bp、s2、sex和s5值對預(yù)測值有正貢獻。s5仍然是這條記錄中最重要的變量,因為它的貢獻是最寬的(它具有最大的條帶)。唯一顯示負貢獻的變量是s1,但它不足以使預(yù)測值低于基值。因此,由于總的正貢獻(紅色條紋)大于負貢獻(藍色條紋),因此最終值大于基值。
往期精彩回顧