時(shí)間序列數(shù)據(jù)隨處可見(jiàn),要進(jìn)行時(shí)間序列分析,我們必須先對(duì)數(shù)據(jù)進(jìn)行預(yù)處理。時(shí)間序列預(yù)處理技術(shù)對(duì)數(shù)據(jù)建模的準(zhǔn)確性有重大影響。- 時(shí)間序列數(shù)據(jù)的定義及其重要性。
- 時(shí)間序列數(shù)據(jù)的預(yù)處理步驟。
- 構(gòu)建時(shí)間序列數(shù)據(jù),查找缺失值,對(duì)特征進(jìn)行去噪,并查找數(shù)據(jù)集中存在的異常值。
時(shí)間序列是在特定時(shí)間間隔內(nèi)記錄的一系列均勻分布的觀測(cè)值。
時(shí)間序列的一個(gè)例子是黃金價(jià)格。在這種情況下,我們的觀察是在固定時(shí)間間隔后一段時(shí)間內(nèi)收集的黃金價(jià)格。時(shí)間單位可以是分鐘、小時(shí)、天、年等。但是任何兩個(gè)連續(xù)樣本之間的時(shí)間差是相同的。時(shí)間序列數(shù)據(jù)預(yù)處理
時(shí)間序列數(shù)據(jù)包含大量信息,但通常是不可見(jiàn)的。與時(shí)間序列相關(guān)的常見(jiàn)問(wèn)題是無(wú)序時(shí)間戳、缺失值(或時(shí)間戳)、異常值和數(shù)據(jù)中的噪聲。在所有提到的問(wèn)題中,處理缺失值是最困難的一個(gè),因?yàn)閭鹘y(tǒng)的插補(bǔ)(一種通過(guò)替換缺失值來(lái)保留大部分信息來(lái)處理缺失數(shù)據(jù)的技術(shù))方法在處理時(shí)間序列數(shù)據(jù)時(shí)不適用。為了分析這個(gè)預(yù)處理的實(shí)時(shí)分析,我們將使用 Kaggle 的 Air Passenger 數(shù)據(jù)集。時(shí)間序列數(shù)據(jù)通常以非結(jié)構(gòu)化格式存在,即時(shí)間戳可能混合在一起并且沒(méi)有正確排序。另外在大多數(shù)情況下,日期時(shí)間列具有默認(rèn)的字符串?dāng)?shù)據(jù)類型,在對(duì)其應(yīng)用任何操作之前,必須先將數(shù)據(jù)時(shí)間列轉(zhuǎn)換為日期時(shí)間數(shù)據(jù)類型。讓我們將其實(shí)現(xiàn)到我們的數(shù)據(jù)集中:import pandas as pd
passenger = pd.read_csv('AirPassengers.csv')
passenger['Date'] = pd.to_datetime(passenger['Date'])
passenger.sort_values(by=['Date'], inplace=True, ascending=True)
時(shí)間序列中的缺失值
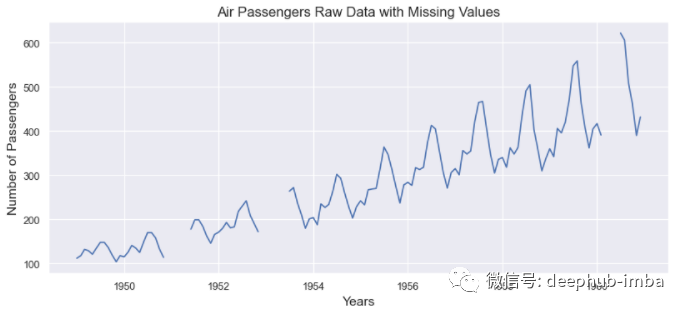
處理時(shí)間序列數(shù)據(jù)中的缺失值是一項(xiàng)具有挑戰(zhàn)性的任務(wù)。傳統(tǒng)的插補(bǔ)技術(shù)不適用于時(shí)間序列數(shù)據(jù),因?yàn)榻邮罩档捻樞蚝苤匾榱私鉀Q這個(gè)問(wèn)題,我們有以下插值方法:插值是一種常用的時(shí)間序列缺失值插補(bǔ)技術(shù)。它有助于使用周圍的兩個(gè)已知數(shù)據(jù)點(diǎn)估計(jì)丟失的數(shù)據(jù)點(diǎn)。這種方法簡(jiǎn)單且最直觀。處理時(shí)序數(shù)據(jù)時(shí)可以使用以下的方法:讓我們看看我們的數(shù)據(jù)在插補(bǔ)之前的樣子:from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
figure(figsize=(12, 5), dpi=80, linewidth=10)
plt.plot(passenger['Date'], passenger['Passengers'])
plt.title('Air Passengers Raw Data with Missing Values')
plt.xlabel('Years', fontsize=14)
plt.ylabel('Number of Passengers', fontsize=14)
plt.show()
passenger[‘Linear’] = passenger[‘Passengers’].interpolate(method=’linear’)
passenger[‘Spline order 3’] = passenger[‘Passengers’].interpolate(method=’spline’, order=3)
passenger[‘Time’] = passenger[‘Passengers’].interpolate(method=’time’)
methods = ['Linear', 'Spline order 3', 'Time']
from matplotlib.pyplot import figure
import matplotlib.pyplot as plt
for method in methods:
? figure(figsize=(12, 4), dpi=80, linewidth=10)
? plt.plot(passenger["Date"], passenger[method])
? plt.title('Air Passengers Imputation using: ' + types)
? plt.xlabel("Years", fontsize=14)
? plt.ylabel("Number of Passengers", fontsize=14)
? plt.show()
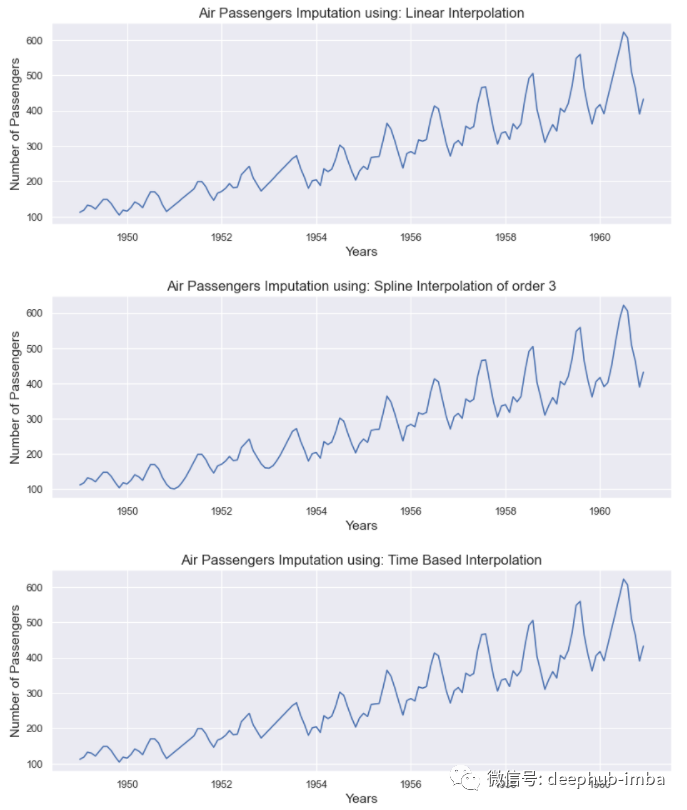
所有的方法都給出了還不錯(cuò)的結(jié)果。當(dāng)缺失值窗口(缺失數(shù)據(jù)的寬度)很小時(shí),這些方法更有意義。但是如果丟失了幾個(gè)連續(xù)的值,這些方法就更難估計(jì)它們。
時(shí)間序列去噪
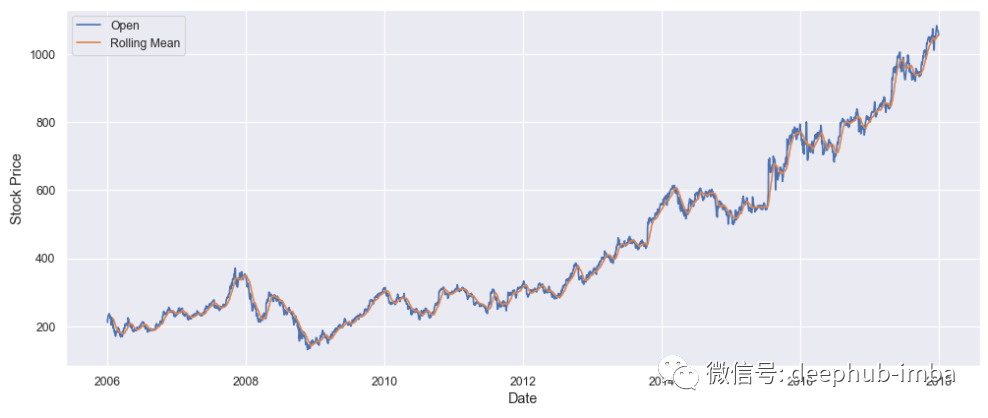
時(shí)間序列中的噪聲元素可能會(huì)導(dǎo)致嚴(yán)重問(wèn)題,所以一般情況下在構(gòu)建任何模型之前都會(huì)有去除噪聲的操作。最小化噪聲的過(guò)程稱為去噪。以下是一些通常用于從時(shí)間序列中去除噪聲的方法:滾動(dòng)平均值是先前觀察窗口的平均值,其中窗口是來(lái)自時(shí)間序列數(shù)據(jù)的一系列值。為每個(gè)有序窗口計(jì)算平均值。這可以極大地幫助最小化時(shí)間序列數(shù)據(jù)中的噪聲。讓我們?cè)诠雀韫善眱r(jià)格上應(yīng)用滾動(dòng)平均值:rolling_google = google_stock_price['Open'].rolling(20).mean()
plt.plot(google_stock_price['Date'], google_stock_price['Open'])
plt.plot(google_stock_price['Date'], rolling_google)
plt.xlabel('Date')
plt.ylabel('Stock Price')
plt.legend(['Open','Rolling Mean'])
plt.show()
傅里葉變換可以通過(guò)將時(shí)間序列數(shù)據(jù)轉(zhuǎn)換到頻域來(lái)幫助去除噪聲,我們可以過(guò)濾掉噪聲頻率。然后應(yīng)用傅里葉反變換得到濾波后的時(shí)間序列。我們用傅里葉變換來(lái)計(jì)算谷歌股票價(jià)格。denoised_google_stock_price = fft_denoiser(value, 0.001, True)
plt.plot(time, google_stock['Open'][0:300])
plt.plot(time, denoised_google_stock_price)
plt.xlabel('Date', fontsize = 13)
plt.ylabel('Stock Price', fontsize = 13)
plt.legend([‘Open’,’Denoised: 0.001'])
plt.show()

時(shí)間序列中的離群值檢測(cè)
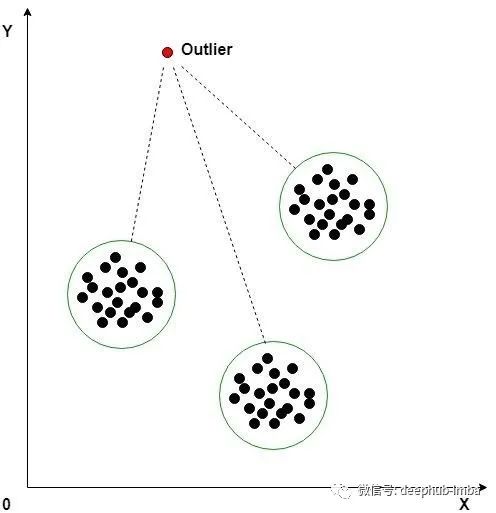
時(shí)間序列中的離群值是指趨勢(shì)線的突然高峰或下降。導(dǎo)致離群值可能有多種因素。讓我們看一下檢測(cè)離群值的可用方法:基于滾動(dòng)統(tǒng)計(jì)的方法這種方法最直觀,適用于幾乎所有類型的時(shí)間序列。在這種方法中,上限和下限是根據(jù)特定的統(tǒng)計(jì)量度創(chuàng)建的,例如均值和標(biāo)準(zhǔn)差、Z 和 T 分?jǐn)?shù)以及分布的百分位數(shù)。例如,我們可以將上限和下限定義為:取整個(gè)序列的均值和標(biāo)準(zhǔn)差是不可取的,因?yàn)樵谶@種情況下,邊界將是靜態(tài)的。邊界應(yīng)該在滾動(dòng)窗口的基礎(chǔ)上創(chuàng)建,就像考慮一組連續(xù)的觀察來(lái)創(chuàng)建邊界,然后轉(zhuǎn)移到另一個(gè)窗口。該方法是一種高效、簡(jiǎn)單的離群點(diǎn)檢測(cè)方法。
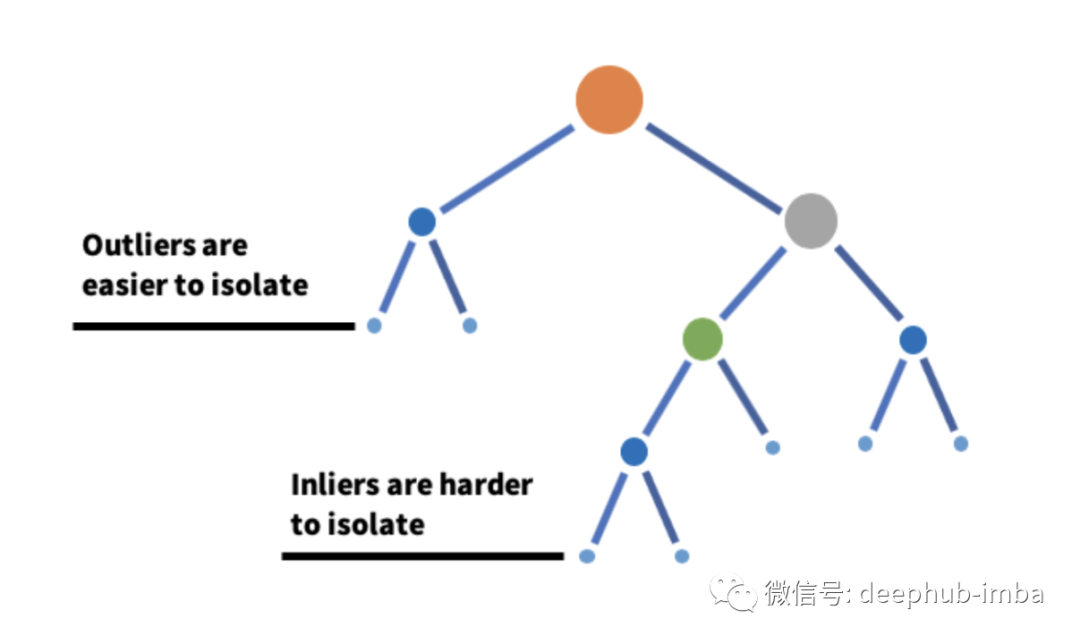
顧名思義,孤立森林是一種基于決策樹的異常檢測(cè)機(jī)器學(xué)習(xí)算法。它通過(guò)使用決策樹的分區(qū)隔離給定特征集上的數(shù)據(jù)點(diǎn)來(lái)工作。換句話說(shuō),它從數(shù)據(jù)集中取出一個(gè)樣本,并在該樣本上構(gòu)建樹,直到每個(gè)點(diǎn)都被隔離。為了隔離數(shù)據(jù)點(diǎn),通過(guò)選擇該特征的最大值和最小值之間的分割來(lái)隨機(jī)進(jìn)行分區(qū),直到每個(gè)點(diǎn)都被隔離。特征的隨機(jī)分區(qū)將為異常數(shù)據(jù)點(diǎn)在樹中創(chuàng)建更短的路徑,從而將它們與其余數(shù)據(jù)區(qū)分開(kāi)來(lái)。K-means 聚類是一種無(wú)監(jiān)督機(jī)器學(xué)習(xí)算法,經(jīng)常用于檢測(cè)時(shí)間序列數(shù)據(jù)中的異常值。該算法查看數(shù)據(jù)集中的數(shù)據(jù)點(diǎn),并將相似的數(shù)據(jù)點(diǎn)分組為 K 個(gè)聚類。通過(guò)測(cè)量數(shù)據(jù)點(diǎn)到其最近質(zhì)心的距離來(lái)區(qū)分異常。如果距離大于某個(gè)閾值,則將該數(shù)據(jù)點(diǎn)標(biāo)記為異常。K-Means 算法使用歐幾里得距離進(jìn)行比較。可能的面試問(wèn)題
如果一個(gè)人在簡(jiǎn)歷中寫了一個(gè)關(guān)于時(shí)間序列的項(xiàng)目,那么面試官可以從這個(gè)主題中提出這些可能的問(wèn)題:- 預(yù)處理時(shí)間序列數(shù)據(jù)的方法有哪些,與標(biāo)準(zhǔn)插補(bǔ)方法有何不同?
- 你聽(tīng)說(shuō)過(guò)孤立森林嗎?如果是,那么你能解釋一下它是如何工作的嗎?
- 什么是傅立葉變換,我們?yōu)槭裁葱枰?/span>
- 填充時(shí)間序列數(shù)據(jù)中缺失值的不同方法是什么?
總結(jié)
在本文中,我們研究了一些常見(jiàn)的時(shí)間序列數(shù)據(jù)預(yù)處理技術(shù)。我們從排序時(shí)間序列觀察開(kāi)始;然后研究了各種缺失值插補(bǔ)技術(shù)。因?yàn)槲覀兲幚淼氖且唤M有序的觀察結(jié)果,所以時(shí)間序列插補(bǔ)與傳統(tǒng)插補(bǔ)技術(shù)不同。此外,還將一些噪聲去除技術(shù)應(yīng)用于谷歌股票價(jià)格數(shù)據(jù)集,最后討論了一些時(shí)間序列的異常值檢測(cè)方法。使用所有這些提到的預(yù)處理步驟可確保高質(zhì)量數(shù)據(jù),為構(gòu)建復(fù)雜模型做好準(zhǔn)備。加入知識(shí)星球【我們談?wù)摂?shù)據(jù)科學(xué)】
500+小伙伴一起學(xué)習(xí)!
·?推薦閱讀?·
盤點(diǎn)2021最佳數(shù)據(jù)可視化作品
「Python實(shí)用秘技04」pdf文件批量添加文字水印
新一代Python包管理工具來(lái)了