
基于Transformer對透明物體進行分割
點擊上方“小白學視覺”,選擇加"星標"或“置頂”
重磅干貨,第一時間送達


本研究提出了一個新的細粒度透明對象分割數(shù)據(jù)集,稱為Trans10Kv2,擴展了Trans10K-v1,第一個大規(guī)模透明對象分割數(shù)據(jù)集。不像Trans10K-v1只有兩個有限的類別,作者的新數(shù)據(jù)集有幾個吸引人的好處。(1)它有11個細粒度的透明對象類別,通常發(fā)生在人類的家庭環(huán)境中,使它更適合于現(xiàn)實世界的應用。(2) Trans10K-v2對現(xiàn)有的高級分割方法帶來了比以前版本更多的挑戰(zhàn)。此外,提出了一種新的基于變壓器的分割管道Trans2Seg。首先,Trans2Seg的變壓器編碼器相對于CNN的局部接受場提供了全局接受場,這顯示了相對于純CNN架構的優(yōu)異優(yōu)勢。其次,作者將語義分割制定為一個字典查找問題,設計了一組可學習的原型作為Trans2Seg s變壓器解碼器的查詢,每個原型學習整個數(shù)據(jù)集中一個類別的統(tǒng)計信息。作者對20多種最新的語義分割方法進行了評測,結果表明Trans2Seg算法的性能明顯優(yōu)于所有基于cnn的方法,表明了本文提出的算法在解決透明對象分割問題上的潛在能力。
開源代碼:https://github.com/xieenze/Trans2Seg
作者提出了最大的玻璃分割數(shù)據(jù)集(Trans10K-v2),包含11種不同場景和高分辨率的細粒度玻璃圖像類別。所有的圖片都用精細的遮罩和面向功能的分類精心標注。
提出了一種基于變壓器的透明物體分割網絡,該網絡采用變壓器編解碼結構。該方法提供了一個全局的接受域,在掩模預測中具有更強的動態(tài)性,具有很好的優(yōu)越性。
作者在Trans10K-v2上評估了20多種語義分割方法,作者的Trans2Seg顯著優(yōu)于這些方法。此外,作者還表明,這一任務在很大程度上尚未解決。因此需要更多的研究。
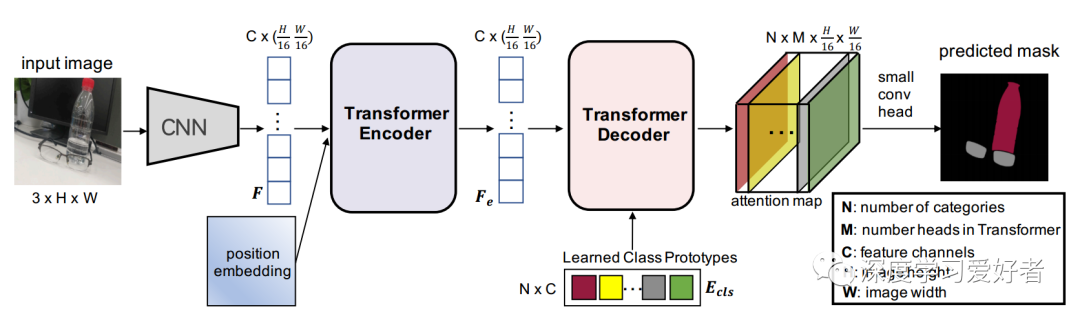
作者的CNN-Transformer混合架構。首先,將輸入圖像輸入到CNN,提取特征F。其次,對于變壓器編碼器,將特征和位置嵌入平滑后饋給Transformer進行自我注意,并從變壓器編碼器輸出特征(Fe)。第三,針對Transforme解碼器,作者專門定義了一組可學習類原型嵌入(Ecls)作為查詢,F(xiàn)e作為鍵,并利用Ecls和Fe計算注意圖。每個類的原型嵌入對應一個最終預測的類別。作者還添加了一個小的conv頭來融合來自CNN骨干的注意力地圖和Res2特征。變壓器解碼器和小錐頭詳見圖4。最后,通過對注意圖進行像素級argmax,得到預測結果。例如,在這個圖中,兩個類別(瓶子和眼鏡)的分割掩模對應著兩個相同顏色的類原型。
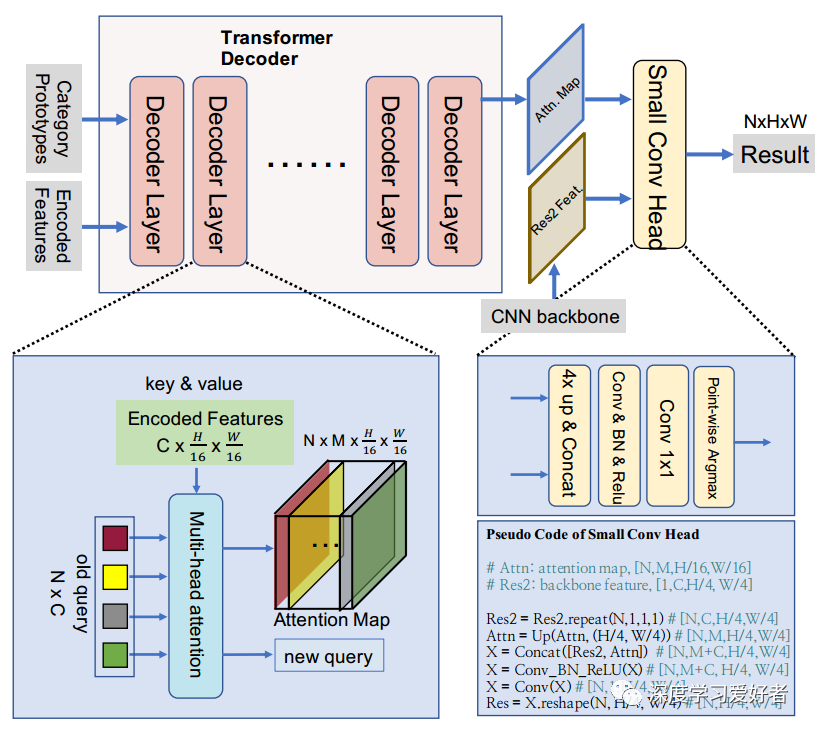
Transformer解碼器詳細圖。輸入:可學習的類別原型作為查詢,從Transformer編碼器的特性作為鍵和值。輸入被饋送到變壓器解碼器,它由幾個解碼器層組成。最后一個解碼器層的注意圖和CNN骨干網的Res2特征相結合,并饋給一個小的conv頭,得到最終的預測結果。為了更好的理解,作者還提供了小錐頭的偽代碼。輸入:可學習的類別原型作為查詢,從變壓器編碼器的特性作為鍵和值。輸入被饋送到Transformer解碼器,它由幾個解碼器層組成。最后一個解碼器層的注意圖和CNN骨干網的Res2特征相結合,并饋給一個小的conv頭,得到最終的預測結果。
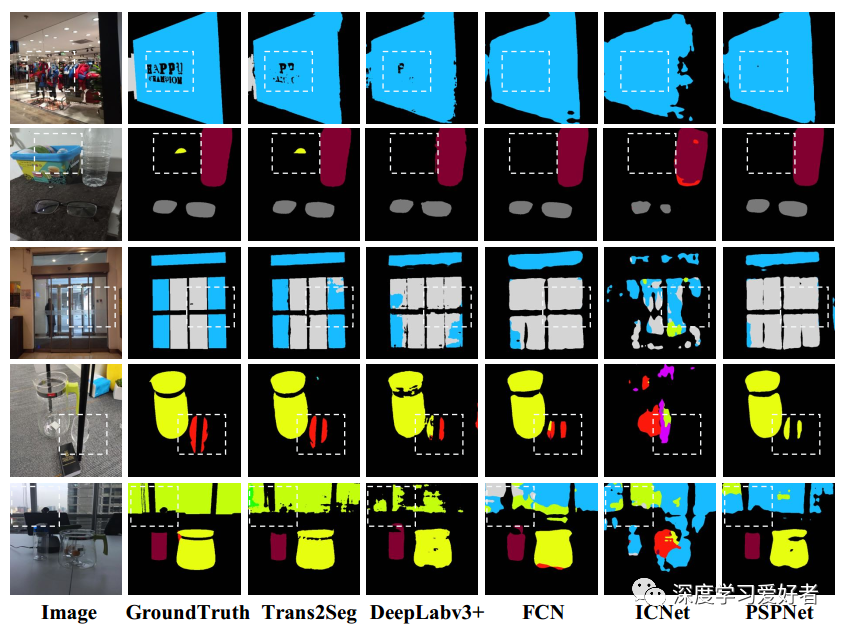
Trans2Seg與其他基于CNN的語義分割方法的視覺比較。輸入:可學習的類別原型作為查詢,從變壓器編碼器的特性作為鍵和值。輸入被饋送到Transformer解碼器,它由幾個解碼器層組成。最后一個解碼器層的注意圖和CNN骨干網的Res2特征相結合,并饋給一個小的conv頭,得到最終的預測結果。為了更好的理解,作者還提供了小錐頭的偽代碼。Trans2Seg的整體感受場和注意機制,特別是在dash區(qū)域,明顯優(yōu)于其他組。放大以獲得最佳視野。更多可視化結果請參考補充材料。
在本文中,作者提出了一個新的細粒度透明對象分割數(shù)據(jù)集,包含11個常見類別,稱為Trans10K-v2,其中數(shù)據(jù)是基于之前的Trans10K。輸入:可學習的類別原型作為查詢,從Transformer編碼器的特性作為鍵和值。輸入被饋送到Transformer解碼器,它由幾個解碼器層組成。最后一個解碼器層的注意圖和CNN骨干網的Res2特征相結合,并饋給一個小的conv頭,得到最終的預測結果。為了更好的理解,作者還提供了小錐頭的偽代碼。作者也討論了提出的數(shù)據(jù)集的挑戰(zhàn)性和實用性。此外,作者提出了一種基于變壓器的管道,稱為Trans2Seg,以解決這一具有挑戰(zhàn)性的任務。在Trans2Seg中,Transformer編碼器提供了全局接收域,這是透明對象分割的必要條件。在transformer解碼器中,作者將分割建模為使用一組可學習查詢的字典查找,其中每個查詢代表一個類別。最后,作者評估了超過20種主流的語義分割方法,并表明作者的Trans2Seg明顯優(yōu)于這些基于CNN的分割方法。
在未來,作者有興趣探索作者的Transformer編碼器-解碼器設計的一般分割任務,如城市景觀和PASCAL VOC。作者也會投入更多的精力來解決透明對象的分割任務。
論文鏈接:https://arxiv.org/pdf/2101.08461.pdf
每日堅持論文分享不易,如果喜歡我們的內容,希望可以推薦或者轉發(fā)給周圍的同學。
- END -

交流群
歡迎加入公眾號讀者群一起和同行交流,目前有SLAM、三維視覺、傳感器、自動駕駛、計算攝影、檢測、分割、識別、醫(yī)學影像、GAN、算法競賽等微信群(以后會逐漸細分),請掃描下面微信號加群,備注:”昵稱+學校/公司+研究方向“,例如:”張三 + 上海交大 + 視覺SLAM“。請按照格式備注,否則不予通過。添加成功后會根據(jù)研究方向邀請進入相關微信群。請勿在群內發(fā)送廣告,否則會請出群,謝謝理解~