
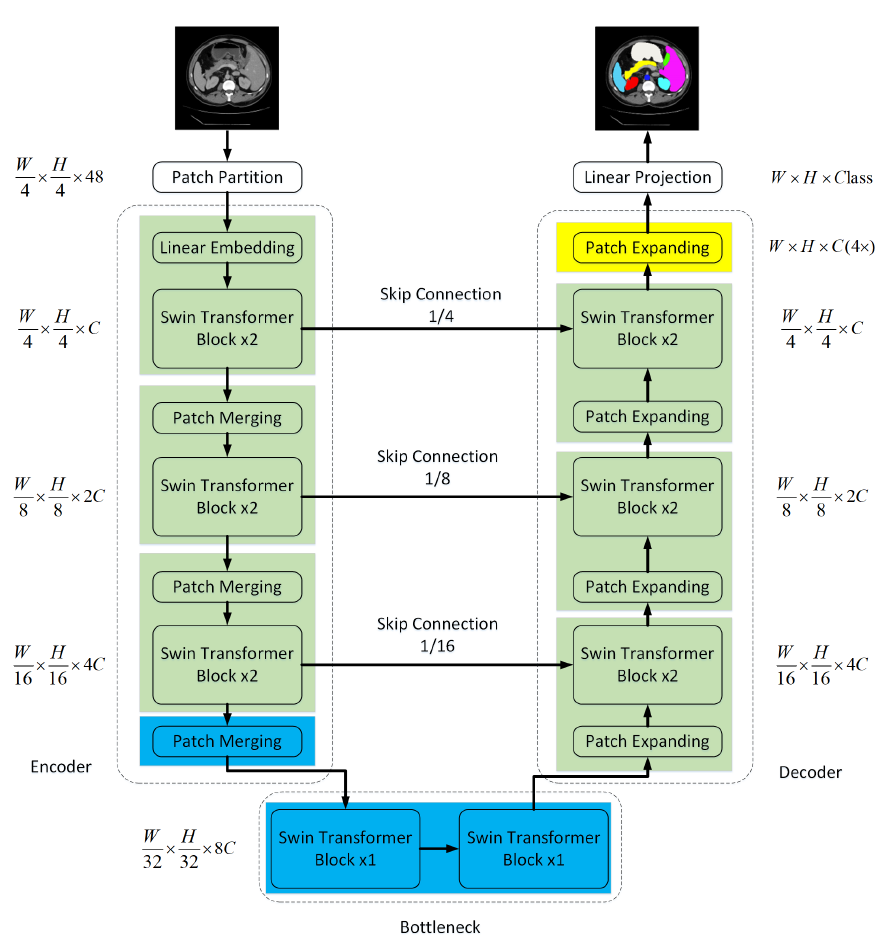
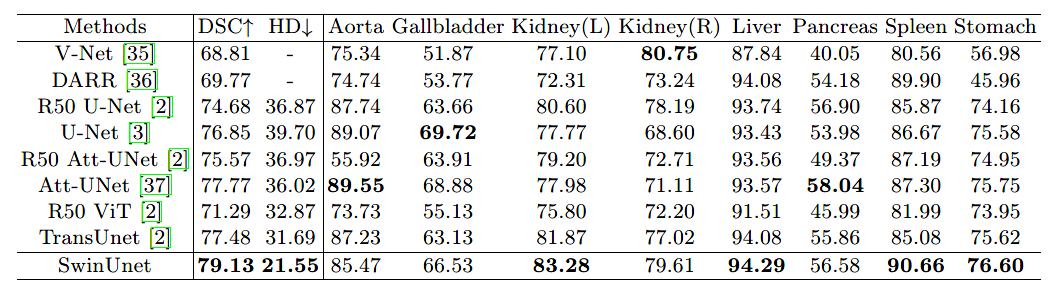
Swin-UNet:基于純 Transformer 結(jié)構(gòu)的語(yǔ)義分割網(wǎng)絡(luò)
Visual Transformer
Author:louwill
Machine Learning Lab


往期精彩:
Swin Transformer:基于Shifted Windows的層次化視覺(jué)Transformer設(shè)計(jì)
TransUNet:基于 Transformer 和 CNN 的混合編碼網(wǎng)絡(luò)
SETR:基于視覺(jué) Transformer 的語(yǔ)義分割模型
ViT:視覺(jué)Transformer backbone網(wǎng)絡(luò)ViT論文與代碼詳解
【原創(chuàng)首發(fā)】機(jī)器學(xué)習(xí)公式推導(dǎo)與代碼實(shí)現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學(xué)習(xí)語(yǔ)義分割理論與實(shí)戰(zhàn)指南.pdf
求個(gè)在看
評(píng)論
圖片
表情