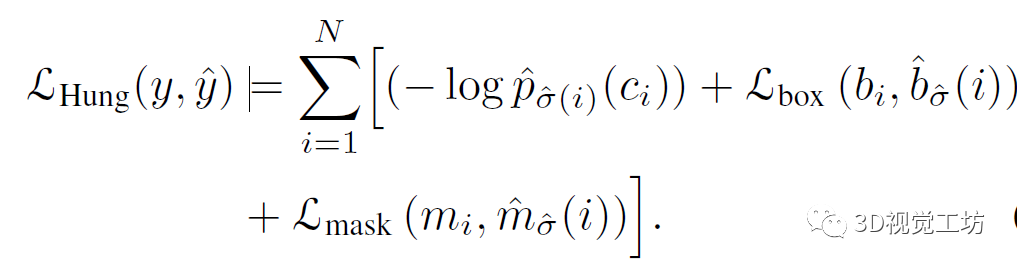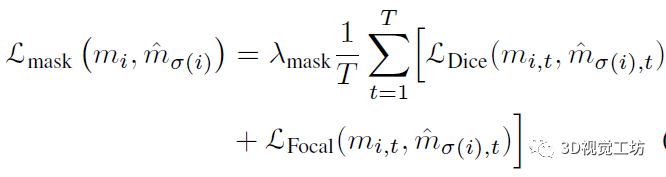點(diǎn)擊上方“AI算法與圖像處理”,選擇加"星標(biāo)"或“置頂”
重磅干貨,第一時(shí)間送達(dá)
原文:End-to-End Video Instance Segmentation with Transformers
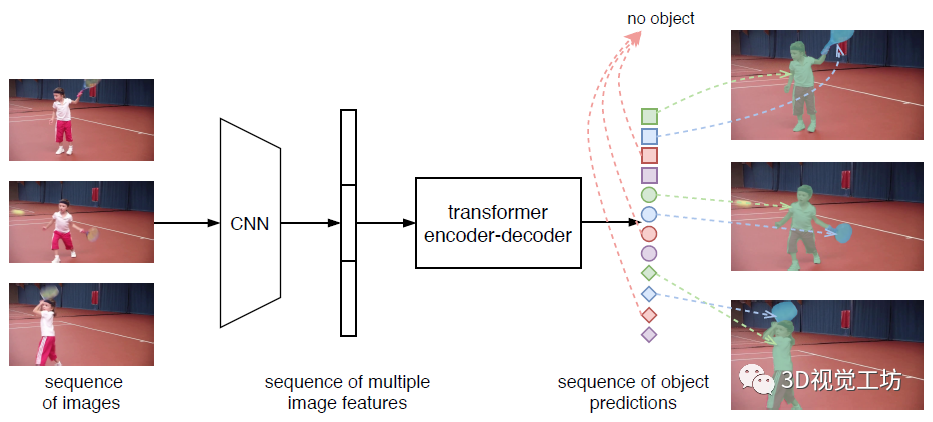
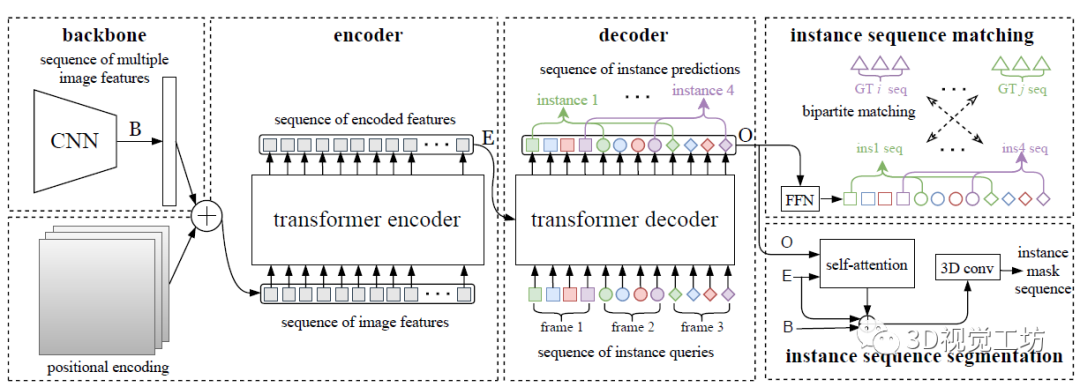
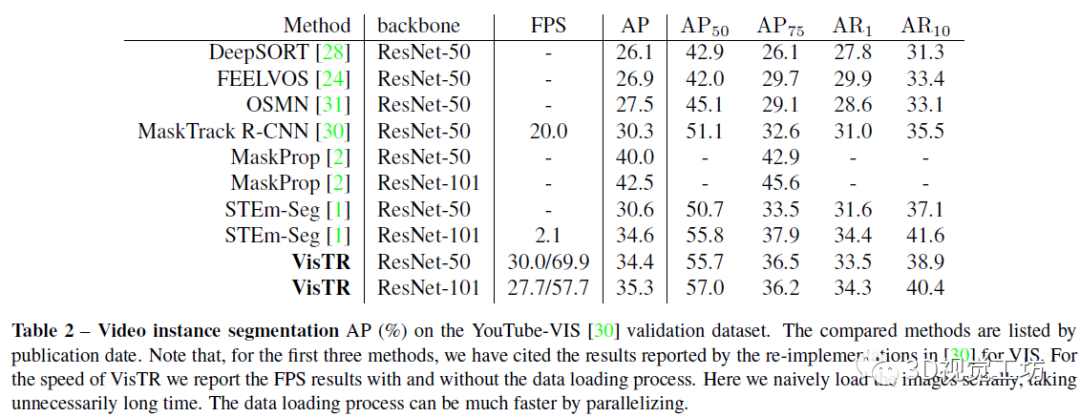
視頻實(shí)例分割(VIS)是一項(xiàng)需要同時(shí)對(duì)視頻中感興趣的對(duì)象實(shí)例進(jìn)行分類、分割和跟蹤的任務(wù)。最近研究人員提出了一個(gè)新的基于Transformers的視頻實(shí)例分割框架VisTR,它將VIS任務(wù)看作一個(gè)直接的端到端并行序列解碼/預(yù)測問題。給定一個(gè)由多個(gè)圖像幀組成的視頻片段作為輸入,VisTR直接輸出視頻中每個(gè)實(shí)例的掩碼序列。其核心是一種新的、有效的instance sequence匹配與分割策略,它在序列級(jí)對(duì)實(shí)例進(jìn)行整體監(jiān)控和分割。VisTR從相似性學(xué)習(xí)的角度對(duì)實(shí)例進(jìn)行分割和跟蹤,大大簡化了整個(gè)流程,與現(xiàn)有方法有很大的不同。VisTR在現(xiàn)有的VIS模型中速度最高,在YouTubeVIS數(shù)據(jù)集上使用單一模型的方法中效果最好。這是第一次,研究人員展示了一個(gè)更簡單,更快的視頻實(shí)例分割框架建立在Transformer,實(shí)現(xiàn)了競爭的準(zhǔn)確性。研究人員希望VisTR能推動(dòng)未來更多的視頻理解任務(wù)的研究。?研究人員提出了一個(gè)新的基于Transformers的視頻實(shí)例分割框架,稱為VisTR,它將VIS任務(wù)視為一個(gè)直接的端到端并行序列解碼/預(yù)測問題。該框架與現(xiàn)有方法大不相同,大大簡化了整個(gè)流程。?VisTR從相似性學(xué)習(xí)的新角度解決了VIS。實(shí)例分割就是學(xué)習(xí)像素級(jí)的相似度,實(shí)例跟蹤就是學(xué)習(xí)實(shí)例之間的相似度。因此,在相同的實(shí)例分割框架下,可以無縫、自然地實(shí)現(xiàn)實(shí)例跟蹤。?VisTR成功的關(guān)鍵是為研究人員的框架定制了一種新的instance sequence匹配和分割策略。這個(gè)精心設(shè)計(jì)的2策略使研究人員能夠在整個(gè)序列級(jí)別上對(duì)實(shí)例進(jìn)行監(jiān)控和分段。?VisTR在YouTube VIS數(shù)據(jù)集上取得了很好的效果,在mask mAP中以27.7 FPS的速度(如果排除數(shù)據(jù)加載,則為57.7 FPS)獲得了35.3%的效果,這是使用單一模型的方法中最好、最快的。研究人員將視頻實(shí)例分割問題建模為一個(gè)直接的序列預(yù)測問題。給定由多個(gè)圖像幀組成的視頻片段作為輸入,VisTR按順序輸出視頻中每個(gè)實(shí)例的掩碼序列。為了實(shí)現(xiàn)這一目標(biāo),研究人員引入了instance sequence匹配和分割策略,在序列級(jí)對(duì)實(shí)例進(jìn)行整體監(jiān)控和分割。整個(gè)VisTR架構(gòu)如上圖所示。它由四個(gè)主要部分組成:一個(gè)用于提取多幀壓縮特征表示的CNN backbone、一個(gè)用于建立像素級(jí)相似性建模的編碼-解碼的transformer、一個(gè)用于監(jiān)控模型的instance sequence matching模塊和一個(gè)instance sequence segmentation模塊。1)Backbone:Backbone提取輸入視頻片段的原始像素級(jí)特征序列,提取每一幀的特征并將所有的特征圖聯(lián)系在一起。2)Transformer encoder:采用編碼器對(duì)圖像中所有像素級(jí)特征的相似性進(jìn)行建模,建模視頻內(nèi)每一個(gè)像素之間的相似性。首先使用11的卷積對(duì)輸入的特征圖張量進(jìn)行降維。然后對(duì)特征圖從空間和時(shí)間上展平到一維。3)Temporal and spatial positional encoding:Transformer的結(jié)構(gòu)是排列不變的,而分割任務(wù)需要精確的位置信息。為了補(bǔ)償這一點(diǎn),研究人員用固定的位置編碼信息來補(bǔ)充特征,這些信息包含三維(時(shí)間、水平和垂直)位置信息,然后再關(guān)聯(lián)在一起。4)Transformer decoder:Transformer解碼器的目標(biāo)是解碼能夠代表每幀實(shí)例的像素特征。受DETR的啟發(fā),研究人員還引入了固定數(shù)量的輸入嵌入來從像素特征中查詢實(shí)例特征,稱為instance queries。這些instance queries是通過模型學(xué)習(xí)得到的。編碼器的輸入為預(yù)設(shè)的instance queries和編碼器的輸出。這樣,預(yù)測的結(jié)果按照原始視頻幀序列的順序輸出,輸出為nT個(gè)instance向量,即學(xué)習(xí)到的instance queries。Instance Sequence Matching:VisTR在一次通過解碼器的過程中推斷出N個(gè)預(yù)測的固定大小序列。該框架的主要挑戰(zhàn)之一是保持同一實(shí)例在不同圖像(即instance sequence)中預(yù)測的相對(duì)位置。為了找到相應(yīng)的ground truth并對(duì)instance sequence進(jìn)行整體監(jiān)控,引入了instance sequence匹配策略。解碼器輸出的固定個(gè)數(shù)的預(yù)測序列是無序的,每一幀包含n個(gè)instance sequence。本論文和DETR相同,利用匈牙利算法進(jìn)行匹配。ViTR采用了和DETR類似的方法,雖然是實(shí)例分割,但需要用到目標(biāo)檢測中的bounding box方便組合優(yōu)化計(jì)算。通過FFN,即全連接計(jì)算出歸一化的bounding box中心,寬和高。通過softmax計(jì)算出該bounding box的標(biāo)簽。最后得到n×T個(gè)bounding box。利用上述得到label概率分布和bounding box匹配instance sequence和gournd truth。最后計(jì)算匈牙利算法的loss,同時(shí)考慮label的概率分布以及bounding box的位置。Loss基本遵循DETR的設(shè)計(jì),使用L1 loss和IOU loss。下式為訓(xùn)練用的loss。由label,bounding box,instance sequence三者的loss組成。Instance Sequence Segmentation:Instance sequence分割模塊的目標(biāo)是預(yù)測每個(gè)實(shí)例的掩碼序列。為了實(shí)現(xiàn)這一點(diǎn),該模型首先對(duì)每個(gè)實(shí)例進(jìn)行mask features的積累,然后對(duì)積累的特征進(jìn)行掩模序列分割。通過計(jì)算對(duì)象預(yù)測O和Transformer編碼特征E之間的相似度映射得到mask features。為了簡化計(jì)算,研究人員只對(duì)每個(gè)對(duì)象預(yù)測使用其對(duì)應(yīng)幀的特征進(jìn)行計(jì)算。對(duì)于每一幀,對(duì)象預(yù)測O和相應(yīng)的編碼特征映射E被饋送到模塊中以獲得初始attention maps。然后attention maps將與對(duì)應(yīng)幀的初始backbone的特征B和變換后的編碼特征E融合,遵循與DETR類似的實(shí)踐。融合的最后一層是可變形卷積層。通過這種方式,獲得不同幀的每個(gè)實(shí)例的mask features。在本節(jié)中,研究人員在YouTubeVIS[30]數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn),該數(shù)據(jù)集包含2238個(gè)訓(xùn)練、302個(gè)驗(yàn)證和343個(gè)測試視頻剪輯。數(shù)據(jù)集的每個(gè)視頻都用每像素分割掩碼、類別和實(shí)例標(biāo)簽進(jìn)行注釋。對(duì)象類別號(hào)為40。當(dāng)測試集評(píng)估結(jié)束時(shí),研究人員在驗(yàn)證集中評(píng)估研究人員的方法。評(píng)價(jià)指標(biāo)為平均精度(AP)和平均召回率(AR),以mask sequences的視頻交集為閾值。在下表中,研究人員將VisTR與一些最新的視頻實(shí)例分割方法進(jìn)行了比較。從精度和速度兩方面進(jìn)行了比較。前三行中的方法最初用于跟蹤或VOS。研究人員引用了其他研究中針對(duì)VIS的重新實(shí)現(xiàn)所報(bào)告的結(jié)果。其他方法包括MaskTrack RCNN、MaskProp和STEmSeg最初是按時(shí)間順序?yàn)閂IS任務(wù)提出的。下圖顯示了YouTube VIS驗(yàn)證數(shù)據(jù)集上VisTR的可視化,每一行包含從同一視頻中采樣的圖像。VisTR可以很好地跟蹤和分割具有挑戰(zhàn)性的實(shí)例,例如:(a)實(shí)例重疊,(b)實(shí)例之間相對(duì)位置的變化,(c)由相近的同類實(shí)例引起的混淆和(d)不同姿勢(shì)的實(shí)例。本文提出了一種基于Transformers的視頻實(shí)例分割框架,將VIS任務(wù)看作一個(gè)直接的端到端并行序列解碼/預(yù)測問題。VisTR從相似性學(xué)習(xí)的新角度解決了VIS問題。因此,在相同的實(shí)例分割框架下,可以無縫、自然地實(shí)現(xiàn)實(shí)例跟蹤。該框架與現(xiàn)有方法大不相同,也比現(xiàn)有方法簡單,大大簡化了整個(gè)流程。通過大量的實(shí)驗(yàn)來研究和驗(yàn)證VisTR的核心因素。在YouTube-VIS數(shù)據(jù)集上,VisTR在使用單一模型的方法中取得了最好的結(jié)果和最高的速度。據(jù)研究人員所知,研究人員的工作是第一個(gè)將Transformer應(yīng)用于視頻實(shí)例分割。研究人員希望類似的方法可以應(yīng)用到更多的視頻理解任務(wù)中請(qǐng)注明:地區(qū)+學(xué)校/企業(yè)+研究方向+昵稱
下載1:何愷明頂會(huì)分享
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):何愷明,即可下載。總共有6份PDF,涉及 ResNet、Mask RCNN等經(jīng)典工作的總結(jié)分析
下載2:終身受益的編程指南:Google編程風(fēng)格指南
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):c++,即可下載。歷經(jīng)十年考驗(yàn),最權(quán)威的編程規(guī)范!
在「AI算法與圖像處理」公眾號(hào)后臺(tái)回復(fù):CVPR,即可下載1467篇CVPR 2020論文 和 CVPR 2021 最新論文
點(diǎn)亮  ,告訴大家你也在看
,告訴大家你也在看