
用Python手寫五大經(jīng)典排序算法,看完這篇終于懂了!
點擊關注上方“SQL數(shù)據(jù)庫開發(fā)”,
設為“置頂或星標”,第一時間送達干貨
算法作為程序員的必修課,是每位程序員必須掌握的基礎。作為Python忠實愛好者,本篇東哥將通過Python來手撕5大經(jīng)典排序算法,結(jié)合例圖剖析內(nèi)部實現(xiàn)邏輯,對比每種算法各自的優(yōu)缺點和應用點。相信我,耐心看完絕對有收獲。
前戲準備
大家都知道從理論上講,我們一般會使用大O表示法測量算法的運行時復雜度。"大O表示法"表示程序的執(zhí)行時間或占用空間隨數(shù)據(jù)規(guī)模的增長趨勢。
但為了測算具體的時間,本篇將使用timeit模塊來衡量實現(xiàn)的運行時間。下面自己寫一個對算法測試時間的函數(shù)。
from?random?import?randint
from?timeit?import?repeat
def?run_sorting_algorithm(algorithm,?array):
????#?調(diào)用特定的算法對提供的數(shù)組執(zhí)行。
????#?如果不是內(nèi)置sort()函數(shù),那就只引入算法函數(shù)。
????setup_code?=?f"from?__main__?import?{algorithm}"?\
????????if?algorithm?!=?"sorted"?else?""
????stmt?=?f"{algorithm}({array})"
????#?十次執(zhí)行代碼,并返回以秒為單位的時間
????times?=?repeat(setup=setup_code,?stmt=stmt,?repeat=3,?number=10)
????#?最后,顯示算法的名稱和運行所需的最短時間
????print(f"Algorithm:?{algorithm}.?Minimum?execution?time:?{min(times)}")
這里用到了一個騷操作,通過f-strings魔術方法導入了算法名稱,不懂的可以自行查看使用方法。
注意:應該找到算法每次運行的平均時間,而不是選擇單個最短時間。由于系統(tǒng)同時運行其他進程,因此時間測量是受影響的。最短的時間肯定是影響最小的,是這樣才使其成為算法時間最短的。
Python中的冒泡排序算法
冒泡排序是最直接的排序算法之一。它的名稱來自算法的工作方式:每經(jīng)過一次新的遍歷,列表中最大的元素就會“冒泡”至正確位置。
在Python中實現(xiàn)冒泡排序
這是Python中冒泡排序算法的實現(xiàn):
def?bubble_sort(array):
?????n?=?len(array)
?
?????for?i?in?range(n):
?????????#?創(chuàng)建一個標識,當沒有可以排序的時候就使函數(shù)終止。
?????????already_sorted?=?True
?
?????????#?從頭開始逐個比較相鄰元素,每一次循環(huán)的總次數(shù)減1,
?????????#?因為每次循環(huán)一次,最后面元素的排序就確定一個。
?????????for?j?in?range(n?-?i?-?1):
?????????????if?array[j]?>?array[j?+?1]:
?????????????????#?如果此時的元素大于相鄰后一個元素,那么交換。
?????????????????array[j],?array[j?+?1]?=?array[j?+?1],?array[j]
?
?????????????????#?如果有了交換,設置already_sorted標志為False算法不會提前停止
?????????????????already_sorted?=?False
?
?????????#?如果最后一輪沒有交換,數(shù)據(jù)已經(jīng)排序完畢,退出
?????????if?already_sorted:
?????????????break
?
?????return?array
為了正確分析算法的工作原理,看下這個列表[8, 2, 6, 4, 5]。假設使用bubble_sort()排序,下圖說明了算法每次迭代時數(shù)組的實際換件情況:
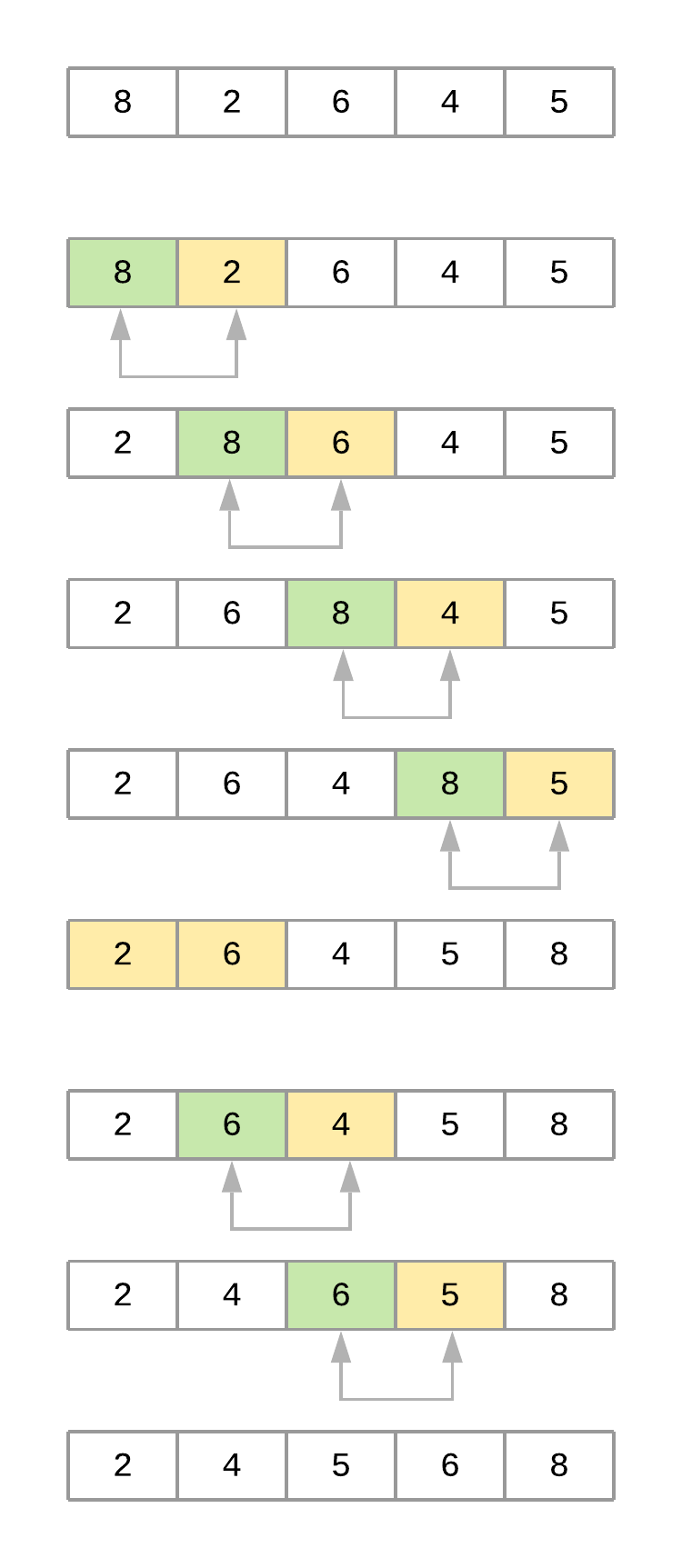
冒泡排序的實現(xiàn)由兩個嵌套for循環(huán)組成,其中算法先執(zhí)行n-1個比較,然后進行n-2個比較,依此類推,直到完成最終比較。因此,總的比較次數(shù)為(N - 1)+(N - 2)+(N - 3)+ ... + 2 + 1 = N(N-1)/ 2,也可以寫成 ?n?2?- ?n。
去掉不會隨數(shù)據(jù)規(guī)模n而變化的常量,可以將符號簡化為 n2?-n。由于 n2的增長速度快于n,因此也可以舍棄最后一項,使冒泡排序的平均和最壞情況下的時間復雜度為 O(n?2)。
在算法接收到已排序的數(shù)組的情況下,運行時間復雜度將降低到更好的O(n),因為算法循環(huán)一遍沒有任何交換,標志是true,所以循環(huán)一遍比較了N次直接退出。因此,O(n)是冒泡排序的最佳情況運行時間復雜度。但最好的情況是個例外,比較不同的算法時,應該關注平均情況。
冒泡排序的時間運行測試
使用run_sorting_algorithm()測試冒泡排序處理具有一萬個元素的數(shù)組所花費的時間。
ARRAY_LENGTH?=?10000if?__name__?==?"__main__":
?????#?生成包含“?ARRAY_LENGTH”個元素的數(shù)組,元素是介于0到999之間的隨機整數(shù)值
?????array?=?[randint(0,?1000)?for?i?in?range(ARRAY_LENGTH)]
?
?????#?使用排序算法的名稱和剛創(chuàng)建的數(shù)組調(diào)用該函數(shù)
?????run_sorting_algorithm(algorithm="bubble_sort",?array=array)
現(xiàn)在運行腳本來獲取bubble_sort的執(zhí)行時間:
$?python?sorting.py
Algorithm:?bubble_sort.?Minimum?execution?time:?73.21720498399998分析冒泡排序的優(yōu)缺點
冒泡排序算法的主要優(yōu)點是它的簡單性,理解起來非常簡單。但也看到了冒泡排序的缺點是速度慢,運行時間復雜度為O(n?2)。因此,一般對大型數(shù)組進行排序的時候,不會考慮使用冒泡排序。
Python中的插入排序算法
像冒泡排序一樣,插入排序算法也易于實現(xiàn)和理解。但是與冒泡排序不同,它通過將每個元素與列表的其余元素進行比較并將其插入正確的位置,來一次構(gòu)建一個排序的列表元素。此“插入”過程為算法命名。
一個例子,就是對一副紙牌進行排序。將一張卡片與其余卡片進行逐個比較,直到找到正確的位置為止,然后重復進行直到您手中的所有卡都被排序。
在Python中實現(xiàn)插入排序
插入排序算法的工作原理與紙牌排序完全相同,Python中的實現(xiàn):
??def?insertion_sort(array):
????#?從數(shù)據(jù)第二個元素開始循環(huán),直到最后一個元素
????for?i?in?range(1,?len(array)):
????????#?這個是我們想要放在正確位置的元素
????????key_item?=?array[i]
????????#?初始化變量,用于尋找元素正確位置
????????j?=?i?-?1
????????#?遍歷元素左邊的列表元素,一旦key_item比被比較元素小,那么找到正確位置插入。
????????while?j?>=?0?and?array[j]?>?key_item:
????????????#?把被檢測元素向左平移一個位置,并將j指向下一個元素(從右向左)
????????????array[j?+?1]?=?array[j]
????????????j?-=?1
????????#?當完成元素位置的變換,把key_item放在正確的位置上
????????array[j?+?1]?=?key_item
????return?array
下圖顯示了對數(shù)組進行排序時算法的不同迭代[8, 2, 6, 4, 5]:
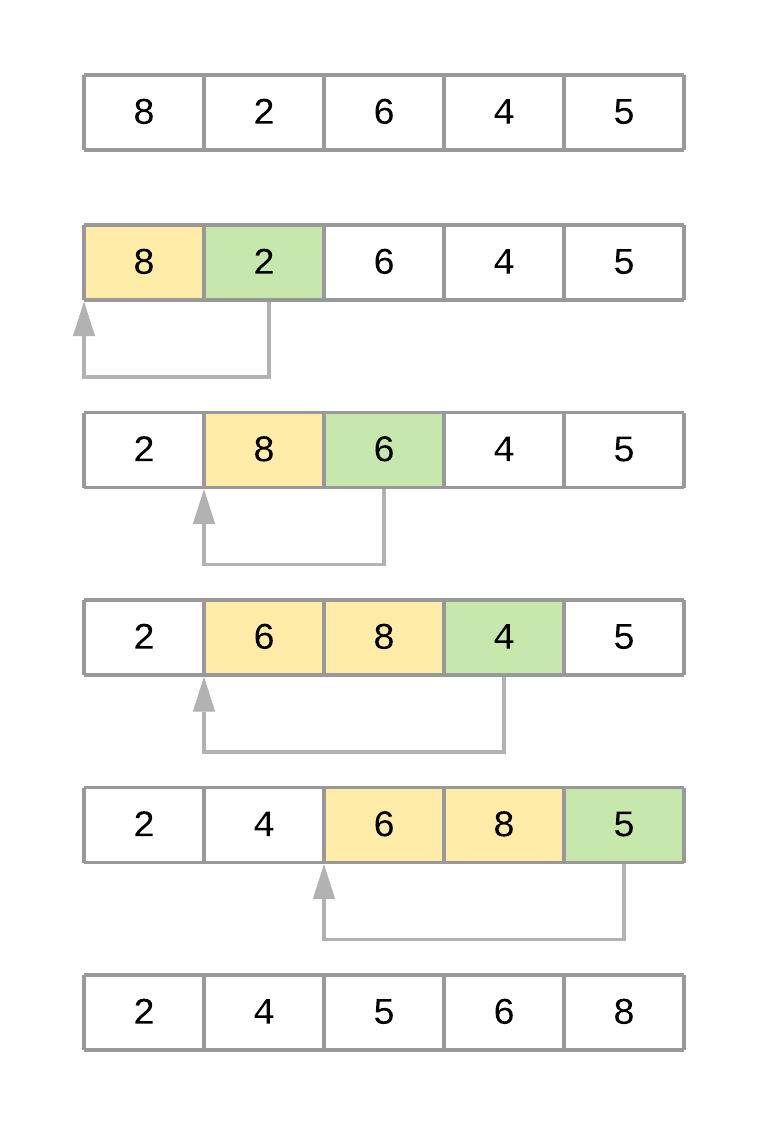
插入排序過程
測量插入排序的大O時間復雜度
與冒泡排序?qū)崿F(xiàn)類似,插入排序算法具有兩個嵌套循環(huán),遍歷整個列表。內(nèi)部循環(huán)非常有效,因為它會遍歷列表,直到找到元素的正確位置為止。
最壞的情況發(fā)生在所提供的數(shù)組以相反順序排序時。在這種情況下,內(nèi)部循環(huán)必須執(zhí)行每個比較,以將每個元素放置在正確的位置。這仍然給您帶來O(n2)運行時復雜性。
最好的情況是對提供的數(shù)組進行了排序。這里,內(nèi)部循環(huán)永遠不會執(zhí)行,導致運行時復雜度為O(n),就像冒泡排序的最佳情況一樣。
盡管冒泡排序和插入排序具有相同的大O時間復雜度,但實際上,插入排序比冒泡排序有效得多。如果查看兩種算法的實現(xiàn),就會看到插入排序是如何減少了對列表進行排序的比較次數(shù)的。
插入排序時間測算
為了證明插入排序比冒泡排序更有效,可以對插入排序算法進行計時,并將其與冒泡排序的結(jié)果進行比較。調(diào)用我們寫好的測試函數(shù)。
??if?__name__?==?"__main__":
?????#?生成包含“?ARRAY_LENGTH”個元素的數(shù)組,元素是介于0到999之間的隨機整數(shù)值
?????array?=?[randint(0,?1000)?for?i?in?range(ARRAY_LENGTH)]
?
?????#?使用排序算法的名稱和剛創(chuàng)建的數(shù)組調(diào)用該函數(shù)
????run_sorting_algorithm(algorithm="insertion_sort",?array=array)
執(zhí)行腳本:
??$?python?sorting.py
Algorithm:?insertion_sort.?Minimum?execution?time:?56.71029764299999
可以看到,插入排序比冒泡排序?qū)崿F(xiàn)少了17秒,即使它們都是O(n 2)算法,插入排序也更加有效。
分析插入排序的優(yōu)點和缺點
就像冒泡排序一樣,插入排序算法的實現(xiàn)也很簡單。盡管插入排序是O(n 2)算法,但在實踐中它也比其他二次實現(xiàn)(例如冒泡排序)更有效。
有更強大的算法,包括合并排序和快速排序,但是這些實現(xiàn)是遞歸的,在處理小型列表時通常無法擊敗插入排序。如果列表足夠小,可以提供更快的整體實現(xiàn),則某些快速排序?qū)崿F(xiàn)甚至在內(nèi)部使用插入排序。Timsort還在內(nèi)部使用插入排序?qū)斎霐?shù)組的一小部分進行排序。
也就是說,插入排序不適用于大型陣列,這為可以更有效地擴展規(guī)模的算法打開了大門。
Python中的合并排序算法
合并排序是一種非常有效的排序算法。它基于分治法,這是一種用于解決復雜問題的強大算法技術。
要正確理解分而治之,應該首先了解遞歸的概念。遞歸涉及將問題分解成較小的子問題,直到它們足夠小以至于無法解決。在編程中,遞歸通常由調(diào)用自身的函數(shù)表示。
分而治之算法通常遵循相同的結(jié)構(gòu):
原始輸入分為幾個部分,每個部分代表一個子問題,該子問題與原始輸入相似,但更為簡單。每個子問題都遞歸解決。所有子問題的解決方案都組合成一個整體解決方案。在合并排序的情況下,分而治之方法將輸入值的集合劃分為兩個大小相等的部分,對每個一半進行遞歸排序,最后將這兩個排序的部分合并為一個排序列表。
在Python中實現(xiàn)合并排序
合并排序算法的實現(xiàn)需要兩個不同的部分:
遞歸地將輸入分成兩半的函數(shù) 合并兩個半部的函數(shù),產(chǎn)生一個排序數(shù)組 這是合并兩個不同數(shù)組的代碼:
def?merge(left,?right):
??#?如果第一個數(shù)組為空,那么不需要合并,
??#?可以直接將第二個數(shù)組返回作為結(jié)果
??if?len(left)?==?0:
??????return?right
? #?如果第二個數(shù)組為空,那么不需要合并,
??#?可以直接將第一個數(shù)組返回作為結(jié)果
??if?len(right)?==?0:
??????return?left
??result?=?[]
??index_left?=?index_right?=?0
??#?查看兩個數(shù)組直到所有元素都裝進結(jié)果數(shù)組中
??while?len(result)???????#?這些需要排序的元素要依次被裝入結(jié)果列表,因此需要決定將從
??????#?第一個還是第二個數(shù)組中取下一個元素
??????if?left[index_left]?<=?right[index_right]:
??????????result.append(left[index_left])
??????????index_left?+=?1
??????else:
??????????result.append(right[index_right])
??????????index_right?+=?1
??????#?如果哪個數(shù)組達到了最后一個元素,那么可以將另外一個數(shù)組的剩余元素
??????#?裝進結(jié)果列表中,然后終止循環(huán)
??????if?index_right?==?len(right):
??????????result?+=?left[index_left:]
??????????break
??????if?index_left?==?len(left):
??????????result?+=?right[index_right:]
??????????break
??return?result
現(xiàn)在還缺少的部分是將輸入數(shù)組遞歸拆分為兩個并用于merge()產(chǎn)生最終結(jié)果的函數(shù):
def?merge_sort(array):
??#?如果輸入數(shù)組包含元素不超過兩個,那么返回它作為函數(shù)結(jié)果
??if?len(array)?2:
??????return?array
??midpoint?=?len(array)?//?2
??#?對數(shù)組遞歸地劃分為兩部分,排序每部分然后合并裝進最終結(jié)果列表
??return?merge(
??????left=merge_sort(array[:midpoint]),
??????right=merge_sort(array[midpoint:]))看一下合并排序?qū)?shù)組進行排序的步驟[8, 2, 6, 4, 5]:
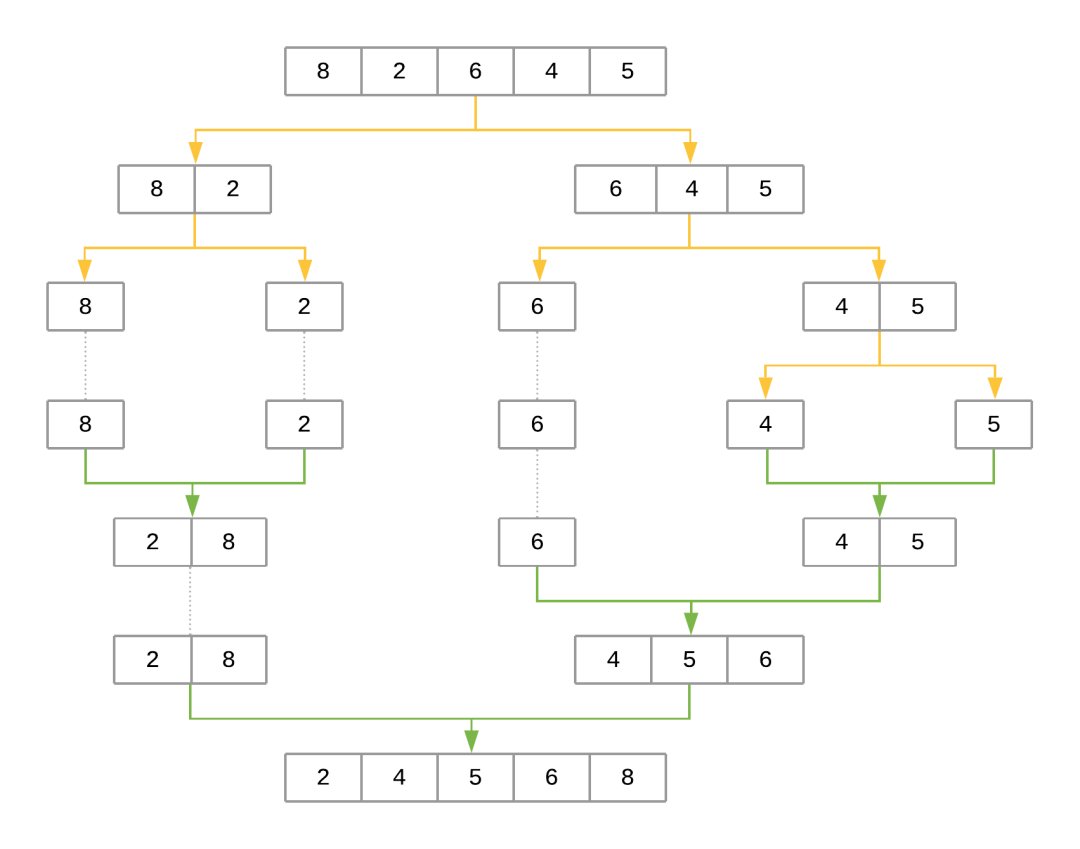
合并排序過程
該圖使用黃色箭頭表示在每個遞歸級別將數(shù)組減半。綠色箭頭表示將每個子陣列合并在一起。
衡量合并排序的大O復雜度
要分析合并排序的復雜性,可以分別查看其兩個步驟:
merge()具有線性運行時間。它接收兩個數(shù)組,它們的組合長度最多為n(原始輸入數(shù)組的長度),并且通過最多查看每個元素一次來組合兩個數(shù)組。這導致運行時復雜度為O(n)。
第二步以遞歸方式拆分輸入數(shù)組,并調(diào)用merge()每一部分。由于將數(shù)組減半直到剩下單個元素,因此此功能執(zhí)行的減半運算總數(shù)為log 2 n。由于merge()每個部分都被調(diào)用,因此總運行時間為O(n log 2 n)。
對合并排序進行測算時間
同樣通過之前時間測試函數(shù):
if?__name__?==?"__main__":
?????#?生成包含“?ARRAY_LENGTH”個元素的數(shù)組,元素是介于0到999之間的隨機整數(shù)值
?????array?=?[randint(0,?1000)?for?i?in?range(ARRAY_LENGTH)]
?
?????#?使用排序算法的名稱和剛創(chuàng)建的數(shù)組調(diào)用該函數(shù)
????run_sorting_algorithm(algorithm="merge_sort",?array=array)
執(zhí)行時間:
$?python?sorting.py
Algorithm:?merge_sort.?Minimum?execution?time:?0.6195857160000173
與冒泡排序和插入排序相比,合并排序?qū)崿F(xiàn)非常快,可以在一秒鐘內(nèi)對一萬個數(shù)組進行排序了!
分析合并排序的優(yōu)點和缺點
由于其運行時復雜度為O(n log 2 n),因此合并排序是一種非常有效的算法,可以隨著輸入數(shù)組大小的增長而很好地擴展。并行化也很簡單,因為它將輸入數(shù)組分成多個塊,必要時可以并行分配和處理這些塊。
缺點是對于較小的列表,遞歸的時間成本就較高了,冒泡排序和插入排序之類的算法更快。例如,運行包含十個元素的列表的實驗的時間:
Algorithm:?bubble_sort.?Minimum?execution?time:?0.000018774999999998654
Algorithm:?insertion_sort.?Minimum?execution?time:?0.000029786000000000395
Algorithm:?merge_sort.?Minimum?execution?time:?0.00016983000000000276合并排序的另一個缺點是,它在遞歸調(diào)用自身時會創(chuàng)建數(shù)組。它還在內(nèi)部創(chuàng)建一個新列表,這使得合并排序比氣泡排序和插入排序使用更多的內(nèi)存。
Python中的快速排序算法
就像合并排序一樣,快速排序算法采用分而治之的原理將輸入數(shù)組分為兩個列表,第一個包含小項目,第二個包含大項目。然后,該算法將對兩個列表進行遞歸排序,直到對結(jié)果列表進行完全排序為止。
劃分輸入列表稱為對列表進行分區(qū)。快排首先選擇一個pivot元素,然后將列表劃分為pivot,然后將每個較小的元素放入low數(shù)組,將每個較大的元素放入high數(shù)組。
將low列表中的每個元素放在列表的左側(cè),列表中的pivot每個元素high放在右側(cè),將其pivot精確定位在最終排序列表中的確切位置。這意味著該函數(shù)現(xiàn)在可以遞歸地將相同的過程應用于low,然后high對整個列表進行排序。
在Python中實現(xiàn)快排
這是快排的一個相當緊湊的實現(xiàn):
from?random?import?randint
def?quicksort(array):
?? #?如果第一個數(shù)組為空,那么不需要合并,
?? #?可以直接將第二個數(shù)組返回作為結(jié)果
????if?len(array)?2:
????????return?array
????low,?same,?high?=?[],?[],?[]
????#?隨機選擇 pivot 元素
????pivot?=?array[randint(0,?len(array)?-?1)]
????for?item?in?array:
????????#?元素小于pivot元素的裝進low列表中,大于piviot元素值的裝進high列表中
????????#?如果和pivot相等,則裝進same列表中
????????if?item?????????????low.append(item)
????????elif?item?==?pivot:
????????????same.append(item)
????????elif?item?>?pivot:
????????????high.append(item)
????#?最后的結(jié)果列表包含排序的low列表、same列表、hight列表
????return?quicksort(low)?+?same?+?quicksort(high)
以下是快排對數(shù)組進行排序的步驟的說明[8, 2, 6, 4, 5]:
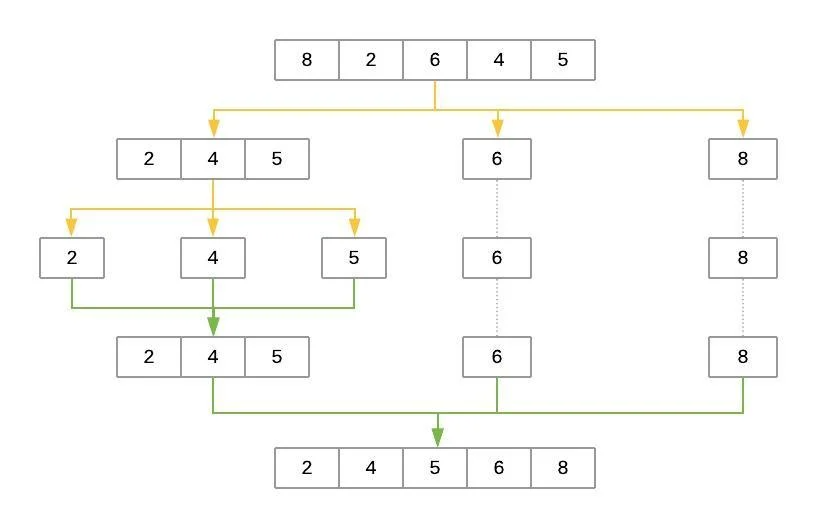
快排排序過程
快速排序流程
黃線表示陣列的劃分成三個列表:low,same,high。綠線表示排序并將這些列表放在一起。
選擇pivot元素
為什么上面的實現(xiàn)會pivot隨機選擇元素?選擇輸入列表的第一個或最后一個元素會不會一樣?
由于快速排序算法的工作原理,遞歸級別的數(shù)量取決于pivot每個分區(qū)的結(jié)尾位置。在最佳情況下,算法始終選擇中值元素作為pivot。這將使每個生成的子問題恰好是前一個問題的一半,從而導致最多l(xiāng)og 2 n級。
另一方面,如果算法始終選擇數(shù)組的最小或最大元素作為pivot,則生成的分區(qū)將盡可能不相等,從而導致n-1個遞歸級別。對于快速排序,那將是最壞的情況。
如你所見,快排的效率通常取決于pivot選擇。如果輸入數(shù)組未排序,則將第一個或最后一個元素用作,pivot將與隨機元素相同。但是,如果輸入數(shù)組已排序或幾乎已排序,則使用第一個或最后一個元素作為pivot可能導致最壞的情況。pivot隨機選擇使其更有可能使快排選擇一個接近中位數(shù)的值并更快地完成。
另一個選擇是找到數(shù)組的中值,并強制算法將其用作pivot。這可以在O(n)時間內(nèi)完成。盡管該過程稍微復雜一些,但將中值用作pivot快速排序可以確保您擁有最折中的大O方案。
衡量快排的大O復雜度
使用快排,將輸入列表按線性時間O(n)進行分區(qū),并且此過程將平均遞歸地重復log 2 n次。這導致最終復雜度為O(n log 2 n)。
當所選擇的pivot是接近陣列的中位數(shù),最好的情況下會發(fā)生O(n),當pivot是陣列的最小或最大的值,最差的時間復雜度為O(n 2)。
從理論上講,如果算法首先專注于找到中值,然后將其用作pivot元素,那么最壞情況下的復雜度將降至O(n log 2 n)。數(shù)組的中位數(shù)可以在線性時間內(nèi)找到,并將其用作pivot保證代碼的快速排序部分將在O(n log 2 n)中執(zhí)行。
通過使用中值作為pivot,最終運行時間為O(n)+ O(n log 2 n)。你可以將其簡化為O(n log 2 n),因為對數(shù)部分的增長快于線性部分。
隨機選擇pivot使最壞情況發(fā)生的可能性很小。這使得隨機pivot選擇對于該算法的大多數(shù)實現(xiàn)都足夠好。
對快排測量運行時間
調(diào)用測試函數(shù):
if?__name__?==?"__main__":
?????#?生成包含“?ARRAY_LENGTH”個元素的數(shù)組,元素是介于0到999之間的隨機整數(shù)值
?????array?=?[randint(0,?1000)?for?i?in?range(ARRAY_LENGTH)]
?
?????#?使用排序算法的名稱和剛創(chuàng)建的數(shù)組調(diào)用該函數(shù)
????run_sorting_algorithm(algorithm="quicksort",?array=array)
執(zhí)行腳本:
$?python?sorting.py
Algorithm:?quicksort.?Minimum?execution?time:?0.11675417600002902
快速排序不僅可以在不到一秒鐘的時間內(nèi)完成,而且比合并排序(0.11幾秒鐘對0.61幾秒鐘)要快得多。如果增加ARRAY_LENGTH從10,000到數(shù)量1,000,000并再次運行腳本,合并排序最終會在97幾秒鐘內(nèi)完成,而快排則僅在10幾秒鐘內(nèi)對列表進行排序。
分析快排的優(yōu)勢和劣勢
顧名思義,快排非常快。盡管從理論上講,它的最壞情況是O(n 2),但在實踐中,快速排序的良好實現(xiàn)勝過大多數(shù)其他排序?qū)崿F(xiàn)。而且,就像合并排序一樣,快排也很容易并行化。
快排的主要缺點之一是缺乏保證達到平均運行時復雜度的保證。盡管最壞的情況很少見,但是某些應用程序不能承受性能不佳的風險,因此無論輸入如何,它們都選擇不超過O(n log 2 n)的算法。
就像合并排序一樣,快排也會在內(nèi)存空間與速度之間進行權衡。這可能成為對較大列表進行排序的限制。
通過快速實驗對十個元素的列表進行排序,可以得出以下結(jié)果:
Algorithm:?bubble_sort.?Minimum?execution?time:?0.0000909000000000014
Algorithm:?insertion_sort.?Minimum?execution?time:?0.00006681900000000268
Algorithm:?quicksort.?Minimum?execution?time:?0.0001319930000000004
結(jié)果表明,當列表足夠小時,快速排序也要付出遞歸的代價,完成時間比插入排序和冒泡排序都要長。
Python中的Timsort算法
最后這個算法就有意思了!
所述Timsort算法被認為是一種混合的排序算法,因為它采用插入排序和合并排序的最佳的兩個世界級組合。Timsort與Python社區(qū)也很有緣,它是由Tim Peters于2002年創(chuàng)建的,被用作Python語言的標準排序算法。我們使用的內(nèi)置sorted函數(shù)就是這個算法。
Timsort的主要特征是它利用了大多數(shù)現(xiàn)實數(shù)據(jù)集中存在的已排序元素。這些稱為natural runs。然后,該算法會遍歷列表,將元素收集到運行中,然后將它們合并到一個排序的列表中。
在Python中實現(xiàn)Timsort
本篇創(chuàng)建一個準系統(tǒng)的Python實現(xiàn),該實現(xiàn)說明Timsort算法的所有部分。如果有興趣,也可以查看Timsort的原始C實現(xiàn)。
實施Timsort的第一步是修改insertion_sort()的實現(xiàn):
def?insertion_sort(array,?left=0,?right=None):
????if?right?is?None:
????????right?=?len(array)?-?1
????#?從指示的left元素循環(huán),直到right被指示
????for?i?in?range(left?+?1,?right?+?1):
#?這個是我們想要放在正確位置的元素
????????key_item?=?array[i]
? #?初始化變量,用于尋找元素正確位置
????????j?=?i?-?1
#?遍歷元素左邊的列表元素,一旦key_item比被比較元素小,那么找到正確位置插入
????????while?j?>=?left?and?array[j]?>?key_item:
#?把被檢測元素向左平移一個位置,并將j指向下一個元素(從右向左)
????????????array[j?+?1]?=?array[j]
????????????j?-=?1
#?當完成元素位置的變換,把key_item放在正確的位置上
????????array[j?+?1]?=?key_item
????return?array
此修改后的實現(xiàn)添加了兩個參數(shù)left和right,它們指示應該對數(shù)組的哪一部分進行排序。這使Timsort算法可以對數(shù)組的一部分進行排序。修改功能而不是創(chuàng)建新功能意味著可以將其同時用于插入排序和Timsort。
現(xiàn)在看一下Timsort的實現(xiàn):
def?timsort(array):
????min_run?=?32
????n?=?len(array)
????#?開始切分、排序輸入數(shù)組的小部分,切分在`min_run`定義
????for?i?in?range(0,?n,?min_run):
????????insertion_sort(array,?i,?min((i?+?min_run?-?1),?n?-?1))
????#?現(xiàn)在可以合并排序的切分塊了
????#?從`min_run`開始,?每次循環(huán)都加倍直到超過數(shù)組的長度
????size?=?min_run
????while?size?????????#?Determine?the?arrays?that?will
????????#?be?merged?together
????????for?start?in?range(0,?n,?size?*?2):
????????????#?計算中點(第一個數(shù)組結(jié)束第二個數(shù)組開始的地方)和終點(第二個數(shù)組結(jié)束的地方)
????????????midpoint?=?start?+?size?-?1
????????????end?=?min((start?+?size?*?2?-?1),?(n-1))
????????????#?合并兩個子數(shù)組
????????????#?left數(shù)組應該從起點到中點+1,?right數(shù)組應該從中點+1到終點+1
????????????merged_array?=?merge(
????????????????left=array[start:midpoint?+?1],
????????????????right=array[midpoint?+?1:end?+?1])
????????????#?最后,把合并的數(shù)組放回數(shù)組
????????????array[start:start?+?len(merged_array)]?=?merged_array
????????#?每次迭代都應該讓數(shù)據(jù)size加倍
????????size?*=?2
????return?array
盡管實現(xiàn)比以前的算法要復雜一些,但是我們可以通過以下方式快速總結(jié)一下:
之前已經(jīng)了解到,插入排序在小列表上速度很快,而Timsort則利用了這一優(yōu)勢。Timsort使用新引入的left和right參數(shù)在insertion_sort()對列表進行適當排序,而不必像merge sort和快排那樣創(chuàng)建新數(shù)組。
定義min_run = 32作為值有兩個原因:
1. 使用插入排序?qū)π?shù)組進行排序非常快,并且min_run利用此特性的價值很小。使用min_run太大的值進行初始化將無法達到使用插入排序的目的,并使算法變慢。
2. 合并兩個平衡列表比合并不成比例的列表要有效得多。min_run在合并算法創(chuàng)建的所有不同運行時,選擇一個為2的冪的值可確保更好的性能。
結(jié)合以上兩個條件,可以提供幾種min_run選擇。本教程中的實現(xiàn)min_run = 32是其中一種可能性。
衡量Timsort的大O時間復雜性
平均而言,Timsort的復雜度為O(n log 2 n),就像合并排序和快速排序一樣。對數(shù)部分來自執(zhí)行每個線性合并操作的運行大小加倍。
但是,Timsort在已排序或接近排序的列表上表現(xiàn)特別出色,從而導致了O(n)的最佳情況。在這種情況下,Timsort明顯勝過合并排序,并與快速排序的最佳情況相匹配。但是,對于Timsort來說,最糟糕的情況也是O(n log 2 n)。
對Timsort測量運行時間
調(diào)用時間運行測試函數(shù):
if?__name__?==?"__main__":
?????#?生成包含“?ARRAY_LENGTH”個元素的數(shù)組,元素是介于0到999之間的隨機整數(shù)值
?????array?=?[randint(0,?1000)?for?i?in?range(ARRAY_LENGTH)]
?
?????#?使用排序算法的名稱和剛創(chuàng)建的數(shù)組調(diào)用該函數(shù)
????run_sorting_algorithm(algorithm="timsort",?array=array)
執(zhí)行時間:
$?python?sorting.py
Algorithm:?timsort.?Minimum?execution?time:?0.5121690789999998
0.51秒,Timsort比合并排序整整快0.1秒,即17%。它也比插入排序快11,000%!
現(xiàn)在,嘗試使用這四種算法對已經(jīng)排序的列表進行排序,然后看看會發(fā)生什么。
if?__name__?==?"__main__":
????#?生成包含“?ARRAY_LENGTH”個元素的數(shù)組
????array?=?[i?for?i?in?range(ARRAY_LENGTH)]
????#?調(diào)用每個函數(shù)
????run_sorting_algorithm(algorithm="insertion_sort",?array=array)
????run_sorting_algorithm(algorithm="merge_sort",?array=array)
????run_sorting_algorithm(algorithm="quicksort",?array=array)
????run_sorting_algorithm(algorithm="timsort",?array=array)
現(xiàn)在執(zhí)行腳本,那么所有算法都將運行并輸出相應的執(zhí)行時間:
Algorithm:?insertion_sort.?Minimum?execution?time:?53.5485634999991
Algorithm:?merge_sort.?Minimum?execution?time:?0.372304601
Algorithm:?quicksort.?Minimum?execution?time:?0.24626494199999982
Algorithm:?timsort.?Minimum?execution?time:?0.23350277099999994
這次,Timsort的速度比合并排序快了37%,比快排快了5%,從而增強了利用已排序運行的能力。
請注意,Timsort如何從兩種算法中受益,這兩種算法單獨使用時速度要慢得多。Timsort的神奇之處在于將這些算法結(jié)合起來并發(fā)揮其優(yōu)勢,以獲得令人印象深刻的結(jié)果。
分析Timsort的優(yōu)勢和劣勢
Timsort的主要缺點是它的復雜性。盡管實現(xiàn)了原始算法的非常簡化的版本,但由于它同時依賴于insertion_sort()和merge(),因此仍需要更多代碼。
Timsort的優(yōu)點之一是其能夠以O(n log 2 n)的方式執(zhí)行預測,而與輸入數(shù)組的結(jié)構(gòu)無關。與快排相比,快排可以降級為O(n 2)。對于小數(shù)組,Timsort也非常快,因為該算法變成了單個插入排序。
對于現(xiàn)實世界中的使用(通常對已經(jīng)具有某些預先存在的順序的數(shù)組進行排序),Timsort是一個不錯的選擇。它的適應性使其成為排序任何長度的數(shù)組的絕佳選擇。
結(jié)論
排序是任何Pythonista工具包中必不可少的工具。了解Python中不同的排序算法以及如何最大程度地發(fā)揮它們的潛力,你就可以實現(xiàn)更快,更高效的應用程序和程序!
參考:?
1. https://realpython.com/sorting-algorithms-python/
2. https://blog.csdn.net/weixin_38483589/article/details/84147376
3. https://mp.weixin.qq.com/s/OHoe6TTX--Ys5G-5yR6juA

——End——
后臺回復關鍵字:1024,獲取一份精心整理的技術干貨 后臺回復關鍵字:進群,帶你進入高手如云的交流群。 推薦閱讀