
數(shù)據增長實驗,數(shù)據分析進階必會技能!
做增長,是數(shù)據分析師最好的立功方式,今天直接來個例子,看看怎么通過數(shù)據設計增長實驗。話不多說,整!
問題場景:
某包含多系列產品的快消品公司,希望推出一款全新飲料(2個SKU)以帶動整體銷售金額。該款為全新推出,缺少經驗,因此計劃在今年先行實驗,觀察效果后大面積推廣。
?
問:該如何設計增長實驗,以提前發(fā)現(xiàn)問題,確保增長?
很多新人同學舉手,表示這題我會:
1、對接頭條、騰訊、阿里大數(shù)據獲取全部信息
2、建立用戶到店-貨架-選擇-加入購物籃-結賬轉化漏斗
3、進行ABtest,進店用戶自動打碼分流進行AA\AB對比
4、建立用戶畫像精準識別目標用戶性別,年齡,收入,愛好
5、建立人工智能大數(shù)據模型精準預測自然銷量
?
現(xiàn)實問題是:沒數(shù)據。因為不是自有渠道,所以只能拿到進貨數(shù),其他的數(shù)據不要想了,不存在的,一條都沒有。倒是門店有沒有鋪貨,可以靠巡店督導定期上門檢查。
?
那么,該怎么辦呢?
最簡單的想法:上新品是為了拉動銷量,所以上新之后,得比上新之前渠道訂貨得多。于是最簡單的模型就出來了(如下圖):
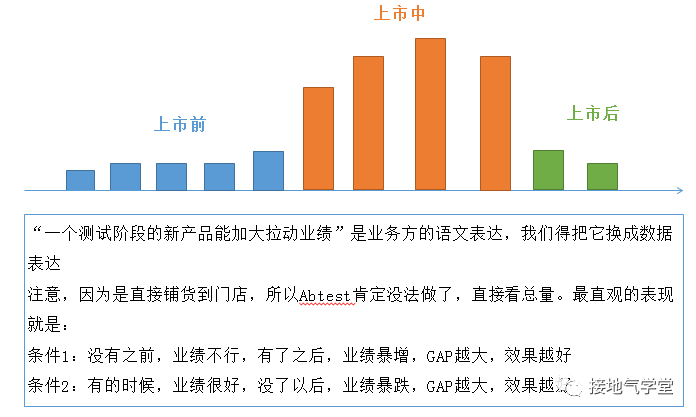
? ? ? ? ? ? ? ? ? ? ? ? ?
那么,看起來實驗設計也很簡單了:
1、找?guī)讉€店
2、鋪貨
3、觀察鋪貨以后銷量
4、搞掂
?
是不是真的搞掂了呢?
第一個問題:找店是隨機找,還是有目標找?
很有可能有的店天生就賣得好,有的店天生賣得差。如果事先不對店過往訂貨情況進行分析,就很有可能高估/低估增長能力。特別要注意專職店是否存在,這類型門店如果數(shù)量過多,可能會影響整體判斷(如下圖):
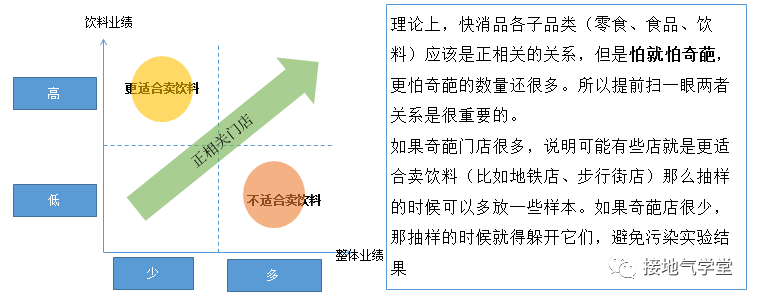
在前期選擇試點樣本店的時候,提前做好篩選,考慮:
門店位置:社區(qū)店/CBD店/步行街店
門店業(yè)績:整體業(yè)績好/中/差
品類業(yè)績:飲料類好/中/差
門店時間:新店/老店
?
這些數(shù)據是可以獲取到的,數(shù)據1在督導的巡店表里有記錄,數(shù)據2,3,4在訂貨單里有記錄,所以完全可獲得。需要做的是提前對數(shù)據進行分析,做好分層和打標簽的工作。
?
這么多維度交叉起來,引發(fā)一個新問題:到底要選多少店做試點。統(tǒng)計學會告訴你單群體最小樣本30,最好384,這樣95%置信度下抽樣誤差5%——但是這些和眼前的問題工作沒多大關系。
因為眼前的問題是:
第一:需要以店為單位抽,有可能所有門店加起來都不夠這么多。
第二:測試的是新產品,且測試周期可能很長,意味著貨源可能不夠。
第三:測試的是新上架產品,需要業(yè)務方一個店一個點鋪貨,得考慮工作量。
所以設計樣本數(shù)的時候,首先對單店在測試周期內銷量有個預計,保證肯定有貨,這樣才能真正測出來:是否達預期。定下門店總量以后,再按以上考慮維度往里塞樣本。最后出來的結果,保證每個分類盡可能都有樣本就行。
?
如果事先有一級、二級、三級門店的分類,則輕松很多。因為一二三級分類,很有可能已經綜合考慮了銷售能力,門店規(guī)模等等因素。但在使用之前得注意幾個問題:
1、過往的一二三級分類,是否目前還準。別出現(xiàn)3級》2級》1級的情況,那事后分析就很尷尬了。
2、一二三級是否考慮類型。避免一級門店全是同一類門店(比如都是CBD店)這樣事后評估,會發(fā)現(xiàn)嚴重缺其他門店樣本。
3、一二三級是否和飲料銷售有關系。注意,題目企業(yè)是個全系列企業(yè),很有可能一二三級是按整體業(yè)績分類的,對應到飲料類,又會出現(xiàn)3級》2級》1級的極端情況。
?
只要不存在以上問題,那1,2,3級分類就直接用吧。
?
考慮增長基礎,不但讓設計更豐滿,而且能極大方便事后的評估。避免諸如以下這些尷尬的問題:
1、為啥測試效果不好,因為找的都是很差的店
2、為啥分析不出推廣潛力,因為找的都是同一類的店
3、為啥1級門店反而賣的不好,因為丫天生就賣得不好
?
并且在事后分析的時候,能對各類型門店標簽下情況進行深入的分析,具體到每一類店鋪標簽的效果。這樣迭代實驗的時候,也有更清晰的方向,落地的時候,思路也更多(如下圖)。
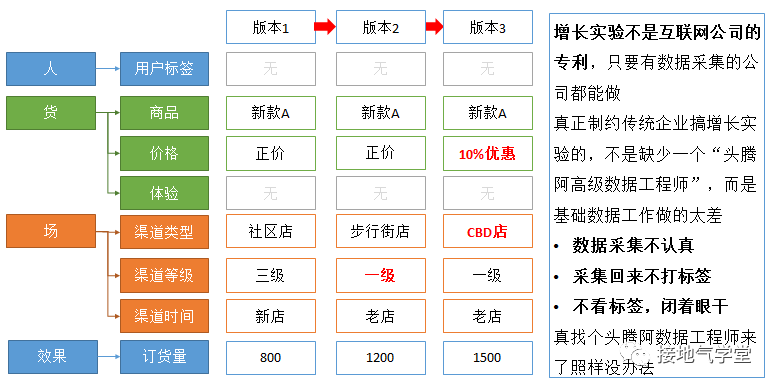
?
那么,考慮到這一步夠了嗎?
第二步:考慮什么時間測,測多久。
一般商品都有自己的銷售周期,飲料類的周期更特殊,可能集中在夏季爆發(fā),也有可能受各地氣候的影響,也有可能受天氣短期影響。因此在設計測試周期的時候,需要先梳理相似價位、相似類型、相似目標群體對應的飲料的走勢,這樣才能有個全局判斷(如下圖)。
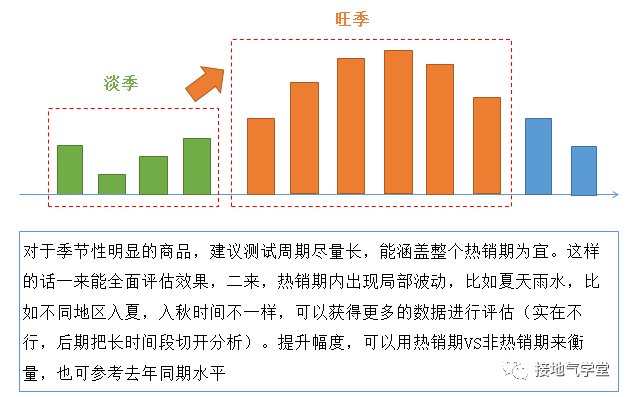
?
有了全局判斷后,可以設一個比較長的觀察周期,以盡可能多覆蓋各種場景。這樣在事后評估分析的時候,也能對各種情況進行分析(如下圖)。
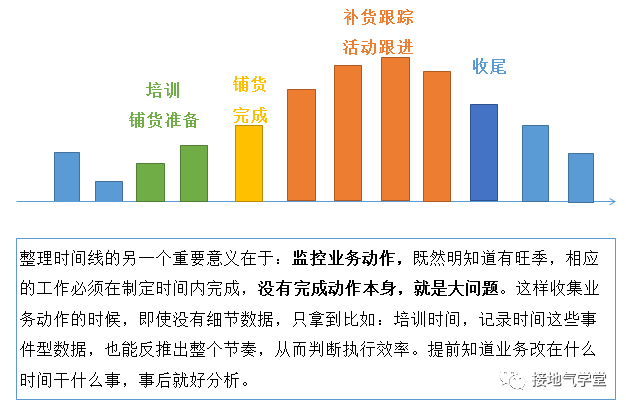
?
第三步:考慮業(yè)務落地動作。
一款新產品上市,宣傳、鋪貨、促銷三件套往往是一起往上招呼。這些落地動作才是最終決定測試成果的因素。而這些動作,都依賴各地分公司/辦事處的執(zhí)行,執(zhí)行力至關重要。
這里有個很深刻的問題:一但測試效果不好……
到底是產品本身沒需求?
還是業(yè)務自己沒做好?
還是數(shù)據分析師算錯了?
?
監(jiān)控了業(yè)務執(zhí)行過程,你才有資格說:業(yè)務做得好/不好。沒有監(jiān)控業(yè)務執(zhí)行過程,人家隨時都能說:數(shù)據分析沒算出來。“現(xiàn)在不都人工智能大數(shù)據了嗎,一定是我們的數(shù)據分析師太蠢了,招個頭騰阿的數(shù)據分析師肯定能算清楚”——這鍋已經為你準備好了,所以一定要掌握清楚。
待掌握的信息包括:
鋪貨啟動時間
鋪貨完成時間
補充訂貨時間
?
有了這些信息,可以結合訂貨數(shù)據做更多分析:
有沒有拖了很久不啟動的
有沒有啟動了推進很慢的
有沒有不分規(guī)模閉著眼睛鋪的
有沒有缺貨了不去補的
當然,后期核查要跟上,且核查的時候,可以增加幾個關鍵維度檢查,比如:
大夏天的把貨鋪在貨架而不是塞冰柜的
大賣場不做堆頭只做貨架的
有促銷物資不往門店進的
這些核查數(shù)據同樣得從督導手里收回來,同數(shù)據一起分析,才更容易看到結果。
?
這樣,在解釋結果的時候,自然更有底氣:凡是沒有執(zhí)行的到位的,一概不許甩鍋給產品/數(shù)據,自己沒做好的自己反省去。這樣也更有利于找到真正問題答案。
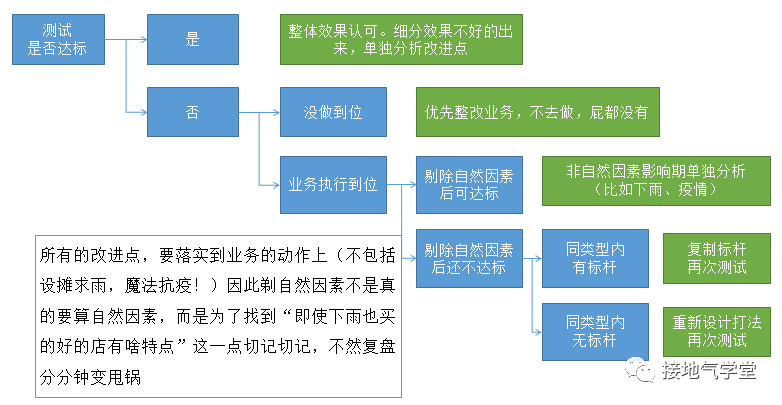
?
2020年的數(shù)據分析領域最大問題,就是:學習過程書本化,脫離實際。教數(shù)據分析的書、老師、課程,為了讓算法、統(tǒng)計原理、用戶畫像、漏斗模型、ABtest發(fā)揮作用,就專門挑一些字段豐富,清洗干凈的數(shù)據集,讓算法跑起來。新人們把工作當讀書,跑幾個數(shù)據集就欣欣然自以為得已得已。
?
兩下相交,導致的結果就是新人們遇到實際問題的時候:不是幻想頭騰阿有靈丹妙藥,就是急著搬書找答案,要么就是跑到各個群問:“有沒有互聯(lián)網飲料行業(yè)的大佬,急,在線等,可付費!”。唯獨喪失了具體問題、具體分析的能力。
?
破除迷信,腳踏實地,認真研究業(yè)務流程,設計合理的方法,才是解決問題之道。數(shù)據簡單有數(shù)據簡單的搞法,數(shù)據豐富有數(shù)據豐富的搞法,把簡單的數(shù)據通過業(yè)務流程改進變得豐富,這三者合并才是一個合格的數(shù)據分析師該有的能力。
.
? ??