
美團(tuán)外賣搜索基于Elasticsearch的優(yōu)化實(shí)踐
點(diǎn)擊“開發(fā)者技術(shù)前線”,選擇“星標(biāo)”
讓一部分開發(fā)者看到未來

來自美團(tuán)技術(shù)團(tuán)隊(duì)
美團(tuán)外賣搜索工程團(tuán)隊(duì)在Elasticsearch的優(yōu)化實(shí)踐中,基于Location-Based Service(LBS)業(yè)務(wù)場景對Elasticsearch的查詢性能進(jìn)行優(yōu)化。該優(yōu)化基于Run-Length Encoding(RLE)設(shè)計了一款高效的倒排索引結(jié)構(gòu),使檢索耗時(TP99)降低了84%。本文從問題分析、技術(shù)選型、優(yōu)化方案等方面進(jìn)行闡述,并給出最終灰度驗(yàn)證的結(jié)論。
1. 前言
2. 背景
3. 挑戰(zhàn)及問題
3.1 倒排鏈查詢流程
3.2 倒排鏈合并流程
4. 技術(shù)探索與實(shí)踐
4.1 倒排鏈查詢優(yōu)化
4.2 倒排鏈合并
4.3 基于 RLE 的倒排格式設(shè)計
4.4 功能集成
5. 性能收益
6. 總結(jié)與展望
7. 作者簡介
8. 參考文獻(xiàn)
1. 前言
最近十年,Elasticsearch 已經(jīng)成為了最受歡迎的開源檢索引擎,其作為離線數(shù)倉、近線檢索、B端檢索的經(jīng)典基建,已沉淀了大量的實(shí)踐案例及優(yōu)化總結(jié)。然而在高并發(fā)、高可用、大數(shù)據(jù)量的 C 端場景,目前可參考的資料并不多。因此,我們希望通過分享在外賣搜索場景下的優(yōu)化實(shí)踐,能為大家提供 Elasticsearch 優(yōu)化思路上的一些借鑒。
美團(tuán)在外賣搜索業(yè)務(wù)場景中大規(guī)模地使用了 Elasticsearch 作為底層檢索引擎。其在過去幾年很好地支持了外賣每天十億以上的檢索流量。然而隨著供給與數(shù)據(jù)量的急劇增長,業(yè)務(wù)檢索耗時與 CPU 負(fù)載也隨之上漲。通過分析我們發(fā)現(xiàn),當(dāng)前檢索的性能熱點(diǎn)主要集中在倒排鏈的檢索與合并流程中。針對這個問題,我們基于 Run-length Encoding(RLE)[1] 技術(shù)設(shè)計實(shí)現(xiàn)了一套高效的倒排索引,使倒排鏈合并時間(TP99)降低了 96%。我們將這一索引能力開發(fā)成了一款通用插件集成到 Elasticsearch 中,使得 Elasticsearch 的檢索鏈路時延(TP99)降低了 84%。
2. 背景
POST food/_search
{
"query": {
"bool": {
"must":{
"term": { "spu_name": { "value": "烤鴨"} }
//...
},
"filter":{
"terms": {
"wm_poi_id": [1,3,18,27,28,29,...,37465542] // 上萬
}
}
}
}
//...
}
3. 挑戰(zhàn)及問題
由于 Elasticsearch 在設(shè)計上針對海量的索引數(shù)據(jù)進(jìn)行優(yōu)化,在過去的 10 年間,逐步去除了內(nèi)存支持索引的功能(例如 RAMDirectory 的刪除)。為了能夠?qū)崿F(xiàn)超大規(guī)模候選集的檢索,Elasticsearch/Lucene 對 Term 倒排鏈的查詢流程設(shè)計了一套內(nèi)存與磁盤共同處理的方案。
3.1 倒排鏈查詢流程
從內(nèi)存中的 Term Index 中獲取該 Term 所在的 Block 在磁盤上的位置。 從磁盤中將該 Block 的 TermDictionary 讀取進(jìn)內(nèi)存。 對倒排鏈存儲格式的進(jìn)行 Decode,生成可用于合并的倒排鏈。
可以看到,這一查詢流程非常復(fù)雜且耗時,且各個階段的復(fù)雜度都不容忽視。所有的 Term 在索引中有序存儲,通過二分查找找到目標(biāo) Term。這個有序的 Term 列表就是 TermDictionary ,二分查找 Term 的時間復(fù)雜度為 O(logN) ,其中 N 是 Term 的總數(shù)量 。Lucene 采用 Finite State Transducer[3](FST)對 TermDictionary 進(jìn)行編碼構(gòu)建 Term Index。FST 可對 Term 的公共前綴、公共后綴進(jìn)行拆分保存,大大壓縮了 TermDictionary 的體積,提高了內(nèi)存效率,F(xiàn)ST 的檢索速度是 O(len(term)),其對于 M 個 Term 的檢索復(fù)雜度為 O(M * len(term))。
3.2 倒排鏈合并流程
在經(jīng)過上述的查詢,檢索出所有目標(biāo) Term 的 Posting List 后,需要對這些 Posting List 求并集(OR 操作)。在 Lucene 的開源實(shí)現(xiàn)中,其采用 Bitset 作為倒排鏈合并的容器,然后遍歷所有倒排鏈中的每一個文檔,將其加入 DocIdSet 中。
偽代碼如下:
Input: termsEnum: 倒排表;termIterator:候選的term
Output: docIdSet : final docs set
for term in termIterator:
if termsEnum.seekExact(term) != null:
docs = read_disk() // 磁盤讀取
docs = decode(docs) // 倒排鏈的decode流程
for doc in docs:
docIdSet.or(doc) //代碼實(shí)現(xiàn)為DocIdSetBuilder.add。
end for
docIdSet.build()//合并,排序,最終生成DocIdSetBuilder,對應(yīng)火焰圖最后一段。
假設(shè)我們有 M 個 Term,每個 Term 對應(yīng)倒排鏈的平均長度為 K,那么合并這 M 個倒排鏈的時間復(fù)雜度為:O(K * M + log(K * M))。可以看出倒排鏈合并的時間復(fù)雜度與 Terms 的數(shù)量 M 呈線性相關(guān)。在我們的場景下,假設(shè)一個商家平均有一千個商品,一次搜索請求需要對一萬個商家進(jìn)行檢索,那么最終需要合并一千萬個商品,即循環(huán)執(zhí)行一千萬次,導(dǎo)致這一問題被放大至無法被忽略的程度。
我們也針對當(dāng)前的系統(tǒng)做了大量的調(diào)研及分析,通過美團(tuán)內(nèi)部的 JVM Profile 系統(tǒng)得到 CPU 的火焰圖,可以看到這一流程在 CPU 熱點(diǎn)圖中的反映也是如此:無論是查詢倒排鏈、還是讀取、合并倒排鏈都相當(dāng)消耗資源,并且可以預(yù)見的是,在供給越來越多的情況下,這三個階段的耗時還會持續(xù)增長。
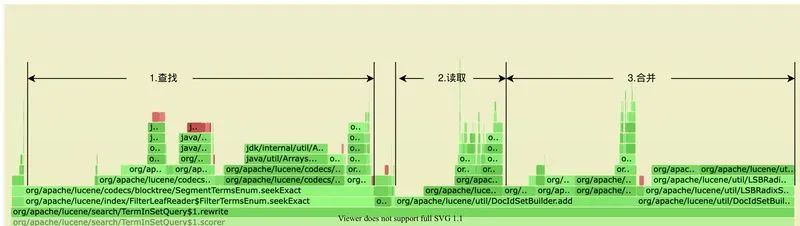
可以明確,我們需要針對倒排鏈查詢、倒排鏈合并這兩個問題予以優(yōu)化。
4. 技術(shù)探索與實(shí)踐
4.1 倒排鏈查詢優(yōu)化
通常情況下,使用 FST 作為 Term 檢索的數(shù)據(jù)結(jié)構(gòu),可以在內(nèi)存開銷和計算開銷上取得一個很好的平衡,同時支持前綴檢索、正則檢索等多種多樣的檢索 Query,然而在我們的場景之下,F(xiàn)ST 帶來的計算開銷無法被忽視。
Term 的數(shù)據(jù)類型為 long 類型。 無范圍檢索,均為完全匹配。 無前綴匹配、模糊查找的需求,不需要使用前綴樹相關(guān)的特性。 候選數(shù)量可控,每個商家的商品數(shù)量較多,即 Term 規(guī)模可預(yù)期,內(nèi)存可以承載這個數(shù)量級的數(shù)據(jù)。
因此在我們的應(yīng)用場景中使用空間換取時間是值得的。
對于 Term 查詢的熱點(diǎn):可替換 FST 的實(shí)現(xiàn)以減少 CPU 開銷,常見的查找數(shù)據(jù)結(jié)構(gòu)中,哈希表有 O(1) 的查詢復(fù)雜度,將 Term 查找轉(zhuǎn)變?yōu)閷1淼囊淮尾樵儭?/span>
對于哈希表的選取,我們主要選擇了常見的 HashMap 和 LongObjectHashMap。
我們主要對比了 FST、HashMap 和 LongObjectHashMap(哈希表的一種高性能實(shí)現(xiàn))的空間和時間效率。
在內(nèi)存占用上:FST 的內(nèi)存效率極佳。而 HashMap/LongObjectHashMap 都有明顯的劣勢; 在查詢時間上:FST 的查詢復(fù)雜度在 O (len(term)),而 Hash/LongObjectHashMap 有著 O(1) 的查詢性能;
注:檢索類型雖然為 Long,但是我們將底層存儲格式進(jìn)行了調(diào)整,沒有使用開源的 BKD Tree 實(shí)現(xiàn),使用 FST 結(jié)構(gòu),僅與 FST 進(jìn)行對比。BKD Tree 在大批量整數(shù) terms 的場景下劣勢更為明顯。
我們使用十萬個 <Long, Long> 的鍵值對來構(gòu)造數(shù)據(jù),對其空間及性能進(jìn)行了對比,結(jié)果如下:
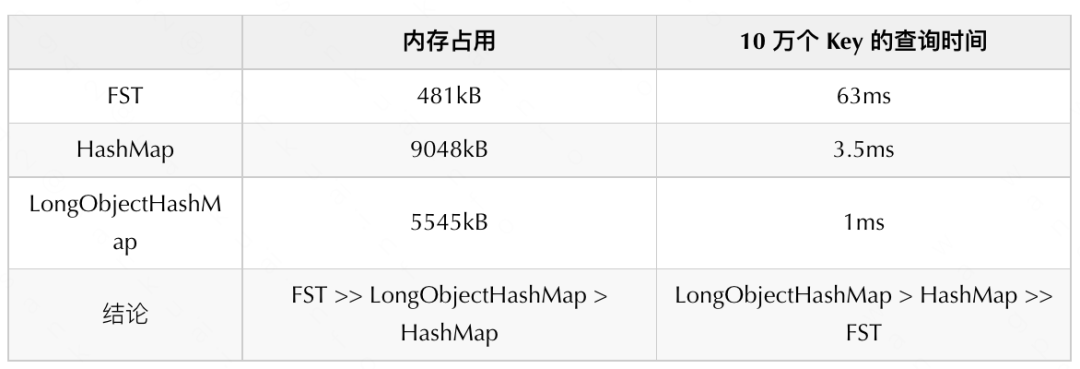
可以看到, 在內(nèi)存占用上 FST 要遠(yuǎn)優(yōu)于 LongObjectHashMap 和 HashMap。而在查詢速度上 LongObjectHashMap 最優(yōu)。
我們最終選擇了 LongObjectHashMap 作為倒排鏈查詢的數(shù)據(jù)結(jié)構(gòu)。
4.2 倒排鏈合并
基于上述問題,我們需要解決兩個明顯的 CPU 熱點(diǎn)問題:倒排鏈讀取 & 倒排鏈合并。我們需要選擇合適的數(shù)據(jù)結(jié)構(gòu)緩存倒排鏈,不再執(zhí)行磁盤 /page cache 的 IO。數(shù)據(jù)結(jié)構(gòu)需要必須滿足以下條件:
支持批量 Merge,減少倒排鏈 Merge 耗時。 內(nèi)存占用少,需要處理千萬數(shù)量級的倒排鏈。
在給出具體的解決方案之前,先介紹一下 Lucene 對于倒排合并的原生實(shí)現(xiàn)、RoaringBitMap、Index Sorting。
4.2.1 原生實(shí)現(xiàn)
Lucene在不同場景上使用了不同的倒排格式,提高整體的效率(空間/時間),通過火焰圖可以發(fā)現(xiàn),在我們的場景上,TermInSetQuery 的倒排合并邏輯開銷最大。
TermInSetQuery 的倒排鏈合并操作分為兩個步驟:倒排鏈讀取和合并。
稀疏數(shù)據(jù):存儲采用 List<int[]> array 方式存儲 Doc ID,最終經(jīng)過 Merge 和排序形成一個有序數(shù)組 int[],耗時主要集中在數(shù)組申請和排序。 稠密數(shù)據(jù):基于 long[] 實(shí)現(xiàn)的 bitmap 結(jié)構(gòu)(FixedBitSet),耗時主要集中在 FixedBitSet 的插入過程,由于倒排鏈需要實(shí)時 Decode 以及 FixedBitSet 的底層實(shí)現(xiàn),無法實(shí)現(xiàn)批量 Merge,只能循環(huán)單個 Doc ID 插入,數(shù)據(jù)量大的情況下,耗時明顯。
我們采用線上流量和數(shù)據(jù)壓測發(fā)現(xiàn)該部分平均耗時約 7 ms。
4.2.2 RoaringBitmap
當(dāng)前 Elasticsearch 選擇 RoaringBitMap 做為 Query Cache 的底層數(shù)據(jù)結(jié)構(gòu)緩存倒排鏈,加快查詢速率。
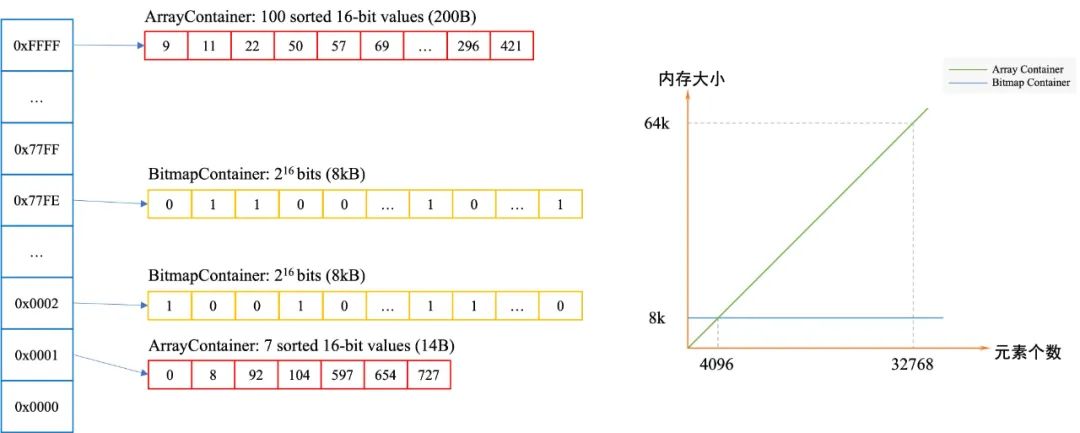
RoaringBitmap 是一種壓縮的位圖,相較于常規(guī)的壓縮位圖能提供更好的壓縮,在稀疏數(shù)據(jù)的場景下空間更有優(yōu)勢。以存放 Integer 為例,Roaring Bitmap 會對存入的數(shù)據(jù)進(jìn)行分桶,每個桶都有自己對應(yīng)的 Container。在存入一個32位的整數(shù)時,它會把整數(shù)劃分為高 16 位和低 16 位,其中高 16 位決定該數(shù)據(jù)需要被分至哪個桶,我們只需要存儲這個數(shù)據(jù)剩余的低 16 位,將低 16 位存儲到 Container 中,若當(dāng)前桶不存在數(shù)據(jù),直接存儲 null 節(jié)省空間。RoaringBitmap有不同的實(shí)現(xiàn)方式,下面以 Lucene 實(shí)現(xiàn)(RoaringDocIdSet)進(jìn)行詳細(xì)講解:
備注:Roaring Bitmap 可參考官方博客[4]。
4.2.3 Index Sorting
Elasticsearch 從 6.0 版本開始支持 Index Sorting[5] 功能,在索引階段可以配置多個字段進(jìn)行排序,調(diào)整索引數(shù)據(jù)組織方式,可以調(diào)整文檔所對應(yīng)的 Doc ID。以 city_id,poi_id 為例:
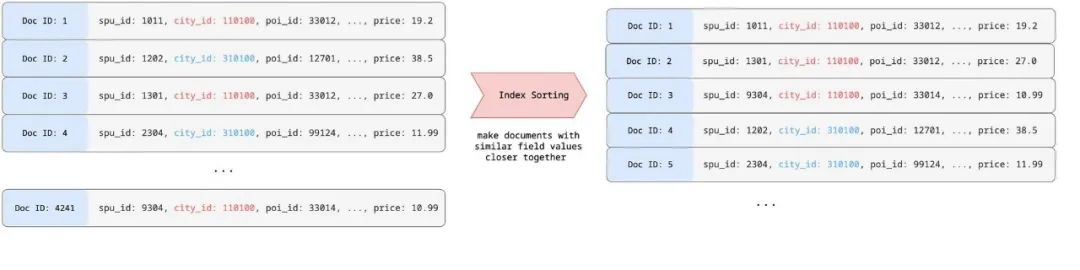
如上示例所示:Index Sorting 會將給定的排序字段(如上圖的 city_id 字段)的文檔排序在一起,相同排序值的文檔的 Doc ID 嚴(yán)格自增,對該字段建立倒排,那么其倒排鏈為自增數(shù)列。
4.3 基于 RLE 的倒排格式設(shè)計
基于以上的背景知識以及當(dāng)前 Elasticsearch/Lucene 的解決方案,可以明確目前有 2 個改造點(diǎn)需要考慮。
合適的倒排結(jié)構(gòu),用于存儲每個 Term 的倒排鏈。 合適的中間結(jié)構(gòu),用于存儲多個 Term 合并后的倒排鏈。
對于索引倒排格式 PostingsEnum,支持接口為:
public abstract class DocIdSetIterator {
public abstract int docID();
public abstract int nextDoc();
public abstract int advance(int target);
}
倒排僅支持單文檔循環(huán)調(diào)用,不支持批量讀取,因此需要為倒排增加批量順序讀取的功能。
原生 RoaringDocIdSet 在構(gòu)建時,只能支持遞增的添加 Doc ID。而在實(shí)際生產(chǎn)中每一個商家的商品的 Doc ID 都是離散的。這就限制了其使用范圍。 原生 RoaringDocIdSet 的底層存儲結(jié)構(gòu) Bitmap Container 和 Array Container 均不支持批量合并,這就無法滿足我們對倒排鏈合并進(jìn)行優(yōu)化的需求。
在明確這個問題的場景下,我們可以考慮最簡單的改造,支持索引倒排格式 PostingsEnum 的批量讀取。并考慮了如下幾種場景:
在支持批量讀取倒排的情況下,直接使用原結(jié)構(gòu) DocIdSetBuilder 進(jìn)行批量的合并。 在支持批量讀取倒排的情況下,使用 RoaringBitMap 進(jìn)行批量合并。
然而我們發(fā)現(xiàn)即使對 bitset 進(jìn)行分段合并,直接對數(shù)據(jù)成段進(jìn)行 OR 操作,整體開銷下降并不明顯。其原因主要在于:對于讀取的批量結(jié)果,均為稀疏分布的 Doc ID,僅減少倒排的循環(huán)調(diào)用無法解決性能開銷問題。
那么問題需要轉(zhuǎn)化為如何解決 Doc ID 分布稀疏的問題。在上文提及的 Index Sorting 即一個絕佳的解決方案。并且由于業(yè)務(wù) LBS 的特點(diǎn),一次檢索的全部結(jié)果集均集中在某個地理位置附近,以及我們檢索僅針對門店列表 ID 的特殊場景,我們最終選擇對城市 ID、 Geohash、門店 ID 進(jìn)行排序,從而讓稀疏分布的 Doc ID 形成連續(xù)分布。在這樣的排序規(guī)則應(yīng)用之后,我們得到了一組絕佳的特性:每一個商家所對應(yīng)的商品,其 Doc ID 完全連續(xù)。
4.3.1 Run-Length Encoding
Run-Length Encoding[3](RLE)技術(shù)誕生于50年前,最早應(yīng)用于連續(xù)的文本壓縮及圖像壓縮。在 2014 年,第一個開源在 GitHub 的 RoaringBitmap 誕生[6],2016年,在 RoaringBitMap 的基礎(chǔ)上增加了對于自增序列的 RLE 實(shí)現(xiàn)[7],并應(yīng)用在 bitmap 這一場景上。
在 bitmap 這一場景之下,主要通過壓縮連續(xù)區(qū)間的稠密數(shù)據(jù),節(jié)省內(nèi)存開銷。以數(shù)組 [1, 2, 3, ..., 59, 60, 89, 90, 91, ..., 99, 100] 為例(如下圖上半部分):使用 RLE 編碼之后就變?yōu)?[1, 60, 89, 12]——形如 [start1, length1, start2, length2, ...] 的形式,其中第一位為連續(xù)數(shù)字的起始值,第二位為其長度。
在數(shù)組完全連續(xù)場景下中,對 32768 個 id (short) 進(jìn)行存儲,數(shù)組存儲需要 64 kB,Bitmap 存儲需要使用 4 kB,而 RLE 編碼后直接存儲僅需要 4 byte。在這一特性下,如果商家倒排鏈完全有序,那么商家的倒排鏈,可被壓縮到最低僅需要兩個整數(shù)即可表示。
當(dāng)然 RLE 并不適用所有情況,在目標(biāo)序列完全不連續(xù)的場景下,如 [1, 3, 5, 7, ... , M],RLE 編碼存儲需要使用 2 * M byte的空間,比數(shù)組直接存儲的空間效率差一倍。
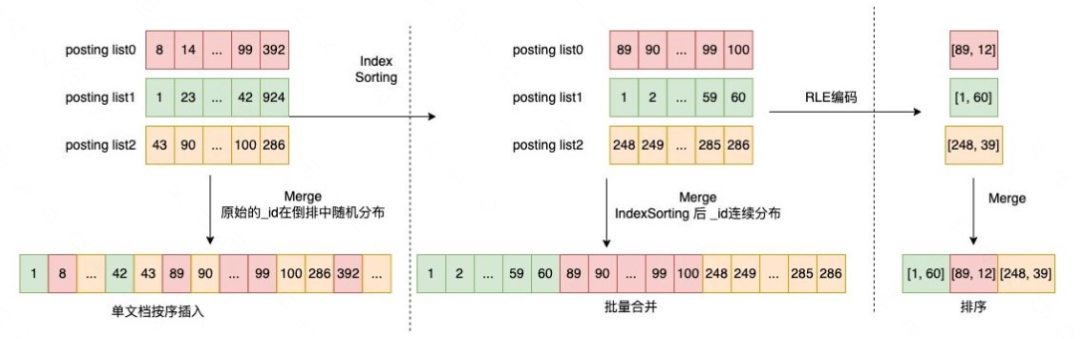
4.3.2 RLE Container 的實(shí)現(xiàn)
在對商家 ID 字段開啟 Index Sorting 之后,同商家的商品 ID 已經(jīng)連續(xù)分布。那么對于商家字段的倒排鏈就是嚴(yán)格自增且無空洞的整數(shù)序列。我們采用RLE編碼對倒排鏈進(jìn)行編碼存儲。由于將倒排鏈編碼為 [start1, length1, start2, length2, ...],更特殊的,在我們場景下,一個倒排鏈的表示為 [start, length],RLE編碼做到了對倒排鏈的極致壓縮,假設(shè)倒排鏈為 [1, 2, ...., 1000], 用 ArrayContainer 存儲,內(nèi)存空間占用為 16 bit * 100 = 200 Byte, RLE 編碼存儲只需要 16 bit * 2 = 4 Byte。考慮到具體的場景分布,以及其他場景可能存在多段有序倒排的情況,我們最終選擇了 [start1, length1, start2, length2, ...] 這樣的存儲格式,且 [start, start + length] 之間兩兩互不重疊。
4.3.3 SparseRoaringDocIdSet 實(shí)現(xiàn)
我們在 RoaringDocIdSet 的基礎(chǔ)上增加了 RLE Container 后,性能已經(jīng)得到了明顯的提升,加速了 50%,然而依然不符合我們的預(yù)期。我們通過對倒排鏈的數(shù)據(jù)分析發(fā)現(xiàn):倒排鏈的平均長度不大,基本在十萬內(nèi)。但是其取值范圍廣 [ 0, Integer.MAX-1 ]。這些特征說明,如果以 RoaringDocIdSet 按高 16 位進(jìn)行分桶的話,大部分?jǐn)?shù)據(jù)將集中在其中連續(xù)的幾個桶中。
在 Elasticsearch 場景上,由于無法預(yù)估數(shù)據(jù)分布,RoaringDocIdSet 在申請 bucket 容器的數(shù)組時,會根據(jù)當(dāng)前 Segment 中的最大 Doc ID 來申請,計算公式為:(maxDoc + (1 << 16) - 1) >>> 16。這種方式可以避免每次均按照 Integer.MAX-1 來創(chuàng)建容器帶來的無謂開銷。然而,當(dāng)?shù)古沛湐?shù)量偏少且分布集中時,這種方式依然無法避免大量 bucket 被空置的空間浪費(fèi);另一方面,在對倒排鏈進(jìn)行合并時,這些空置的 bucket 也會參與到遍歷中,即使它被置為了空。這就又造成了性能上的浪費(fèi)。我們通過壓測評估證實(shí)了這一推理,即空置的 bucket 在合并時也會占用大量的 CPU 資源。
針對這一問題,我們設(shè)計了一套用于稀疏數(shù)據(jù)的方案,實(shí)現(xiàn)了 SparseRoaringDocIdSet,同時保持接口與 RoaringDocIdSet 一致,可在各場景下進(jìn)行復(fù)用,其結(jié)構(gòu)如下:
class SparseRoaringDocIdSet {
int[] index; // 記錄有 container 的 bucket Index
Container[] denseSets; // 記錄緊密排列的倒排鏈
}
保存倒排鏈的過程與 RoaringDocIDSet 保持一致,在確認(rèn)具體的 Container 的分桶時,我們額外使用一組索引記錄所有有值的 bucket 的 location。
下圖是一組分別使用 RLE based RoaringDocIdSet 和 SparseRoaringDocIdSet 對 [846710, 100, 936858, 110] 倒排鏈(RLE 編碼)進(jìn)行存儲的示意圖:
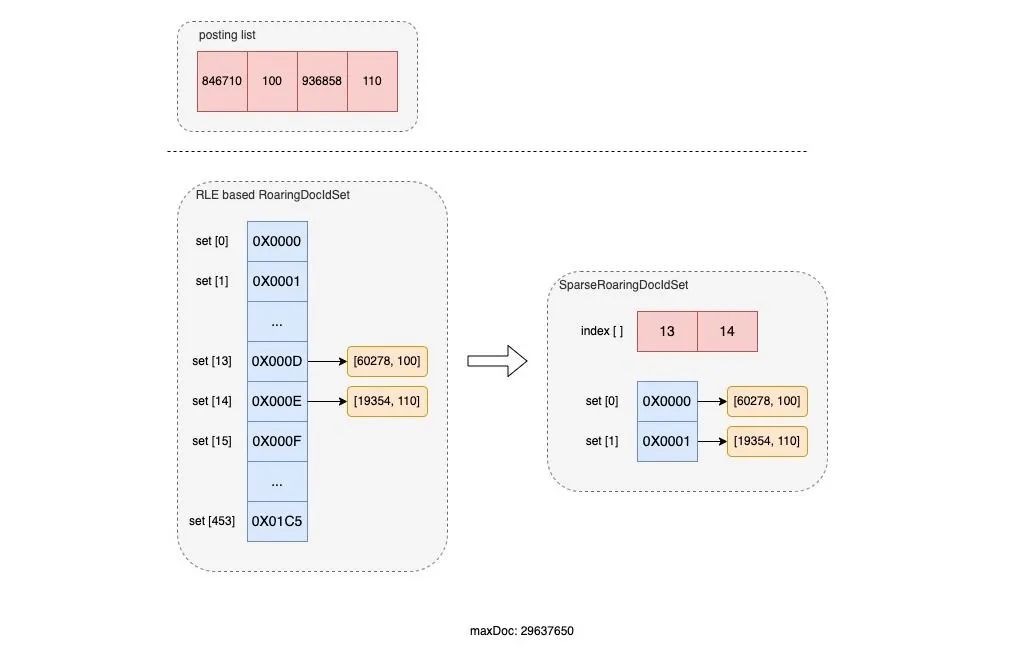
可以看到:在 SparseRoaringDocIdSet 實(shí)現(xiàn)下,所有不為空的 bucket 被緊密的排列在了一起,并在 index [] 中記錄了其原始 bucket 的索引,這就避免了大量 bucket 被空置的情況。另外,在進(jìn)行倒排鏈的合并時,就可以直接對緊密排列的 denseSet 進(jìn)行遍歷,并從 index [] 獲得其對應(yīng)的原始 bucket location,這就避免了大量的空置 bucket 在合并時帶來的性能浪費(fèi)。
我們分別對以下4個場景進(jìn)行了壓測:原生的 TermInSetQuery 對倒排鏈的合并邏輯、基于 FixedBitSet 的批量合并、RLE based RoaringBitmap、RLE based Dense RoaringBitmap。對 10000 個平均長度為 100 的倒排鏈進(jìn)行合并壓測,壓測結(jié)果如下:
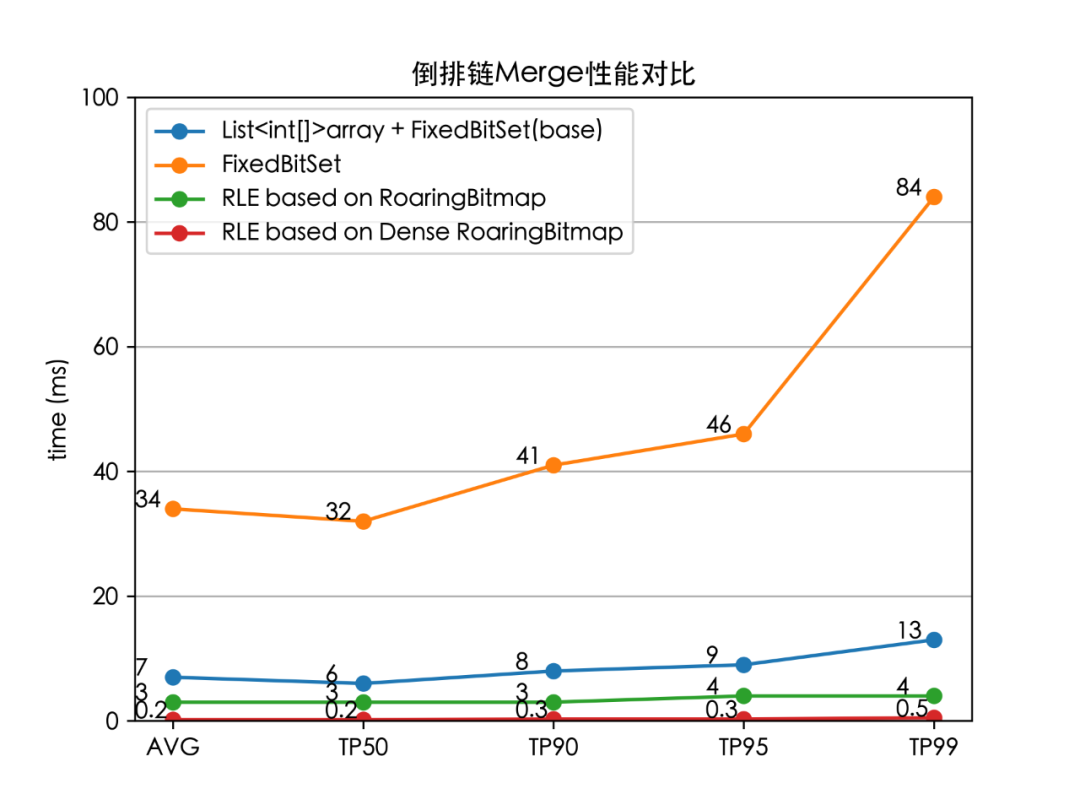
我們實(shí)現(xiàn)的 RLE based Dense RoaringBitmap,相比官方的基準(zhǔn)實(shí)現(xiàn)耗時降低了 96%(TP99 13 ms 下降至 0.5 ms)。
4.4 功能集成
至此,核心的倒排索引問題已經(jīng)解決,后續(xù)主要為工程問題:如何在 Elasticsearch 系統(tǒng)中集成基于 RLE 的倒排格式。對于高吞吐高并發(fā)的C端在線場景,我們希望盡可能保障線上的穩(wěn)定,對開源數(shù)據(jù)格式的兼容,保障前向的兼容,做到隨時可降級。
工程部分主要分為兩部分:倒排索引的集成和在線檢索鏈路。以下主要介紹全量索引部分的鏈路設(shè)計。
4.4.1 倒排索引集成
倒排索引格式的改造,一般情況下,需要實(shí)現(xiàn)一套 PostingsFormat,并實(shí)現(xiàn)對應(yīng)的 Reader、Writer。為了保證對原有檢索語句的兼容,支持多種場景的檢索,以及為了未來能夠無縫的配合 Elasticsearch 的版本升級,我們并沒有選擇直接實(shí)現(xiàn)一組新的 PostingsFormat,避免出現(xiàn)不兼容的情況導(dǎo)致無法升級版本。我們選擇了基于現(xiàn)有的倒排格式,在服務(wù)加載前后初始化 RLE 倒排,并考慮到業(yè)務(wù)場景,我們決定將 RLE 倒排全量放入內(nèi)存中,以達(dá)到極致的性能。具體的解決方案為:
索引加載過程中增加一組 Hook,用于獲取現(xiàn)有的 InternalEngine( Elasticsearch中負(fù)責(zé)索引增刪改查的主要對象 )。 對所有的 semgents 遍歷讀取數(shù)據(jù),解析倒排數(shù)據(jù)。 對所有配置了 RLE 倒排優(yōu)化的字段,生成 RLE 倒排表。 將 RLE 倒排表與 segment 做關(guān)聯(lián),保證后續(xù)的檢索鏈路中能獲取到倒排表。
為了避免內(nèi)存泄漏,我們也將索引刪除,segment 變更的場景進(jìn)行了相應(yīng)的處理。
4.4.2 在線檢索鏈路
在線檢索鏈路也采用了無侵入兼容的實(shí)現(xiàn),我們實(shí)現(xiàn)了一套新的檢索語句,并且在索引無 RLE 倒排的情況下,可以降級回原生的檢索類型,更加安全。
我們基于 Elasticsearch 的插件機(jī)制,生成一組新的 Query,實(shí)現(xiàn)了其 AbstractQueryBuilder,實(shí)現(xiàn)對 Query 的解析與改寫,并將 Query 與 RLE 倒排進(jìn)行關(guān)聯(lián),我們通過改寫具體的檢索實(shí)現(xiàn),將整個鏈路集成到 Elasticsearch 中。
5. 性能收益
由協(xié)調(diào)節(jié)點(diǎn)進(jìn)行請求的分發(fā),發(fā)送到各個檢索節(jié)點(diǎn)上。 每個數(shù)據(jù)節(jié)點(diǎn)的各自進(jìn)行檢索,并返回檢索結(jié)果給協(xié)調(diào)節(jié)點(diǎn),這一段各個數(shù)據(jù)節(jié)點(diǎn)的耗時即“數(shù)據(jù)節(jié)點(diǎn)查詢耗時”。 協(xié)調(diào)節(jié)點(diǎn)等待所有數(shù)據(jù)節(jié)點(diǎn)的返回,協(xié)調(diào)節(jié)點(diǎn)選取 Top K 后進(jìn)行 fetch 操作。1~3 步的完整耗時為“完整鏈路查詢耗時”。
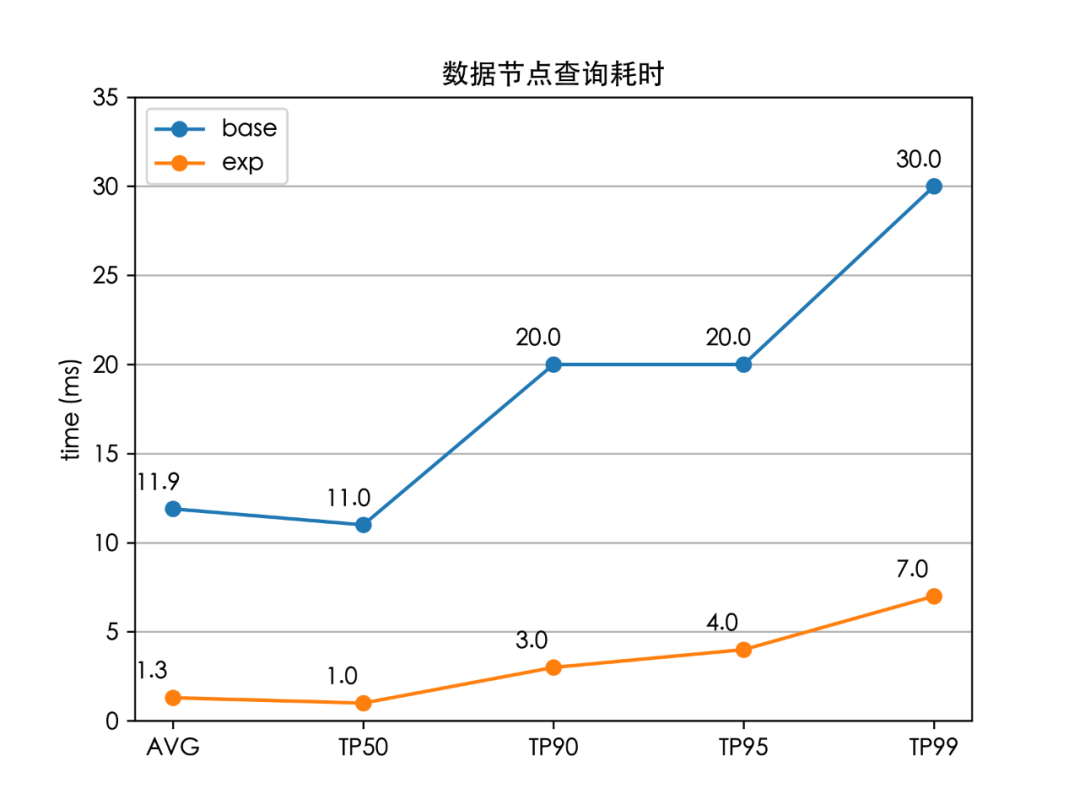
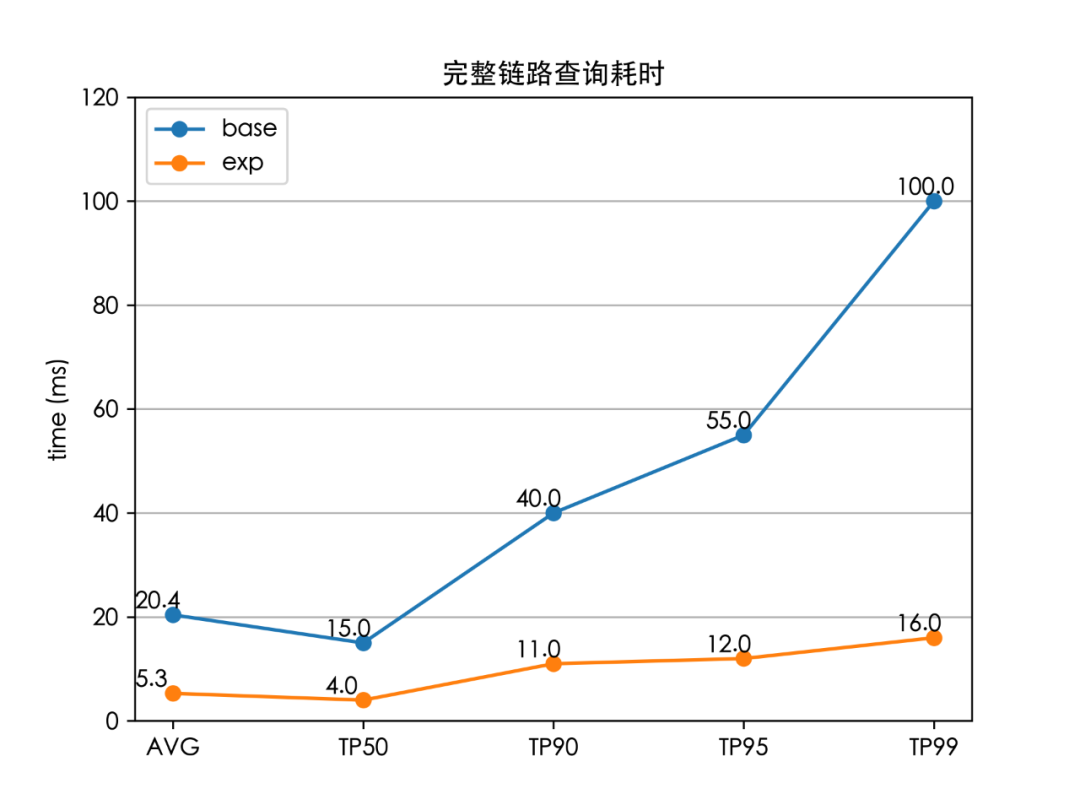
至此,我們成功將全鏈路的檢索時延(TP99)降低了 84%(100 ms 下降至 16 ms),解決了外賣搜索的檢索耗時問題,并且線上服務(wù)的 CPU 也大大降低。
6. 總結(jié)與展望
本文主要針對搜索業(yè)務(wù)場景中遇到的問題,進(jìn)行問題分析、技術(shù)選型、壓測、選擇合適的解決方案、集成、灰度驗(yàn)證。我們最終實(shí)現(xiàn)了一套基于 RLE 倒排格式,作為一種新型的倒排格式,徹底解決了這個場景上的性能瓶頸,從分析至上線的流程長達(dá)數(shù)月。本文希望能提供一個思路,讓其他同學(xué)在遇到 Elasticsearch 相關(guān)的性能問題時,也能遵循相同的路徑,解決業(yè)務(wù)上的問題。
一般的,我們分析問題可以遵循這樣的路徑:
明確性能問題后,首先通過流量錄制,獲得一個用于后續(xù)基準(zhǔn)壓測的測試集合。 通過相關(guān)的性能分析工具,先明確是否存在 CPU 的熱點(diǎn)或 IO 問題,對于 Java 技術(shù)棧,有很多常見的可用于分析性能的工具,美團(tuán)內(nèi)部有 Scaple 分析工具,外部可以使用 JProfiler、Java Flight Recorder、Async Profiler、Arthas、perf 這些工具。 對分析火焰圖進(jìn)行分析,配合源代碼,進(jìn)行數(shù)據(jù)分析和驗(yàn)證。 此外在 Elasticsearch 中還可以通過 Kibana 的 Search Profiler 用于協(xié)助定位問題。在錄制大量的流量,抽樣分析后,以我們的場景為例,進(jìn)行 Profiler 后可以明確 TermInSetQuery 占用了一半以上的耗時。 明確問題后從索引、檢索鏈路兩側(cè)進(jìn)行分析,評估問題,進(jìn)行多種解決方案的設(shè)計與嘗試,通過 Java Microbenchmark Harness(JMH)代碼基準(zhǔn)測試工具,驗(yàn)證解決方案的有效性。 集成驗(yàn)證最終效果。

我們最終實(shí)現(xiàn)的關(guān)鍵點(diǎn):
使用哈希表來實(shí)現(xiàn)索引 Term 的精確查找,以此減少倒排鏈的查詢與讀取的時間。 選取 RoaringBitmap 作為存儲倒排鏈的數(shù)據(jù)結(jié)構(gòu),并與 RLE Container 相結(jié)合,實(shí)現(xiàn)對倒排鏈的壓縮存儲。當(dāng)然,最重要的是,RLE 編碼將倒排鏈的合并問題轉(zhuǎn)換成了排序問題,實(shí)現(xiàn)了批量合并,從而大幅度減少了合并的性能消耗。
當(dāng)然,我們的方案也還具有一些可以繼續(xù)探索優(yōu)化的地方。我們進(jìn)行具體方案開發(fā)的時候,主要考慮解決我們特定場景的問題,做了一些定制化,以取得最大的性能收益。在一些更通用的場景上,也可以通過 RLE 倒排獲得收益,例如根據(jù)數(shù)據(jù)的分布,自動選擇 bitmap/array/RLE 容器,支持倒排鏈重疊的情況下的數(shù)據(jù)合并。
我們在發(fā)現(xiàn)也有論文與我們的想法不謀而合,有興趣了解可以參考具體論文[9]。另外,在增量索引場景下,如果增量索引的變更量非常大,那么勢必會遇到頻繁更新內(nèi)存 RLE 倒排的情況,這對內(nèi)存和性能的消耗都不小,基于性能的考量,也可以直接將 RLE 倒排索引的結(jié)構(gòu)固化到文件中,即在寫索引時就完成對倒排鏈的編碼,這樣就能避免這一問題。
7. 作者簡介
澤鈺、張聰、曉鵬等,均來自美團(tuán)到家事業(yè)群/搜索推薦技術(shù)部-搜索工程團(tuán)隊(duì)。
8. 參考文獻(xiàn)
[1] https://en.wikipedia.org/wiki/Run-length_encoding
[2] https://www.elastic.co/guide/en/elasticsearch/reference/7.10/query-dsl-geo-polygon-query.html
[4] Frame of Reference and Roaring Bitmaps
[5] https://www.elastic.co/cn/blog/index-sorting-elasticsearch-6-0
[6] Chambi S, Lemire D, Kaser O, et al. Better bitmap performance with roaring bitmaps[J]. Software: practice and experience, 2016, 46(5): 709-719.
[7] Lemire D, Ssi‐Yan‐Kai G, Kaser O. Consistently faster and smaller compressed bitmaps with roaring[J]. Software: Practice and Experience, 2016, 46(11): 1547-1569.
[8] 檢索兩階段流程:https://www.elastic.co/guide/cn/elasticsearch/guide/current/_fetch_phase.html#_fetch_phase
— 完 —
點(diǎn)這里??關(guān)注我,記得標(biāo)星呀~