
Python實現(xiàn)時間序列的分類預測

來源:Deephub IMBA 機器學習算法那些事 本文約1800字,建議閱讀9分鐘
本文將遵循 CRISP-DM 流程模型,以便我們采用結(jié)構(gòu)化方法來解決業(yè)務案例。
本文將以股票交易預測作為示例項目。我們用 AI 模型預測股票第二天是漲還是跌。在此背景下,比較了分類算法 XGBoost、隨機森林和邏輯分類器。文章的另外一個重點是數(shù)據(jù)準備,我們必須如何轉(zhuǎn)換數(shù)據(jù)以便模型可以處理它。
在本文中,我們將遵循 CRISP-DM 流程模型,以便我們采用結(jié)構(gòu)化方法來解決業(yè)務案例。CRISP-DM 特別適用于潛在分析,通常在行業(yè)中用于構(gòu)建數(shù)據(jù)科學項目。
另外就是我們將使用 Python 包 openbb。這個包以包含了一些來自金融部門的數(shù)據(jù)源,我們可以方便的使用它。
首先就是安裝必須的庫:
pip install pandas numpy “openbb[all]” swifter scikit-learn
業(yè)務理解
首先應該了解我們要解決的問題, 在我們的例子中,可以將問題定義如下:
預測股票代碼 AAPL 的股價第二天會上漲還是下跌。
然后就是應該考慮手頭有什么樣的機器學習模型的問題。我們想預測第二天股票是上漲還是下跌。所以這是一個分類問題(1:股票第二天上漲或 0:股票第二天下跌)。在分類問題中,我們預測一個類別。在我們的例子中,是一個 0 類和 1 類的二元分類。
數(shù)據(jù)理解和準備
數(shù)據(jù)理解階段側(cè)重于識別、收集和分析數(shù)據(jù)集。第一步,我們下載 Apple 股票數(shù)據(jù)。以下是如何使用 openbb 執(zhí)行此操作:
data = openbb.stocks.load(symbol = 'AAPL',start_date = '2023-01-01',end_date = '2023-04-01',monthly = False)data
該代碼下載 2023-01-01 和 2023-04-01 之間的數(shù)據(jù)。下載的數(shù)據(jù)包含以下信息:
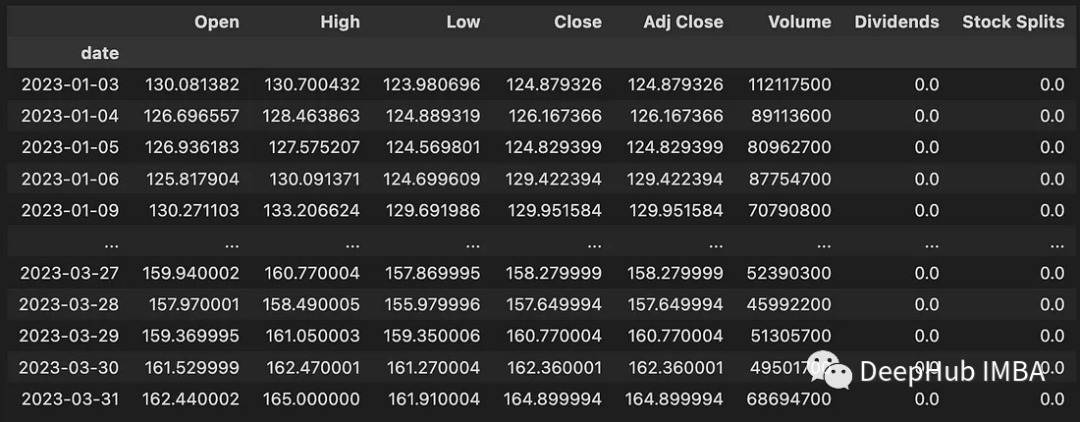
-
Open:美元每日開盤價 -
High:當日最高價(美元) -
Low:當日最低價(美元) -
Close:美元每日收盤價 -
Adj Close:與股息或股票分割相關(guān)的調(diào)整后收盤價 -
Volume:交易的股票數(shù)量 -
Dividends:已付股息 -
Stock Splits:股票分割執(zhí)行
我們已經(jīng)下載了數(shù)據(jù),但是數(shù)據(jù)還不適合建模分類模型。所以仍然需要為建模準備數(shù)據(jù)。所以需要編寫了一個函數(shù)來下載數(shù)據(jù),然后對其進行轉(zhuǎn)換以進行建模。以下代碼顯示了此功能:
def get_training_data(symbol, start_date, end_date, monthly_bool=True, lookback=10):data = openbb.stocks.load(symbol = symbol,start_date = start_date,end_date = end_date,monthly = monthly_bool)data = get_label(data)data_up_down = data['up_down'].to_numpy()training_data = get_sequence_data(data_up_down, lookback)return training_data
這里面包含的第一個函數(shù)時get_label():
def encoding(n):if n > 0:return 1else:return 0def get_label(data):data['Delta'] = data['Close'] - data['Open']data['up_down'] = data['Delta'].swifter.apply(lambda d: encoding(d))return data
他的主要工作是:計算收盤價和開盤價之間的差值。然后我們用 1 標記股價上漲的所有日期,股價下跌的所有日期都標記為 0。另外的up_down列包含股票價格在特定日期是上漲還是下跌。這里使用 swifter.apply() 函數(shù)替代 pandas apply()是因為 swifter 提供多核支持。
第二個函數(shù)是get_sequence_data()。參數(shù) lookback 指定預測中包含過去多少天。get_sequence_data()代碼如下 :
def get_sequence_data(data_up_down, lookback):shape = (data_up_down.shape[0] - lookback + 1, lookback)strides = data_up_down.strides + (data_up_down.strides[-1],)return np.lib.stride_tricks.as_strided(data_up_down, shape=shape, strides=strides)
這個函數(shù)有兩個參數(shù):data_up_down 和 lookback。它返回一個新的 NumPy 數(shù)組,該數(shù)組表示具有指定窗口大小的 data_up_down 數(shù)組的滑動窗口視圖,該窗口大小由 lookback 參數(shù)確定。為了說明這個函數(shù)是如何工作的,我們看一個小例子。
get_sequence_data(np.array([1, 2, 3, 4, 5, 6]), 3)結(jié)果如下:
array([[1, 2, 3],[2, 3, 4],[3, 4, 5],[4, 5, 6]])
在下文中,我們下載 Apple 股票的數(shù)據(jù)并對其進行轉(zhuǎn)換以進行建模。我們使用 10 天的回溯期。
data = get_training_data(symbol = 'AAPL', start_date = '2023-01-01', end_date = '2023-04-01', monthly_bool = False, lookback=10)pd.DataFrame(data).to_csv("data/data_aapl.csv")
數(shù)據(jù)已經(jīng)準備完畢了,我們開始建模和評估模型。
建模
將數(shù)據(jù)讀入數(shù)據(jù)并生成測試和訓練數(shù)據(jù)。
data = pandas.read_csv("./data/data_aapl.csv")X=data.iloc[:,:-1]Y=data.iloc[:,-1]X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.33, random_state=4284, stratify=Y)
邏輯回歸:
該分類器是基于線性的模型,通常用作基線模型。我們使用scikit-learn的實現(xiàn):
model_lr = LogisticRegression(random_state = 42)model_lr.fit(X_train,y_train)y_pred = model_lr.predict(X_test)
XGBoost:
XGBoost 是為速度和性能而設計的梯度提升決策樹的實現(xiàn)。它屬于樹提升算法,將許多弱樹分類器依次連接。
model_xgb = XGBClassifier(random_state = 42)model_xgb.fit(X_train, y_train)y_pred = model_xgb.predict(X_test)
隨機森林:
隨機森林構(gòu)建多個決策樹。這種方法稱為集成學習,因為多個學習器是相互連接的,該算法屬于bagging方法。首字母縮寫詞“bagging”代表引導聚合。 這里也使用scikit-learn的實現(xiàn):
model_rf = RandomForestClassifier(random_state = 42)model_rf.fit(X_train, y_train)y_pred = model_rf.predict(X_test)
評估
在對模型進行建模和訓練之后,我們需要檢查模型在測試數(shù)據(jù)上的性能。測量指標是 Recall、Precision 和 F1-Score。下表顯示了結(jié)果。
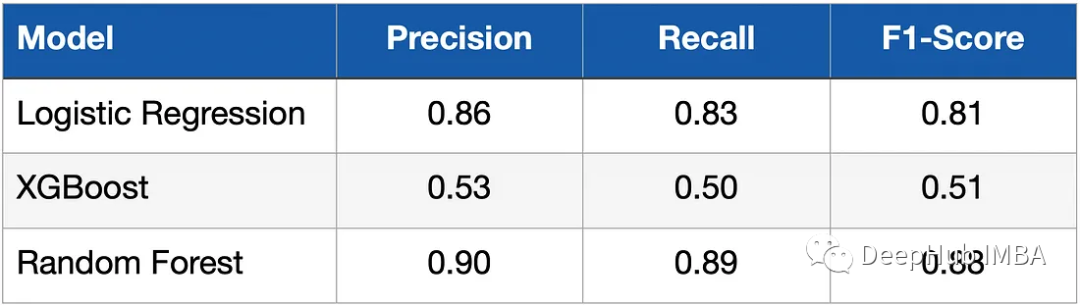
可以看到邏輯分類器(邏輯回歸)和隨機森林取得了明顯優(yōu)于XGBoost模型的結(jié)果, 這是什么原因呢?這是因為數(shù)據(jù)比較簡單,只有幾個維度的特征,并且數(shù)據(jù)的長度也很小,我們所有的模型也沒有進行調(diào)優(yōu)。
總結(jié)
我們這篇文章的主要目的是介紹如何將股票價格的時間序列轉(zhuǎn)換為分類問題,并且演示如何在數(shù)據(jù)處理時使用窗口函數(shù)將時間序列轉(zhuǎn)換為一個序列,至于模型并沒有太多的進行調(diào)優(yōu),所以對于效果評估來說越簡單的模型表現(xiàn)得就越好。