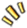關于Facebook故障的分析和反思
點擊上方“服務端思維”,選擇“設為星標”
回復”669“獲取獨家整理的精選資料集
回復”加群“加入全國服務端高端社群「后端圈」
今天美國東部標準時間上午11點51分開始,Facebook出現故障,最終六個小時以后才恢復。很多平臺(CloudFlare[1],ThousandEye[2])都做了故障歸因. 本文的第一部分簡要的概括一下故障原因,以翻譯整理這兩個參考網站資料為主, 第二個部分主要是從技術上和協議上分析分析一些缺陷, 最后一部分則是從管理的視角來看待基礎架構團隊的風險控制和激勵機制。
Facebook癱瘓原因
按照好基友的說法,遇到如此大規(guī)模的癱瘓不是DNS就是BGP出了問題。但是很抱歉,這次是兩個一起出了問題.
[UTC 15:40] ThousandEye監(jiān)控到Facebook應用出現DNS失效的情況,然后 繼而出現Authoritative DNS服務器不可達的情況:
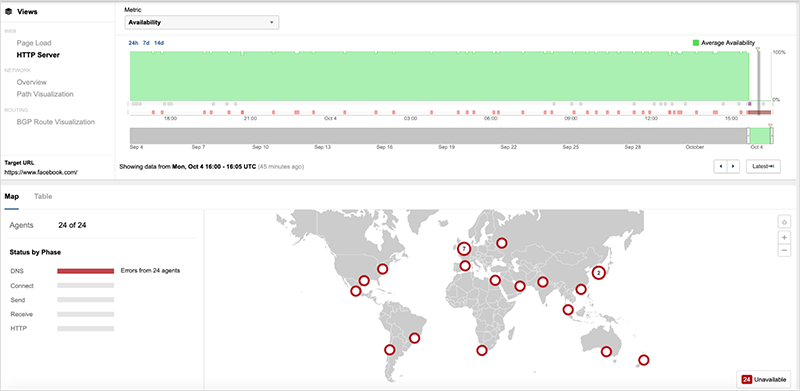
而Cloudflare在自身解析FB DNS服務出現故障后,懷疑是自己的DNS服務(1.1.1.1)故障,并在進一步的歸因分析中發(fā)現Facebook在UTC 1540時產生了大量的BGP更新:
進一步分析BGP消息發(fā)現了大量的路由并撤銷了關于DNS服務器的路由:

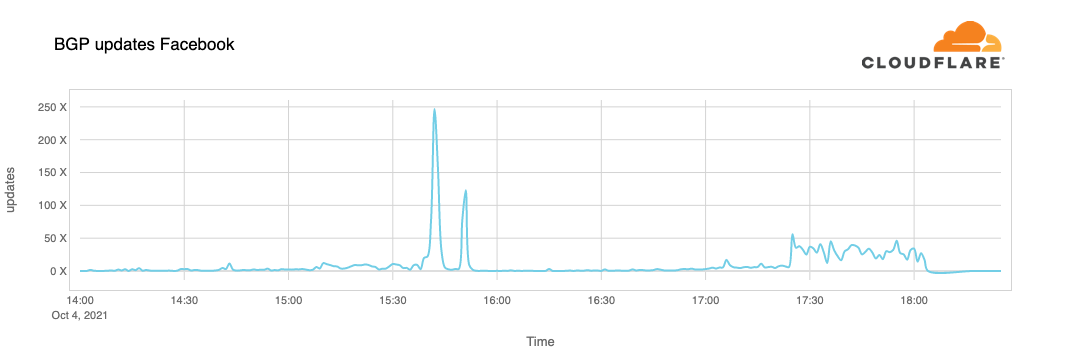
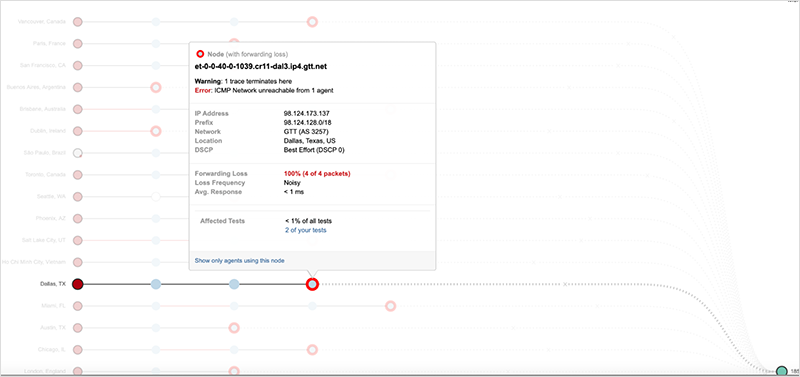
[UTC 17:40] ThousandEye也分析發(fā)現,這些關于DNS服務器的路由,在事故前是129.134.30.0/23 ?129.134.30.0/24 129.134.31.0/24的明細路由。但事故發(fā)生時它們可達的路由變成了129.134.0.0/17,并且數據包通過TraceRoute發(fā)現丟棄在FB的邊界路由器上,大概率斷定是人為配置錯誤,很有可能是流量調度時搞錯了。
而另兩個DNS服務器的路由已經被撤銷,導致路由在運營商邊界就不可達了
Cloudflare在后續(xù)的時間中發(fā)現,關于FB的DNS請求放大了30倍:
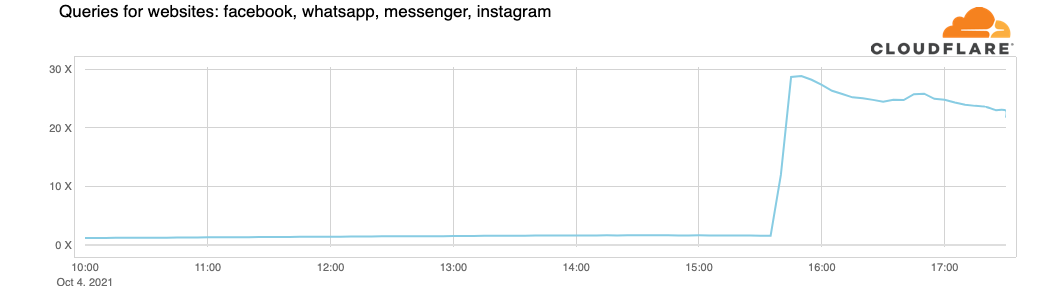
[UTC 21:00] CloudFlare發(fā)現FaceBook開始通過BGP通告了一些路由,直到21:17通告大量路由后,流量基本恢復.

任何一起大事故都是一系列偶然因素的疊加,從BGP路由的變化來看,很有可能是在做流量工程的時候,將路由發(fā)布錯了,極大概率又和BGP FlowSpec有關,但是一個值得反思的問題是過去幾個小時靜悄悄的沒有任何路由器的更新發(fā)出,有傳言稱是DNS掛了導致門禁系統(tǒng)掛了,從而無法進入機房恢復數據。
關于故障的反思.1 BGP
關于BGP帶來的重大事故已經不止一次發(fā)生了,BGP作為整個互聯網的基石,其協議用了30年了,BGP協議源于1989年1月第12次IETF會議, 由Len Bosack, Kirk Lougheed 和Yakov Rekhter提出實現一種所謂的邊界網關協議(Board Gateway Protocol", 其后在三張餐巾紙上完成了BGP設計的草稿. 然后在會議結束后的不到一個月的時間, 他們提出了兩個BGP的實現方案, 并在1989年6月發(fā)布了RFC1105.
協議設計之初的想法比較簡單, 第一個想法在路由信息中包含相關的路徑屬性, 并且使用它來提供無環(huán)路的路由. 第二個想法是采用增量更新來盡量減少路由信息在兩個路由器之間的交互. 第三個想法則是通過TCP來保證可靠傳輸. 最后一個想法則是使用TLV的方式來定義數據結構, 這樣使得協議擁有了很好的擴展性.
但是30年后,其主要的問題是其通信和計算機制已經不能滿足大量路由(接近1M前綴)的需求了。TCP帶來的Head Of line Blocking導致了BGP通信過程中收斂緩慢。4Byte-ASN和IPv4地址交易帶了路由前綴大量更新。數據中心內針對BGP-EVPN的擴展和使用BGP FlowSpec使得協議棧越來越復雜。互聯網上各種魔改的開源BGP(FRR-OpenBGP/GoBGP)使得協議互通時出現Bug的幾率急劇上升。當然最嚴重的問題是:BGP狀態(tài)機和TCP的耦合:
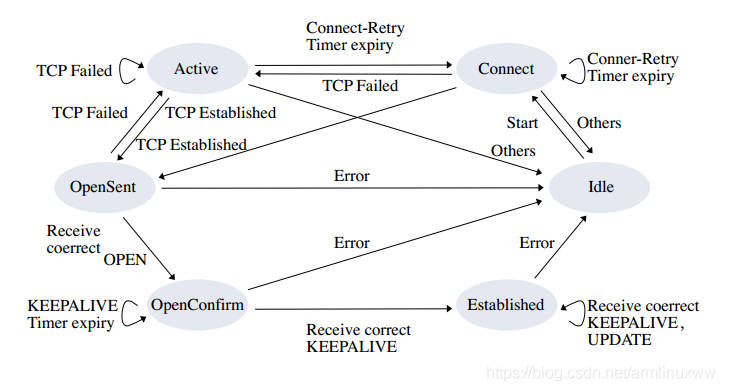
其實早在10多年前我就看到了這個問題,簡單的修復方式是使用MultiThread構建多個BGP Peering的會話來發(fā)送不同的Address-Family信息,另一種是針對路徑上的一些問題,使用MultiHoming和MultiStreaming的方式,也就是使用BGP Over SCTP的處理方式,并且在10多年前就寫了相應的RFC-Draft
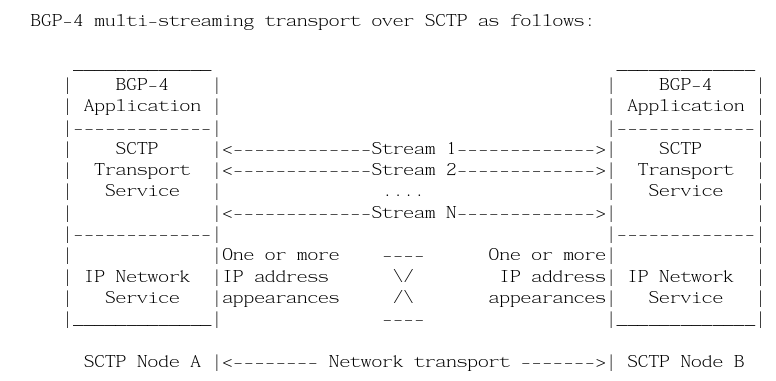
但是最終因為當時BGP并未承載如此大的流量以及SCTP協議棧本身的失敗,所以擱置了.
BGP另一個問題是其低效的一致性收斂算法。BGP協議設計時還是剛到486的年代,自然有一些自身的限制和容量的取舍,eBGP防環(huán)可以通過AS_PATH,而iBGP不同,因為出于防環(huán)的考慮,iBGP收到更新后不能將其傳給其它iBGP對等體,因此必須要將AS內部的路由器進行iBGP Fullmesh連接。事實上, 對于一個大型的運營商其內部可能有數以百計的BGP路由器并需要全互聯形成iBGP對等體.
這樣的部署方式對于運營商來說是不切實際并不被接受的. 因此Tony Bates和Ravi Chandra在1996年6月提
出了RFC1966: Route Reflector 作為一種避免iBGP Fullmesh的備選方案。而提出BGP-RR的Ravi Chandra就是支持我搞ML在網計算的大佬:

現在說大爺的BGP-RR有問題,好像有點尷尬。但是事實如此,畢竟國內好多運營商還專門拿我們做的某款路由器來做整個骨干網的RR,所以里面大大小小的問題我都清楚,調TCP-Stack,優(yōu)化QoS這些都干過...
結論: 其實不光我說的,以前阿里的依群總也講過BGP這樣的協議發(fā)展了20、30年了也急需做一些變革了。而這些變革就在分布式一致性上,也就是我為什么建議在域內使用ETCD代替BGP路由并構建Ruta控制平面[3]的根本原因。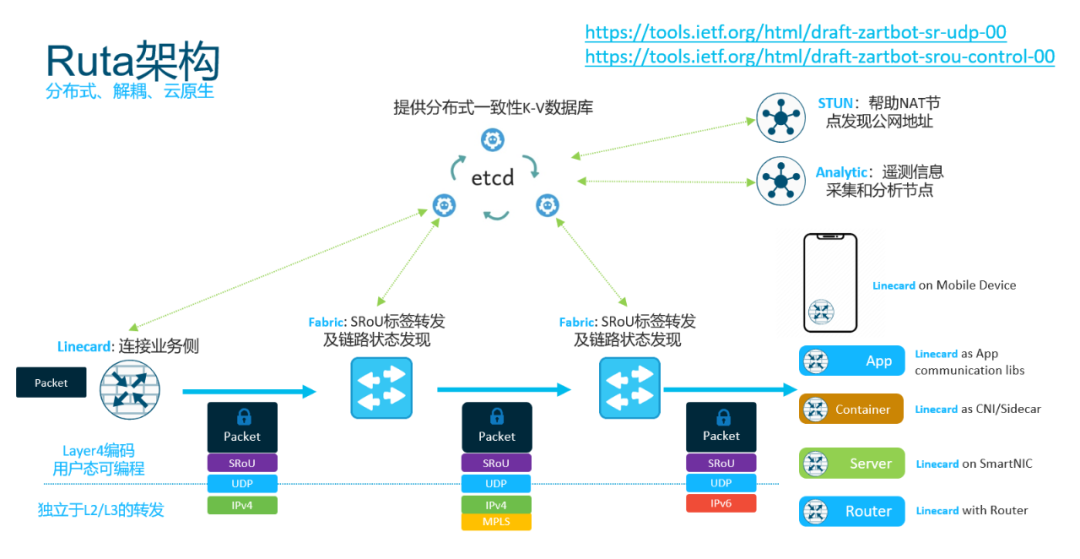
在域內將iBGP的一致性轉換為分布式K-V數據庫同步的處理方式.
另一方面你們可以看到NSDI'21上Google發(fā)布的Orion[4] Google便是使用其分布式數據庫來保存路徑信息和域內的一致性。而Ruta同樣如此,采用ETCD來實現。
Google便是使用其分布式數據庫來保存路徑信息和域內的一致性。而Ruta同樣如此,采用ETCD來實現。
具體關于控制面協議設計,去看今年早些時候寫的一文吧
關于故障的反思.2 互聯
當然BGP的失效有可能是中間某個運營商的錯誤配置導致的,雖然這次FB的故障是FB自身,但是下次有哪個運營商發(fā)布錯了劫持了Facebook DNS地址呢?
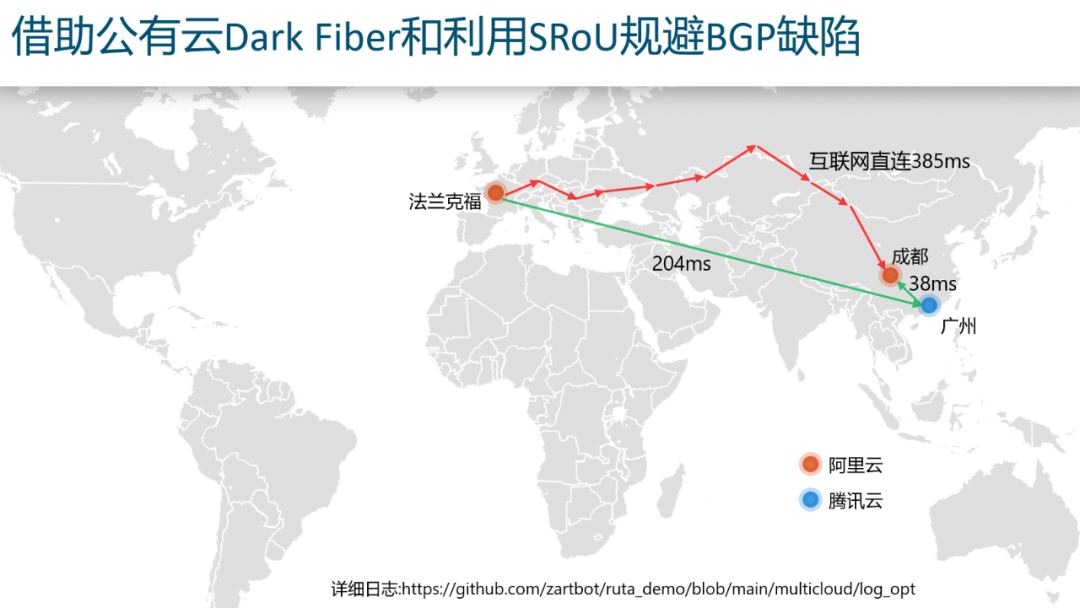
然后由于公有云和很多傳統(tǒng)運營商都有Peering,可以讓本地網絡可以盡快的接到云上,這樣就規(guī)避了傳統(tǒng)的Internet路由使用BGP跨越多個運營商的缺陷,在不改變Internet架構的同時,構建了一個Overlay將部分云節(jié)點構成了Transit-AS
關于故障的反思.3 DNS
DNS其實某種意義上來看也是一種基于域名的路由協議,這也是我前幾個月要自己開發(fā)一個開源項目ZaDNS的原因,傳統(tǒng)的主機只能選擇一主一備兩個DNS服務器,然后通常我們又因為很多場景需要基于不同的Domain查詢不同的DNS服務器,因此有了基于DNS的Domain Based Routing的需求。另一方面針對CDN失效避免和CDN優(yōu)化需要進行可達性探測,還有針對網絡安全需要做ZTNA或者基于ML算法的DNS域名或者Bad Reputation Record的過濾,這些都一起實現好了開源出來了:
項目地址:
github.com/zartbot/zadns
關于故障的反思.4 監(jiān)控
針對BGP的監(jiān)控比較容易,有現成的BGP Monitor Protocol, 另一個比較有用的就是快速的TraceRoute,ThousandEye算是比較成功的一家了。當然TraceRoute和探針測量本來就很簡單:
TraceRoute我自己開源了一個并行的快速探測軟件:
github.com/zartbot/ztrace
而針對Internet的測量和統(tǒng)計,也有相應的最佳實踐:
關于故障的反思.5 激勵
基礎架構團隊主要是為整個業(yè)務提供算力、網絡等各種資源,基礎設施建設本來就是重資產支出的部門,簡單的來說一個純花錢的部門如何進行業(yè)績評估和激勵。從運營的角度不出事故永遠看不到這群人的重要性,而6小時的故障損失也一定程度上衡量了這種部門的關鍵性。
其實我們從另一個角度來看, 銀行攬儲的部門是不是有額外的獎金?但是這些部門也是純花錢的部門,畢竟攬儲來的錢不得付利息啊?那么為啥都是花錢一個有激勵,一個沒有呢?關鍵就是針對計算彈性的資源提供方如何進行轉移定價的問題。
內部資金轉移定價(FTP)是指,商業(yè)銀行內部資金中心與業(yè)務經營單位按照一定規(guī)則全額有償轉移資金,達到核算業(yè)務資金成本或收益等目的的一種內部經營管理模式。業(yè)務經營單位每筆負債業(yè)務所籌集的資金,均以該業(yè)務的FTP價格全額轉移給資金中心;每筆資產業(yè)務所需要的資金,均以該業(yè)務的FTP價格全額向資金管理部門購買。對于資產業(yè)務,FTP價格代表其資金成本,需要支付FTP利息;對于負債業(yè)務,FTP代表其資金收益,可以從中獲取FTP利息收入。
FTP能夠科學評價績效、優(yōu)化配置資源、合理引導定價、集中管理市場風險等,具體而言:一是以合理的資金成本或資金收益為基礎,逐步構建銀行對產品、對客戶、對個人的科學評價體系;二是以資金成本的準確計量為基礎,逐步建立和完善銀行資源配置機制、產品定價機制以及經風險調整后的績效評估機制;三是通過科學的產品FTP定價,剝離經營單位的市場風險,建立由專業(yè)化團隊集中管理市場風險的經營管理模式;四是通過FTP推廣,逐步推進資金管理體制改革,以及扁平化、事業(yè)部方式的全行條線為主的組織架構改革。而對于數字化資產我們同樣可以實施相應的FTP,為解決基礎架構部門和業(yè)務及應用部門相互利益分配會有很大的好處,從而進一步從財務核算上激勵雙方進行技術創(chuàng)新

基于FTP的機制還有一個好處是在基礎架構建設過程中,通過完整的端到端成本核算,能夠有利于激發(fā)團隊進行關鍵性的節(jié)點的創(chuàng)新和風險補償機制。
— 本文結束 —

關注我,回復 「加群」 加入各種主題討論群。
對「服務端思維」有期待,請在文末點個在看
喜歡這篇文章,歡迎轉發(fā)、分享朋友圈