
語義分割方向,國內(nèi)面試經(jīng)常會問哪些問題?
一.deeplab系列
1.簡述Deeplab v1網(wǎng)絡(luò)
DeepLab是結(jié)合了深度卷積神經(jīng)網(wǎng)絡(luò)(DCNNs)和概率圖模型(DenseCRFs)的方法。在實(shí)驗(yàn)中發(fā)現(xiàn)DCNNs做語義分割時(shí)精準(zhǔn)度不夠的問題,根本原因是DCNNs的高級特征的平移不變性(即高層次特征映射,根源在于重復(fù)的池化和下采樣)。針對信號下采樣或池化降低分辨率,DeepLab是采用的atrous(帶孔)算法擴(kuò)展感受野,獲取更多的上下文信息。另外,DeepLab 采用完全連接的條件隨機(jī)場(CRF)提高模型捕獲細(xì)節(jié)的能力。論文模型基于 VGG16,在 Titan GPU 上運(yùn)行速度達(dá)到了 8FPS,全連接 CRF 平均推斷需要 0.5s ,在 PASCAL VOC-2012 達(dá)到 71.6% IOU accuracy。
2.簡述Deeplab v2網(wǎng)絡(luò)
DeepLabv2 是相對于 DeepLabv1 基礎(chǔ)上的優(yōu)化。DeepLabv1 在三個(gè)方向努力解決,但是問題依然存在:特征分辨率的降低、物體存在多尺度,DCNN 的平移不變性。因 DCNN 連續(xù)池化和下采樣造成分辨率降低,DeepLabv2 在最后幾個(gè)最大池化層中去除下采樣,取而代之的是使用空洞卷積,以更高的采樣密度計(jì)算特征映射。物體存在多尺度的問題,DeepLabv1 中是用多個(gè) MLP 結(jié)合多尺度特征解決,雖然可以提供系統(tǒng)的性能,但是增加特征計(jì)算量和存儲空間。論文受到 Spatial Pyramid Pooling (SPP) 的啟發(fā),提出了一個(gè)類似的結(jié)構(gòu),在給定的輸入上以不同采樣率的空洞卷積并行采樣,相當(dāng)于以多個(gè)比例捕捉圖像的上下文,稱為 ASPP (atrous spatial pyramid pooling) 模塊。
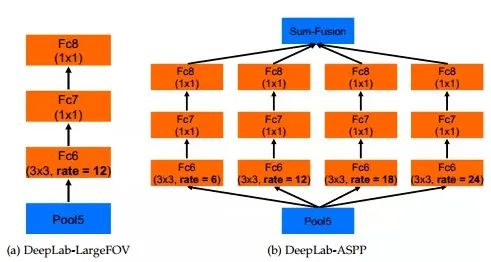
相比于DeepLab v1,deeplab v2在之前的基礎(chǔ)上做了三個(gè)方面的貢獻(xiàn):一是使用Atrous Convolution 代替原來上采樣的方法,比之前得到更高像素的score map,并且增加了感受野的大小;二是使用ASPP 代替原來對圖像做預(yù)處理resize 的方法,使得輸入圖片可以具有任意尺度,而不影響神經(jīng)網(wǎng)絡(luò)中全連接層的輸入大小;三是使用全連接的CRF,利用低層的細(xì)節(jié)信息對分類的局部特征進(jìn)行優(yōu)化。
論文模型基于 ResNet,在 NVidia Titan X GPU 上運(yùn)行速度達(dá)到了 8FPS,全連接 CRF 平均推斷需要 0.5s ,在耗時(shí)方面和 DeepLabv1 無差異,但在 PASCAL VOC-2012 達(dá)到 79.7 mIOU。
3.簡述Deeplab v3網(wǎng)絡(luò)相比于之前的v1和v2網(wǎng)絡(luò)有哪些改進(jìn)
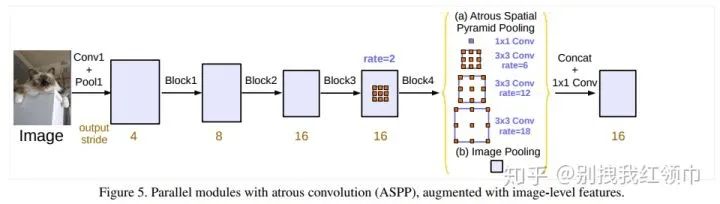
①重新討論了空洞卷積的使用,這讓我們在級聯(lián)模塊和空間金字塔池化的框架下,能夠獲取更大的感受野從而獲取多尺度信息。②改進(jìn)了ASPP模塊:由不同采樣率的空洞卷積和BN層組成,我們嘗試以級聯(lián)或并行的方式布局模塊。③討論了一個(gè)重要問題:使用大采樣率的3×3的空洞卷積,因?yàn)閳D像邊界響應(yīng)無法捕捉遠(yuǎn)距離信息,會退化為1×1的卷積, 我們建議將圖像級特征融合到ASPP模塊中。④闡述了訓(xùn)練細(xì)節(jié)并分享了訓(xùn)練經(jīng)驗(yàn)。
介紹deeplabv3,畫出backbone
DeepLab V3將空洞卷積應(yīng)用在了級聯(lián)模塊,并且改進(jìn)了ASPP模塊。backbone還是resnet 101. 增強(qiáng)ASPP模塊,復(fù)制resnet最后的block級聯(lián)起來,加入BN。沒有使用CRFs新的ASPP模塊包括:一個(gè)1×1卷積和3個(gè)3×3的空洞卷積(采樣率為(6,12,18)),每個(gè)卷積核都有256個(gè)且都有BN層;包含圖像級特征image-level features(即全局平均池化Global Avearge Pooling);所有分支得到的結(jié)果concate起來通過1×1卷積之后得到最終結(jié)果。
DeepLab V3采用atrous convolution的上采樣濾波器提取稠密特征映射和去捕獲大范圍的上下文信息。具體來說,編碼多尺度信息,提出的級聯(lián)模塊逐步翻倍的atrous rates,提出的atrous spatial pyramid pooling模塊增強(qiáng)圖像級的特征,探討了多采樣率和有效視場下的濾波器特性。實(shí)驗(yàn)結(jié)果表明,該模型在Pascalvoc 2012語義圖像分割基準(zhǔn)上比以前的DeppLab版本有了明顯的改進(jìn),并取得了與其他先進(jìn)模型相當(dāng)?shù)男阅堋?/p>
DeepLab V3的改進(jìn)主要包括以下幾方面:1)提出了更通用的框架,適用于任何網(wǎng)絡(luò)
2)復(fù)制了ResNet最后的block,并級聯(lián)起來3)在ASPP中使用BN層4)去掉了CRF。
deeplabv3的損失函數(shù)交叉熵?fù)p失函數(shù)
4.deeplabv3+系列
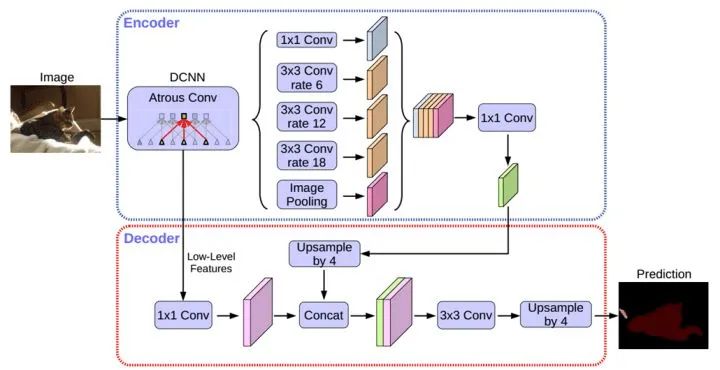
DeepLabv3 +采用編碼器解碼器結(jié)構(gòu)擴(kuò)展了DeepLabv3。編碼器模塊通過在多個(gè)尺度上應(yīng)用atrous卷積來編碼多尺度上下文信息,而簡單但有效的解碼器模塊沿著對象邊界細(xì)化分割結(jié)果。DeepLabv3+模型中使用ResNet-101作為網(wǎng)絡(luò)主干。探索Xecption模型, 將depthwise separable convolution應(yīng)用到ASPP和解碼模塊上(更快,更穩(wěn)定)。
5.條件隨機(jī)場(CRF)后處理的目的
CRF使像素級別的類別標(biāo)簽的多類別輸出與底層圖像信息(如像素間的相互關(guān)系)有關(guān),這種結(jié)合尤其重要,這也是關(guān)注于局部細(xì)節(jié)的CNN所未能考慮到的。CRF 將圖像中每個(gè)像素點(diǎn)所屬的類別都看作一個(gè)變量xi,然后考慮任意兩個(gè)變量之間的關(guān)系,建立一個(gè)完全圖。
6.簡要闡述一下UNet網(wǎng)絡(luò)
UNet網(wǎng)絡(luò)可以簡單看為先下采樣,經(jīng)過不同程度的卷積,學(xué)習(xí)了深層次的特征,再經(jīng)過上采樣回復(fù)為原圖大小,上采樣用反卷積實(shí)現(xiàn)。輸出類別數(shù)量的特征圖,最后使用激活函數(shù)softmax將特征圖轉(zhuǎn)換為概率圖,針對某個(gè)像素點(diǎn),如輸出是[0.1,0.9],則判定這個(gè)像素點(diǎn)是第二類的概率更大。
網(wǎng)絡(luò)結(jié)構(gòu)可以看成3個(gè)部分:
①下采樣:網(wǎng)絡(luò)的紅色箭頭部分,池化實(shí)現(xiàn)
②上采樣:網(wǎng)絡(luò)的綠色箭頭部分,反卷積實(shí)現(xiàn)
③最后層的softmax:在網(wǎng)絡(luò)結(jié)構(gòu)中,最后輸出兩張fiture maps后,其實(shí)在最后還要做一次softmax,將其轉(zhuǎn)換為概率圖。
7. 簡述encode和decode思想
將一個(gè)input信息編碼到一個(gè)壓縮空間中 將一個(gè)壓縮空間向量解碼到一個(gè)原始空間中。
8. FCN與CNN最大的區(qū)別?
卷積層不再與FC層相連,而是加入一個(gè)全局池化層。
FCN是如何取代FC層的 FCN用卷積層代替FC層。
9.分割出來的結(jié)果通常會有不連續(xù)的情況,怎么處理?開運(yùn)算閉運(yùn)算
設(shè)定閾值,去掉閾值較小的連通集,和較小的空洞。
開運(yùn)算 = 先腐蝕運(yùn)算,再膨脹運(yùn)算(看上去把細(xì)微連在一起的兩塊目標(biāo)分開了)
開運(yùn)算總結(jié):(1)開運(yùn)算能夠除去孤立的小點(diǎn),毛刺和小橋,而總的位置和形狀不便。
(2)開運(yùn)算是一個(gè)基于幾何運(yùn)算的濾波器。(3)結(jié)構(gòu)元素大小的不同將導(dǎo)致濾波效果的不同。(4)不同的結(jié)構(gòu)元素的選擇導(dǎo)致了不同的分割,即提取出不同的特征。
閉運(yùn)算 = 先膨脹運(yùn)算,再腐蝕運(yùn)算(看上去將兩個(gè)細(xì)微連接的圖塊封閉在一起)
閉運(yùn)算總結(jié):(1)閉運(yùn)算能夠填平小湖(即小孔),彌合小裂縫,而總的位置和形狀不變。
(2)閉運(yùn)算是通過填充圖像的凹角來濾波圖像的。(3)結(jié)構(gòu)元素大小的不同將導(dǎo)致濾波效果的不同。(4)不同結(jié)構(gòu)元素的選擇導(dǎo)致了不同的分割。
10. 簡單闡述一下mIOU,寫出mIOU的計(jì)算公式
mIoU值是一個(gè)衡量圖像分割精度的重要指標(biāo)。mIoU可解釋為平均交并比,即在每個(gè)類別上計(jì)算IoU值(即真正樣本數(shù)量/(真正樣本數(shù)量+假負(fù)樣本數(shù)量+假正樣本數(shù)量))。

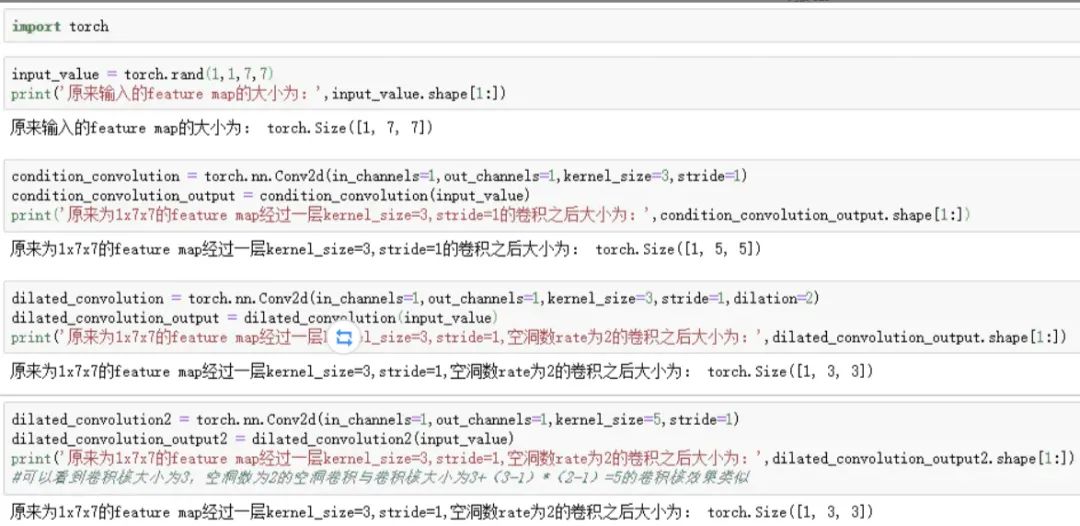
11.空洞卷積的具體實(shí)現(xiàn)
Dilated convolution就是為了在不是用pooling操作損失信息也能增加感受野。空洞卷積:在3*3卷積核中間填充0,有兩種實(shí)現(xiàn)方式,第一,卷積核填充0,第二,輸入等間隔采樣。空洞卷積的rate,代表傳統(tǒng)卷積核的相鄰之間插入rate-1個(gè)空洞數(shù)。當(dāng)rate=1時(shí),相當(dāng)于傳統(tǒng)的卷積核。擴(kuò)張卷積具有更大的感受野。
Pytorch實(shí)現(xiàn)過程如下:
13.簡要闡述一下圖像分割中常用的Loss
①Log loss
對于二分類而言,對數(shù)損失函數(shù)如下公式所示:
其中,y_i為輸入實(shí)例x_i的真實(shí)類別, p_i為預(yù)測輸入實(shí)例 x_i屬于類別 1的概率.對所有樣本的對數(shù)損失表示對每個(gè)樣本的對數(shù)損失的平均值,對于完美的分類器, 對數(shù)損失為 0。
此loss function每一次梯度的回傳對每一個(gè)類別具有相同的關(guān)注度!所以極易受到類別不平衡的影響。
②WCE Loss
帶權(quán)重的交叉熵loss — Weighted cross-entropy (WCE)
R為標(biāo)準(zhǔn)的分割圖,其中r_n為label 分割圖中的某一個(gè)像素的GT。P為預(yù)測的概率圖,p_n為像素的預(yù)測概率值,背景像素圖的概率值就為1-P。
只有兩個(gè)類別的帶權(quán)重的交叉熵為:
w為權(quán)重,缺點(diǎn)是需要人為的調(diào)整困難樣本的權(quán)重,增加調(diào)參難度。
③Focal loss
能否使網(wǎng)絡(luò)主動學(xué)習(xí)困難樣本呢?focal loss的提出是在目標(biāo)檢測領(lǐng)域,為了解決正負(fù)樣本比例嚴(yán)重失衡的問題。是由log loss改進(jìn)而來的,為了與log loss進(jìn)行對比,公式如下:
說白了就多了一個(gè) ,loss隨樣本概率的大小如下圖所示:
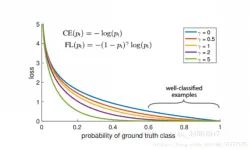
其基本思想就是,對于類別極度不均衡的情況下,網(wǎng)絡(luò)如果在log loss下會傾向于只預(yù)測負(fù)樣本,并且負(fù)樣本的預(yù)測概率p_i也會非常的高,回傳的梯度也很大。但是如果添加則會使預(yù)測概率大的樣本得到的loss變小,而預(yù)測概率小的樣本,loss變得大,從而加強(qiáng)對正樣本的關(guān)注度。
可以改善目標(biāo)不均衡的現(xiàn)象,對此情況比 binary_crossentropy 要好很多。
目前在圖像分割上只是適應(yīng)于二分類。需要添加額外的兩個(gè)全局參數(shù)alpha和gamma,對于調(diào)參不方便。
④Dice loss
dice loss的提出是在V-net中,其中的一段原因描述是在感興趣的解剖結(jié)構(gòu)僅占據(jù)掃描的非常小的區(qū)域,從而使學(xué)習(xí)過程陷入損失函數(shù)的局部最小值。所以要加大前景區(qū)域的權(quán)重。
Dice 可以理解為是兩個(gè)輪廓區(qū)域的相似程度,用A、B表示兩個(gè)輪廓區(qū)域所包含的點(diǎn)集,定義為:
其次Dice也可以表示為:其中TP,F(xiàn)P,F(xiàn)N分別是真陽性、假陽性、假陰性的個(gè)數(shù)。
二分類dice loss:
結(jié)論:
1.有時(shí)使用dice loss會使訓(xùn)練曲線有時(shí)不可信,而且dice loss好的模型并不一定在其他的評價(jià)標(biāo)準(zhǔn)上效果更好,例如mean surface distance 或者是Hausdorff surface distance。不可信的原因是梯度,對于softmax或者是log loss其梯度簡化而言為p-t,t為目標(biāo)值,p為預(yù)測值。而dice loss為,如果p,t過小則會導(dǎo)致梯度變化劇烈,導(dǎo)致訓(xùn)練困難。
2.屬于直接在評價(jià)標(biāo)準(zhǔn)上進(jìn)行優(yōu)化。
3.不均衡的場景下的確好使。
⑤IOU loss
可類比DICE LOSS,也是直接針對評價(jià)標(biāo)準(zhǔn)進(jìn)行優(yōu)化。
定義如下:
在圖像分割領(lǐng)域評價(jià)標(biāo)準(zhǔn)IOU實(shí)際上 ,而TP,F(xiàn)P,F(xiàn)N分別是真陽性、假陽性、假陰性的個(gè)數(shù)。
而作為loss function,定義 其中,
X為預(yù)測值而Y為真實(shí)標(biāo)簽。
IOU loss的缺點(diǎn)同DICE loss是相類似的,訓(xùn)練曲線可能并不可信,訓(xùn)練的過程也可能并不穩(wěn)定,有時(shí)不如使用softmax loss等的曲線有直觀性,通常而言softmax loss得到的loss下降曲線較為平滑。
參考文獻(xiàn)
參考鏈接
https://bbs.cvmart.net/topics/674/DeepLab
https://zhcv.github.io/2019/02/28/DeepLap-Series-Papers/
http://www.cxyzjd.com/searchArticle?qc=OpenCV%E9%97%AD%E8%BF%90%E7%AE%97&page=1
本文亮點(diǎn)總結(jié)
如果覺得有用,就請分享到朋友圈吧!
往期精彩:
【原創(chuàng)首發(fā)】機(jī)器學(xué)習(xí)公式推導(dǎo)與代碼實(shí)現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學(xué)習(xí)語義分割理論與實(shí)戰(zhàn)指南.pdf
求個(gè)在看