
2020年,語義分割可以在哪些方向進行研究并取得突破?
編輯:深度學習與計算機視覺
語義分割(Semantic Segmentation)說到底還是為了讓人工智體更好的去理解場景(Scene Understanding)。什么是理解場景?當我們在說讓一個智體去理解場景的時候,我們究竟在討論什么?這其中包含很多,場景中物體的語義,屬性,場景與物體之間的相對關系,場景中人與物體的交互關系,等等。說實話很難用一句話來概括,很多研究工作往往也都是在有限的任務范圍下給出了機器人理解其所視場景的定義。那么為什么語義分割對于場景理解來說這么重要?因為不管怎么說,場景理解中有些要素是繞不開的,例如目標物體的語義, 目標物體的坐標。當我們真正要應用場景理解的技術到實際生活中時,這兩個點幾乎是必需的。而語義分割恰好能夠同時提供這兩種重要的信息。
傳統(tǒng)的2D圖像語義分割技術經(jīng)過眾多研究人員幾年時間不停的迭代,已經(jīng)發(fā)展到了一個提升相當困難的時期。同時這也意味著這項技術已經(jīng)漸漸的趨于成熟。但傳統(tǒng)的2D分割還是有一定的局限性,比如我們很難從2D圖像中直接獲知物體的空間位置,以及其在整體空間中的布局。這很直觀,因為2D圖像捅破天也只有2D信息,想知道整體空間的位置信息還是需要更多的3D信息。事實上,這件事已經(jīng)有相當一部分人在做了。為了讓單純的2D圖像(RGB)具有深度信息從而轉(zhuǎn)變成RGB-D,我們發(fā)展了深度估計(Depth Estimation);為了讓RGB-D變成真正有用的3D信息,我們發(fā)展了三維重建(3D Reconstruction)技術;為了得到整個場景的三維點云,我們發(fā)展了SLAM;為了得到場景中點云的語義信息,我們又發(fā)展了基于點云的語義分割技術。這一整套流程下來,我們可以讓機器人從單純的2D圖像出發(fā),得到空間中物體三維的坐標,語義,和邊界信息。這一連串的思路十分完備,也非常本質(zhì)。然而3D數(shù)據(jù)往往又面臨著極為昂貴的計算成本與數(shù)據(jù)采集和標注的成本,不像2D數(shù)據(jù)有一臺手機就能采集,對于標注人員來說也不如2D圖像的標注來的那么直觀。
那么我們能不能依舊基于2D圖像,讓機器人對于整個空間中物體的坐標有更好的感知?
答案是肯定的。其實在相當一部分實際任務中,得到物體準確的3D坐標是一件精確過頭的事,就好比能用16位浮點數(shù)解決的任務我偏偏要用32位,可以但不是必要。很多時候我們需要3D坐標只是因為這是一個清晰的,看得見摸得著的,具體的數(shù)值目標。但再好的數(shù)值目標,跟實際使用體驗的關聯(lián)性也不是百分百對應的。就好像損失函數(shù)低不一定代表最后的準確率就高,數(shù)值準確率高不一定代表實際的人眼效果就好。扯遠了,話說回來,基于以上我所說的,我們在求解準確的3D信息所需要的代價與傳統(tǒng)的2D分割的局限之間找到了一個平衡點,也就是利用俯視語義圖(Top-down-view Semantic Map)來感知周圍環(huán)境物體的方位與布局。
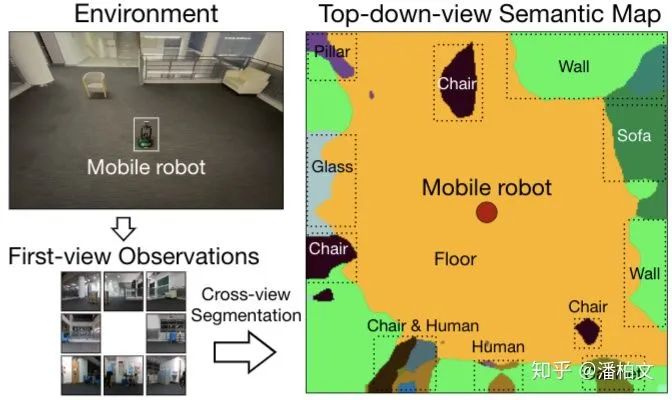
我們把從第一視角的2D圖像(First-view Observation)得到俯視語義圖(Top-down-view Semantic Map)的過程稱作跨視角語義分割(Cross-view Semantic Segmentation)。跨視角語義分割與傳統(tǒng)2D語義分割的區(qū)別在于我們得到的不再是一張與原圖逐像素對應的語義圖,而是一張俯視視角下看到的周圍環(huán)境的語義圖。另外對于模型的輸入來說,跨視角語義分割的輸入從2D語義分割的一張RGB圖變成了多張第一視角的任意模態(tài)的圖(RGB,Semantic Mask,Depth)。
由于這是一個新問題,現(xiàn)有的語義分割數(shù)據(jù)集并不支持我們?nèi)ビ柧氝@樣一個跨視角語義分割的模型。我們于是將目光投向了一些模擬仿真環(huán)境(Simulated Environment),例如House3D,Gibson Environment,Matterport3D。我們從這些模擬仿真環(huán)境中提取第一視角的圖像以及對應的俯視語義圖,從而完成訓練過程。然而仿真環(huán)境中提取的圖像與真實世界的圖像還是有著很大的差別,因此我們在部署我們的模型到真實世界的時候還做了一步半監(jiān)督的域適應(Domain Adaptation)。我們利用這樣一個仿真環(huán)境+半監(jiān)督域適應的流程暫時緩解了沒有真實數(shù)據(jù)的問題。但是在未來如果我們需要對這個方向進行長足的發(fā)展,真實世界的數(shù)據(jù)仍然是不可或缺的。
從模型結構的角度來看,我們的實驗發(fā)現(xiàn),由于不存在像素級的對應關系,傳統(tǒng)2D語義分割的模型結構并不能直接套用在我們跨視角語義分割的任務上。然而為了能夠繼承這些極為優(yōu)秀的,凝結了許多前人智慧的傳統(tǒng)2D語義分割的模型結構,我們提出了一種視角轉(zhuǎn)換模塊(View Transformer Module)插入到編碼器(Encoder)和解碼器(Decoder)之間。這種視角轉(zhuǎn)換模塊保持了原來的模型結構,從而在跨視角語義分割任務上更好的發(fā)揮作用。
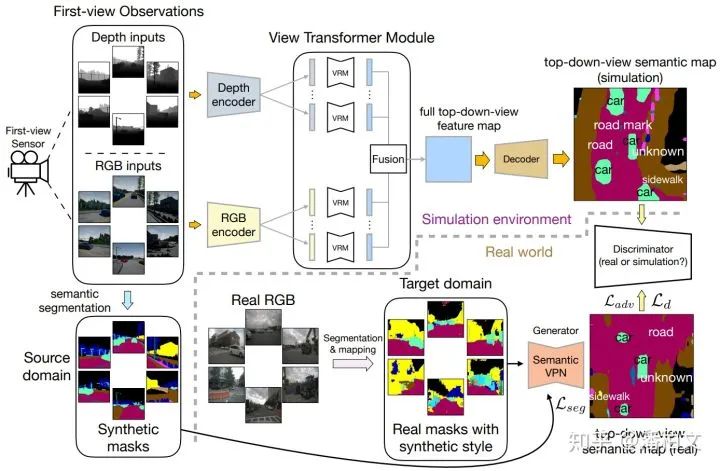
https://www.zhihu.com/question/376432270/answer/1301138347
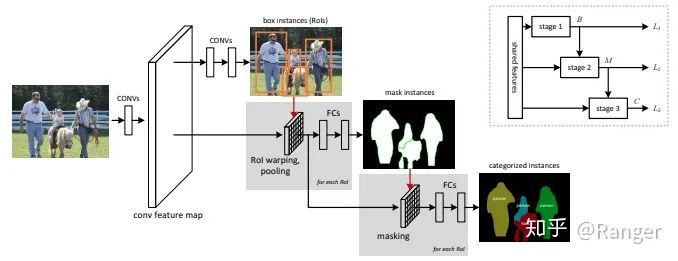
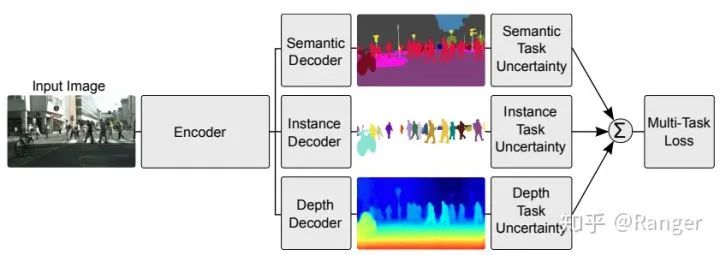
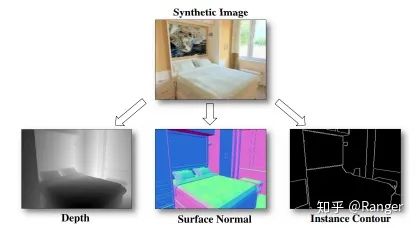
2.利用data-fusion來優(yōu)化semantic segmentation,例如:
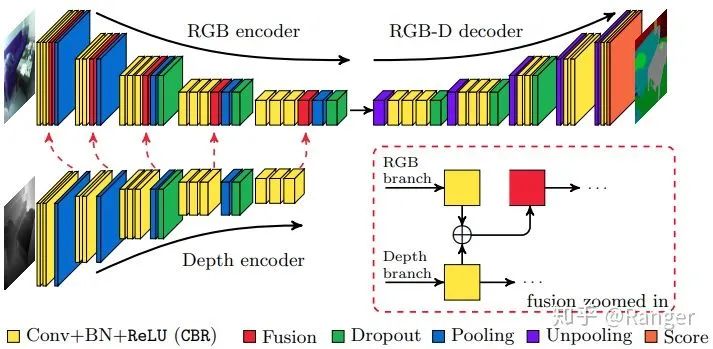
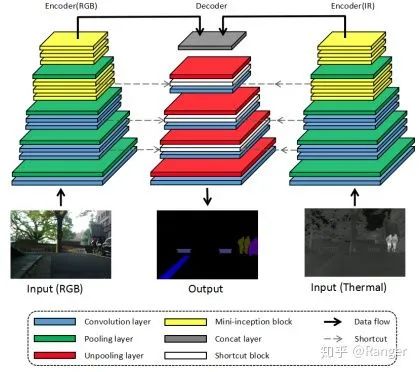


https://www.zhihu.com/question/376432270/answer/1301176481
其實是因為前面深度學習這一波走的太順了,尤其CNN出來,然后gan沒過多少年就出來了,其實你看看前面大概八十年的ai歷史,大部分時候圖像處理走的都很慢,那才是常態(tài)。
反正前路還是有點難的。
作者:Jowey https://www.zhihu.com/question/376432270/answer/1561921142
end
往期精彩:
【原創(chuàng)首發(fā)】機器學習公式推導與代碼實現(xiàn)30講.pdf
【原創(chuàng)首發(fā)】深度學習語義分割理論與實戰(zhàn)指南.pdf