
SWA:讓你的目標(biāo)檢測模型無痛漲點(diǎn)1% AP
 點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
點(diǎn)藍(lán)色字關(guān)注“機(jī)器學(xué)習(xí)算法工程師”
設(shè)為星標(biāo),干貨直達(dá)!
最近目標(biāo)檢測領(lǐng)域可謂是百花齊放,無論是anchor-free的檢測算法還是基于transformer的檢測算法都比較耀眼。雖然COCO 數(shù)據(jù)集上的AP值已經(jīng)刷到了0.61,但是其實(shí)很多模型在同樣條件下的mAP值差異也只是在1~2%。一篇最新的論文SWA Object Detection介紹了一個(gè)讓你的檢測模型無痛漲點(diǎn)1% AP值的策略:采用周期式學(xué)習(xí)速率(余弦退火學(xué)習(xí)速率)額外再訓(xùn)練你的模型12個(gè)epoch,然后簡單地平均每個(gè)epoch訓(xùn)練得到的weights作為最終的模型。這個(gè)做法只是額外增加了訓(xùn)練時(shí)間,但是對模型的推理沒有任何影響,更重要的是作者通過實(shí)驗(yàn)證明了這個(gè)策略在實(shí)例分割模型(Mask R-CNN)、two-stage檢測模型(Faster R-CNN),基于anchor的one-stage檢測模型(RetinaNet,YOLOv3)以及anchor-free的檢測模型(FCOS)上都簡單有效。這個(gè)trick是來源于18年的一份工作所提出的Stochastic Weights Averaging (SWA),經(jīng)過實(shí)驗(yàn)作者發(fā)現(xiàn)SWA在檢測領(lǐng)域也有效。
SWA
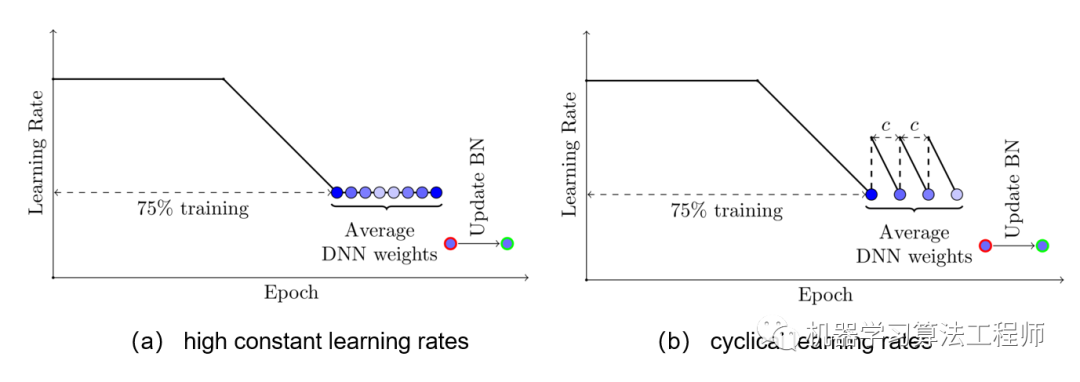
SWA簡單來說就是對訓(xùn)練過程中的多個(gè)checkpoints進(jìn)行平均,以提升模型的泛化性能。記訓(xùn)練過程第個(gè)epoch的checkpoint為,一般情況下我們會(huì)選擇訓(xùn)練過程中最后的一個(gè)epoch的模型或者在驗(yàn)證集上效果最好的一個(gè)模型作為最終模型。但SWA一般在最后采用較高的固定學(xué)習(xí)速率或者周期式學(xué)習(xí)速率額外訓(xùn)練一段時(shí)間,取多個(gè)checkpoints的平均值作為最終模型。SWA的具體做法如下圖所示,前75%的時(shí)間使用標(biāo)準(zhǔn)的衰減學(xué)習(xí)速率策略訓(xùn)練,然后剩余25%設(shè)置一個(gè)合理的固定學(xué)習(xí)速率進(jìn)行訓(xùn)練,最后平均第二階段每個(gè)epoch的weights。如下圖b所示,也可以采用在每個(gè)epoch采用周期式的學(xué)習(xí)速率策略來訓(xùn)練。另外一點(diǎn)是模型中如果有BN層,那么應(yīng)該用SWA得到的模型在訓(xùn)練數(shù)據(jù)中跑一遍得到BN層的running statistics。
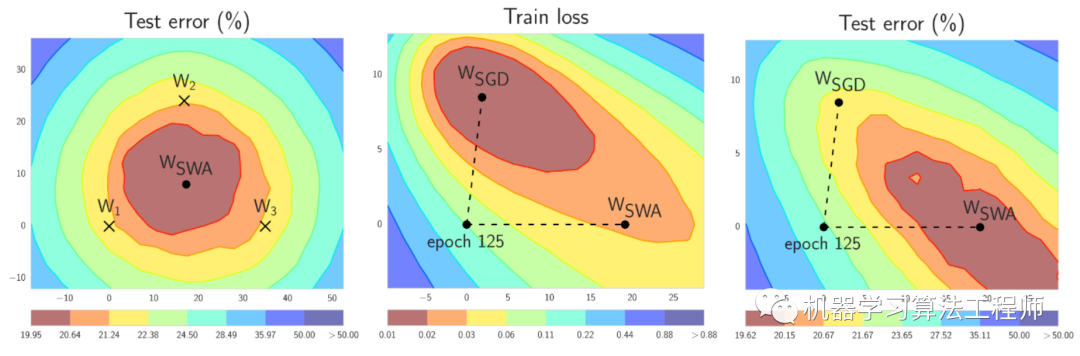
那么SWA為什么有效呢,論文也給了簡單的解釋,由于模型的參數(shù)屬于高維空間,SGD訓(xùn)練的模型往往收斂到最優(yōu)解的邊界區(qū)域,如下圖a中的模型, 和都落在邊緣位置,但是平均它們可以接近最優(yōu)解。那么SWA后面采用固定學(xué)習(xí)速率或者周期式學(xué)習(xí)速率來尋找更多的次優(yōu)解,最后平均接近最優(yōu)解。圖b和c是說的是訓(xùn)練誤差和測試誤差往往不對齊,就是我們所說的模型泛化性能,那么平均的話其實(shí)是可以提升泛化性能的。
其實(shí)除了SWA,另外一個(gè)常用的策略是對訓(xùn)練過程的weights進(jìn)行指數(shù)加權(quán)平均來提升泛化性能,這個(gè)TensorFlow有對應(yīng)的實(shí)現(xiàn)tf.train.ExponentialMovingAverage:
shadow_variable = decay * shadow_variable +(1- decay)* variable
SWA在檢測上的應(yīng)用
具體到目標(biāo)檢測模型,那么要通過實(shí)驗(yàn)來確定SWA的具體策略:學(xué)習(xí)速率策略以及訓(xùn)練epochs。論文中選擇了Mask R-CNN模型進(jìn)行實(shí)驗(yàn),其中學(xué)習(xí)速率第一種是采用固定學(xué)習(xí)速率,共0.02, 0.002和0.0002三種學(xué)習(xí)速率,第二種是采用cos學(xué)習(xí)速率,如下圖所示,每個(gè)epoch為一個(gè)周期,epoch開始時(shí)的學(xué)習(xí)速率最大,然后在epoch結(jié)束時(shí)學(xué)習(xí)速率衰減為最低,實(shí)驗(yàn)共選擇了兩套參數(shù)(0.01, 0.0001)和 (0.02, 0.0002)。至于訓(xùn)練epochs,共選擇兩套參數(shù):24和48個(gè)epochs。這里對pretrained的模型進(jìn)行finetune時(shí),由于BN參數(shù)被frozen,所以不需要像原始的SWA那樣重新計(jì)算訓(xùn)練集的running statistics。

具體實(shí)驗(yàn)結(jié)果如下表所示,從實(shí)驗(yàn)結(jié)果來看,采用固定學(xué)習(xí)速率最終的模型效果有所惡化,但是采用cos學(xué)習(xí)速率效果有提升,具體地采用cos lr為(0.02, 0.0002),額外訓(xùn)練12個(gè)epoch就可以額外提升約一個(gè)點(diǎn)。另外這個(gè)策略也在Faster R-CNN,RetinaNet,F(xiàn)COS,YOLOv3和VFNet實(shí)驗(yàn),最終都可以大約提升AP一個(gè)點(diǎn)左右。所以最后的策略是:
after the conventional training of an object detector with the initial learning rate and the ending learning rate , train it for an extra 12 epochs using the cyclical learning rates (, ) for each epoch, and then average these 12 checkpoints as the final detection model

參考文獻(xiàn)
SWA Object Detection Stochastic Weight Averaging in PyTorch
推薦閱讀
CondInst:性能和速度均超越Mask RCNN的實(shí)例分割模型
mmdetection最小復(fù)刻版(十一):概率Anchor分配機(jī)制PAA深入分析
MMDetection新版本V2.7發(fā)布,支持DETR,還有YOLOV4在路上!
無需tricks,知識(shí)蒸餾提升ResNet50在ImageNet上準(zhǔn)確度至80%+
不妨試試MoCo,來替換ImageNet上pretrain模型!
mmdetection最小復(fù)刻版(七):anchor-base和anchor-free差異分析
mmdetection最小復(fù)刻版(四):獨(dú)家yolo轉(zhuǎn)化內(nèi)幕
機(jī)器學(xué)習(xí)算法工程師
? ??? ? ? ? ? ? ? ? ? ? ? ??????? ??一個(gè)用心的公眾號(hào)
?
