
如何衡量目標(biāo)檢測(cè)模型的優(yōu)劣

極市導(dǎo)讀
?機(jī)器學(xué)習(xí)算法的落地從數(shù)據(jù)>>建模>>訓(xùn)練>>評(píng)估>>部署,生命周期中的這5個(gè)環(huán)節(jié)一樣都不能少,其中算法的評(píng)估尤為重要,不同的任務(wù)有其自身的衡量標(biāo)準(zhǔn).
本文我們走進(jìn)目標(biāo)檢測(cè)任務(wù)的各項(xiàng)評(píng)價(jià)指標(biāo),回顧各項(xiàng)衡量標(biāo)準(zhǔn)的優(yōu)劣及使用環(huán)境。?>>加入極市CV技術(shù)交流群,走在計(jì)算機(jī)視覺的最前沿
細(xì)數(shù)目標(biāo)檢測(cè)中的評(píng)價(jià)指標(biāo)
計(jì)算機(jī)視覺中的目標(biāo)檢測(cè)即包含了分類和回歸兩大任務(wù),對(duì)于預(yù)測(cè)的結(jié)果我們不能憑直覺判斷模型的好壞,而是需要一個(gè)量化指標(biāo)。業(yè)界對(duì)模型的性能評(píng)估已經(jīng)有很多不同的指標(biāo):比如準(zhǔn)確率、精確率、召回率、平方誤差、余弦距離、P-R曲線、ROC曲線、AP、mAP、AUC、IOU等等。本文我們從最簡(jiǎn)單的準(zhǔn)確率說起。
最簡(jiǎn)單的評(píng)價(jià)指標(biāo)—準(zhǔn)確率
準(zhǔn)確率是分類問題中最簡(jiǎn)單的評(píng)價(jià)指標(biāo),表示正確的樣本占總樣本的比例。這里我們會(huì)有一個(gè)疑問:是不是模型的準(zhǔn)確率越高性能就越好呢?
當(dāng)然不是。準(zhǔn)確率一般是從全局角度評(píng)估模型的優(yōu)劣。但是它存在一定的局限性,比如訓(xùn)練階段有1000個(gè)樣本,其中999個(gè)負(fù)樣本,1個(gè)正樣本。那么如果我們將所有樣本都預(yù)測(cè)成負(fù)樣本,準(zhǔn)確率可以達(dá)到99.9%,從數(shù)據(jù)上看感覺性能很好,但是部署上線后可能大部分正樣本都預(yù)測(cè)錯(cuò)誤,造成用戶體驗(yàn)的下降。
原因是由于樣本類別的不平衡導(dǎo)致訓(xùn)練過程雖然準(zhǔn)確率很高,但是實(shí)際效果卻不好,得到誤導(dǎo)性的結(jié)果。如果準(zhǔn)確率不能很有效的評(píng)估模型性能,那么我們可以采用什么指標(biāo)來評(píng)估呢?
精確率和召回率一對(duì)矛盾共生體
在日常生活中我們經(jīng)常遇到這樣的情況:比如你去超市買橘子,我們關(guān)心的是挑選的橘子中有多少個(gè)是甜的;或者所有甜的橘子中有多少個(gè)被你選中了。前者叫做精確率,后者叫做召回率。
精確率又叫查準(zhǔn)率,是指分類正確的正樣本個(gè)數(shù)占分類器判定為正樣本的樣本個(gè)數(shù)的比例。
召回率又叫查全率,是指分類正確的正樣本個(gè)數(shù)占真正的正樣本個(gè)數(shù)的比例。
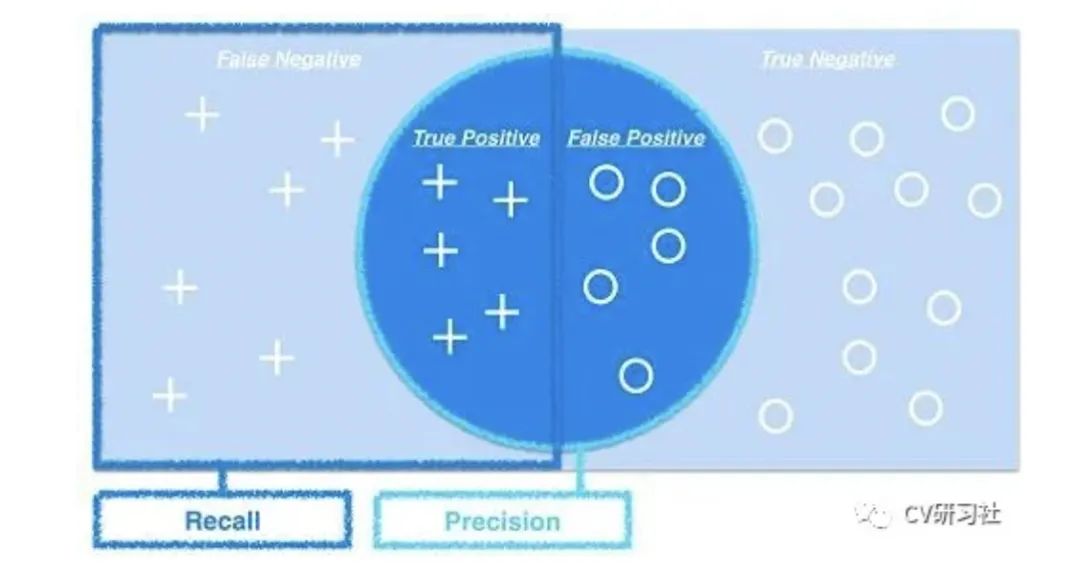
這兩個(gè)定義有點(diǎn)拗口,具體可以借助下面的混淆矩陣直觀理解(本文圖片來源于網(wǎng)絡(luò),如有侵權(quán)聯(lián)系刪除)
精準(zhǔn)度和召回率是最常見的指標(biāo)之一,模型的性能需要在兩者之間權(quán)衡。往往為了提供精確率,需要盡量在更有把握時(shí)才將待測(cè)樣本判定為正樣本,但如此保守的策略也會(huì)漏掉很多真值。
和誰(shuí)都有關(guān)系的混淆矩陣
為了可視化算法的性能如何,這里引出一個(gè)混淆矩陣的概念,它能夠快速直觀的幫助算法人員分析每個(gè)類別的誤分類情況。
我們經(jīng)常會(huì)看到這么幾個(gè)簡(jiǎn)寫:TP,TN,F(xiàn)P,F(xiàn)N:
TP代表真陽(yáng)性,即正樣本被預(yù)測(cè)成正樣本 TN代表真陰性,即負(fù)樣本被預(yù)測(cè)成負(fù)樣本 FP代表假陽(yáng)性,即負(fù)樣本被預(yù)測(cè)成正樣本 FN代表假陰性,即正樣本被預(yù)測(cè)成負(fù)樣本
這四個(gè)簡(jiǎn)稱小編以前經(jīng)常會(huì)記混,第一個(gè)字母表示預(yù)測(cè)的對(duì)錯(cuò)True/False,第二個(gè)字母表示預(yù)測(cè)的結(jié)果Positive/Negative。
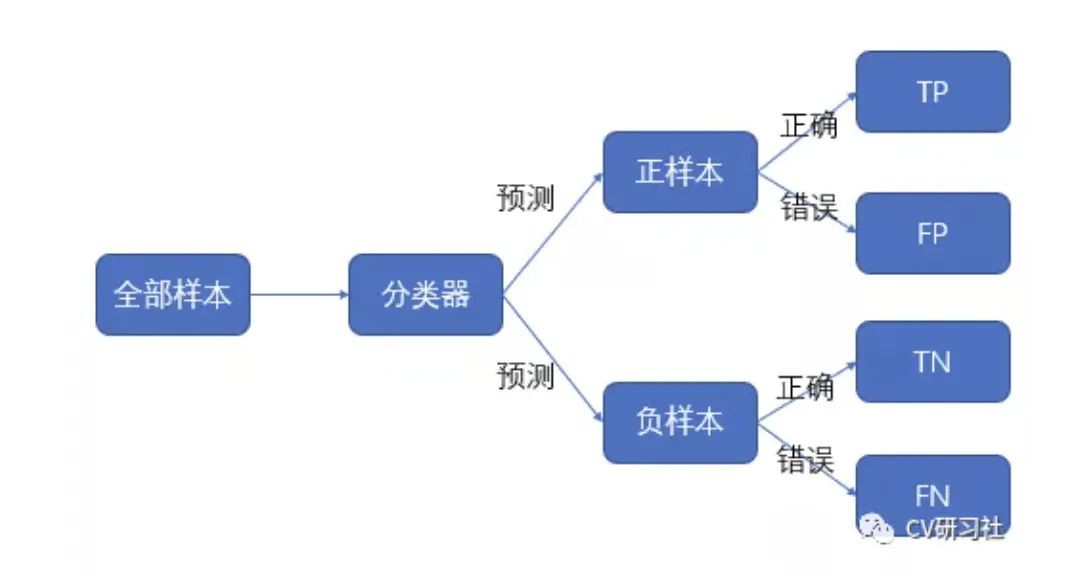
通過這四個(gè)統(tǒng)計(jì)量可以幫我們構(gòu)建出下圖的矩陣,這里我們是以二分類為例,構(gòu)建2×2的矩陣;如果是K個(gè)類別,可以推廣到K×K的矩陣:
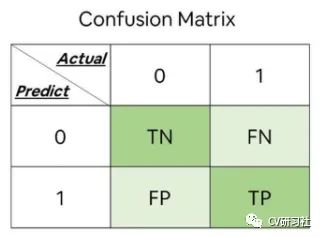
其中每一列代表預(yù)測(cè)值,每一行代表實(shí)際值。每一行的個(gè)數(shù)之和代表該類別的實(shí)際個(gè)數(shù),所有正確預(yù)測(cè)的結(jié)果都在矩陣的對(duì)角線上,它可以解決上面提到的正確率指標(biāo)的局限性,直觀的看出每個(gè)類別正確識(shí)別的數(shù)量和錯(cuò)誤識(shí)別的數(shù)量。
混淆矩陣也可以延伸出各個(gè)評(píng)價(jià)指標(biāo)的表達(dá)方式:
準(zhǔn)確率 = TP / (TP + TN + FP + FN) 精確率 = TP / (TP + FP) 召回率 = TP / (TP + FN) F1 = 2 × 精確率 × 召回率 / (精確率 + 召回率)
備注:F1得分是精確率和召回率的調(diào)和平均值。
上面我們討論的精確率/召回率都是在固定閾值下得到的一個(gè)數(shù)值,為了綜合評(píng)估一個(gè)模型的優(yōu)劣,是否需要在不同的Top N下的觀察P-R兩方面的結(jié)果呢?
P-R 曲線和AP值的用途
P-R 曲線是由精確率和召回率構(gòu)成的一張曲線圖,以召回率作為橫坐標(biāo)軸,精確率作為縱坐標(biāo)軸。在某個(gè)閾值下,模型將大于該閾值的結(jié)果判定成正樣本,將小于該閾值的結(jié)果判定成負(fù)樣本,再結(jié)合真值得到精確率和召回率,即表示P-R曲線上的一個(gè)點(diǎn)。如果想要生成一幅 P-R 曲線圖,通常需要執(zhí)行以下幾步:
用訓(xùn)練好的模型評(píng)估所有測(cè)試樣本的得分; 每一類分別分開統(tǒng)計(jì),并對(duì)分類概率值排序; 從Top-1開始,將第1個(gè)置信度作為閾值,當(dāng)前預(yù)測(cè)的為正樣本,其余得分小于該閾值的作為負(fù)樣本,統(tǒng)計(jì)TP,F(xiàn)P,F(xiàn)N; 根據(jù)統(tǒng)計(jì)值計(jì)算當(dāng)前閾值下的精確度和召回率; 從Top-1至Top-N重復(fù)步驟3和4; 將不同閾值下的P-R值繪制成P-R曲線圖;
通常P-R曲線可以顯示出分類器在查準(zhǔn)率與查全率之間的權(quán)衡。在各大刷榜論文中給出的AP值就是指P-R曲線下面的面積。下圖是包含A,B,C三個(gè)分類器的P-R曲線圖:
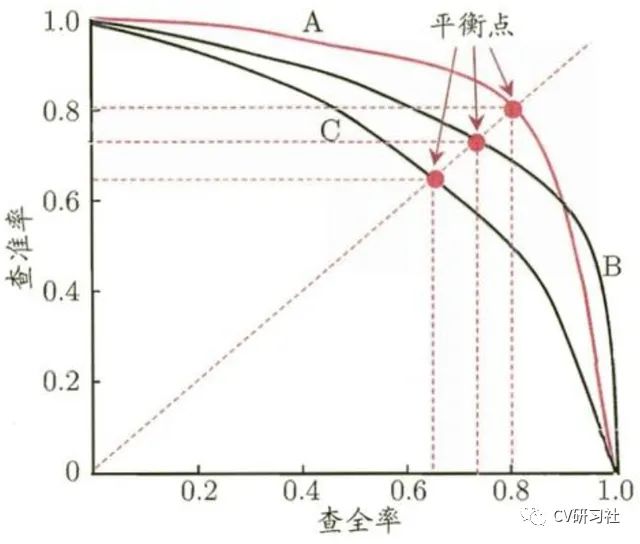
根據(jù)P-R曲線圖如何評(píng)估不同分類器的性能呢?
分類器C的P-R曲線被分類器A或B的P-R曲線完全包住,則說明分類器A和B的性能優(yōu)于C;
當(dāng)A和B兩個(gè)分類器的P-R曲線交叉時(shí)又該怎么評(píng)估性能優(yōu)劣呢?
一般可以統(tǒng)計(jì)A和B曲線下的面積來衡量,該面積又叫做平均精度AP,值越大性能越好。為了更加準(zhǔn)確的計(jì)算,還可以采用平衡點(diǎn)或者F1 score的方式度量。
如果用戶場(chǎng)景對(duì)模型的性能更偏向于全面性或者精確性怎么辦?
我們知道F1 score是調(diào)和平均數(shù),認(rèn)為精確率和召回率重要程度一樣的一個(gè)統(tǒng)計(jì)平均值。當(dāng)用戶的業(yè)務(wù)場(chǎng)景本身就需要偏向某一方時(shí),該值就不在適用了。針對(duì)用戶的不同偏好,可以在F1的基礎(chǔ)上增加權(quán)重a,即(1 + a×a) P×R / ((a × a × P) + R),權(quán)重a>1時(shí),召回率占比更大,權(quán)重a < 1時(shí),精準(zhǔn)率占比更大。
在P-R曲線中,不管是精確率還是召回率關(guān)注點(diǎn)都在于正樣本的占比,如果在測(cè)試集中的正負(fù)樣本占比發(fā)生變化后,P-R曲線的統(tǒng)計(jì)值就會(huì)發(fā)生很大的變化,但是在實(shí)際應(yīng)用中,在類別不平衡的數(shù)據(jù)中用戶關(guān)心的也還是正樣本,所以P-R曲線仍然被廣泛應(yīng)用。
如果有小伙伴非要兼顧正樣本和負(fù)樣本,評(píng)估分類器的整體水平怎么辦呢?這里我們有另一種曲線——ROC曲線!
ROC 曲線和 AUC 值的用途
ROC曲線反映了真陽(yáng)性率和假陽(yáng)性率之間的變化關(guān)系。橫軸就是FPR,縱軸就是TPR,然后選擇不同的閾值時(shí),就可以對(duì)應(yīng)坐標(biāo)系中一個(gè)點(diǎn)。
真陽(yáng)性率即TPR = TP / (TP + FN),表示在所有正樣本中被預(yù)測(cè)為正樣本的比例,俗稱命中率。
假陽(yáng)性率即FPR = FP / (FP + TN),表示在所有負(fù)樣本中被預(yù)測(cè)成正樣本的比例,俗稱虛警率。
如下圖所示:我們主要看正方形的四個(gè)頂點(diǎn)(0,0),(0,1),(1,0),(1,1)的含義:
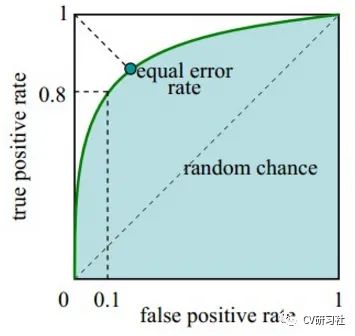
我們根據(jù)ROC計(jì)算的兩個(gè)數(shù)學(xué)公式來進(jìn)一步分析:
(0,0)點(diǎn)表示TPR=0且TFR=0,也就是說TP和FP都是0,換句話說就是給我任何一個(gè)樣本,都會(huì)被預(yù)測(cè)成正樣本。
(1,1)點(diǎn)表示TPR=1且TFR=1,也就是說TP和FP都是1,和(0,0)點(diǎn)的含義剛好相反,給我任何一個(gè)樣本,都會(huì)被預(yù)測(cè)成負(fù)樣本。
(0,1)點(diǎn)表示FPR=0且TPR=1,也就是說FP和FN都是0,既沒有把任何一個(gè)負(fù)樣本預(yù)測(cè)成正樣本,也沒有把任何一個(gè)正樣本預(yù)測(cè)成負(fù)樣本,這不是完美嘛!所以曲線越趨近于左上角,預(yù)測(cè)結(jié)果越準(zhǔn)確。
(1,0)點(diǎn)表示FPR=1且TPR=0,也就是說TP和TN都是0,這簡(jiǎn)直是史上運(yùn)氣最差的分類器,沒有一個(gè)正樣本預(yù)測(cè)正確,也沒有一個(gè)負(fù)樣本預(yù)測(cè)正確。
這里計(jì)算的ROC仍然是根據(jù)固定閾值進(jìn)行混淆矩陣的統(tǒng)計(jì)最后得到的一個(gè)點(diǎn),曲線的繪制和P-R曲線流程相似,都是根據(jù)測(cè)試數(shù)據(jù)的類別置信度進(jìn)行從高到低的排序,依次將置信度得分作為閾值統(tǒng)計(jì)不同區(qū)域時(shí)的FPR和TPR。
被繞進(jìn)去的小伙伴可以在回到上面重溫混淆矩陣,構(gòu)建一個(gè)高性能的分類器我們希望假陽(yáng)性率越小越好,真陽(yáng)性率越大越好。相比于P-R曲線,TPR更加關(guān)注正樣本,F(xiàn)PR更加關(guān)注負(fù)樣本,所以是一種對(duì)正負(fù)樣本更加均衡的評(píng)估方式。
ROC曲線在數(shù)據(jù)分布發(fā)生變化時(shí)表現(xiàn)的平穩(wěn)性,也注定是它的缺陷所在,在模型評(píng)估的時(shí)候,當(dāng)正負(fù)樣本比例是1:1、1:10、1:100等等,ROC曲線形式都是驚人的相似,而P-R曲線更加明顯的表現(xiàn)出模型之間的優(yōu)劣。
AP表示P-R曲線下的面積,那么ROC曲線下的面積又有什么物理意義呢?
ROC曲線下面積越大,該模型越有可能將正樣本排在負(fù)樣本前面,表明分類器的性能越好,這個(gè)概率值就叫做AUC。
- END -
如果覺得有用,就請(qǐng)分享到朋友圈吧!
公眾號(hào)后臺(tái)回復(fù)“CVPR21檢測(cè)”獲取CVPR2021目標(biāo)檢測(cè)論文下載~

#?CV技術(shù)社群邀請(qǐng)函?#

備注:姓名-學(xué)校/公司-研究方向-城市(如:小極-北大-目標(biāo)檢測(cè)-深圳)
即可申請(qǐng)加入極市目標(biāo)檢測(cè)/圖像分割/工業(yè)檢測(cè)/人臉/醫(yī)學(xué)影像/3D/SLAM/自動(dòng)駕駛/超分辨率/姿態(tài)估計(jì)/ReID/GAN/圖像增強(qiáng)/OCR/視頻理解等技術(shù)交流群
每月大咖直播分享、真實(shí)項(xiàng)目需求對(duì)接、求職內(nèi)推、算法競(jìng)賽、干貨資訊匯總、與?10000+來自港科大、北大、清華、中科院、CMU、騰訊、百度等名校名企視覺開發(fā)者互動(dòng)交流~
